Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送--Spark入门实战系列》获取
、编译Spark
、时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 2、maven下载大文件是多线程进行,而SBT是单进程),Maven编译成功前后花了3、4个小时。
1.1 编译Spark(SBT)
1.1.1 安装git并编译安装
1. 从如下地址下载git安装包
http://www.onlinedown.net/softdown/169333_2.htm
https://www.kernel.org/pub/software/scm/git/
如果linux是CentOS操作系统可以通过:yum install git直接进行安装
由于从https获取内容,需要安装curl-devel,可以从如下地址获取
http://rpmfind.net/linux/rpm2html/search.php?query=curl-devel
如果linux是CentOS操作系统可以通过:yum install curl-devel直接进行安装
2. 上传git并解压缩
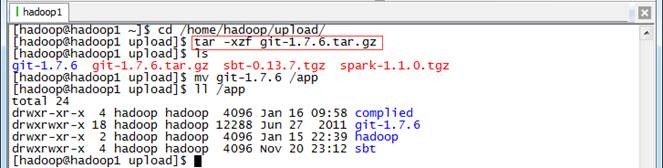
把git-1.7.6.tar.gz安装包上传到/home/hadoop/upload目录中,解压缩然后放到/app目录下
$cd /home/hadoop/upload/
$tar -xzf git-1.7.6.tar.gz
$mv git-1.7.6 /app
$ll /app
3. 编译安装git
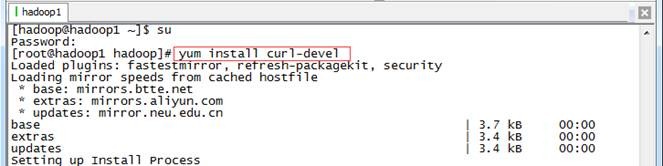
以root用户进行在git所在路径编译安装git
#yum install curl-devel
#cd /app/git-1.7.6
#./configure
#make
#make install


4. 把git加入到PATH路径中
打开/etc/profile把git所在路径加入到PATH参数中
export GIT_HOME=/app/git-1.7.6
export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$GIT_HOME/bin

重新登录或者使用source /etc/profile使参数生效,然后使用git命令查看配置是否正确
1.1.2 下载Spark源代码并上传
1. 可以从如下地址下载到spark源代码:
http://spark.apache.org/downloads.html
http://d3kbcqa49mib13.cloudfront.net/spark-1.1.0.tgz
git clone https://github.com/apache/spark.git
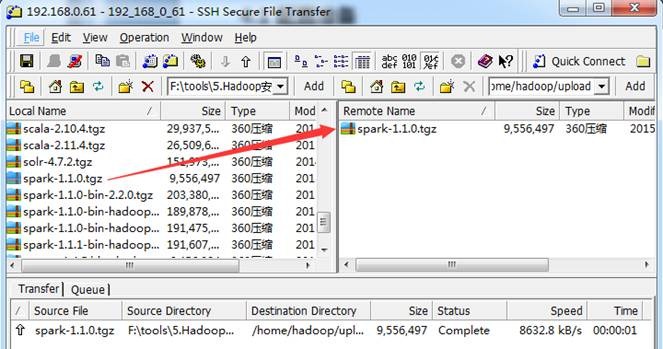
把下载好的spark-1.1.0.tgz源代码包使用1.1.3.1介绍的工具上传到/home/hadoop/upload 目录下
2. 在主节点上解压缩
$cd /home/hadoop/upload/
$tar -xzf spark-1.1.0.tgz

3. 把spark-1.1.0改名并移动到/app/complied目录下
$mv spark-1.1.0 /app/complied/spark-1.1.0-sbt
$ls /app/complied

1.1.3 编译代码
编译spark源代码的时候,需要从网上下载依赖包,所以整个编译过程机器必须保证在联网状态。编译执行如下脚本:
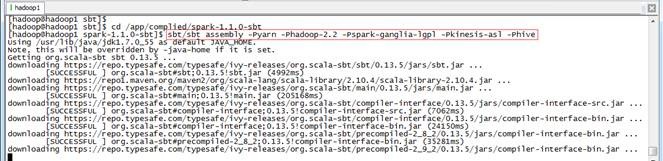
$cd /app/complied/spark-1.1.0-sbt
$sbt/sbt assembly -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -Pkinesis-asl -Phive

