一样的Java,不一样的HDInsight大数据开发体验
大数据的热潮一直居高不下,每个人都在谈。你也许不知道,早些年这个领域可是有个非常「惹眼球」的段子:

1首先开始科普
什么是 HDInsight
Azure HDInsight 是 Hortonworks Data Platform (HDP) 提供的 Hadoop 组件的云发行版,适用于对计算机集群上的大数据集进行分布式处理和分析。目前 HDInsight 可提供以下集群类型:Apache Hadoop、Apache Spark、Apache HBase、Apache Storm、Apache 交互式 Hive(预览版),以及其他包含脚本操作的自定义集群。
什么是 Hadoop
Hadoop 技术堆栈包括相关的软件和实用程序(Apache Hive、HBase、Spark 等),通常包含 Hadoop 分布式文件系统 (HDFS)、适用于作业计划和资源管理的 YARN、适用于并行处理的 MapReduce。Hadoop 最常用于已存储数据的批处理。
什么是 MapReduce
MapReduce 是一个旧软件框架,用于编写并行批量处理大数据集的应用程序。MapReduce 作业将分割大型数据集,并将数据组织成键值对进行处理。MapReduce 作业在 YARN 上运行。
什么是 Java
![]() 这个真有必要解释?
这个真有必要解释?
通过 Azure HDInsight 服务使用 Hadoop,可以获得很多便利,例如:减少了设置和配置工作,提高了可用性和可靠性,可在不中断作业的情况下进行动态缩放,可灵活使用组件更新和当前版本,并且能与其他Azure 服务(包括 Web 应用和 SQL 数据库)集成。
机智的你理解这些概念了么,接下来我们一起来用 Java 开发一个 MapReduce 程序,然后通过 HDInsight服务运行吧。
2前期准备
首先你需要准备好 Java JDK 8 或更高版本以及 Apache Maven,随后按照下列方式配置开发环境:
1设置环境变量
请在安装 Java 和 JDK 时设置以下环境变量(同时请注意检查这些环境变量是否已经存在并且包含正确的值):
JAVA_HOME -应该指向已安装 Java 运行时环境 (JRE)的目录。例如在 macOS、Unix 或 Linux 系统上,值应该类似于 /usr/lib/jvm/java-7-oracle;在 Windows 中,值类似于 c:\ProgramFiles (x86)\Java\jre1.7。
PATH - 应该包含以下路径:
JAVA_HOME(或等效路径)
JAVA_HOME\bin(或等效路径)
安装 Maven 的目录
2创建 Maven 项目
1、在开发环境中,通过中断会话或命令行将目录更改为要存储此项目的位置。
2、使用随同 Maven 一起安装的 mvn 命令,为项目生成基架。

此命令将使用 artifactID 参数指定的名称(此示例中为 wordcountjava)创建目录。此目录包含以下项:
pom.xml - 项目对象模型 (POM),其中包含用于生成项目的信息和配置详细信息。
src - 包含应用程序的目录。
3、删除 src/test/java/org/apache/hadoop/examples/apptest.java 文件,此示例不使用该文件。 添加依赖项
1、编辑 pom.xml 文件,并在<dependencies>部分中添加以下文本: 
定义具有特定版本(在<version> 中列出)的库(在<artifactId> 中列出)。编译时会从默认 Maven 存储库下载这些依赖项,此外也可使用 Maven 存储库搜索来查看详细信息。
<scope>provided</scope>会告知 Maven 这些依赖项不应与此应用程序一起打包,因为它们在运行时由HDInsight 集群提供。
注意:使用的版本应与集群上存在的 Hadoop 版本匹配。有关版本的详细信息,请参阅 HDInsight 组件版本控制文档。
2、将以下内容添加到 pom.xml 文件中。 此文本必须位于文件中的 <project>...</project>标记内;例如</dependencies>和 </project>之间。 
