SQL SERVER 内存学习系列(二)-DMV查看内存信息
内存管理在SQL Server中有一个三级结构。底部是内存节点,这是最低级的分配器,用于SQL Server的内存。第二个层次是由内存Clerk组成,这是用来访问内存节点和缓存存储,缓存存储则用于缓存。最上层包含内存对象,它提供了一个比内存Clerk更小程度的粒度,内存对象允许直接。只有Clerk可以访问存储节点,来分配内存,所以每一个需要分配大量内存的组件都需要在SQL Server服务启动时创建它自己的内存Clerk。
以前版本的SQL Server需要SQL Server内存分配之外的VAS空间,以满足多页分配(MPA)和CLR内存要求。MPA用于每当一个组件需要一个单一分配大于8KB的时候,单页分配器处理任何不大于8KB的时候。在SQL Server 2012中,只有一个页面分配器用于所有的请求,他们都直接来自于SQL Server的内存分配。在SQL Server 2012中,CLR分配也是直接来自于SQL Server的内存分配,这使得它更容易规模化SQL Server的内存需求
2008R2
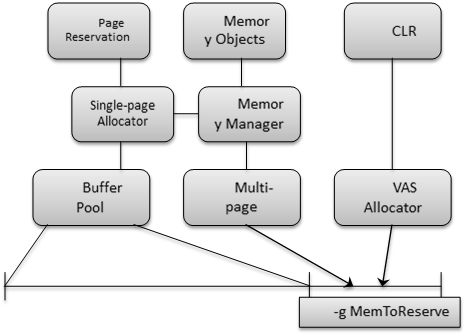
2012

从上面的图可以看出,SQL Server 2012 多了一个memory Manager,它来统一响应SQL Server 内部各种组件内存申请的请求。因为这个原因,在SQL Server 2012里面,max server memory 不再像以前的版本那样,只控制buffer pool的大小,也包括那些大于8kb 的内存请求。也就是, max server memory 能够更准确地控制SQL Server 的内存使用了(并非完全控制)。
SQL SERVER使用Memory Clerk的方式统一管理内存的分配和回收,所以这使得我们使用SQL SERVER内存变得容易,因为需要我们设置的东西很少。除了限制一下max server memory 我貌似也想不到什么需要干涉SQL 使用内存的了(当然类似resource governor这种东西除外哈)。
SQL SERVER可以知道每个Clerk使用了多少内存从而也知道自己总共使用了多少内存,这些信息都在DMV视图中可以查询的到,虽然大部分管理中都是使用性能监控器但是DMV的信息也是一种比较好的监控手段。另外很多人喜欢用DBCC 语句查看SQL各种信息,我也不例外,但是现在的DMV在产品技术不断发展也越来越全面细致了。
---------------转载请注明出处------------http://www.cnblogs.com/double-K/p/5063024.html--------------------
1.memory clerk :跟踪内存sys.dm_os_memory_clerks 这个视图在05,08,12中都有变化
-----查看内存节点直接映射到NUMA节点
select * from sys.dm_os_memory_nodes ----
----查看memory clerk信息
----2012 中 pages_kb = 2008 中 single_pages_kb + multi_pages_kb
----2005 请自行查找
SELECT [type],
memory_node_id,
pages_kb,
virtual_memory_reserved_kb,
virtual_memory_committed_kb,
shared_memory_reserved_kb,
shared_memory_committed_kb,
awe_allocated_kb
FROM sys.dm_os_memory_clerks
ORDER BY [type] DESC; -----不区分memory_node_id 查看总体clerk分配情况
SELECT [type],
sum(pages_kb) as [pages_kb],
sum(virtual_memory_reserved_kb) as [vm reserved],
sum(virtual_memory_committed_kb) as [vm committed],
sum(shared_memory_reserved_kb) as [sm reserved],
sum(shared_memory_committed_kb) as [sm committed],
sum(awe_allocated_kb) as [awe allocated]
FROM sys.dm_os_memory_clerks
group by [type]
ORDER BY [type] DESC;
白皮书的字段说明:
|
列名 |
数据类型 |
说明 |
|
|---|---|---|---|
|
memory_clerk_address |
varbinary(8) |
指定内存分配器的唯一内存地址。 这是主键列。 不可为 Null。 |
|
|
类型 |
nvarchar(60) |
指定内存分配器的类型。 每个分配器都具有特定类型,例如,CLR Clerks MEMORYCLERK_SQLCLR。 不可为 Null。 |
