Windows下Tesseract4.0识别与中文手写字体训练
一 、 tesseract 4.0 安装及使用
1. tesseract 4.0 安装
安装包下载地址: http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
我在CSDN下载资源里也上传了一份: http://download.csdn.net/download/dcrmg/10021168
exe可执行文件直接安装,选择安装路径:
安装完成之后需要添加2个环境变量:
1. 把安装路径“C:\Program Files (x86)\Tesseract-OCR”添加到环境变量里,方便在命令行里直接调用;
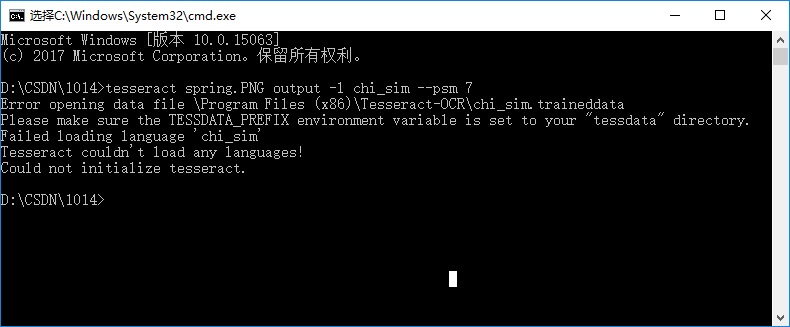
2. 把语言包所在路径“C:\Program Files (x86)\Tesseract-OCR\tessdata”添加到环境变量里,变量名称为“TESSDATA_PREFIX”,不添加语言包路径的话调用tesseract识别会报如下错误:
2. 简体中文语言包下载
语言包存放路径是在“C:\Program Files (x86)\Tesseract-OCR\tessdata”文件下,是一些后缀为“.traineddata”的文件,tesseract安装包里预装了英文识别语言包“eng.traineddata”,其他语言包需要下载后放到这个文件夹下。
简体中文语言包下载地址: https://github.com/tesseract-ocr/tessdata/find/master
名称是“chi_sim.traineddata”的是简体中文语言包,访问不了github的可以试试到这里下载: http://download.csdn.net/download/dcrmg/10021178