个插件配置 Maven Shade Plugin,用于生成 uberjar(有时称为 fatjar),其中包含应用程序所需的依赖项。 它还可以防止在 jar 包中复制许可证,复制许可证在某些系统中可能会导致问题。
第二个插件配置目标 Java 版本。
注意:HDInsight 3.4 及更早版本使用 Java 7,HDInsight3.5 使用 Java 8。
3、保存 pom.xml 文件。
3创建 MapReduce 应用程序
1、转到 wordcountjava/src/main/java/org/apache/hadoop/examples 目录,并将 App.java 文件重命名为WordCount.java。
2、在文本编辑器中打开 WordCount.java 文件,然后将其内容替换为以下文本: 
意,包名称为 org.apache.hadoop.examples,类名称为 WordCount。提交 MapReduce 作业时需要使用这些名称。
3、保存文件。
4构建应用程序
1、如果尚未到达此目录,请更改为 wordcountjava 目录。
2、使用以下命令生成包含该应用程序的 JAR 文件: 
此命令将清除任何以前构建的项目,下载任何尚未安装的依赖项,然后生成并打包应用程序。
3、命令完成后,wordcountjava/target 目录将包含一个名为 wordcountjava-1.0-SNAPSHOT.jar 的文件。
注意:wordcountjava-1.0-SNAPSHOT.jar 文件是一种 uberjar,其中不仅包含 WordCount 作业,还包含作业在运行时需要的依赖项。
5上传 jar 运行 MapReduce 作业
使用以下命令将该jar 文件上传到 HDInsight 头节点: 
将 USERNAME 替换为集群的 SSH 用户名,将 CLUSTERNAME 替换为 HDInsight 集群名称。
此命令会将文件从本地系统复制到头节点。
随后通过下列步骤运行这个 MapReduce 作业:
1、使用 SSH 连接到 HDInsight。详细信息请参阅将 SSH 与 HDInsight 配合使用。
2、在 SSH 会话中,使用以下命令运行 MapReduce 应用程序: 
此命令将启动 WordCountMapReduce 应用程序。输入文件是 /example/data/gutenberg/davinci.txt,输出目录是/example/data/wordcountout。输入文件和输出均存储到集群的默认存储中。
3、作业完成后,请使用以下命令查看结果: 
用户会收到单词和计数列表,其包含的值类似于以下文本: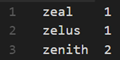
搞定收工!
我有一条不成熟的小建议
你看,使用 Java语言开发 MapReduce 程序也不是很难。
如果你更喜欢用其他语言,或者希望开发其他类型的 HDInsight 应用,那么这些资源应该能提供一些帮助:
一样的Java,不一样的HDInsight大数据开发体验的更多相关文章
- 杭州某知名xxxx公司急招大量java以及大数据开发工程师
因公司战略以及业务拓展,收大量java攻城狮以及大数据开发攻城狮. 职位信息: java攻城狮: https://job.cnblogs.com/offer/56032 大数据开发攻城狮: https ...
- Java后端开发工程师是否该转大数据开发?
撰写我对java后端开发工程师选择方向的想法,写给在java后端选择转方向的人 背景 看到一些java开发工程师,对java后端薪酬太悲观了.认为换去大数据领域就会高工资.觉得java后端没有前途.我 ...
- Java转大数据开发全套视频资料
大数据在近两年可算是特别火,有很多人都想去学大数据,有java转大数据的,零基础学习大数据的.但是大数据真的好学吗. 我们先来了解一下什么是大数据. 大数据是指无法在一定时间内用常规软件工具对其内容进 ...
- BAT推荐免费下载JAVA转型大数据开发全链路教程(视频+源码)价值19880元
如今随着环境的改变,物联网.AI.大数据.人工智能等,是未来的大趋势,而大数据是这些基石,万物互联,机器学习都是大数据应用场景! 为什么要学习大数据?我们JAVA到底要不要转型大数据? 好比问一个程序 ...