整个编译过程编译了约十几个任务,重新编译N次,需要几个甚至十几个小时才能编译完成(主要看下载依赖包的速度)。
1.2 编译Spark(Maven)
1.2.1 安装Maven并配置参数
在编译前最好安装3.0以上版本的Maven,在/etc/profile配置文件中加入如下设置:
export MAVEN_HOME=/app/apache-maven-3.0.5
export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$GIT_HOME/bin

1.2.2 下载Spark源代码并上传
1. 可以从如下地址下载到spark源代码:
http://spark.apache.org/downloads.html
http://d3kbcqa49mib13.cloudfront.net/spark-1.1.0.tgz
git clone https://github.com/apache/spark.git
把下载好的spark-1.1.0.tgz源代码包使用1.1.3.1介绍的工具上传到/home/hadoop/upload 目录下
2. 在主节点上解压缩
$cd /home/hadoop/upload/
$tar -xzf spark-1.1.0.tgz

3. 把spark-1.1.0改名并移动到/app/complied目录下
$mv spark-1.1.0 /app/complied/spark-1.1.0-mvn
$ls /app/complied

1.2.3 编译代码
编译spark源代码的时候,需要从网上下载依赖包,所以整个编译过程机器必须保证在联网状态。编译执行如下脚本:
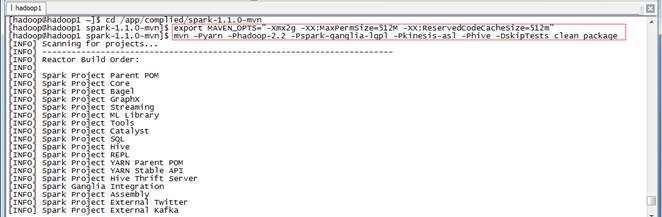
$cd /app/complied/spark-1.1.0-mvn
$export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
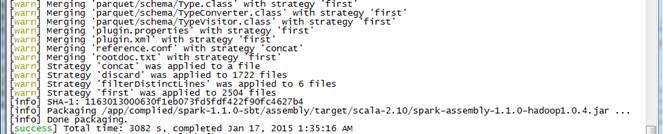
$mvn -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -Pkinesis-asl -Phive -DskipTests clean package
个任务,整个过程耗时1小时45分钟。