|
|
name |
nvarchar(256) |
指定在内部为此内存分配器分配的名称。 一个组件可拥有多个特定类型的内存分配器。 组件可选择使用特定名称来标识相同类型的内存分配器。 不可为 Null。 |
|
|
memory_node_id |
smallint |
指定内存节点的 ID。 不可为 Null。 |
|
|
single_pages_kb |
bigint |
|
|
|
pages_kb |
bigint |
指定为此内存分配器分配的页内存量 (KB)。 不可为 Null。
|
|
|
multi_pages_kb |
bigint |
分配的多页内存量 (KB)。 这是使用内存节点的多页分配器分配的内存量。 此内存在缓冲池外面分配,利用了内存节点虚拟分配器的优势。 不可为 Null。
|
|
|
virtual_memory_reserved_kb |
bigint |
指定内存分配器保留的虚拟内存量。 不可为 Null。 |
|
|
virtual_memory_committed_kb |
bigint |
指定内存分配器提交的虚拟内存量。 提交的内存量应始终小于保留的内存量。 不可为 Null。 |
|
|
awe_allocated_kb |
bigint |
指定在物理内存中锁定且未由操作系统调出的内存量 (KB) 。 不可为 Null。 |
|
|
shared_memory_reserved_kb |
bigint |
指定内存分配器保留的共享内存量。 保留以供共享内存和文件映射使用的内存量。 不可为 Null。 |
|
|
shared_memory_committed_kb |
bigint |
指定内存分配器提交的共享内存量。 不可为 Null。 |
|
|
page_size_in_bytes |
bigint |
指定此内存分配器的页分配粒度。 不可为 Null。 |
|
|
page_allocator_address |
varbinary(8) |
指定页分配器的地址。 此地址对于内存分配器唯一,且可在 sys.dm_os_memory_objects 中使用,以查找绑定到此分配器的内存对象。 不可为 Null。 |
|
|
host_address |
varbinary(8) |
指定用于此内存分配器的主机的内存地址。 有关详细信息,请参阅 sys.dm_os_hosts (Transact-SQL)。 Microsoft SQL Server Native Client 等组件通过宿主接口访问 SQL Server 内存资源。 0x00000000 = 属于 SQL Server 的内存分配器。 不可为 Null。 |
2.缓存
SQL Server使用三种类型的缓存机制:对象存储,缓存存储和用户存储。对象存储用于缓存同种类型的无状态的数据,但缓存存储和用户存储是最常见的。两者很相似,因为都是缓存。它们的主要区别是,用户存储必须是由使用开发框架的自身存储语义来创建,而缓存存储则实现对前面提到的用于提供更小内存分配粒度的存储对象的支持。从本质上讲,用户存储主要用于微软内部不同的开发团队实现SQL Server功能的特定缓存,所以你可以以相同的方式看待缓存存储和用户存储。要查看SQL Server上实施的不同的缓存,可以使用DMV sys.dm_os_memory_cache_counters。例如,运行下面的查询会显示所有可用的缓存,它们以空间消费的总量排序:
SELECT [name],[type],pages_kb,entries_count
FROM sys.dm_os_memory_cache_counters
ORDER BY pages_kb DESC;
3.缓冲池
缓冲池包含并管理SQL Server的数据缓存。其内容信息可通过DMV sys.dm_os_buffer_descriptors DMV来查看。例如,下面的查询将返回每个数据库的缓存使用量,以MB为单位:
SELECT count(*)*8/1024 AS 'Cached Size (MB)'
,CASE database_id WHEN 32767 THEN 'ResourceDb'
ELSE db_name(database_id) END AS 'Database'
FROM sys.dm_os_buffer_descriptors
GROUP BY db_name(database_id),database_id
ORDER BY 'Cached Size (MB)' DESC
4.计划缓存
创建执行计划是好事且资源密集的,因此,如果SQL Server能找到执行一段代码的好方式,将是一件有意义的事,应该尝试为后续的请求复用它。计划缓存用于缓存所有的执行计划,以备复用。你可以使用DMV sys.dm_exec_cached_plans来查看计划缓存中的内容和确定它当前的大小:
SELECT count(*) AS 'Number of Plans',
sum(cast(size_in_bytes AS BIGINT))/1024/1024 AS 'Plan Cache Size (MB)'
