xv6学习笔记(5) : 锁与管道与多cpu
xv6学习笔记(5) : 锁与管道与多cpu
1. xv6锁结构
1. xv6操作系统要求在内核临界区操作时中断必须关闭。
如果此时中断开启,那么可能会出现以下死锁情况:
- 进程A在内核态运行并拿下了p锁时,触发中断进入中断处理程序。
- 中断处理程序也在内核态中请求p锁,由于锁在A进程手里,且只有A进程执行时才能释放p锁,因此中断处理程序必须返回,p锁才能被释放。
- 那么此时中断处理程序会永远拿不到锁,陷入无限循环,进入死锁。
2. xv6中的自旋锁
Xv6中实现了自旋锁(Spinlock)用于内核临界区访问的同步和互斥。自旋锁最大的特征是当进程拿不到锁时会进入无限循环,直到拿到锁退出循环。Xv6使用100ms一次的时钟中断和Round-Robin调度算法来避免陷入自旋锁的进程一直无限循环下去。Xv6允许同时运行多个CPU核,多核CPU上的等待队列实现相当复杂,因此使用自旋锁是相对比较简单且能正确执行的实现方案。
v6中锁的定义如下
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
uint pcs[10]; // The call stack (an array of program counters)
// that locked the lock.
};
核心的变量只有一个locked,当locked为1时代表锁已被占用,反之未被占用,初始值为0。
在调用锁之前,必须对锁进行初始化。
void initlock(struct spinlock *lk, char *name) {
lk->name = name;
lk->locked = 0;
lk->cpu = 0;
}
这里的需要注意的就是如何对locked变量进行原子操作占用锁和释放锁。
这两步具体被实现为acquire()和release()函数。
1. acquire函数
- 首先禁止中断防止死锁(如果这里不禁止中断就可能会出现上述的死锁问题
- 然后利用
xchg来上锁
void
acquire(struct spinlock *lk)
{
pushcli(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
// The xchg is atomic.
while(xchg(&lk->locked, 1) != 0)
;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen after the lock is acquired.
__sync_synchronize();
// Record info about lock acquisition for debugging.
lk->cpu = mycpu();
getcallerpcs(&lk, lk->pcs);
}
xchg这里采用内联汇编实现
最前面的lock表示这是一条指令前缀,它保证了这条指令对总线和缓存的独占权,也就是这条指令的执行过程中不会有其他CPU或同CPU内的指令访问缓存和内存。
static inline uint xchg(volatile uint *addr, uint newval) {
uint result;
// The + in "+m" denotes a read-modify-write operand.
asm volatile("lock; xchgl %0, %1" :
"+m" (*addr), "=a" (result) :
"1" (newval) :
"cc");
return result;
}
最后,acquire()函数使用__sync_synchronize为了避免编译器对这段代码进行指令顺序调整的话和避免CPU在这块代码采用乱序执行的优化。
这样就保证了原子操作的加锁。也就是把lk->locked设置为1
2. release函数
// Release the lock.
void release(struct spinlock *lk) {
if(!holding(lk))
panic("release");
lk->pcs[0] = 0;
lk->cpu = 0;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that all the stores in the critical
// section are visible to other cores before the lock is released.
// Both the C compiler and the hardware may re-order loads and
// stores; __sync_synchronize() tells them both not to.
__sync_synchronize();
// Release the lock, equivalent to lk->locked = 0.
// This code can't use a C assignment, since it might
// not be atomic. A real OS would use C atomics here.