1.3 生成Spark部署包
在Spark源码根目录下有一个生成部署包的脚本make-distribution.sh,可以通过执行如下命令进行打包 ./make-distribution.sh [--name] [--tgz] [--with-tachyon] <maven build options>
l --name NAME和--tgz 结合可以生成spark-$VERSION-bin-$NAME.tgz 的部署包,不加此参数时NAME 为hadoop 的版本号
l --tgz在根目录下生成 spark-$VERSION-bin.tgz ,不加此参数时不生成tgz 文件,只生成/dist 目录
l --with-tachyon 是否支持内存文件系统Tachyon ,不加此参数时不支持tachyon
例子:
1. 生成支持yarn 、hadoop2.2.0 、hive 的部署包:
./make-distribution.sh --tgz --name 2.2.0 -Pyarn -Phadoop-2.2 -Phive
2. 生成支持yarn 、hadoop2.2.0 、hive 、ganglia 的部署包:
./make-distribution.sh --tgz --name 2.2.0 -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -P hive
1.3.1 生成部署包
使用如下命令生成Spark部署包,由于该脚本默认在JDK1.6进行,在开始时会进行询问是否继续,只要选择Y即可
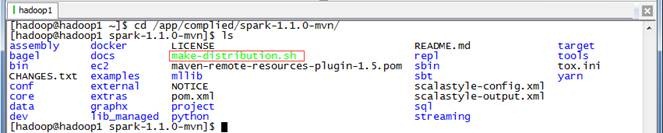
$cd /app/complied/spark-1.1.0-mvn/
$./make-distribution.sh --tgz --name 2.2.0 -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -P hive
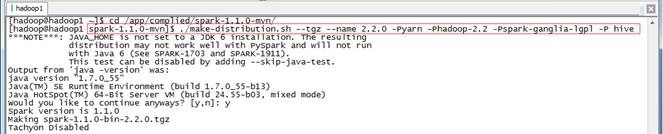
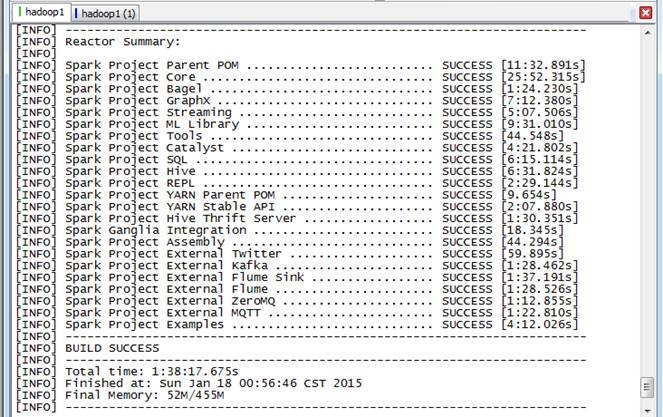
个任务,用时大概1小时38分钟。
1.3.2 查看生成结果
生成在部署包位于根目录下,文件名类似于spark-1.1.0-bin-2.2.0.tgz。
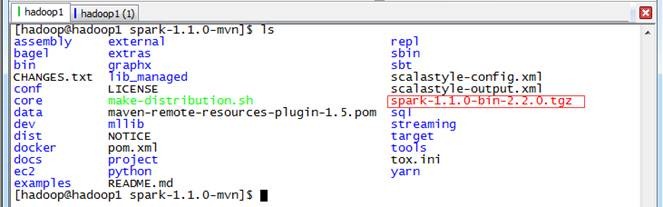
、安装Spark
2.1 上传并解压Spark安装包
位hadoop安装包),使用"Spark编译与部署(上)"中1. 3.1介绍的工具上传到/home/hadoop/upload 目录下
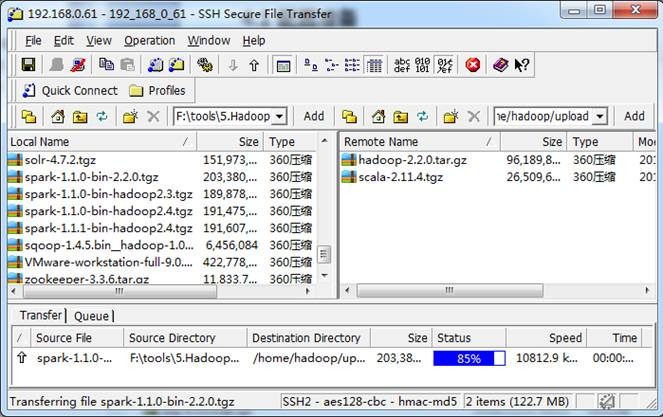
2. 在主节点上解压缩
$cd /home/hadoop/upload/
$tar -xzf spark-1.1.0-bin-2.2.0.tgz
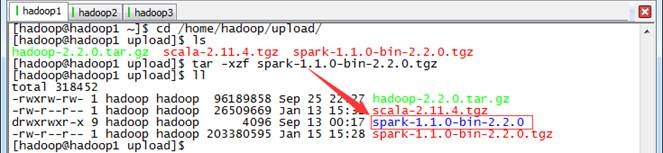
3. 把spark改名并移动到/app/hadoop目录下
$mv spark-1.1.0-bin-2.2.0 /app/hadoop/spark-1.1.0
$ll /app/hadoop

