朴素贝叶斯(NB)复习总结
摘要:
1.算法概述
2.算法推导
3.算法特性及优缺点
4.注意事项
5.实现和具体例子
6.适用场合
内容:
1.算法概述
贝叶斯分类算法是统计学的一种分类方法,其分类原理就是利用贝叶斯公式根据某对象的先验概率计算出其后验概率,然后选择具有最大后验概率的类作为该对象所属的类。
之所以称之为"朴素",是因为贝叶斯分类只做最原始、最简单的假设:
1,所有的特征之间是统计独立的;
2,所有的特征地位相同。那么假设某样本x有a1,...,aM个属性
那么有:P(x)=P(a1,...,aM) = P(a1)*...*P(aM);这里给出NB的模型函数:
根据变量的分布不同,NB也分为以下3类:
朴素贝叶斯的高斯模型(连续变量,符合高斯分布)
朴素贝叶斯的多项式模型(离散变量,符合多项分布)
朴素贝叶斯的伯努利模型(离散变量,符合二项分布),在文本分类的情境中,被用来训练和使用这一分类器的是词语同现向量
2.算法推导
贝叶斯定理:

其中P(A|B)是在B发生的情况下A发生的可能性。
在贝叶斯定理中,每个名词都有约定俗成的名称:
P(A)是A的先验概率或边缘概率。之所以称为"先验"是因为它不考虑任何B方面的因素。
P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
P(B)是B的先验概率或边缘概率,也作标准化常量(normalizing constant).
由贝叶斯公式和各特征相互独立的情况下,将贝叶斯公式A替换为y,B替换为X;去掉分母(同一样本的分母不影响整体的大小)得到如下公式:

条件概率的计算方法:
1,离散分布-当特征属性为离散值时,只要统计训练样本中各个划分在每个类别中出现的频率即可用来估计P(a|y)。
2,连续分布-当特征属性为连续值时,通常假定a|y服从高斯分布(正态分布)。
即:

3.算法特性及优缺点
优点:算法简单、所需估计参数很少、对缺失数据不太敏感。另外朴素贝叶斯的计算过程类条件概率等计算彼此是独立的,因此特别适于分布式计算。朴素贝叶斯属于生成式模型,收敛速度将快于判别模型(如逻辑回归);天然可以处理多分类问题
缺点:因为朴素贝叶斯分类假设样本各个特征之间相互独立,这个假设在实际应用中往往是不成立的,从而影响分类正确性;不能学习特征间的相互作用;对输入数据的表达形式很敏感。
4.注意事项
4.1 取对数:
实际项目中,概率P往往是值很小的小数,连续的微小小数相乘容易造成下溢出使乘积为0或者得不到正确答案。一种解决办法就是对乘积取自然对数,将连乘变为连加,ln(AB)=lnA+lnB。
4.2 Laplace校准:
如果新特征出现,会导致类别的条件概率为0,最终出现0/0 未定义的情况 ;修改后的的表达式为: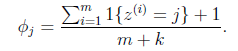 每个z=j的分子都加1,分母加k(类别的个数)。
每个z=j的分子都加1,分母加k(类别的个数)。
5.实现和具体例子
垃圾邮件过滤:吴恩达的斯坦福公开课
6.适用场合
是否支持大规模数据:支持,并且有分布式实现
特征维度:可以很高
是否有 Online 算法:有(参考自)
特征处理:支持数值型,类别型类型
朴素贝叶斯(NB)复习总结的更多相关文章
- 朴素贝叶斯(Naive Bayes)
1.朴素贝叶斯模型 朴素贝叶斯分类器是一种有监督算法,并且是一种生成模型,简单易于实现,且效果也不错,需要注意,朴素贝叶斯是一种线性模型,他是是基于贝叶斯定理的算法,贝叶斯定理的形式如下: \[P(Y ...
- Logistic 最大熵 朴素贝叶斯 HMM MEMM CRF 几个模型的总结
朴素贝叶斯(NB) , 最大熵(MaxEnt) (逻辑回归, LR), 因马尔科夫模型(HMM), 最大熵马尔科夫模型(MEMM), 条件随机场(CRF) 这几个模型之间有千丝万缕的联系,本文首先会 ...
- Python实现nb(朴素贝叶斯)
Python实现nb(朴素贝叶斯) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>ope ...
- 【cs229-Lecture5】生成学习算法:1)高斯判别分析(GDA);2)朴素贝叶斯(NB)
参考: cs229讲义 机器学习(一):生成学习算法Generative Learning algorithms:http://www.cnblogs.com/zjgtan/archive/2013/ ...
- 【机器学习与R语言】3-概率学习朴素贝叶斯(NB)
目录 1.理解朴素贝叶斯 1)基本概念 2)朴素贝叶斯算法 2.朴素贝斯分类应用 1)收集数据 2)探索和准备数据 3)训练模型 4)评估模型性能 5)提升模型性能 1.理解朴素贝叶斯 1)基本概念 ...
- Stanford大学机器学习公开课(六):朴素贝叶斯多项式模型、神经网络、SVM初步
(一)朴素贝叶斯多项式事件模型 在上篇笔记中,那个最基本的NB模型被称为多元伯努利事件模型(Multivariate Bernoulli Event Model,以下简称 NB-MBEM).该模型有多 ...
- Stanford大学机器学习公开课(五):生成学习算法、高斯判别、朴素贝叶斯
(一)生成学习算法 在线性回归和Logistic回归这种类型的学习算法中我们探讨的模型都是p(y|x;θ),即给定x的情况探讨y的条件概率分布.如二分类问题,不管是感知器算法还是逻辑回归算法,都是在解 ...
- Spark朴素贝叶斯(naiveBayes)
朴素贝叶斯(Naïve Bayes) 介绍 Byesian算法是统计学的分类方法,它是一种利用概率统计知识进行分类的算法.在许多场合,朴素贝叶斯分类算法可以与决策树和神经网络分类算法想媲美,该算法能运 ...
- R语言︱贝叶斯网络语言实现及与朴素贝叶斯区别(笔记)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 一.贝叶斯网络与朴素贝叶斯的区别 朴素贝叶斯的 ...
随机推荐
- 进击的Python【第二十章】
1.Django请求的生命周期 路由系统 -> 试图函数(获取模板+数据=>渲染) -> 字符串返回给用户 2.路由系统 /index/ -> 函数或类.as_view() / ...
- centos 研究
默认工具: yum , (Ubuntu: apt-get)
- C# Current thread must be set to single thread apartment (STA) mode before OLE calls can be made
将箭头指向部分替换为编译器报错的内容即可. 参考文章:https://www.experts-exchange.com/questions/28238490/C-help-needed-Current ...
- java-并发-活性
浏览以下内容前,请点击并阅读 声明 一个并发程序以适时方式执行的能力叫活性.以下部分介绍最常见的一种活性问题,死锁,并简单介绍其他两种活性问题,饥饿和活锁. 死锁 死锁描述了一种情况:两个或两个以上的 ...
- 【BO】SAP BO相关问题汇总贴
本文将以往写过的关于SAP BO相关问题的帖子汇总了一下,方便寻找 #1 为WEBI报表添加自定义字体font #2 WEBI文件打开时提示Illegal access错误 #3 安装BO服务器时,o ...
- 数据库sqlite 存储图片
SQLite可以存储 BLOB(binary large object,二进制大对象)格式数据,利用它可以在安卓应用开发中存储图片资源. 这里先讲下,怎样把数据从数据库中取出,并显示在imagView ...
- 【hihoCoder】1148:2月29日
问题:http://hihocoder.com/problemset/problem/1148 给定两个日期,计算这两个日期之间有多少个2月29日(包括起始日期). 思路: 1. 将问题转换成求两个日 ...
- java执行linux命令
package com.gtstar.collector; import java.io.BufferedReader;import java.io.IOException;import java.i ...
- tornado web 框架的认识
tornado 简介 1,概述 Tornado就是我们在 FriendFeed 的 Web 服务器及其常用工具的开源版本.Tornado 和现在的主流 Web 服务器框架(包括大多数 Python 的 ...
- C++风格的回调对象方法. 采用template实现
今天看了一篇文章,收藏一下代码.读一读很有激情 #include <iostream> #include <string> #include <vector> us ...