Scrapy实战-新浪网分类资讯爬虫
项目要求:
爬取新浪网导航页所有下所有大类、小类、小类里的子链接,以及子链接页面的新闻内容。
什么是Scrapy框架:
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求.
Scrapy架构图
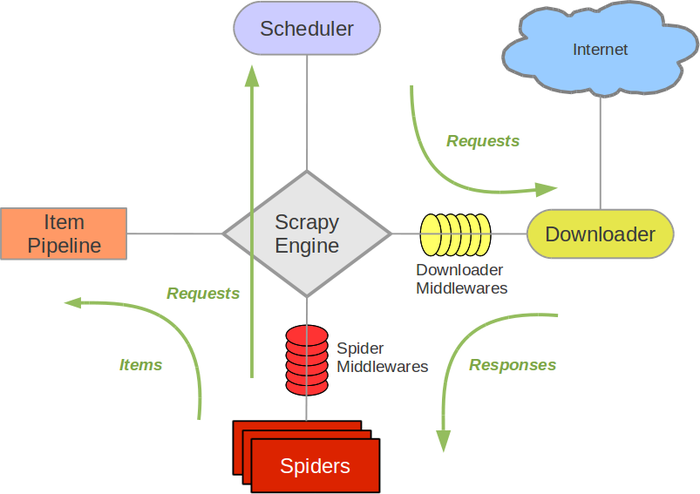
制作Scrapy爬虫需要4个步骤:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
开始实战:
新建Scrapy项目
进入终端后,cd进入自定义的目录中,运行以下命令
scrapy startproject sina
成功创建项目

明确目标(编写items.py)明确你想要抓取的目标
接下来需要明确抓取的目标,编写爬虫
打开mySpider目录下的items.py,该文件下已自动为我们创建好scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item(可以理解成类似于ORM的映射关系)。
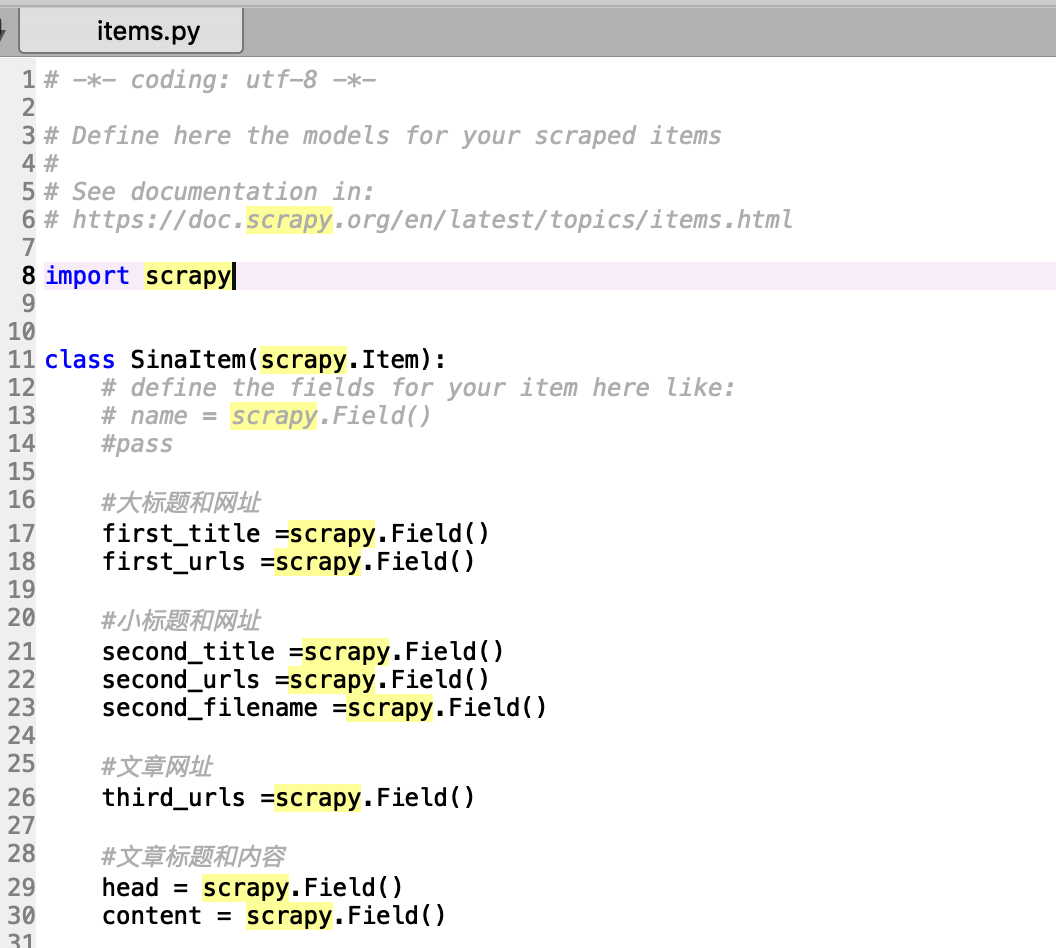
2.接下来,修改已创建好的SinaItem类,构建item模型(model)。
制作爬虫 (spiders/xxspider.py)
第三步就开始制作爬虫开始爬取网页
- 在当前目录下输入命令,将在sina/
sina/spiders目录下创建一个名为sina_guide的爬虫,并指定爬取域的范围:
scrapy genspider sina_guide 'sina.com'

- 打开sina_guide.py文件,爬虫类也已创建好,默认爬虫名为‘sina_guide’,爬取范围为sina.com,起始网址为‘http://sina.com/’(需修改)

- 需要修改起始网址为 http://news.sina.com.cn/guide/,该导航网址下有众多一级标题,又细分为众多二级标题

- 爬取所有大类标题及小类标题,右键点击‘审查元素’,可定位到该元素的地址,提取出XPATH地址(可使用xpath helper插件帮助定位生成)
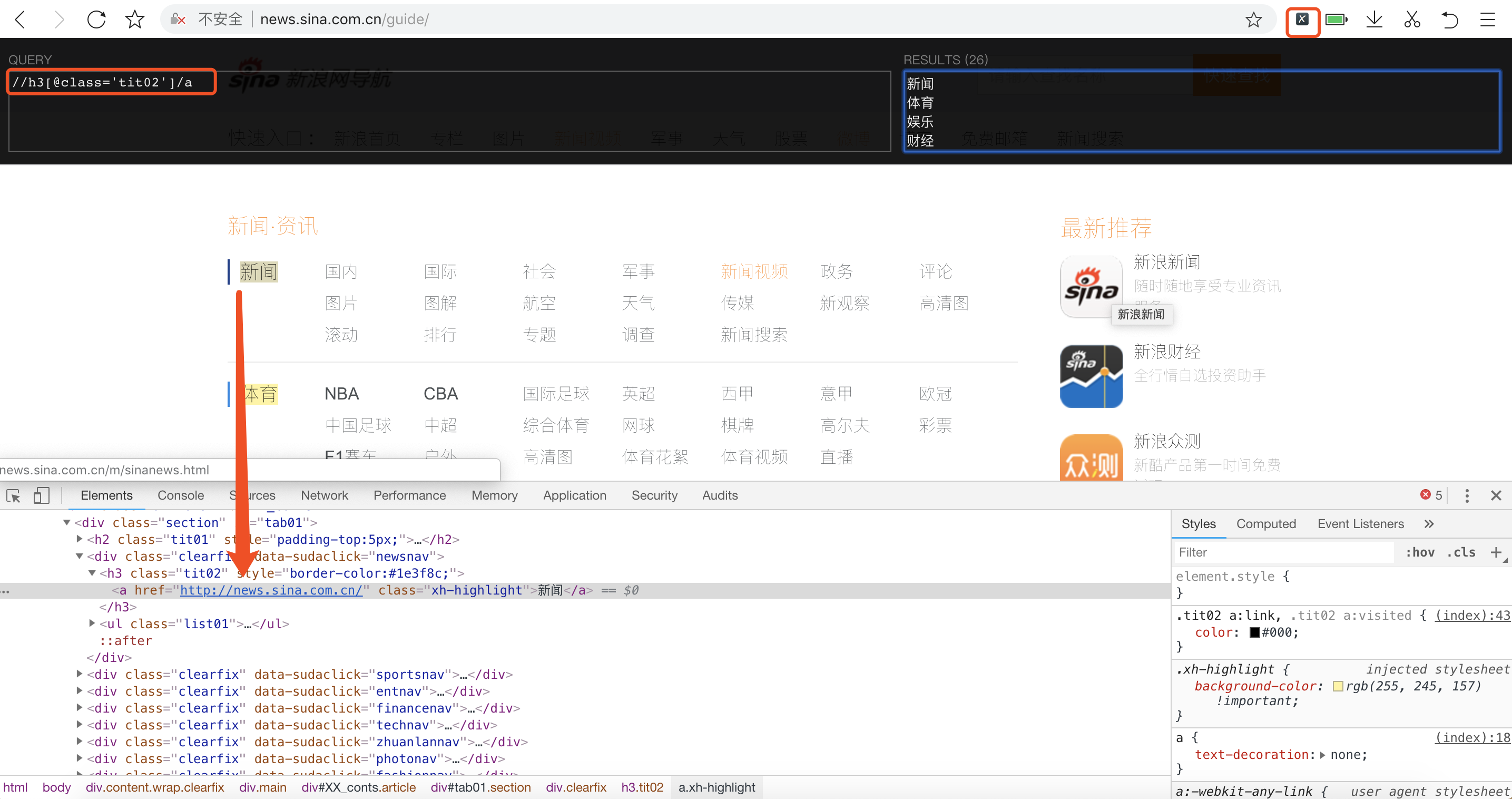
def parse(self, response):
#items =[]
#所有大类标题和网址
first_title = response.xpath("//h3[@class='tit02']/a/text()").extract()
first_urls = response.xpath("//h3[@class='tit02']//@href").extract() #所有小类标题和网址
second_title = response.xpath("//ul[@class='list01']/li/a/text()").extract()
second_urls = response.xpath("//ul[@class='list01']/li/a/@href").extract()