3. tesseract在命令行里的使用
在命令行里输入tesseract,查看:
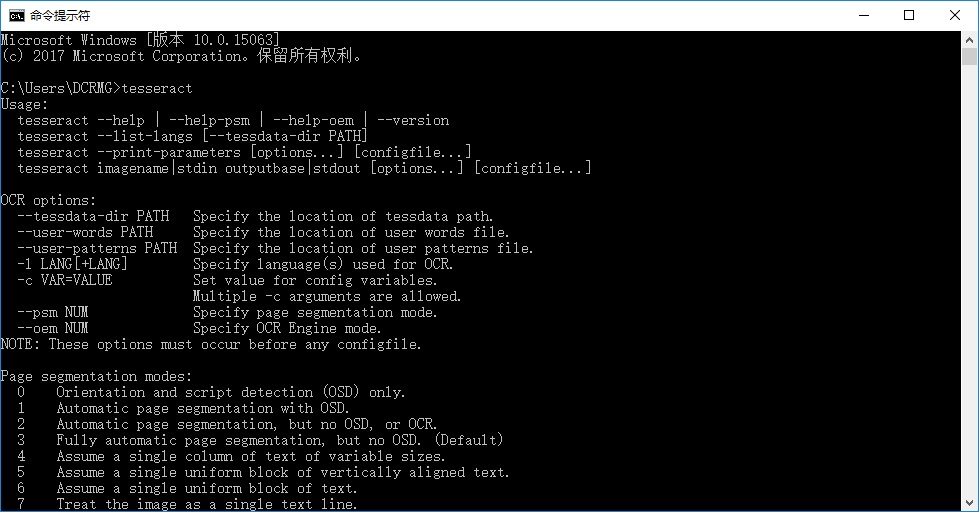
-l : 指定识别语言
--psm: 指定识别对象属性,如果要识别的图像中文字的分布是只有一行,就是用 “--psm 7”
对这个图像中微软雅黑字体的中文进行识别:

在图像文件所在目录下启动命令提示符,输入:
tesseract spring1.png output_sim -l chi_sim --psm 7
执行之后,图像中的文字都正确识别出来了:

测试对这个图像中同样文字的手写字体内容进行识别效果如何:

结果很差,只正确识别出来3个字:
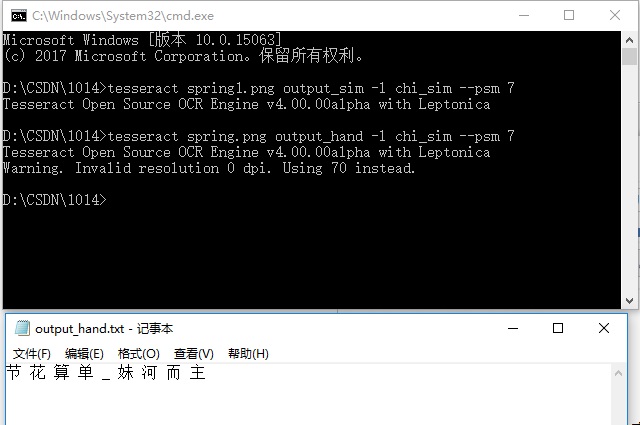
所以tesseract的中文语言包“chi_sim”对中文手写字体(或环境比较复杂的情况)的识别正确率不高,需要针对特定情况用自己的样本进行训练,提高识别率。
二、 jTessBoxEditor 和 java 下载安装
tesseract的训练需要使用到一个“.box”文件,相当于一个打标文件,记录了对应图片上各个文字的内容和位置,这个.box文件可以使用 “jTessBoxEditor”(这个东西是本人遇到过的有史以来最惨绝人寰、最惨无人道、最罄竹难书的东东~) 这个工具来进行调整,这个鬼东西的运行依赖于Java运行时环境,所以还得安装Java虚拟机。
1. Java虚拟机安装
java虚拟机 百度下载地址: http://rj.baidu.com/soft/detail/10463.html?ald
或: http://download.csdn.net/download/dcrmg/10021382
2. jTessBoxEditor 安装