2.2 配置/etc/profile
1. 打开配置文件/etc/profile
$sudo vi /etc/profile
2. 定义SPARK_HOME并把spark路径加入到PATH参数中
SPARK_HOME=/app/hadoop/spark-1.1.0
PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
2.3 配置conf/slaves
1. 打开配置文件conf/slaves
$cd /app/hadoop/spark-1.1.0/conf
$sudo vi slaves

2. 加入slave配置节点
hadoop1
hadoop2
hadoop3

2.4 配置conf/spark-env.sh
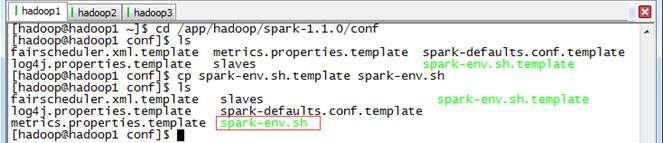
1. 打开配置文件conf/spark-env.sh
$cd /app/hadoop/spark-1.1.0/conf
$cp spark-env.sh.template spark-env.sh
$sudo vi spark-env.sh
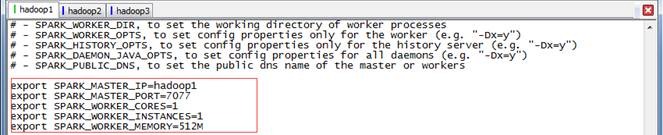
2. 加入Spark环境配置内容,设置hadoop1为Master节点
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=512M
2.5 向各节点分发Spark程序
1. 进入hadoop1机器/app/hadoop目录,使用如下命令把spark文件夹复制到hadoop2和hadoop3机器
$cd /app/hadoop
$scp -r spark-1.1.0 hadoop@hadoop2:/app/hadoop/
$scp -r spark-1.1.0 hadoop@hadoop3:/app/hadoop/


2. 在从节点查看是否复制成功
2.6 启动Spark
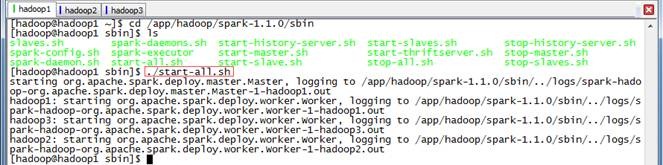
$cd /app/hadoop/spark-1.1.0/sbin
$./start-all.sh
2.7 验证启动
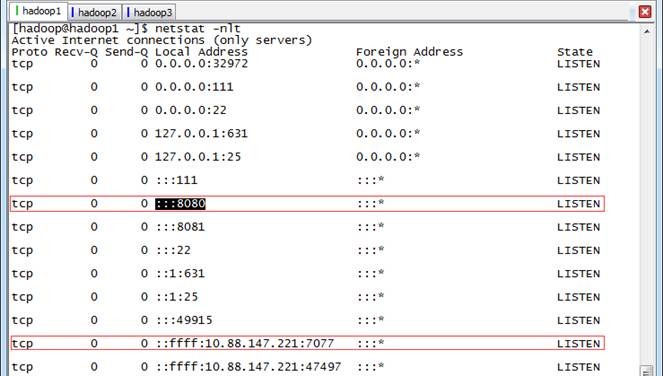
此时在hadoop1上面运行的进程有:Worker和Master

