Windows核心编程笔记之处理字符串
0x01 ANSI 和宽字符定义
// ANSI 字符定义
CHAR varChar_1 = 'a'; // #typedef char CHAR
CHAR varChar_2[] = "ABCDEFG";
CHAR varChar_3[20] = "ABCDEFG";
// 宽字符定义
WCHAR varWChar_1 = L'a'; // #typedef wchar_t WCHAR
WCHAR varWChar_2[] = L"ABCDEFG";
WCHAR varWChar_3[20] = L"ABCDEFG";
0x02 字符串处理函数
- 不安全的字符串处理函数
CHAR buffer[10] = { 0 }; // 初始化字符串
CHAR overflow[] = "AAAAAAAAAAAAAAAAAAAA"; // 造成溢出的数据
int BufferSize = 20; // 控制溢出的整数
memset(buffer, 0x41, BufferSize); // BufferSize 过大导致栈溢出
strcpy(buffer, overflow); // overflow 过大导致栈溢出
strcat(buffer, overflow); // overflow + buffer 的长度过大导致栈溢出
- 安全的字符串处理函数
CHAR buffer[10] = { 0 }; // 初始化字符串
CHAR overflow[] = "AAAAAAAAAAAAAAAAAAAAAA"; // 造成溢出的数据
errno_t res = NULL;
// strcpy_s
res = strcpy_s(buffer, overflow); // 只有两个参数,那么会自动检测 overflow 的大小是否超过 buffer
res = strcpy_s(buffer, 5, overflow); // 限制复制的大小为 5 个字节
// strcat_s
res = strcat_s(buffer, overflow); // 由于 overflow 大于 buffer,所以引发异常
异常如下
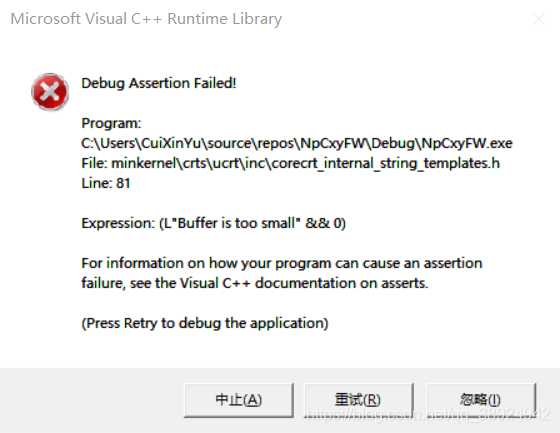
0x03 其他安全的字符串处理函数
- StringCchCat(Ex),安全的拼接字符串
- https://docs.microsoft.com/en-us/previous-versions/windows/embedded/ms860411(v=msdn.10)
WCHAR Buffer[10] = L"AAAAAA";
WCHAR LinkBuffer[] = L"A";
STRSAFE_LPWSTR *DestEnd = NULL; // #typedef wchar_t *STRSAFE_LPWSTR
size_t size = NULL;
// 安全的字符串拼接函数 StringCchCat
HRESULT res;
res = StringCchCat((STRSAFE_LPWSTR)Buffer, lstrlen(Buffer) + lstrlen(LinkBuffer) + 1, (STRSAFE_LPWSTR)LinkBuffer);
res = StringCchCatEx(
(STRSAFE_LPWSTR)Buffer, // 目标缓冲区
lstrlen(Buffer) + lstrlen(LinkBuffer) + 1, // 目标缓冲区大小,务必等于 Buffer + LinkBuffer + 1 的大小,1 为终止符
(STRSAFE_LPWSTR)LinkBuffer, // 源缓冲区,用于拼接至 Buffer 后
DestEnd, // Buffer 结尾的指针
&size, // 未使用的字符
STRSAFE_NO_TRUNCATION | STRSAFE_FILL_BEHIND_NULL // 如果函数成功,则使用dwFlags(0)的低字节来填充终止空字符后的pszDest的未初
// 如果函数失败,则pszDest不受影响。原始内容中没有添加任何内容
);
// cout << "DestEnd: " << DestEnd << endl;
// cout << "size: " << size << endl;
- StringCchCopy(Ex),安全的拷贝字符串
- https://docs.microsoft.com/en-us/previous-versions/windows/embedded/ms860420(v=msdn.10)
WCHAR DestBuffer[10] = { 0 };
WCHAR SrcBuffer[] = L"AAAAAAAAA";
STRSAFE_LPWSTR *DestEnd = NULL;
size_t size = NULL;
HRESULT res;
res = StringCchCopy((STRSAFE_LPWSTR)DestBuffer, lstrlen(SrcBuffer) + 1, SrcBuffer);
res = StringCchCopyEx(
(STRSAFE_LPWSTR)DestBuffer, // 目标缓冲区
lstrlen(SrcBuffer) + 1, // 目标缓冲区大小,务必等于 Buffer + LinkBuffer + 1 的大小,1 为终止符
SrcBuffer, // 源字符串地址
DestEnd, // 源字符串结尾指正
&size, // 目标缓冲区未使用的字节
STRSAFE_NO_TRUNCATION | STRSAFE_FILL_BEHIND_NULL); // 如果函数成功,则使用dwFlags(0)的低字节来填充终止空字符后的pszDest的未初始化部分
// 与STRSAFE_NULL_ON_FAILURE的情况一样,如果函数失败,则pszDest设置为空字符串(TEXT(""))
/*
cout << "DestEnd: " << DestEnd << endl;