jTessBoxEditor下载地址: https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
务必选择带FX的版本,才支持中文字符编辑:
安装包解压出来之后双击里边的“jTessBoxEditor.jar” (或者双击该文件夹下的 “train.bat” 脚本文件),如果前边安装了Java虚拟机,一般会弹出来如下对话框,选择 “Java(TM) Platform SE binary” 就行了:

jTessBoxEditor 打开之后长这个样子:
三、 使用 tesseract && JTessBoxEditor 执行手写体图片样本训练
1. 样本图片准备
理论上训练样本数量越多越好,这里作为训练流程的演示,对以上测试图片 “长花短草 贴河而立” 里边的8个字分别只准备了2种手写字体样本,如下:


截取的样本图片中最好不要有10个以上的字符样本,特别是在背景复杂的情况下,因为正常情况下tesseract分割出来的各个字符的位置和大小是不对的,需要使用jTessBoxEditor这个惨绝人寰的工具进行调整,单张图片中有过多的字符需要调整在jTessBoxEditor中的难度是成几何倍数增长的,Try it……
旧版的jTessBoxEditor只能处理后缀为 “.tif” 的图片,上文下载链接中提供的是2.0版本,可以处理 GPEG、PNG、BItmap等几乎所有格式的图片,不再需要对样本进行 “.tif” 格式的转化了。
以上2张训练图片分别命名为: spring1.PNG、spring2.PNG,存放路径在 “D:\CSDN\1014\samples” 下。
2. 使用 jTessBoxEditor 生成 训练样本的 “合并”(Merge)图片
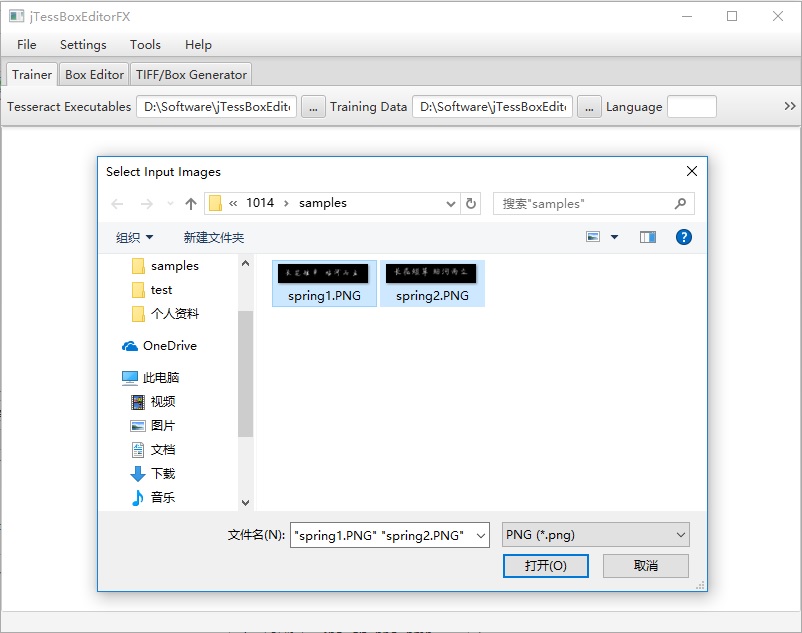