- 根据爬取到的标题名分层创建文件夹,
- 创建大类标题文件夹
def parse(self, response):
#items =[]
#所有大类标题和网址
first_title = response.xpath("//h3[@class='tit02']/a/text()").extract()
first_urls = response.xpath("//h3[@class='tit02']//@href").extract() #所有小类标题和网址
second_title = response.xpath("//ul[@class='list01']/li/a/text()").extract()
second_urls = response.xpath("//ul[@class='list01']/li/a/@href").extract() #爬取大类并指定文件路径
for i in range(0,len(first_title)): item =SinaItem() #指定大类工作路径和文件名
first_filename = "/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA" + '/' + first_title[i] #if判断,防止重复创建
#创建大类文件夹
if (not os.path.exists(first_filename)):
os.makedirs(first_filename) #保存大类的标题和网址
item['first_title'] = first_title[i]
item['first_urls'] = first_urls[i]
- 创建二级标题文件夹
#爬取小类标题并指定文件路径
for j in range(0,len(second_urls)): if second_urls[j].startswith(first_urls[i]):
second_filename =first_filename +'/'+ second_title[j] #if判断,防止重复创建文件夹
#创建文件夹,指定小类工作路径和文件名
if (not os.path.exists(second_filename)):
os.makedirs(second_filename) #保存小类标题和网址
item['second_title'] = second_title[j]
item['second_urls'] = second_urls[j]
item['second_filename']=second_filename #items.append(item) b_filename =r"/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA/111.txt"
with open (b_filename,'a+') as b:
b.write(item['second_filename']+'\t'+item['second_title']+'\t'+item['second_urls']+'\n') #发送每个小类url的Request请求,得到Response连同包含meta数据 一同交给回调函数 second_parse 方法处理
#for item in items:
yield scrapy.Request(url = item['second_urls'],meta={'meta_1':copy.deepcopy(item)},callback=self.second_parse) #b_filename =r"/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA/222.txt"
#with open (b_filename,'a+') as b:
# b.write(item['second_filename']+'\t'+item['second_title']+'\n') def second_parse(self,response):
item = response.meta['meta_1']
third_urls =response.xpath('//a/@href').extract() #items =[] for i in range(0,len(third_urls)): #检查每个链接是否以大类网址开头,shtml结束,结果返回TRue
if_belong = third_urls[i].startswith(item['first_urls']) and third_urls[i].endswith('shtml')
if (if_belong):
'''
item = SinaItem()
item['first_title'] = meta_1['first_title']
item['first_urls'] = meta_1['first_urls']
item['second_title'] = meta_1['second_title']
item['second_urls'] = meta_1['second_urls']
item['second_filename']=meta_1['second_filename']
'''
item['third_urls'] =third_urls[i]
yield scrapy.Request(url=item['third_urls'],meta={'meta_2':copy.deepcopy(item)},
callback = self.detail_parse)
#items.append(item) b_filename =r"/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA/222.txt"
with open (b_filename,'a+') as b:
b.write(item['second_filename']+'\t'+item['second_title']+'\t'+item['second_urls']+'\n')