asm volatile("movl $0, %0" : "+m" (lk->locked) : );
popcli();
}
release函数为了保证设置locked为0的操作的原子性,同样使用了内联汇编。
2. 信号量
在xv6中没有信号量,但是我看博客有大佬利用xv6中提供的接口实现了信号量
3. 唤醒与睡眠
1. 先看有问题的版本
struct q {
struct spinlock lock;
void *ptr;
};
void *
send(struct q *q, void *p)
{
acquire(&q->lock);
while(q->ptr != 0)
;
q->ptr = p;
wakeup(q);
release(&q->lock);
}
void*
recv(struct q *q)
{
void *p;
acquire(&q->lock);
while((p = q->ptr) == 0)
sleep(q);
q->ptr = 0;
release(&q->lock;
return p;
}
这个代码乍一看是没什么问题,发出消息之后,调用wakeup唤醒进程来接受。而且在发送的过程中保持锁。反正出现问题。在发送完成后释放锁。同时wakeup会让进程从seleep状态返回,这里的返回就会到recv函数来进行接受。
但是这里的问题在于当当 recv 带着锁 q->lock 进入睡眠后,发送者就会在希望获得锁时一直阻塞。
所以想要解决问题,我们必须要改变 sleep 的接口。sleep 必须将锁作为一个参数,然后在进入睡眠状态后释放之;这样就能避免上面提到的“遗失的唤醒”问题。一旦进程被唤醒了,sleep 在返回之前还需要重新获得锁。于是我们应该使用下面的代码:
2. 上面版本的改进
struct q {
struct spinlock lock;
void *ptr;
};
void *
send(struct q *q, void *p)
{
acquire(&q->lock);
while(q->ptr != 0)
;
q->ptr = p;
wakeup(q);
release(&q->lock);
}
void*
recv(struct q *q)
{
void *p;
acquire(&q->lock);
while((p = q->ptr) == 0)
sleep(q, &q->lock);
q->ptr = 0;
release(&q->lock;
return p;
}
recv 持有 q->lock 就能防止 send 在 recv 检查 q->ptr 与调用 sleep 之间调用 wakeup 了。当然,为了避免死锁,接收进程最好别在睡眠时仍持有锁。所以我们希望 sleep 能用原子操作释放 q->lock 并让接收进程进入休眠状态。
完整的发送者/接收者的实现还应该让发送者在等待接收者拿出前一个 send 放入的值时处于休眠状态。
3. xv6的wakeup和sleep
sleep(chan) 让进程在任意的 chan 上休眠,称之为等待队列(wait channel)。sleep 让调用进程休眠,释放所占 CPU。wakeup(chan) 则唤醒在 chan 上休眠的所有进程,让他们的 sleep 调用返回。如果没有进程在 chan 上等待唤醒,wakeup 就什么也不做。
总体思路是希望
sleep将当前进程转化为SLEEPING状态并调用sched以释放 CPU,而wakeup则寻找一个睡眠状态的进程并把它标记为RUNNABLE。
1. sleep函数
- 首先sleep会做几个检查:必须存在当前进程、并且
sleep必须持有锁(2558-2559)。接着sleep要求持有ptable.lock - 于是该进程就会同时持有锁
ptable.lock和lk了。调用者(例如recv)是必须持有lk的,这样可以保证其他进程(例如一个正在运行的send)无法调用wakeup(chan)。而如今sleep已经持有了ptable.lock,那么它现在就能安全地释放lk了:这样即使别的进程调用了wakeup(chan),wakeup也不可能在没有持有ptable.lock的情况下运行,所以wakeup必须等待sleep让进程睡眠后才能运行。这样一来,wakeup就不会错过sleep了。 - 这里要注意如果
lk == ptable.lock的话则就会跳过对于if语句的判断 - 后面做的就是把当前进程放入chan中(等待队列)
- 随后进行调度交出cpu
void
sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc();
if(p == 0)
panic("sleep");
if(lk == 0)
panic("sleep without lk");
// Must acquire ptable.lock in order to
// change p->state and then call sched.
// Once we hold ptable.lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup runs with ptable.lock locked),
// so it's okay to release lk.
if(lk != &ptable.lock){ //DOC: sleeplock0
acquire(&ptable.lock); //DOC: sleeplock1
release(lk);
}
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
// Tidy up.
p->chan = 0;
// Reacquire original lock.
if(lk != &ptable.lock){ //DOC: sleeplock2
release(&ptable.lock);
acquire(lk);
}
}
2. wakeup函数
- 遍历所有的进程表
- 判断p->chan == chan 设置为runable
// Wake up all processes sleeping on chan.
void
wakeup(void *chan)
{
acquire(&ptable.lock);
wakeup1(chan);
release(&ptable.lock);
}
// wakeup --> wakeup1
// Wake up all processes sleeping on chan.
// The ptable lock must be held.