打开 jTessBoxEditor ,选择 Tools -> Merge TIFF,打开对话框,选择训练样本所在文件夹,并选中所有要参与训练的样本图片,注意对话框中“文件类型”的选取:
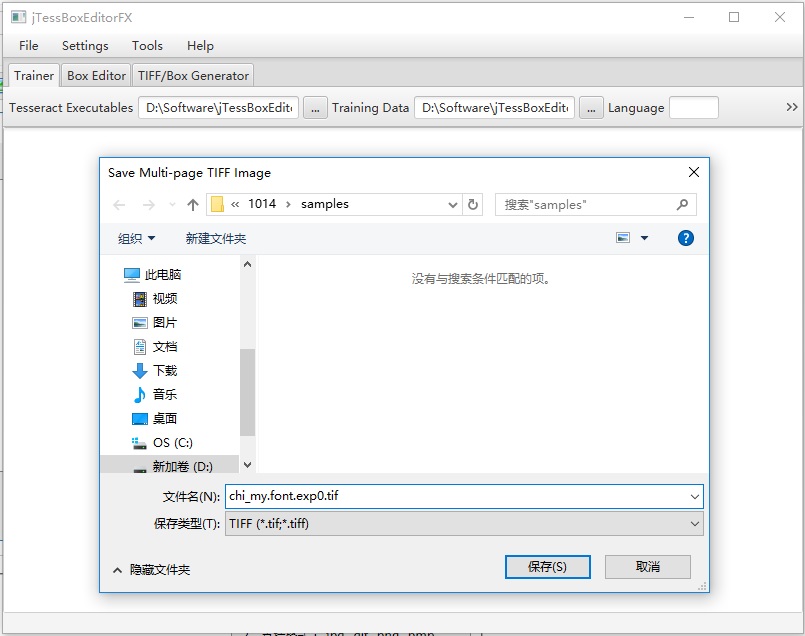
点击 “打开” 之后弹出保存对话框,还是选择在当前路径下保存,文件命名为 “chi_my.font.exp0.tif” ,格式只有一种 “TIFF” 可选:
点击 “保存” 之后在指定路径下生成所有样本的 “合并” 图片 chi_my.font.exp0.tif
3. 使用 tesseract 生成 .box 文件
在上一步骤中生成的 “chi_my.font.exp0.tif” 文件所在路径下打开命令行程序,执行以下命名:
tesseract chi_my.font.exp0.tif chi_my.font.exp0 -l chi_sim batch.nochop makebox
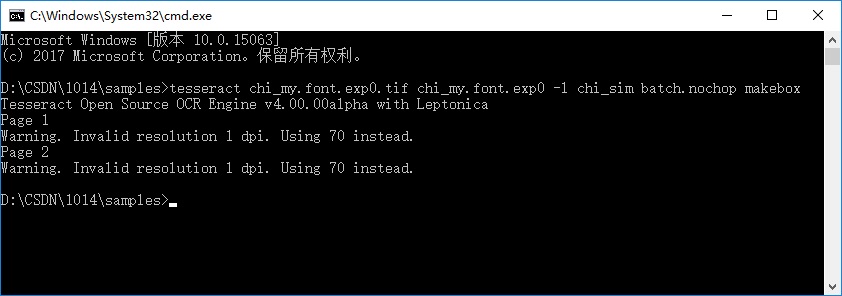
执行后在当前路径下生成 “chi_my.font.exp0.box” 文件
4. 使用 jTessBoxEditor 调整 .box 训练文件
“.box” 文件中记录了每个字符在图片上的位置以及识别出的内容,训练之前需要使用jTessBoxEditor调整字符的位置和内容。
打开 jTessBoxEditor ,点击 Box Editor -> Open ,打开步骤2中生成的 “chi_my.font.exp0.tif” ,会自动关联到 “chi_my.font.exp0.box”
文件:
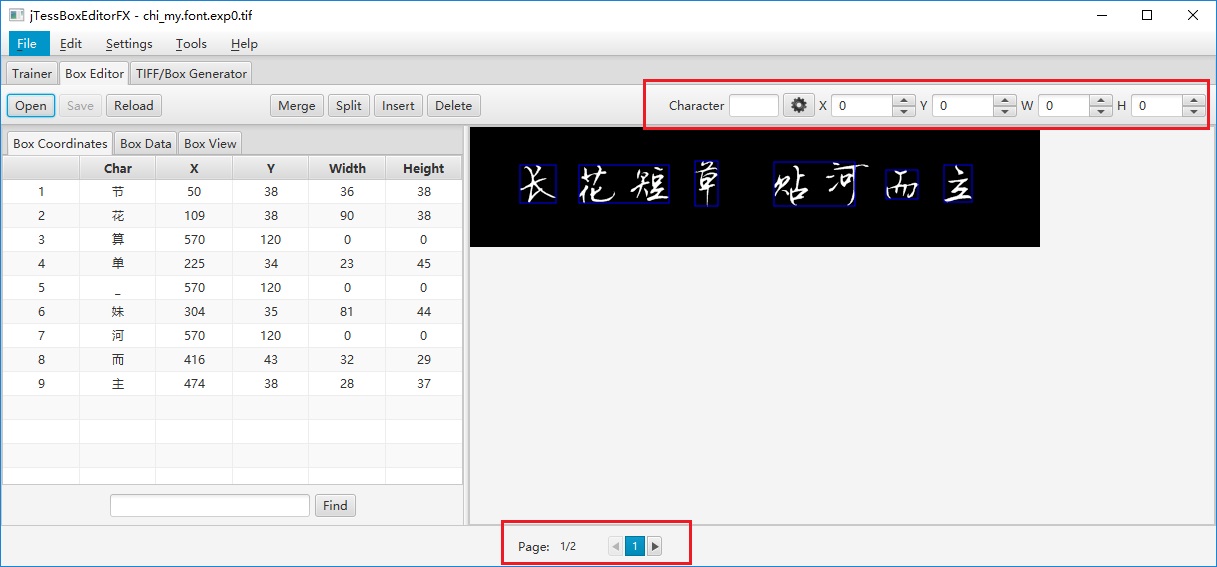
右上角红色方框内分别可以调整字符的内容、位置、宽高等,不带 “FX”版本的jTessBoxEditor还可以直接在方框内输入具体的数值,但不支持中文字符!…… 带 “FX” 版本的jTessBoxEditor支持中文字符,但是竟然不可以在方框内直接输入数值,需要一下一下点击方框右边的三角框!从600点到20是常有的事! 慢慢享受……