此时在hadoop2和hadoop3上面运行的进程有只有Worker

通过 netstat -nlt 命令查看hadoop1节点网络情况
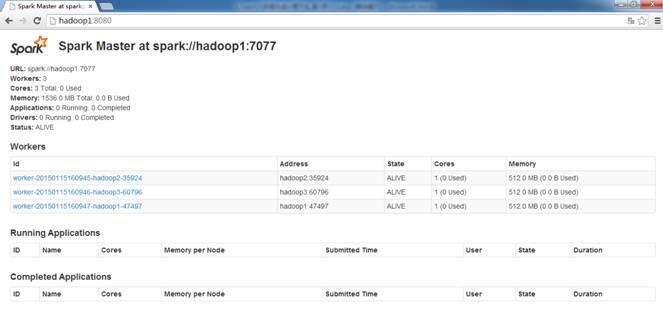
在浏览器中输入 http://hadoop1:8080(需要注意的是要在网络设置中把hadoop*除外,否则会到外网DNS解析,出现无法访问的情况) 既可以进入Spark集群状态页面
2.8 验证客户端连接
进入hadoop1节点,进入spark的bin目录,使用spark-shell连接集群
$cd /app/hadoop/spark-1.1.0/bin
$spark-shell --master spark://hadoop1:7077 --executor-memory 500m
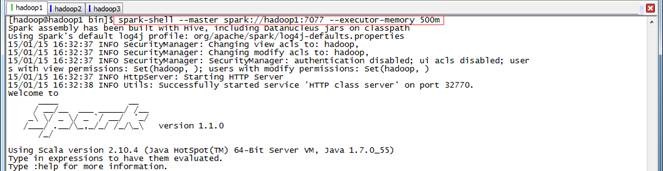
在命令中只指定了内存大小并没有指定核数,所以该客户端将占用该集群所有核并在每个节点分配500M内存
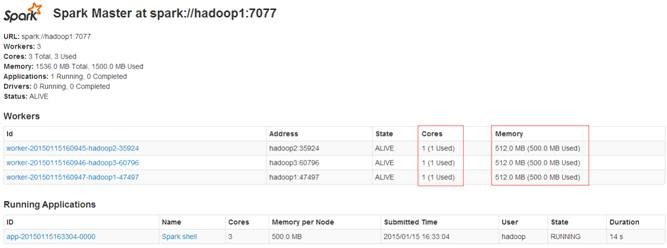

、Spark测试
3.1 使用Spark-shell测试
这里我们测试一下在Hadoop中大家都知道的WordCout程序,在MapReduce实现WordCout需要Map、Reduce和Job三个部分,而在Spark中甚至一行就能够搞定。下面就看一下是如何实现的:
3.1.1 启动HDFS
$cd /app/hadoop/hadoop-2.2.0/sbin
$./start-dfs.sh
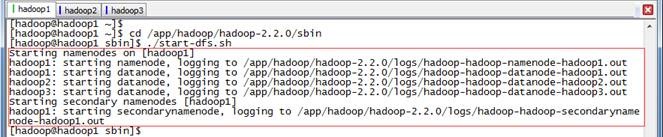
通过jps观察启动情况,在hadoop1上面运行的进程有:NameNode、SecondaryNameNode和DataNode

hadoop2和hadoop3上面运行的进程有:NameNode和DataNode

3.1.2 上传数据到HDFS中
把hadoop配置文件core-site.xml文件作为测试文件上传到HDFS中
$hadoop fs -mkdir -p /user/hadoop/testdata
$hadoop fs -put /app/hadoop/hadoop-2.2.0/etc/hadoop/core-site.xml /user/hadoop/testdata