//
static void
wakeup1(void *chan)
{
struct proc *p;
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++)
if(p->state == SLEEPING && p->chan == chan)
p->state = RUNNABLE;
}
4.管道
在xv6中管道是比较复杂的使用 sleep/wakeup 来同步读者写者队列的例子。
1. 管道结构体
struct pipe {
struct spinlock lock;
char data[PIPESIZE];
uint nread; // number of bytes read
uint nwrite; // number of bytes written
int readopen; // read fd is still open
int writeopen; // write fd is still open
};
我们从管道的一端写入数据字节,然后数据被拷贝到内核缓冲区中,接着就能从管道的另一端读取数据了。
中有一个锁 lock和内存缓冲区。其中的域 nread 和 nwrite 表示从缓冲区读出和写入的字节数。pipe 对缓冲区做了包装,使得虽然计数器继续增长,但实际上在 data[PIPESIZE - 1] 之后写入的字节存放在 data[0]。这样就让我们可以区分一个满的缓冲区(nwrite == nread + PIPESIZE)和一个空的缓冲区(nwrite == nread),但这也意味着我们必须使用 buf[nread % PIPESIZE] 而不是 buf[nread] 来读出/写入数据。
2. Piperead()函数
- 当缓冲数据区为空的时候(并且writeopen被打开了)这个时候就要等。因为写操作还没完成所以主动sleep
- 否则就可以读了
- 读完了就唤醒写
int
piperead(struct pipe *p, char *addr, int n)
{
int i;
acquire(&p->lock);
while(p->nread == p->nwrite && p->writeopen){ //DOC: pipe-empty
if(myproc()->killed){
release(&p->lock);
return -1;
}
sleep(&p->nread, &p->lock); //DOC: piperead-sleep
}
for(i = 0; i < n; i++){ //DOC: piperead-copy
if(p->nread == p->nwrite)
break;
addr[i] = p->data[p->nread++ % PIPESIZE];
}
wakeup(&p->nwrite); //DOC: piperead-wakeup
release(&p->lock);
return i;
}
3. pipewrite()函数
- 当缓冲区已经满了,但是readopen被打开了,这个时候就要唤醒读缓冲区的进程去读操作。
- 否则就是简单的写操作了
- 写完了就唤醒读
int
pipewrite(struct pipe *p, char *addr, int n)
{
int i;
acquire(&p->lock);
for(i = 0; i < n; i++){
while(p->nwrite == p->nread + PIPESIZE){ //DOC: pipewrite-full
if(p->readopen == 0 || myproc()->killed){
release(&p->lock);
return -1;
}
wakeup(&p->nread);
sleep(&p->nwrite, &p->lock); //DOC: pipewrite-sleep
}
p->data[p->nwrite++ % PIPESIZE] = addr[i];
}
wakeup(&p->nread); //DOC: pipewrite-wakeup1
release(&p->lock);
return n;
}
5. xv6下的多cpu启动
这里多cpu主要结合828的lab来一起分析。要是有不同的也会做一下对比
在xv6中和828中对于多cpu的支持都是SMP体系架构下的。
在SMP下所有的cpu的地位是一模一样的,他们具有相同的权限,相同的资源。所有CPU在SMP中在功能上相同,但在引导过程中,它们可以分为两种类型:
- 引导处理器BSP(bootstrap processor)负责初始化系统并且引导操作系统。