FROM sys.dm_exec_cached_plans
下面是一些其他的网络常用脚本:
--查看数据缓冲区里面的脏数据页
SELECT OBJECT_NAME(p.[object_id]) AS [TableName]
, ISNULL(i.name, '-- HEAP --') AS ObjectName
, COUNT(1) AS PagesCount
FROM sys.allocation_units AS a
INNER JOIN sys.dm_os_buffer_descriptors AS b
ON a.allocation_unit_id = b.allocation_unit_id
INNER JOIN sys.partitions AS p
INNER JOIN sys.indexes i
ON p.index_id = i.index_id
AND p.[object_id] = i.[object_id]
ON a.container_id = p.hobt_id
WHERE b.database_id = DB_ID()
AND B.is_modified=1
GROUP BY p.[object_id], i.name --对象的分布
SELECT TOP 50 OBJECT_NAME(p.[object_id]) AS [TableName]
, ISNULL(i.name, '-- HEAP --') AS ObjectName
, COUNT(1) * 8 / 1024 AS PagesCount_mb
FROM sys.allocation_units AS a
INNER JOIN sys.dm_os_buffer_descriptors AS b
ON a.allocation_unit_id = b.allocation_unit_id
INNER JOIN sys.partitions AS p
INNER JOIN sys.indexes i
ON p.index_id = i.index_id
AND p.[object_id] = i.[object_id]
ON a.container_id = p.hobt_id
WHERE b.database_id = DB_ID()
--AND B.is_modified=1
GROUP BY p.[object_id], i.name
ORDER By PagesCount_mb DESC ----缓冲池内数据库缓冲池中各个数据库的分布情况---
select case database_id when 32767 then 'resourcedb' else DB_NAME(database_id) end as database_name,
COUNT(*) as cached_pages_count
from sys.dm_os_buffer_descriptors
group by db_name(database_id),database_id
order by cached_pages_count desc ---------缓冲池中前十位消耗内存最大的内存组件-----
select top(100) type ,SUM(pages_kb) as [spa mem,kb]
--select *
from sys.dm_os_memory_clerks
group by type
order by SUM(pages_kb) desc
---------------转载请注明出处------------http://www.cnblogs.com/double-K/p/5063024.html--------------------
总结:内存相关的DMV视图有很多用法也很灵活,对排查内存问题很有帮助,但话说回来,既然SQL SERVER 选择自己管理分配内存,这也让用户可干预的很少,所以个人经验:目前内存出现问题,只能出内存的使用者角度出发,分析为什么会占用这么多内存,是否可以减少内存的使用?总之我们能够干预的内存使用还是很有限的,这个似乎有些坑了。有更好的办法也还请赐教。
SQL SERVER 内存学习系列(二)-DMV查看内存信息的更多相关文章
- sql server 索引阐述系列二 索引存储结构
一.概述. "流光容易把人抛,红了樱桃,绿了芭蕉“ 转眼又年中了,感叹生命的有限,知识的无限.在后续讨论索引之前,先来了解下索引和表数据的内部结构,这一节将介绍页的存储,页分配单元类型,区的 ...
- sql server 索引阐述系列六 碎片查看与解决方案
一 . dm_db_index_physical_stats 重要字段说明 1.1 内部碎片:是avg_page_space_used_in_percent字段.是指页的填充度,为了使磁盘使用状况达到 ...
- 【目录】sql server 进阶篇系列
随笔分类 - sql server 进阶篇系列 sql server 下载安装标记 摘要: SQL Server 2017 的各版本和支持的功能 https://docs.microsoft.com/ ...