- 创建完成后即可得到文件夹按标题分类创建
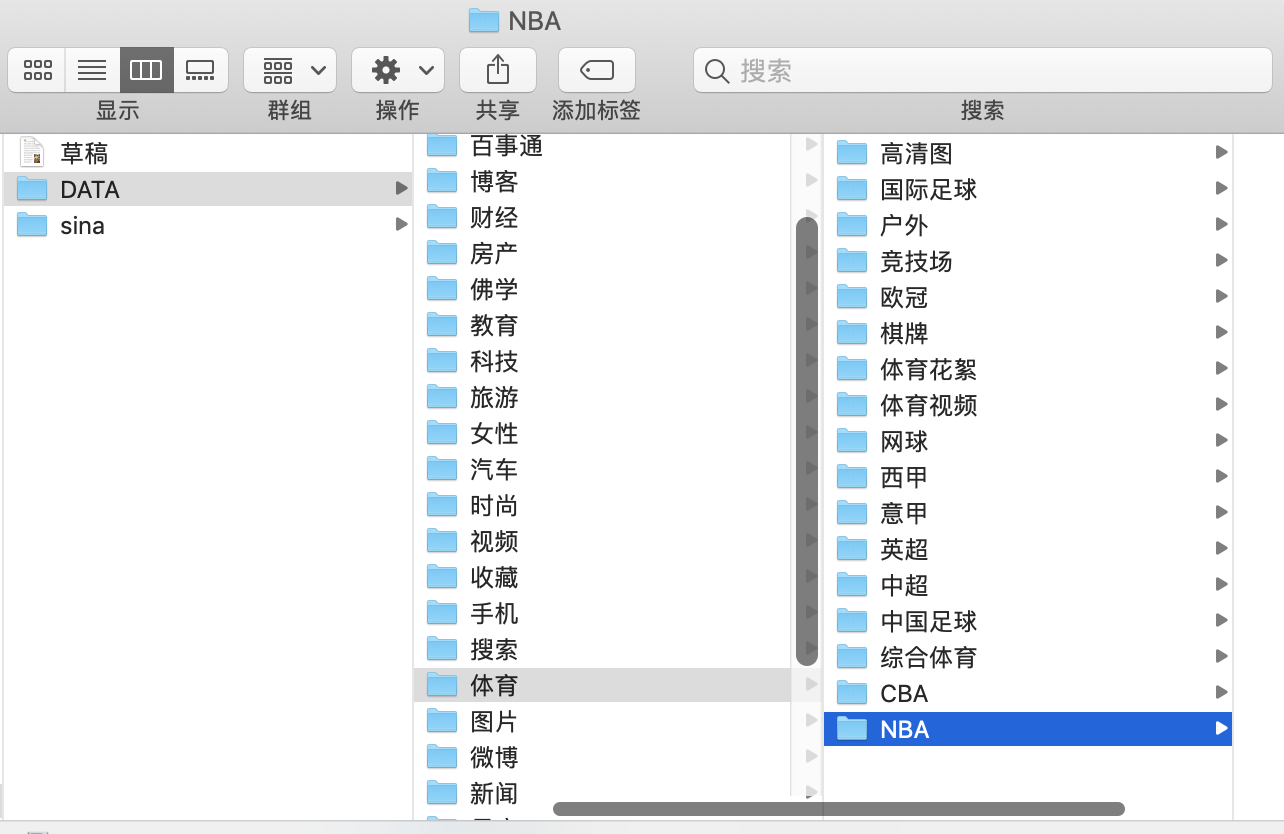
- 创建文件夹后,便需要对内容进行采集并按文件夹存放

def detail_parse(self,response):
item =response.meta['meta_2'] #抓取标题
head = response.xpath("//li[@class='item']//a/text() | //title/text()").extract()[0]
#抓取的内容返回列表
content =""
content_list = response.xpath('//div[@id=\"artibody\"]/p/text()').extract()
for i in content_list:
content += i
content = content.replace('\u3000','') item['head']=head
item['content'] =content yield item b_filename =r"/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA/333.txt"
with open (b_filename,'a+') as b:
b.write(item['second_filename']+'\t'+item['second_title']+'\t'+item['second_urls']+'\n')
存储内容 (pipelines.py)
配置pipelines.py
import random class SinaPipeline(object):
def process_item(self, item, spider):
# head=item['head']
# filename ='/' + str(random.randint(1,100))+r'.txt'
# f = open(item['second_filename']+filename,'w')
f = open(item['second_filename'] + '/' + item['head']+r'.txt','w')
f.write(item['content'])
f.close() b_filename =r"/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA/444.txt"
with open (b_filename,'a') as b:
b.write(item['second_filename']+'\t'+item['second_title']+'\t'+item['second_urls']+'\n') return item
在终端执行爬虫文件:
scrapy crawl sina_guide
完
附上完整sina_guide.py以供参考:
# -*- coding: utf-8 -*- ####注意scrapy.Request中meta参数深拷贝的问题!!!!!!!
#https://blog.csdn.net/qq_41020281/article/details/83115617
import copy
#import os
#os.chdir('/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/sina/sina')
import sys
sys.path.append('/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/sina')
#print(sys.path) import scrapy
import os
from sina.items import SinaItem class SinaGuideSpider(scrapy.Spider):
name = 'sina_guide'
allowed_domains = ['sina.com.cn']
start_urls = ['http://news.sina.com.cn/guide/'] def parse(self, response):
#items =[]
#所有大类标题和网址
first_title = response.xpath("//h3[@class='tit02']/a/text()").extract()
first_urls = response.xpath("//h3[@class='tit02']//@href").extract() #所有小类标题和网址
second_title = response.xpath("//ul[@class='list01']/li/a/text()").extract()
second_urls = response.xpath("//ul[@class='list01']/li/a/@href").extract() #爬取大类并指定文件路径
for i in range(0,len(first_title)): item =SinaItem() #指定大类工作路径和文件名
first_filename = "/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA" + '/' + first_title[i] #if判断,防止重复创建
#创建大类文件夹
if (not os.path.exists(first_filename)):
os.makedirs(first_filename) #保存大类的标题和网址
item['first_title'] = first_title[i]
item['first_urls'] = first_urls[i] #爬取小类标题并指定文件路径
for j in range(0,len(second_urls)): if second_urls[j].startswith(first_urls[i]):
second_filename =first_filename +'/'+ second_title[j] #if判断,防止重复创建文件夹
#创建文件夹,指定小类工作路径和文件名
if (not os.path.exists(second_filename)):
os.makedirs(second_filename) #保存小类标题和网址
item['second_title'] = second_title[j]
item['second_urls'] = second_urls[j]
item['second_filename']=second_filename #items.append(item) b_filename =r"/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA/111.txt"
with open (b_filename,'a+') as b:
b.write(item['second_filename']+'\t'+item['second_title']+'\t'+item['second_urls']+'\n') #发送每个小类url的Request请求,得到Response连同包含meta数据 一同交给回调函数 second_parse 方法处理
#for item in items:
yield scrapy.Request(url = item['second_urls'],meta={'meta_1':copy.deepcopy(item)},callback=self.second_parse) #b_filename =r"/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA/222.txt"
#with open (b_filename,'a+') as b:
# b.write(item['second_filename']+'\t'+item['second_title']+'\n') def second_parse(self,response):
item = response.meta['meta_1']
third_urls =response.xpath('//a/@href').extract() #items =[] for i in range(0,len(third_urls)): #检查每个链接是否以大类网址开头,shtml结束,结果返回TRue
if_belong = third_urls[i].startswith(item['first_urls']) and third_urls[i].endswith('shtml')
if (if_belong):
'''
item = SinaItem()
item['first_title'] = meta_1['first_title']
item['first_urls'] = meta_1['first_urls']
item['second_title'] = meta_1['second_title']
item['second_urls'] = meta_1['second_urls']
item['second_filename']=meta_1['second_filename']
'''
item['third_urls'] =third_urls[i]
yield scrapy.Request(url=item['third_urls'],meta={'meta_2':copy.deepcopy(item)},
callback = self.detail_parse)
#items.append(item) b_filename =r"/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA/222.txt"
with open (b_filename,'a+') as b:
b.write(item['second_filename']+'\t'+item['second_title']+'\t'+item['second_urls']+'\n') #for item in items: def detail_parse(self,response):
item =response.meta['meta_2'] #抓取标题
head = response.xpath("//li[@class='item']//a/text() | //title/text()").extract()[0]
#抓取的内容返回列表
content =""
content_list = response.xpath('//div[@id=\"artibody\"]/p/text()').extract()
for i in content_list:
content += i
content = content.replace('\u3000','') item['head']=head
item['content'] =content yield item b_filename =r"/Users/jvf/Downloads/数据分析/练习/0715-新浪网导航/DATA/333.txt"
with open (b_filename,'a+') as b:
b.write(item['second_filename']+'\t'+item['second_title']+'\t'+item['second_urls']+'\n')
Scrapy实战-新浪网分类资讯爬虫的更多相关文章
- 爬虫笔记八——Scrapy实战项目
(案例一)手机App抓包爬虫 1. items.py import scrapy class DouyuspiderItem(scrapy.Item): # 存储照片的名字 nickName = sc ...