- 应用处理器AP(application processor)在操作系统启动之后被BSP激活。
由哪个(些)处理器来担任BSP的功能是由BIOS和硬件决定的,之前的所有代码都是在BSP上实现的。
总的步骤如下参考
BIOS 启动 BSP,完成读取内核balabala的操作一直到main.c中
BSP 从
MP Configuration Table中获取多处理器的的配置信息BSP 启动 APs,通过发送
INIT-SIPI-SIPI消息给 APsAPs 启动,各个 APs 处理器要像 BSP 一样建立自己的一些机制,比如保护模式,分页,中断等等
关于多核启动在网上看见了一个很好的博客我这里也是大多参考于它
1. mpinit函数
mpinit函数负责是检测CPU个数并将检测到的CPU存入一个全局的数组中。
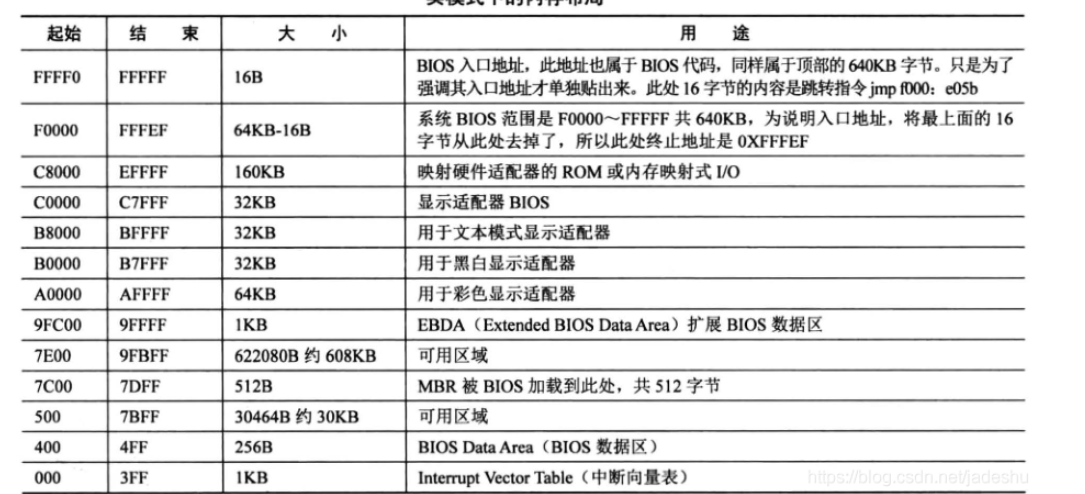
这里我们需要解析MP Configuration Table。而在xv6中这个信息使用mp结构体来存储的。下面是要注意的点!!
这个结构只可能出现在三个位置,寻找 floating pointer 的时候就按下面的循序查找:
- EBDA(Extended BIOS Data Area)最开始的 1KB
- 系统基本内存的最后 1KB (对于 640 KB 的基本内存来说就是 639KB-640KB,对于 512KB 的基本内存来说就是 511KB-512KB)
- BIOS 的 ROM 区域,在
到
之间
第一步要调用
mpconfig函数来解析出mpvoid
mpinit(void)
{
uchar *p, *e;
int ismp;
struct mp *mp;
struct mpconf *conf;
struct mpproc *proc;
struct mpioapic *ioapic; if((conf = mpconfig(&mp)) == 0)
panic("Expect to run on an SMP");
而
mpconfig函数最重要的就是利用mpserach函数关于对照关系上面给了一个表格
这里就是完全按照上面说的三个顺序进行测试的,只不过对应的地址变化(我也不会,也懒得看了。)就是知道他是依此去这三个地方find mp就行了
static struct mp* mpsearch(void) //寻找mp floating pointer 结构
{
uchar *bda;
uint p;
struct mp *mp; bda = (uchar *) P2V(0x400); //BIOS Data Area地址 if((p = ((bda[0x0F]<<8)| bda[0x0E]) << 4)){ //在EBDA中最开始1K中寻找
if((mp = mpsearch1(p, 1024)))
return mp;
} else { //在基本内存的最后1K中查找
p = ((bda[0x14]<<8)|bda[0x13])*1024;
if((mp = mpsearch1(p-1024, 1024)))
return mp;
}
return mpsearch1(0xF0000, 0x10000); //在0xf0000~0xfffff中查找
}
下面就是根据读到的conf来解析cpu信息
ismp = 1;
lapic = (uint*)conf->lapicaddr;
for(p=(uchar*)(conf+1), e=(uchar*)conf+conf->length; p<e; ){
switch(*p){
case MPPROC: // 如果是处理器
proc = (struct mpproc*)p;
if(ncpu < NCPU) {
cpus[ncpu].apicid = proc->apicid; // 为cpu分配apicid 也就是说apicid标识了唯一的cpu
ncpu++;
}
p += sizeof(struct mpproc);
continue;
case MPIOAPIC:
ioapic = (struct mpioapic*)p;
ioapicid = ioapic->apicno;
p += sizeof(struct mpioapic);
continue;
case MPBUS:
case MPIOINTR:
case MPLINTR:
p += 8;
continue;
default:
ismp = 0;
break;
}
}
if(!ismp)
panic("Didn't find a suitable machine");
if(mp->imcrp){
// Bochs doesn't support IMCR, so this doesn't run on Bochs.