底部的红色方框内可以看到总的图片数量和当前编辑的张数,调整所有样本后点击 File -> Save as 另存为调整后的 “.box” 文件或Ctrl + S 原地保存。
5. 使用echo命令创建字体特征文件
在终端中执行以下命令:
echo font 0 0 0 0 0>font_properties
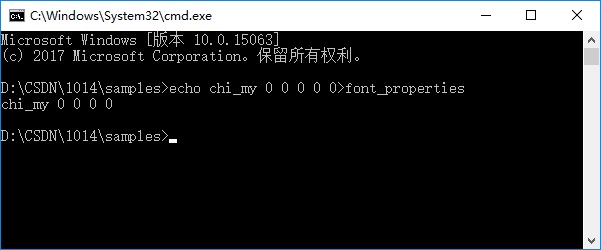
执行完成之后,在当前文件夹下生成font_properties文件
也可以手动在该文件夹下建立一个名为 “font_properties” 的文件,这个文件没有后缀名称,输入内容 “font 0 0 0 0 0” , 表示字体 font 的粗体、倾斜等共计5个属性全都设置为0
注意 : 这里输入的 “font” 名称必须与 “chi_my.font.exp0.box” 中两个点号之间的 “font” 名称保持一致。
在tesseract训练语言包的过程中,jTessBoxEditor的作用就是调整(位置和内容)tesseract生成的 “.box”文件,这个文件中列出了每个字符在图片上的位置以及内容。
6. 使用 tesseract 生成 chi_my.font.exp0.tr 训练文件
在终端中执行以下命名:
tesseract chi_my.font.exp0.tif chi_my.font.exp0 nobatch box.train
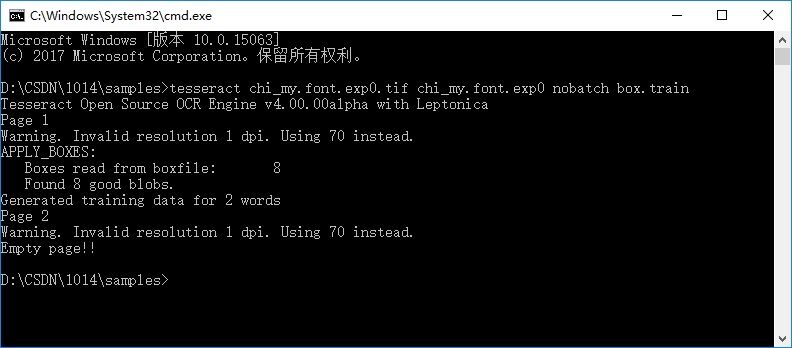
执行后在当前文件夹下生成 chi_ym.font.exp0.tr训练文件。
7. 生成字符集文件
在终端中执行以下命令:
unicharset_extractor chi_my.font.exp0.box