- Python分布式爬虫开发搜索引擎 Scrapy实战视频教程
点击了解更多Python课程>>> Python分布式爬虫开发搜索引擎 Scrapy实战视频教程 课程目录 |--第01集 教程推介 98.23MB |--第02集 windows下 ...
- 以豌豆荚为例,用 Scrapy 爬取分类多级页面
本文转载自以下网站:以豌豆荚为例,用 Scrapy 爬取分类多级页面 https://www.makcyun.top/web_scraping_withpython17.html 需要学习的地方: 1 ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- python scrapy版 极客学院爬虫V2
python scrapy版 极客学院爬虫V2 1 基本技术 使用scrapy 2 这个爬虫的难点是 Request中的headers和cookies 尝试过好多次才成功(模拟登录),否则只能抓免费课 ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- scrapy实战--登陆人人网爬取个人信息
今天把scrapy的文档研究了一下,感觉有点手痒,就写点东西留点念想吧,也做为备忘录.随意写写,看到的朋友觉得不好,不要喷我哈. 创建scrapy工程 cd C:\Spider_dev\app\scr ...
- 使用scrapy框架做赶集网爬虫
使用scrapy框架做赶集网爬虫 一.安装 首先scrapy的安装之前需要安装这个模块:wheel.lxml.Twisted.pywin32,最后在安装scrapy pip install wheel ...
随机推荐
- 根据日期计算发布时间段(NSCalendar)
// 返回发布时间dateWithString - (NSString *)backReleaseTimeWithDateStr:(NSString *)dateWithString{ // 获取当前 ...
- TYVJ 2032 搜索
P2032 「Poetize9」升降梯上 描述 开启了升降梯的动力之后,探险队员们进入了升降梯运行的那条竖直的隧道,映入眼帘的是一条直通塔顶的轨道.一辆停在轨道底部的电梯.和电梯内一杆控制电梯升降的巨 ...
- Technocup 2017 - Elimination Round 1 (Unofficially Open for Everyone, Rated for Div. 2) A
Vasily has a number a, which he wants to turn into a number b. For this purpose, he can do two types ...
- siege官方文档(译)(二)
WHY DO I NEED IT? Siege was written for both web developers and web systems administrators. siege是为了 ...
- asp.net中,跳转页面的几种方式
js方式的页面跳转1.window.location.href方式 <script language="javascript" type="text/java ...
- ASP.NET Cookie的登录验证
做用户登录,我一直用form验证的方式.有时候,为了节省时间,用户希望用户名输入框能够记住用户名,省得下次重新输入.这个时候光用form验证是不行的,因为form验证的话,用户一退出系统就失效了,所以 ...
- Flask 学习系列(一) -登录
Flask是一个使用 Python 编写的轻量级 Web 应用框架.其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 .Flask使用 BSD 授权. Flask也被称为 “ ...
- WPF MATERAIL DESIGN TOOKIT
最近有个程序需要用到WPF,本以为WEB可以做到很炫的,没有想到XAML也能做到如此之炫.心动了,那就行动吧. 搜到有各种款式的:METRO风格,RIBBON风格,MATERIAL风格…… 也许是玩W ...
- 《Head First HTML与CSS》项目实践中学到的东西
1.组织的重要性. 首先是要建立两个根文件夹,一个存上线页面的资源,一个存测试页面的资源.所有改动内容都在测试页面的文件夹中进行,在这个文件夹中进行测试.W3C语法检测后(HTML检测网站:https ...
- Somethings about Floors题解
题目内容:一个楼梯有N级(N >=0), 每次走1级或2级, 从底走到顶一共有多少种走法? 输入要求:只有一行输入,并且只有一个数N(如果N > 20,则N = N%21,即保证N的范围控 ...