// But it would on real hardware.
outb(0x22, 0x70); // Select IMCR
outb(0x23, inb(0x23) | 1); // Mask external interrupts.
}
}
2. lapicinit(void)
这是在启动多个aps之间要做的一些初始化操作。
下面用得最多的lapicw操作其实非常简单
static void
lapicw(int index, int value)
{
lapic[index] = value;
lapic[ID]; // wait for write to finish, by reading
}
中断流程:
- 一个 CPU 给其他 CPU 发送中断的时候, 就在自己的 ICR 中, 放中断向量和目标LAPIC ID, 然后通过总线发送到对应 LAPIC,
- 目标 LAPIC 根据自己的 LVT(Local Vector Table) 来对不同的中断进行处理.
- 处理完了写EOI 表示处理完了.
所以下面的操作其实就是在初始化LVT表
void
lapicinit(void)
{
if(!lapic)
return;
// Enable local APIC; set spurious interrupt vector.
lapicw(SVR, ENABLE | (T_IRQ0 + IRQ_SPURIOUS));
// The timer repeatedly counts down at bus frequency
// from lapic[TICR] and then issues an interrupt.
// If xv6 cared more about precise timekeeping,
// TICR would be calibrated using an external time source.
lapicw(TDCR, X1);
lapicw(TIMER, PERIODIC | (T_IRQ0 + IRQ_TIMER));
lapicw(TICR, 10000000);
// Disable logical interrupt lines.
lapicw(LINT0, MASKED);
lapicw(LINT1, MASKED);
// Disable performance counter overflow interrupts
// on machines that provide that interrupt entry.
if(((lapic[VER]>>16) & 0xFF) >= 4)
lapicw(PCINT, MASKED);
// Map error interrupt to IRQ_ERROR.
lapicw(ERROR, T_IRQ0 + IRQ_ERROR);
// Clear error status register (requires back-to-back writes).
lapicw(ESR, 0);
lapicw(ESR, 0);
// Ack any outstanding interrupts.
lapicw(EOI, 0);
// Send an Init Level De-Assert to synchronise arbitration ID's.
lapicw(ICRHI, 0);
lapicw(ICRLO, BCAST | INIT | LEVEL);
while(lapic[ICRLO] & DELIVS)
;
// Enable interrupts on the APIC (but not on the processor).
lapicw(TPR, 0);
}
3. startothers函数
寻到了有多少个 CPU,而且也有了每个 CPU 的标识信息,就可以去启动它们了,直接来看 startothers 的代码:
entryother.S 是APs启动时要运行的代码,链接器将映像放在
_binary_entryother_start然后将其移动到0x7000然后利用for循环,循环启动APs
最后调用
lapicstartap()函数来启动 APs
static void
startothers(void)
{
extern uchar _binary_entryother_start[], _binary_entryother_size[];
uchar *code;
struct cpu *c;
char *stack;
// Write entry code to unused memory at 0x7000.
// The linker has placed the image of entryother.S in
// _binary_entryother_start.
code = P2V(0x7000);
memmove(code, _binary_entryother_start, (uint)_binary_entryother_size);
for(c = cpus; c < cpus+ncpu; c++){
if(c == mycpu()) // We've started already.
continue;
// Tell entryother.S what stack to use, where to enter, and what
// pgdir to use. We cannot use kpgdir yet, because the AP processor
// is running in low memory, so we use entrypgdir for the APs too.