cout << "size: " << size << endl;
*/
- StringCchPrintf(Ex),安全的格式化字符串
- https://docs.microsoft.com/en-us/previous-versions/windows/embedded/ms860435(v=msdn.10)
WCHAR DestBuffer[10] = { 0 };
HRESULT res;
res = StringCchPrintf((STRSAFE_LPWSTR)DestBuffer, sizeof(DestBuffer) / 2, TEXT("%d + %d = %d"), 1, 2, 3);
STRSAFE_LPWSTR *DestEnd = NULL;
size_t size;
res = StringCchPrintfEx(
(STRSAFE_LPWSTR)DestBuffer, // 目标缓冲区
sizeof(DestBuffer) / 2, // 目标缓冲区大小
DestEnd, // 目标缓冲区结尾指针
&size, // 目标缓冲区未使用的字符数
STRSAFE_NO_TRUNCATION | STRSAFE_FILL_BEHIND_NULL, // 如果函数成功,则使用dwFlags(0)的低字节来填充终止空字符后的pszDest的未初始化部分
// 与STRSAFE_NULL_ON_FAILURE的情况一样,如果函数失败,则pszDest设置为空字符串(TEXT(""))
TEXT("%d + %d = %d"), 1, 2, 3 // 格式化字符
);
if (res == S_OK)
{
cout << "有足够的空间可以将结果复制到pszDest而不进行截断,并且缓冲区以空值终止" << endl;
}
else if (res == STRSAFE_E_INSUFFICIENT_BUFFER)
{
cout << "cchDest 是 0 或比 STRSAFE_MAX_CCH 更大,或目标缓冲区是满的" << endl;
}
else if (res == STRSAFE_E_INVALID_PARAMETER)
{
cout << "由于缓冲区空间不足,复制操作失败" << endl;
}
- StrFormatKBSize(StrFormatByteSize),数值大小转换成字符串
https://docs.microsoft.com/zh-cn/windows/desktop/api/shlwapi/nf-shlwapi-strformatkbsizea
#include <Windows.h>
#include <iostream>
#include <String.h>
#include <shlwapi.h>
#pragma comment (lib, "Shlwapi.lib")
using namespace std;
int main(int argc, char *argv[])
{
LONGLONG var_1 = 521;
WCHAR Buffer[10] = { 0 }; // Buffer 初始化
// StrFormatKBSize 将数值转换为字符串,该字符串表示以千字节为单位表示的大小值
PTSTR res = StrFormatKBSize(
var_1, // 需要转换的数值
(PWSTR)Buffer, // 指向缓冲区的指针
sizeof(Buffer) / 2 // pszBuf的大小,以字符为单位
);
if (res == NULL)
{
cout << "调用失败" << endl;
}
else
{
cout << "字符串的地址: " << res << endl;
}
return 0;
}
- CompareString(一般比较字符串)+ CompareStringOrdinal(为了比较编程类的字符串)
- https://docs.microsoft.com/zh-cn/windows/desktop/api/stringapiset/nf-stringapiset-comparestringex
- https://docs.microsoft.com/zh-cn/windows/desktop/api/stringapiset/nf-stringapiset-comparestringordinal
WCHAR String1[] = L"ABCDEFG"; // 定义两个相等的字符串
WCHAR String2[] = L"AbCdEfG";
int res = CompareStringEx(
LOCALE_NAME_SYSTEM_DEFAULT, // 设置为当前操作系统区域设置的名称
NORM_IGNORECASE | NORM_IGNORESYMBOLS, // 忽略大小写 | 忽略符号和标点符号
(LPCWCH)&String1, // 用于比较的字符串 1
sizeof(String1) / 2, // 用于比较的字符串 1 的大小
(LPCWCH)&String2, // 用于比较的字符串 2
sizeof(String2) / 2, // 用于比较的字符串 2 的大小
NULL, // 保留位,必须设置为 NULL
NULL, // 同上
0 // 同上
);
if (res != 0) // CompareStringEx 调用失败返回则 0
{
switch (res)
{
case CSTR_LESS_THAN:
cout << "lpString1指示的字符串的词汇值小于lpString2指示的字符串" << endl; break;
case CSTR_EQUAL:
cout << "由lpString1指示的字符串在词汇值中等效于由lpString2指示的字符串" << endl; break;
case CSTR_GREATER_THAN:
cout << "lpString1指示的字符串的词汇值大于lpString2指示的字符串" << endl; break;
}
}
else
{
DWORD error = GetLastError();