3.1.3 启动Spark
$cd /app/hadoop/spark-1.1.0/sbin
$./start-all.sh
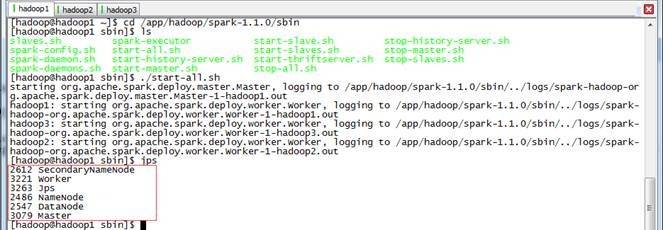
3.1.4 启动Spark-shell
在spark客户端(这里在hadoop1节点),使用spark-shell连接集群
$cd /app/hadoop/spark-1.1.0/bin
$./spark-shell --master spark://hadoop1:7077 --executor-memory 512m --driver-memory 500m
3.1.5 运行WordCount脚本
下面就是WordCount的执行脚本,该脚本是scala编写,以下为一行实现:
scala>sc.textFile("hdfs://hadoop1:9000/user/hadoop/testdata/core-site.xml").flatMap(_.split(" ")).map(x=>(x,1)).reduceByKey(_+_).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1)).take(10)
为了更好看到实现过程,下面将逐行进行实现:
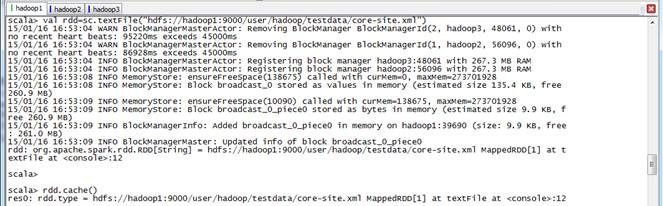
scala>val rdd=sc.textFile("hdfs://hadoop1:9000/user/hadoop/testdata/core-site.xml")
scala>rdd.cache()
scala>val wordcount=rdd.flatMap(_.split(" ")).map(x=>(x,1)).reduceByKey(_+_)
scala>wordcount.take(10)
scala>val wordsort=wordcount.map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
scala>wordsort.take(10)
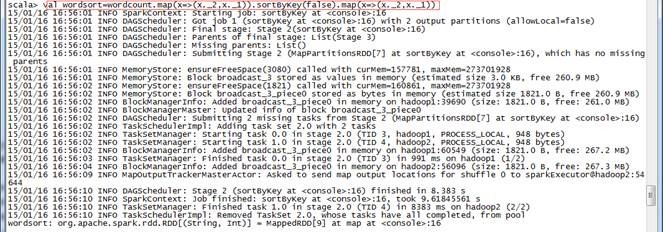


词频统计结果如下:
Array[(String, Int)] = Array(("",100), (the,7), (</property>,6), (<property>,6), (under,3), (in,3), (License,3), (this,2), (-->,2), (file.,2))
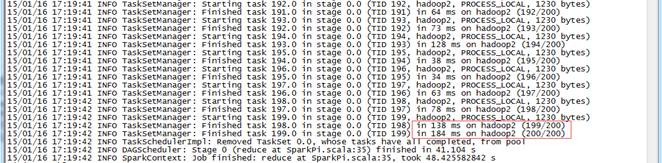
3.1.6 观察运行情况
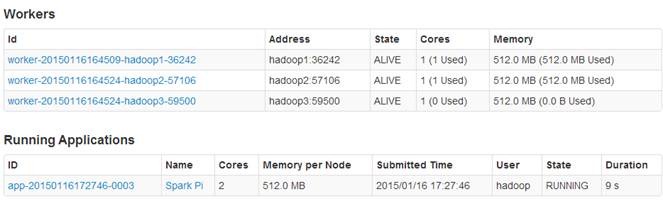
个节点,每个节点各为1个内核/512M内存,客户端分配3个核,每个核有512M内存。
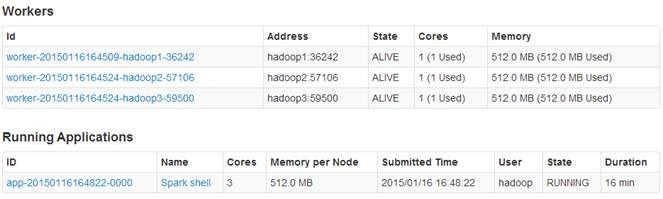
通过点击客户端运行任务ID,可以看到该任务在hadoop2和hadoop3节点上运行,在hadoop1上并没有运行,主要是由于hadoop1为NameNode和Spark客户端造成内存占用过大造成