- SQL SERVER 内存学习系列(一)
最近帮客户解决发布订阅的问题时,突然遇到这样一个问题发布订阅中报下面的错误,另外执行alter table 操作时也会报错 : 问题很奇怪发布订阅和CLR有什么关系?memtoleave内存是个啥?回 ...
- SQL Server调优系列玩转篇二(如何利用汇聚联合提示(Hint)引导语句运行)
前言 上一篇我们分析了查询Hint的用法,作为调优系列的最后一个玩转模块的第一篇.有兴趣的可以点击查看:SQL Server调优系列玩转篇(如何利用查询提示(Hint)引导语句运行) 本篇继续玩转模块 ...
- SQL Server调优系列基础篇(并行运算总结篇二)
前言 上一篇文章我们介绍了查看查询计划的并行运行方式. 本篇我们接着分析SQL Server的并行运算. 闲言少叙,直接进入本篇的正题. 技术准备 同前几篇一样,基于SQL Server2008R2版 ...
- SQL Server 调优系列玩转篇二(如何利用汇聚联合提示(Hint)引导语句运行)
前言 上一篇我们分析了查询Hint的用法,作为调优系列的最后一个玩转模块的第一篇.有兴趣的可以点击查看:SQL Server调优系列玩转篇(如何利用查询提示(Hint)引导语句运行) 本篇继续玩转模块 ...
- SQL Server调优系列进阶篇(查询语句运行几个指标值监测)
前言 上一篇我们分析了查询优化器的工作方式,其中包括:查询优化器的详细运行步骤.筛选条件分析.索引项优化等信息. 本篇我们分析在我们运行的过程中几个关键指标值的检测. 通过这些指标值来分析语句的运行问 ...
- SQL Server调优系列基础篇(并行运算总结)
前言 上三篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符.联合运算符的优化技巧. 本篇我们分析SQL Server的并行运算,作为多核计算机盛行的今天,SQL Server也会适时调整自 ...
随机推荐
- 调用 WebService 浏览器提示 500 (Internal Server Error) 的原因及解决办法
在 ASP.NET 开发中,WebService部署成站点之后,如果在本地测试WebService可以运行,在远程却显示“测试窗体只能用于来自本地计算机的请求”或 者"The test fo ...
- SEO和SEM的区别
SEO是属于SEM的一部分,SEO和SEM最主要的是最终目标的不同: SEO主要是为了关键词的排名.网站的流量.网站的结构.搜索引擎中页面收录的数据. SEM是通过SEO技术基础上扩展为搜索引擎中所带 ...
- 建站阿里云、amh主机面版
阿里云 Nginx+tomcat7+Mencached负载均衡集群配置 http://blog.csdn.net/zht666/article/details/38515147 apache2.2.1 ...
- wpf 空白汉字占位符
<TextBlock xml:space="preserve" Text="主 编" /> 表示一个汉字占位符
- c# 筛选进程命令行,得其ProcessId(唯一标示符,简称pid),再通过pid结束进程
不说别的,上代码 部分using: using System.Diagnostics; using System.Management; 其中要引用System.Management 1.通过筛选Co ...
- myeclipse2014激活
MyEclipse2014破解教程 一. 在破解myeclipse2014之前,要先把环境变量配置好: 1)打开我的电脑--属性--高级--环境变量 2)新建系统变量JAVA_HOME 和CLASSP ...
- 【线段树套平衡树】【pb_ds】bzoj3196 Tyvj 1730 二逼平衡树
线段树套pb_ds里的平衡树,在洛谷OJ上测试,后三个测试点TLE #include<cstdio> #include<algorithm> #include<ext/p ...
- Matlab 语谱图(时频图)绘制与分析
Matlab 语谱图(时频图)绘制与分析 语谱图:先将语音信号作傅里叶变换,然后以横轴为时间,纵轴为频率,用颜色表示幅值即可绘制出语谱图.在一幅图中表示信号的频率.幅度随时间的变化,故也称" ...
- 推荐一款跨平台的 Azure Storage Explorer
var appInsights=window.appInsights||function(config){ function r(config){t[config]=function(){var i= ...
- 动画总结(UIView的动画)
Main.storyboard ViewController.m // // ViewController.m // 8A08.动画总结 // // Created by huan on 16/ ...