if (error == ERROR_INVALID_FLAGS)
{
cout << "为标志提供的值无效: " << endl;
}
else if(error == ERROR_INVALID_PARAMETER)
{
cout << "任何参数值都无效: " << endl;
}
}
WCHAR String1[] = L"ABCDEFG";
WCHAR String2[] = L"AbCdEfG";
int res = CompareStringOrdinal((LPCWCH)String1, sizeof(String1) / 2, (LPCWCH)String2, sizeof(String2) / 2, TRUE);// TRUE 为不区分大小写的比较
if (res != 0)
{
switch (res)
{
case CSTR_LESS_THAN:
cout << "lpString1指示的值小于lpString2指示的值" << endl; break;
case CSTR_EQUAL:
cout << "lpString1指示的值等于lpString2指示的值" << endl; break;
case CSTR_GREATER_THAN:
cout << "lpString1指示的值大于lpString2指示的值" << endl; break;
}
}
else
{
DWORD res = GetLastError();
if (res == ERROR_INVALID_PARAMETER)
{
cout << "任何参数值都无效" << endl;
}
}
- MultiByteToWideChar(用于将 ANSI 字符转换成宽字节字符),WideCharToMultiByte函(将宽字节字符转换成 ANSI 字符)
- https://docs.microsoft.com/en-us/previous-versions/bb202786(v=msdn.10)
- https://docs.microsoft.com/zh-cn/windows/desktop/api/stringapiset/nf-stringapiset-widechartomultibyte
CHAR BeforeConversion[] = "ABCDEFG";
WCHAR AfterConversion[10] = { 0 };
int res = MultiByteToWideChar(
CP_ACP, // ANSI 代码页
NULL, // 影响读音符号的字符,一般设置为 NULL
(LPCCH)BeforeConversion, // 需要转换的 ANII 字符
-1, // 自动计算函数大小
(LPWSTR)AfterConversion, // 转换过后的字符串缓冲区
sizeof(AfterConversion) // 转换过后的字符串缓冲区的大小
);
if (res == 0) // 函数调用失败返回 0
{
cout << "转换失败" << endl;
}
WCHAR BeforeConverion[] = L"ABCDEFG";
CHAR AfterConversion[10] = { 0 };
CHAR DefaultChar = '*';
BOOL UserDefaultChar = NULL;
int res = WideCharToMultiByte(
CP_UTF8, // 使用 CP_UTF8 代码页完成从宽字节到多字节的转换
NULL, // 一般为 NULL
(LPCWCH)BeforeConverion, // 需要转换的字符串的地址
-1, // 自动计算转换字符串的大小
(LPSTR)AfterConversion, // 转换完成时字符串储存地址
sizeof(AfterConversion), // 储存地址大小
(LPCCH)DefaultChar, // 遇到无法转换的字符时用什么代替
(LPBOOL)UserDefaultChar // 转换成功返回 FALSE,有一个或者多个字符无法转换时设置为 TRUE
);
if (res != 0 && UserDefaultChar == FALSE)
{
cout << "转换成功" << endl;
}
else // 调用之后返回 0 表示失败
{
switch (res)
{
case ERROR_INSUFFICIENT_BUFFER:
cout << "提供的缓冲区大小不够大,或者错误地设置为NULL" << endl; break;
case ERROR_INVALID_FLAGS:
cout << "为标志提供的值无效" << endl; break;
case ERROR_INVALID_PARAMETER:
cout << "任何参数值都无效" << endl; break;
case ERROR_NO_UNICODE_TRANSLATION:
cout << "在字符串中找到无效的Unicode" << endl; break;
}
}
- IsTextUnicode(用于判断是 ANSI 字符还是宽字节字符)
CHAR JudgeStr[] = "ABCDEFG"; // 测试字符串
int Result = IS_TEXT_UNICODE_REVERSE_MASK; // 是否包含宽字界字符标志位
BOOL res = IsTextUnicode((const void *)JudgeStr, sizeof(JudgeStr), (LPINT)&Result);
if (res != 0)
{
cout << "包含宽字节字符" << endl;
}
else
{
cout << "为 ANSI 字符" << endl;
}
Windows核心编程笔记之处理字符串的更多相关文章
- Windows核心编程笔记之进程
改变进程基址,获取进程基址 #include <Windows.h> #include <iostream> #include <strsafe.h> #inclu ...