3.2 使用Spark-submit测试
从Spark1.0.0开始,Spark提供了一个易用的应用程序部署工具bin/spark-submit,可以完成Spark应用程序在local、Standalone、YARN、Mesos上的快捷部署。该工具语法及参数说明如下:
Usage: spark-submit [options] <app jar | python file> [app options]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE driver运行之处,client运行在本机,cluster运行在集群
--class CLASS_NAME 应用程序包的要运行的class
--name NAME 应用程序名称
--jars JARS 用逗号隔开的driver本地jar包列表以及executor类路径
--py-files PY_FILES 用逗号隔开的放置在Python应用程序
PYTHONPATH上的.zip, .egg, .py文件列表
--files FILES 用逗号隔开的要放置在每个executor工作目录的文件列表
--properties-file FILE 设置应用程序属性的文件放置位置,默认是conf/spark-defaults.conf
--driver-memory MEM driver内存大小,默认512M
--driver-java-options driver的java选项
--driver-library-path driver的库路径Extra library path entries to pass to the driver
--driver-class-path driver的类路径,用--jars 添加的jar包会自动包含在类路径里
--executor-memory MEM executor内存大小,默认1G
Spark standalone with cluster deploy mode only:
--supervise 如果设置了该参数,driver失败是会重启
Spark standalone and Mesos only:
--total-executor-cores NUM executor使用的总核数
YARN-only:
--queue QUEUE_NAME 提交应用程序给哪个YARN的队列,默认是default队列
个
--archives ARCHIVES 被每个executor提取到工作目录的档案列表,用逗号隔开
该脚本为Spark自带例子,在该例子中个计算了圆周率π的值,以下为执行脚本:
$cd /app/hadoop/spark-1.1.0/bin
$./spark-submit --master spark://hadoop1:7077 --class org.apache.spark.examples.SparkPi --executor-memory 512m ../lib/spark-examples-1.1.0-hadoop2.2.0.jar 200
参数说明(详细可以参考上面的参数说明):
l --master Master所在地址,可以有Mesos、Spark、YARN和Local四种,在这里为Spark Standalone集群,地址为spark://hadoop1:7077
l --class应用程序调用的类名,这里为org.apache.spark.examples.SparkPi
l --executor-memory 每个executor所分配的内存大小,这里为512M
l 执行jar包 这里是../lib/spark-examples-1.1.0-hadoop2.2.0.jar
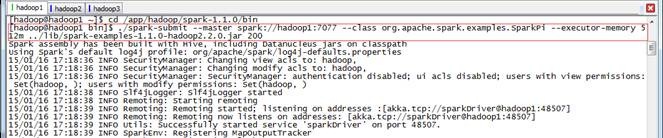
3.2.2 观察运行情况
个Worker节点和正在运行的1个应用程序,每个Worker节点为1内核/512M内存。由于没有指定应用程序所占内核数目,则该应用程序占用该集群所有3个内核,并且每个节点分配512M内存。
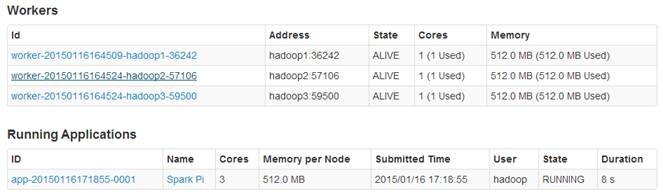
。而hadoop3执行executor数为10个,其中5个EXITED状态,5个KILLED状态。
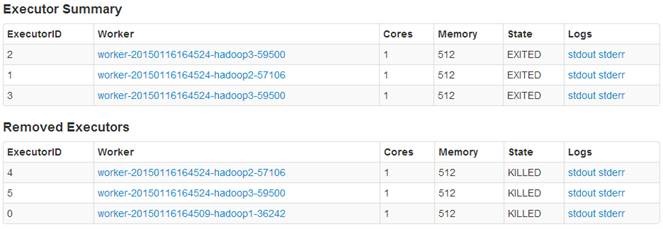
这里指定了每个executor内核数据,以下为执行脚本:
$cd /app/hadoop/spark-1.1.0/bin
$./spark-submit --master spark://hadoop1:7077 --class org.apache.spark.examples.SparkPi --executor-memory 512m --total-executor-cores 2 ../lib/spark-examples-1.1.0-hadoop2.2.0.jar 200
参数说明(详细可以参考上面的参数说明):
l --master Master所在地址,可以有Mesos、Spark、YARN和Local四种,在这里为Spark Standalone集群,地址为spark://hadoop1:7077
l --class应用程序调用的类名,这里为org.apache.spark.examples.SparkPi
l --executor-memory 每个executor所分配的内存大小,这里为512M
l --total-executor-cores 2 每个executor分配的内核数
l 执行jar包 这里是../lib/spark-examples-1.1.0-hadoop2.2.0.jar
3.2.4 观察运行情况
个Worker节点和正在运行的1个应用程序,每个Worker节点为1内核/512M内存。由于指定应用程序所占内核数目为2,则该应用程序使用该集群所有2个内核。

Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装的更多相关文章
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Hadooop 1.1 搭建环境 1.1.1 安装并设置maven 1. 下载mave ...
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 . 安装IntelliJ IDEA IDEA 全称 IntelliJ IDEA,是java语 ...
- Spark入门实战系列--5.Hive(上)--Hive介绍及部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Hive介绍 1.1 Hive介绍 月开源的一个数据仓库框架,提供了类似于SQL语法的HQ ...
- Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .SparkSQL的发展历程 1.1 Hive and Shark SparkSQL的前身是 ...
- Spark入门实战系列--6.SparkSQL(中)--深入了解SparkSQL运行计划及调优
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1.1 运行环境说明 1.1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软 ...
- Spark入门实战系列--6.SparkSQL(下)--Spark实战应用
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .运行环境说明 1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软件:VMwa ...
随机推荐
- JSON 序列化和反序列化——JavaScriptSerializer实现
一. JavaScriptSerializer 类由异步通信层内部使用,用于序列化和反序列化在浏览器和 Web 服务器之间传递的数据.您无法访问序列化程序的此实例.但是,此类公开了公共 API.因此, ...
- Linux tcpdump 详解
简介 用简单的话来定义tcpdump,就是:dump the traffic on a network,根据使用者的定义对网络上的数据包进行截获的包分析工具. tcpdump可以将网络中传送的数据包的 ...
- python-getattr
getattr(object, name[, default]) Return the value of the named attribute of object. name must be a ...
- cuda计算的分块
gpu的架构分为streaming multiprocessors 每个streaming multiprocessors(SM)又能分步骤执行很多threads,单个SM内部能同时执行的thread ...
- 关于通过jq /js 实现验证单选框 复选框是否都有被选中
今天项目中遇到一个问题 就是要实现,单选框,复选框 同时都被选中才能进行下一步的问题,开始用js原生来写 怎么写都觉得不合适,通过for循环得出 复选框被选中的,在通过for循环得出单选框被选中的,问 ...
- Replication的犄角旮旯(四)--关于事务复制的监控
<Replication的犄角旮旯>系列导读 Replication的犄角旮旯(一)--变更订阅端表名的应用场景 Replication的犄角旮旯(二)--寻找订阅端丢失的记录 Repli ...
- 【菜鸟玩Linux开发】在C++里操作MySQL
MySQL是一个的开源关系型数据库,对于服务端开发来说是一个优秀的选择.本篇内容将介绍如何在C++程序里操作MySQL数据库. ———————————————————————————————————— ...
- Windows Phone 8.1 开发技术概览 (Universal APP)
前一阵真的比较懒 WP8.1 已经出来这么长时间了现在才更新BLOG让大家久等了,今天我先为大家介绍下 WP 8.1的开发框架,什么是微软所推崇的 Universal APP,以及我们要开发 Univ ...
- 【AspNetCore】【WebApi】扩展Webapi中的RouteConstraint中,让DateTime类型,支持时间格式化(DateTimeFormat)
扩展Webapi中的RouteConstraint中,让DateTime类型,支持时间格式化(DateTimeFormat) 一.背景 大家在使用WebApi时,会用到DateTime为参数,类似于这 ...
- Fedora23Server配置
系统准备 启动网卡: sudo service network start 更新系统: sudo dnf update 远程管理: https://IP:9090/ Dnf使用: http://www ...