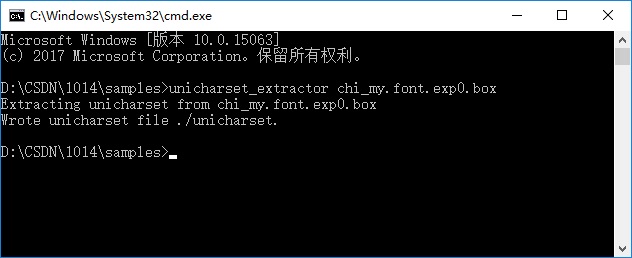
执行之后在当前文件夹下生成 “unicharset” 文件。
8. 生成字典数据
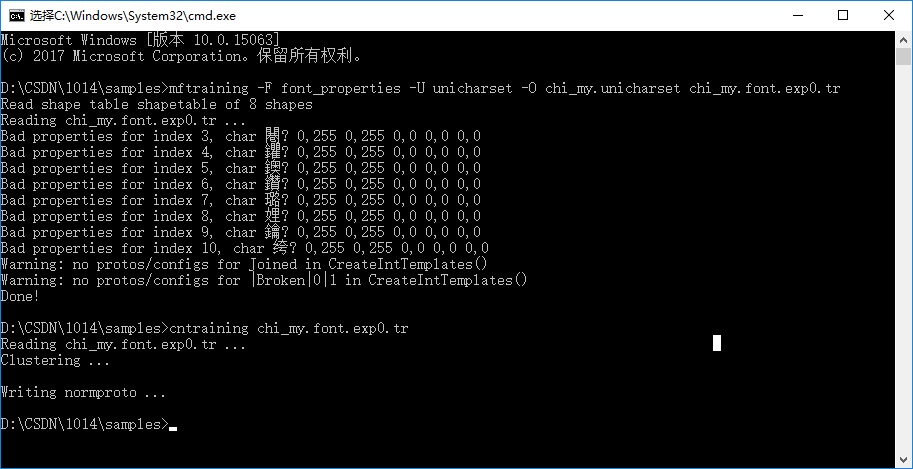
在终端中依次执行以下两条命名:
mftraining -F font_properties -U unicharset -O chi_my.unicharset chi_my.font.exp0.tr
cntraining chi_my.font.expo.tr
9. 合并数据文件
在终端中执行以下命令:
combine_tessdata chi_my.
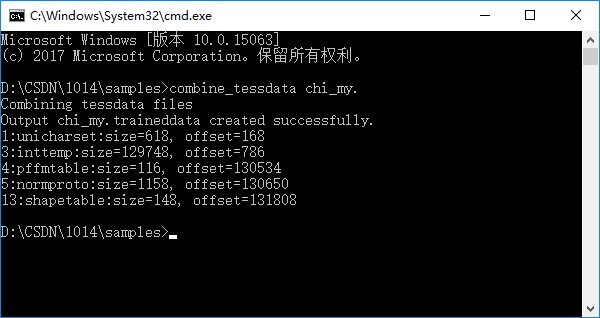
Log 输出中的 Offset 1、3、4、5、13 这些项不是 -1 ,表示新的语言包生成成功。
将生成的 “chi_my.traineddata” 语言包文件拷贝到 tessdata 目录下,就可以用它来进行中文字符识别了。
10. 验证训练生成的语言包
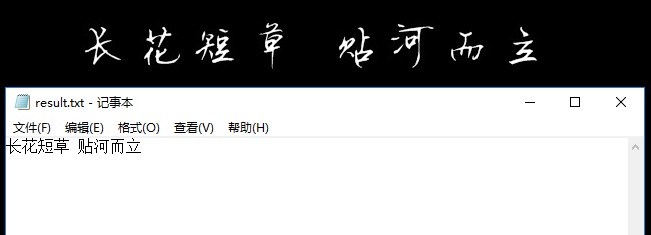
在终端中输入:
tesseract spring1.PNG result -l chi_my --psm 7
使用 “chi_sim” 语言包只可以正确识别3个字,使用新训练生成的 “chi_my” 都可以正确识别了:
Windows下Tesseract4.0识别与中文手写字体训练的更多相关文章
- [纯C#实现]基于BP神经网络的中文手写识别算法
效果展示 这不是OCR,有些人可能会觉得这东西会和OCR一样,直接进行整个字的识别就行,然而并不是. OCR是2维像素矩阵的像素数据.而手写识别不一样,手写可以把用户写字的笔画时间顺序,抽象成一个维度 ...