- Java转型大数据开发全套教程,都在这儿!
众所周知,很多语言技术已经在长久的历史发展中掩埋,这期间不同的程序员也走出的自己的发展道路. 有的去了解新的发展趋势的语言,了解新的技术,利用自己原先的思维顺利改变自己的title. 比如我自己,也都 ...
- 为什么说LAXCUS颠覆了我的大数据使用体验
切入正题前,先做个自我介绍. 本人是从业三年的大数据小码农一枚,在帝都一家有点名气的广告公司工作,同时兼着大数据管理员的职责. 平时主要的工作是配合业务部门,做各种广告大数据计算分析工作,然后制成各种 ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 大数据开发实战:离线大数据处理的主要技术--Hive,概念,SQL,Hive数据库
1.Hive出现背景 Hive是Facebook开发并贡献给Hadoop开源社区的.它是建立在Hadoop体系架构上的一层SQL抽象,使得数据相关人员使用他们最为熟悉的SQL语言就可以进行海量数据的处 ...
- FusionInsight大数据开发学习总结(1)
FusionInsight大数据开发 FusionInsight HD是一个大数据全栈商用平台,支持各种通用大数据应用场景. 技能需求 扎实的编程基础 Java/Scala/python/SQL/sh ...
随机推荐
- 896C
ODT/珂朵莉树 原来这个东西很咸鱼,只能数据随机情况下nloglogn,不过作为卡常还是很好的 大概就是维护区间,值相同的并且连续当成一个区间存在set里,每次区间操作强行分裂就行了. 复杂度因为是 ...
- 1.Win7中判断当前端口是否被占用
以Win7为例,可以用如下方法找出某个端口是否被其他进程占用:netstat -aon|findstr "8081" 发现8081端口被PID为5900的进程占用, tasklis ...
- 【转】Cache Buffer Chain 第二篇
文章转自:http://m.bianceng.cn/database/Oracle/201407/42884.htm 测试环境:版本11gR2 SQL> select * from v$vers ...
- java命令行从编译到打jar包到执行
目录: 一. javac编译 1. 没有额外的jar包 2. 包含额外的jar包 二. jar打jar包 三. java运行 1. java命令执行 2. jar包执 ...
- 1.3-1.4 hive环境部署
一. 官网:http://hive.apache.org/ 下载:http://archive.apache.org/dist/hive/ GitHub:https://github.com/apac ...
- monkey基本命令及脚本编写
Monkey 是Android自带的黑盒测试工具,一般通过随机触发界面事件,来确定应用是否会发生异常,多用于android应用的稳定性.压力测试 基本命令: adb shell monkey [op ...
- Flutter实战视频-移动电商-17.首页_楼层组件的编写技巧
17.首页_楼层组件的编写技巧 博客地址: https://jspang.com/post/FlutterShop.html#toc-b50 楼层的效果: 标题 stlessW快速生成: 接收一个St ...
- 内存、缓存、cpu之间的关系
一.缓存和内存 许多人认为,“缓存”是内存的一部分 许多技术文章都是这样教授的 但是还是有很多人不知道缓存在什么地方,缓存是做什么用的 其实,缓存是CPU的一部分,它存在于CPU中 CPU存取数据的速 ...
- 前端基础 之css
css 介绍 css(层叠样式表)定义如何显示html 元素 当浏览器读到一个样式表, 他就会按照这个表对文档进行格式化(渲染) css语法 css实例 css 注释 注释是代码之母 /* 这是注释* ...
- UVaLive 10859 Placing Lampposts (树形DP)
题意:给定一个无向无环图,要在一些顶点上放灯使得每条边都能被照亮,问灯的最少数,并且被两盏灯照亮边数尽量多. 析:其实就是一个森林,由于是独立的,所以我们可以单独来看每棵树,dp[i][0] 表示不在 ...