对数据仓库Hive的一些认识
首先我们得明白什么是数据仓库?
数据仓库,英文名称为Data warehouse,可简写为DW或DWH。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。它出于分析性报告和决策支持目的而创建。
数据仓库本身并不“生产”任何数据,同时自身也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。
数据仓库的主要特征:数据仓库是 面向主题的(Subject-Oriented )、 集成的(Integrated)、非易失的(Non-Volatile)和 时变的(Time-Variant )数据集合,用以支持管理决策。
数据仓库与数据库的区别:数据库与数据仓库的区别实际讲的是 OLTP 与 OLAP 的区别。
操作型处理,叫联机事务处理 OLTP(On-Line Transaction Processing),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理,叫联机分析处理 OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策。
首先我们要明白,数据仓库的出现,并不是要取代数据库。概况起来,可以从以下几个方面去看待数据仓库跟数据库的区别:
- 数据库是面向事务的设计,数据仓库是面向主题设计的。
- 数据库一般存储业务数据,数据仓库存储的一般是历史数据。
- 数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的 User 表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
关于数据仓库分层架构:按照数据流入流出的过程,数据仓库架构可分为三层—— 源数据、数据仓库、数据应用。
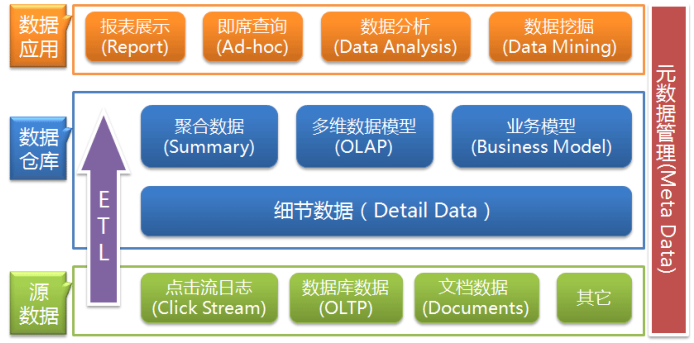
数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自下而上流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。
源数据层(ODS):此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。
细节层(DW):为数据仓库层,DW 层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。
应用层(DA 或 APP):前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据。
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是 ETL(抽取 Extra, 转化 Transfer, 装载 Load)的过程,ETL 是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持 ETL 的正常和稳定。
为什么要对数据仓库分层?
用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。
通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
数据仓库元数据管理
元数据(Meta Date),其实应该叫做解释性数据,或者数据字典,即数据的数据。主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及 ETL 的任务运行状态。一般会通过元数据资料库(MetadataRepository)来统一地存储和管理元数据,其主要目的是使数据仓库的设计、部署、操作和管理能达成协同和一致。
元数据是数据仓库管理系统的重要组成部分,元数据管理是企业级数据仓库中的关键组件,贯穿数据仓库构建的整个过程,直接影响着数据仓库的构建、使用和维护。
注:
- 构建数据仓库的主要步骤之一是 ETL。这时元数据将发挥重要的作用,它定义了源数据系统到数据仓库的映射、数据转换的规则、数据仓库的逻辑结构、数据更新的规则、数据导入历史记录以及装载周期等相关内容。数据抽取和转换的专家以及数据仓库管理员正是通过元数据高效地构建数据仓库。
- 用户在使用数据仓库时,通过元数据访问数据,明确数据项的含义以及定制报表。
- 数据仓库的规模及其复杂性离不开正确的元数据管理,包括增加或移除外部数据源,改变数据清洗方法,控制出错的查询以及安排备份等。
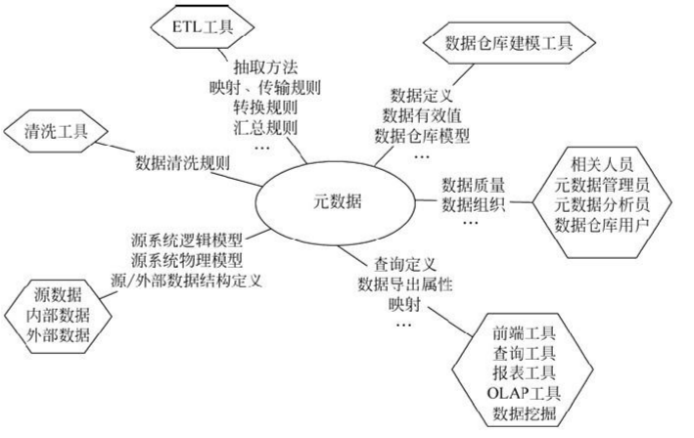
由上可见,元数据不仅定义了数据仓库中数据的模式、来源、抽取和转换规则等,而且是整个数据仓库系统运行的基础,元数据把数据仓库系统中各个松散的组件联系起来,组成了一个有机的整体。
那么重点来了,什么是hive呢?
Hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。本质是将SQL转换为MapReduce程序。
hive的主要用途:用来做离线数据分析,比直接用MapReduce程序开发效率更高。
直接使用MapReduce所面临的问题:
- 人员学习成本太高
- 项目周期要求太短
- MapReduce 实现复杂查询逻辑开发难度太大
为什么使用hive:
- 操作接口采用类 SQL 语法,提供快速开发的能力。
- 避免了去写 MapReduce,减少开发人员的学习成本。
- 功能扩展很方便。
再来看一下hive的架构图
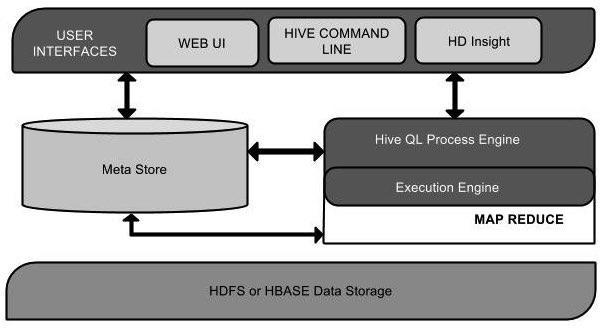
Hive基本组成
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- 元数据存储:通常是存储在关系数据库如 mysql , derby 中。
- 解释器、编译器、优化器、执行器。
Hive 各组件的基本功能
用户接口主要由三个:CLI、JDBC/ODBC 和 WebGUI。其中,CLI(command lineinterface)为 shell 命令行;JDBC/ODBC 是 Hive 的 JAVA 实现,与传统数据库 JDBC 类似;WebGUI 是通过浏览器访问 Hive。
元数据存储:Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有MapReduce 调用执行。
Hive 与 Hadoop 的关系
Hive 利用 HDFS存储数据,利用 MapReduce 查询分析数据 。

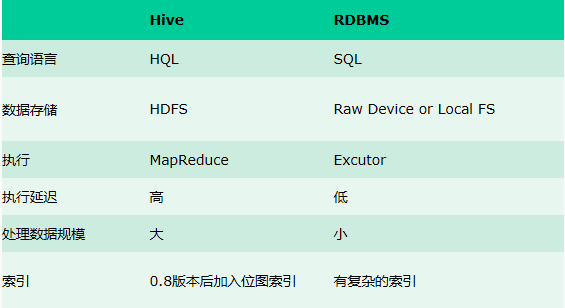
Hive与传统数据库对比
hive 用于海量数据的离线数据分析。hive 具有 sql 数据库的外表,但应用场景完全不同,hive 只适合用来做批量数据统计分析。更直观的对比看下面这幅图:
对数据仓库Hive的一些认识的更多相关文章
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive中分区Partition如何使用
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 将数据从数据仓库Hive导入到MySQL
1.启动Hadoop,hive,mysql 2.在mysql中建表(需要导入数据的) mysql> CREATE TABLE `dbtaobao`.`user_log` (`user_id` v ...
- Spark环境搭建(四)-----------数据仓库Hive环境搭建
Hive产生背景 1)MapReduce的编程不便,需通过Java语言等编写程序 2) HDFS上的文缺失Schema(在数据库中的表名列名等),方便开发者通过SQL的方式处理结构化的数据,而不需要J ...
- Hadoop整理五(基于Hadoop的数据仓库Hive)
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合.它是单个数据存储,出于分析性报告和决策支持目的而创建. 为需要业务智能的企业,提供指导业务流程改进.监视时间.成本.质量以及控 ...
- 基于Hadoop的数据仓库Hive
Hive是基于Hadoop的数据仓库工具,可对存储在HDFS上的文件中的数据集进行数据整理.特殊查询和分析处理,提供了类似于SQL语言的查询语言–HiveQL,可通过HQL语句实现简单的MR统计,Hi ...
- Hive- 大数据仓库Hive
什么是 Hive? Hive 是由 FaceBook 开源用于解决少量数据结构化日志的数据统计.Hive是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询 ...
随机推荐
- Raymond Mill In Lisp
Raymond Mill is suitable for producing minerals powder, which is widely used in the metallurgy, buil ...
- 解决Spring JdbcTemplate调用queryForObject()方法结果集为空时报异常
JdbcTemplate用的时候发现一个问题:调用queryForObject()方法,如果没有查到东西则会抛一个异常:org.springframework.dao.EmptyResultDataA ...
- 一步一步配置Spring
https://blog.csdn.net/tangtong1/article/details/51442757
- Ubuntu安装LAMP环境(PHP5.6) 以及下载安装phpmyadmin
参考路径: http://blog.nciaer.com/?p=133 修改apache(2.4.18)的web路径时, 需要将 /etc/apache2/sites-available/000def ...
- xmanger图形化登陆远程服务器
由于网上的资料比较杂,经过本人整理实际操作验证,保证ok 本人的服务器系统为centos5.8 下面的都是centos服务器上的操作,需要简单的配置下: win客户端使用xmanger软件:首先是服 ...
- Device
#import "AppDelegate.h" #import "RootViewController.h" @implementation AppDelega ...
- DB2常用函数详解
(一) 字符串函数 VALUE函数 语法:VALUE(EXPRESSION1,EXPRESSION2) VALUE函数是用返回一个非空的值,当其第一个参数非空,直接返回该参数的值,如果第一个参数为空 ...
- android sqlite 递归删除一棵子树
背景:android studio 3.0 GreenDao 目标:在android 中,如何做到递归删除某颗子树?? ======================================== ...
- genlist -s 192.168.21.\*
显示网段192.168.21中可用的主机.
- Jsoup进阶选择器
package com.open1111.jsoup; import org.apache.http.HttpEntity;import org.apache.http.client.methods. ...