stack = kalloc();
*(void**)(code-4) = stack + KSTACKSIZE;
*(void(**)(void))(code-8) = mpenter;
*(int**)(code-12) = (void *) V2P(entrypgdir);
lapicstartap(c->apicid, V2P(code));
// wait for cpu to finish mpmain()
while(c->started == 0)
;
}
}
4. lapicstartap函数
前面提到过BSP是通过发送信号给APs来启动其他cpu的,简单来说就是一个 CPU 通过写 LAPIC 的 ICR 寄存器来与其他 CPU 进行通信
其实下面一大堆我觉得看不懂也没差。。太低层了。只要知道下面这一点就行了
BSP通过向AP逐个发送中断来启动AP,首先发送INIT中断来初始化AP,然后发送SIPI中断来启动AP,发送中断使用的是写ICR寄存器的方式
void
lapicstartap(uchar apicid, uint addr)
{
int i;
ushort *wrv;
// "The BSP must initialize CMOS shutdown code to 0AH
// and the warm reset vector (DWORD based at 40:67) to point at
// the AP startup code prior to the [universal startup algorithm]."
outb(CMOS_PORT, 0xF); // offset 0xF is shutdown code
outb(CMOS_PORT+1, 0x0A);
wrv = (ushort*)P2V((0x40<<4 | 0x67)); // Warm reset vector
wrv[0] = 0;
wrv[1] = addr >> 4;
// "Universal startup algorithm."
// Send INIT (level-triggered) interrupt to reset other CPU.
lapicw(ICRHI, apicid<<24);
lapicw(ICRLO, INIT | LEVEL | ASSERT);
microdelay(200);
lapicw(ICRLO, INIT | LEVEL);
microdelay(100); // should be 10ms, but too slow in Bochs!
// Send startup IPI (twice!) to enter code.
// Regular hardware is supposed to only accept a STARTUP
// when it is in the halted state due to an INIT. So the second
// should be ignored, but it is part of the official Intel algorithm.
// Bochs complains about the second one. Too bad for Bochs.
for(i = 0; i < 2; i++){
lapicw(ICRHI, apicid<<24);
lapicw(ICRLO, STARTUP | (addr>>12));
microdelay(200);
}
}
5. 看一下entryother.S
上面的代码总共就干了两件事,1.找到所有的cpu信息、2. 利用IPI中断,也就是写ICR寄存器来启动其他的APS。
而启动APs是要执行boot代码的。对应的地址是0x7000。也就是entryother.S的代码
这个代码前面干的事情和entry.S基本一样的。需要注意的就是下面这两行
# Switch to the stack allocated by startothers()
movl (start-4), %esp
# Call mpenter()
call *(start-8)
// Other CPUs jump here from entryother.S.
static void
mpenter(void)
{
switchkvm(); //切换到内核页表
seginit(); // 初始化gdt
lapicinit(); // 初始化apic
mpmain();
}
static void mpmain(void)
{
cprintf("cpu%d: starting %d\n", cpuid(), cpuid());
idtinit(); // 加载GDT
xchg(&(mycpu()->started), 1); // 将started置1表启动完成了
scheduler(); // 开始调度进程执行程序了
}
可以看到,这里面所做的工作主要还是初始化建立环境,最后 CPU 这个结构体中的元素 started 置 1 表示这个 CPU 已经启动好了,这里就会通知 startothers 函数,可以启动下一个 AP 了。最后就是调用 scheduler() 可以开始调度执行程序了。
下面是startothers中的一段while循环。
// startothers
// wait for cpu to finish mpmain()
while(c->started == 0)
;
xv6学习笔记(5) : 锁与管道与多cpu的更多相关文章
- xv6学习笔记(4) : 进程调度
xv6学习笔记(4) : 进程 xv6所有程序都是单进程.单线程程序.要明白这个概念才好继续往下看 1. XV6中进程相关的数据结构 在XV6中,与进程有关的数据结构如下 // Per-process ...
- XV6学习笔记(1) : 启动与加载
XV6学习笔记(1) 1. 启动与加载 首先我们先来分析pc的启动.其实这个都是老生常谈了,但是还是很重要的(也不知道面试官考不考这玩意), 1. 启动的第一件事-bios 首先启动的第一件事就是运行 ...
- XV6学习笔记(2) :内存管理
XV6学习笔记(2) :内存管理 在学习笔记1中,完成了对于pc启动和加载的过程.目前已经可以开始在c语言代码中运行了,而当前已经开启了分页模式,不过是两个4mb的大的内存页,而没有开启小的内存页.接 ...
- xv6学习笔记(3):中断处理和系统调用
xv6学习笔记(3):中断处理和系统调用 1. tvinit函数 这个函数位于main函数内 表明了就是设置idt表 void tvinit(void) { int i; for(i = 0; i & ...