- 【OpenCV】opencv3.0中的SVM训练 mnist 手写字体识别
前言: SVM(支持向量机)一种训练分类器的学习方法 mnist 是一个手写字体图像数据库,训练样本有60000个,测试样本有10000个 LibSVM 一个常用的SVM框架 OpenCV3.0 中的 ...
- Windows Mobile 6.0 SDK和中文模拟器下载
[转] Windows Mobile 6.0 SDK和中文模拟器下载 Windows Mobile 6.5 模拟器 2010年12月06日 星期一 07:48 转载自 zhangyanle86 终于编 ...
- Windows下Git中正确显示中文的设置方法
Windows下Git中正确显示中文的设置方法 具体设置方法如下: 进入目录etc:$ cd /etc 1. 编辑 gitconfig 文件:$ vi gitconfig.在其中增加如下内容: [gu ...
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
- 深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版 这是tf入门的第一个例子.minst应该是内置的数据集. 前置知识在学习笔记(1)里面讲过了 这里直接上代码 # -*- ...
- 基于kNN的手写字体识别——《机器学习实战》笔记
看完一节<机器学习实战>,算是踏入ML的大门了吧!这里就详细讲一下一个demo:使用kNN算法实现手写字体的简单识别 kNN 先简单介绍一下kNN,就是所谓的K-近邻算法: [作用原理]: ...
- 深度学习---手写字体识别程序分析(python)
我想大部分程序员的第一个程序应该都是“hello world”,在深度学习领域,这个“hello world”程序就是手写字体识别程序. 这次我们详细的分析下手写字体识别程序,从而可以对深度学习建立一 ...
- 机器学习之路: python 支持向量机 LinearSVC 手写字体识别
使用python3 学习sklearn中支持向量机api的使用 可以来到我的git下载源代码:https://github.com/linyi0604/MachineLearning # 导入手写字体 ...
随机推荐
- 【grpc】spring boot+grpc的使用
spring boot+grpc的使用 参考:https://baijiahao.baidu.com/s?id=1573961922096412&wfr=spider&for=pc
- Pixhawk之姿态解算篇(1)_入门篇(DCM Nomalize)
一.开篇 慢慢的.慢慢的.慢慢的就快要到飞控的主要部分了,飞控飞控就是所谓的飞行控制呗,一个是姿态解算一个是姿态控制,解算是解算,控制是控制,各自负责各自的任务.我也不懂.还在学习中~~~~ 近期看姿 ...
- fast-cgi & php-fpm 等的理解
原文地址:https://segmentfault.com/q/1010000000256516 网上有的说,fastcgi是一个协议,php-fpm实现了这个协议: 有的说,php-fpm是fast ...
- Upgrade to postgresql 9.5
Add postgresql apt repo.. according to your distribution (utopic, trusty, jessie, wheezy and etc ...
- Solaris Samba服务器与DNS服务
用于文件传输的协议,类似于ftp,ssh,只是它比其他两个好用. Samba协议 NetBIOS :一种编程接口. SMB:server message block .主要作为Microsoft网络通 ...
- mvc用UpdateModel报错
项目中使用UpdateModel时报错:未能更新类型“XXXXXX”的模型. 原因如下:表单Post时,有的参数为空,如a=1&b=2&=3.
- 剖析CPU温度监控技术
转载 :剖析CPU温度监控技术 标签: CPU 温度控制技术 1805 具体温度检测调整代码(转载) 迄今为止还没有一种cpu散热系统能保证永不失效.失去了散热系统保护伞的“芯”,往 ...
- Ubuntu16.04上安装mongoDB
安装MongoDB 现在最新版本是3.4 1: sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 0C49F37303 ...
- POI-----POI操作Excel-4、字体
- Android对apk源代码的改动--反编译+源代码改动+又一次打包+签名【附HelloWorld的改动实例】
最近遇到了须要改动apk源代码的问题,于是上网查了下相关资料.编写了HelloWorld进行改动看看可行性,经过实验证明此方案可行,而且后来也成功用这种方法对目标apk进行了改动,仅仅只是须要改动的部 ...