- [C#学习笔记]lock锁的解释与用法
写在前面 前几时在写业务代码的时候,看到有用到lock这个方法的,而我竟然并不知道是做什么用的,所以查找了许多博客文章,弄懂了百分之七八十,在此做下笔记. 感谢博客 http://www.cnblog ...
- Oracle学习笔记七 锁
锁的概念 锁是数据库用来控制共享资源并发访问的机制. 锁用于保护正在被修改的数据 直到提交或回滚了事务之后,其他用户才可以更新数据 对数据的并发控制,保证一致性.完整性.
- linux c学习笔记----互斥锁属性
转自:http://lobert.iteye.com/blog/1762844 互斥锁属性 使用互斥锁(互斥)可以使线程按顺序执行.通常,互斥锁通过确保一次只有一个线程执行代码的临界段来同步多个线程. ...
- Redis学习笔记~分布锁的使用
回到目录 分布锁主要用在多进程共同访问同一个资源时候,用来保持同一时间段只能有一个进程执行,同时避免了并发冲突的出现,这在很多场景都会用到,像秒杀库存,抽奖库存,多操作者处理一家公司等. void T ...
- 《ASP.NET MVC4 WEB编程》学习笔记------乐观锁和悲观锁
摘要:对数据库的并发访问一直是应用程序开发者需要面对的问题之一,一个好的解决方案不仅可以提供高的可靠性还能给应用程序的性能带来提升.下面我们来看一下Couchbase产品市场经理Don Pinto结合 ...
随机推荐
- 八大排序算法~简单选择排序【记录下标k变量的作用】
八大排序算法~简单选择排序[记录下标k变量的作用] 1,思想:打擂台法,数组中的前n-1个元素依次上擂台"装嫩",后边的元素一个挨着一个不服,一个一个上去换掉它 2,优化:通过记录 ...
- html自定义加载动画
整体代码 HTML 实现自定义加载动画,话不多说如下代码所示: <!DOCTYPE html> <html lang="en"> <head> ...
- 【剑指offer】55 - I. 二叉树的深度
剑指 Offer 55 - I. 二叉树的深度 知识点:二叉树,递归 题目描述 输入一棵二叉树的根节点,求该树的深度.从根节点到叶节点依次经过的节点(含根.叶节点)形成树的一条路径,最长路径的长度为树 ...
- 【洛谷P2800又上锁妖塔】动态规划
分析 考虑上一层还是上两层还是爬上去 AC代码 #include <bits/stdc++.h> using namespace std; int f[1000005],a[1000005 ...
- POJ1934 Trip 题解
LCS 模板,但要输出具体方案,这就很毒瘤了. 神奇的预处理:fa[i][j]表示在 \(a\) 串的前 \(i\) 个字符中,字母表第 \(j\) 个字母最晚出现的位置,fb[i][j]同理. 这样 ...
- wait()、notify()、notifyAll()(三)
有新理解持续更新 轮询 线程本身是操作系统中独立的个体,但是线程与线程之间不是独立的个体,因为它们彼此之间要相互通信和协作. 想像一个场景,A线程做int型变量i的累加操作,B线程等待i到了10000 ...
- ODOO14笔记---系统升级崩溃后进不去系统解决办法
一.通过pycharm升级模块: 2.对于已安装odoo模块,升级报错系统崩溃的解决办法:---执行以下SQL update ir_module_module set state ='ins ...
- Go是一门什么样的语言?
Go语言基本介绍 首先Go语言诞生于2007年由谷歌公司研发,2009年开源,2012年推出1.0版本,Go是一种语言层面支持并发(Go最大的特色.天生支持并发).内置runtime,支持垃圾回收(G ...
- markdown文档编写基础
Markdown快速入门教程 ###########来源:https://zhuanlan.zhihu.com/p/84918488 ###########来源:https://github.com/ ...
- git从远程仓库里拉取一条本地不存在的分支
查看远程分支和本地分支 git branch -va 当我想从远程仓库里拉取一条本地不存在的分支时: git checkout -b 本地分支名 origin/远程分支名 例如: 切换远程分支 git ...