- Windows核心编程笔记之内核对象
0x01 子进程继承父进程内核对象句柄 父进程 #include <Windows.h> #include <iostream> #include <strsafe.h& ...
- Windows核心编程笔记之错误处理
0x01 GetLastError() 函数用于获取上一个操作的错误代码 #include <Windows.h> #include <iostream> using name ...
- Windows核心编程笔记之作业
创建作业,并加以限制 HANDLE WINAPI CreateJob() { BOOL IsInJob = FALSE; DWORD ErrorCode = NULL; // 不能将已经在作业中的进程 ...
- 《Windows核心编程》读书笔记 上
[C++]<Windows核心编程>读书笔记 这篇笔记是我在读<Windows核心编程>第5版时做的记录和总结(部分章节是第4版的书),没有摘抄原句,包含了很多我个人的思考和对 ...
- C++Windows核心编程读书笔记
转自:http://www.makaidong.com/%E5%8D%9A%E5%AE%A2%E5%9B%AD%E6%96%87/71405.shtml "C++Windows核心编程读书笔 ...
- 【转】《windows核心编程》读书笔记
这篇笔记是我在读<Windows核心编程>第5版时做的记录和总结(部分章节是第4版的书),没有摘抄原句,包含了很多我个人的思考和对实现的推断,因此不少条款和Windows实际机制可能有出入 ...
- windows核心编程---第二章 字符和字符串处理
使用vc编程时项目-->属性-->常规栏下我们可以设置项目字符集合,它可以是ANSI(多字节)字符集,也可以是unicode字符集.一般情况下说Unicode都是指UTF-16.也 ...
- Windows核心编程第二章,字符串的表示以及宽窄字符的转换
目录 Windows核心编程,字符串的表示以及宽窄字符的转换 1.字符集 1.1.双字节字符集DBCS 1.2 Unicode字符集 1.3 UTF-8编码 1.4 UTF - 32编码. 1.5 U ...
随机推荐
- 洛谷P3285 [SCOI2014]方伯伯的OJ 动态开点平衡树
洛谷P3285 [SCOI2014]方伯伯的OJ 动态开点平衡树 题目描述 方伯伯正在做他的 \(Oj\) .现在他在处理 \(Oj\) 上的用户排名问题. \(Oj\) 上注册了 \(n\) 个用户 ...
- 顺序表及基本操作(C语言)
#include <stdio.h> #include <stdlib.h> //基本操作函数用到的状态码 #define TRUE 1; #define FALSE 0; # ...
- NET 5.0 Swagger API 自动生成MarkDown文档
目录 1.SwaggerDoc引用 主要接口 接口实现 2.Startup配置 注册SwaggerDoc服务 注册Swagger服务 引用Swagger中间件 3.生成MarkDown 4.生成示例 ...
- LeetCode 175. Combine Two Tables 【MySQL中连接查询on和where的区别】
一.题目 175. Combine Two Tables 二.分析 连接查询的时候要考虑where和on的区别 where : 查询时,连接的时候是必须严格满足条件的,满足了才会加入到临时表中. on ...
- Xshell(远程)连接不上linux服务器(防火墙介绍)
一.原因 远程(ssh)连接不上linux服务器的大多数原因都是因为本地服务器的防火墙策略导致的,因此我们想ssh远程能够连接上服务器,有两种方法: 修改防火墙策略 关闭防火墙 二.防火墙服务介绍 1 ...
- 2.掌握numpy数组
一.改变数组形态 reshape()--通过改变数组的维度改变数组形态 import numpy as np Array=np.arange(1,17,1) Array Array_1=np.aran ...
- Mac下安装lightgb并在jupyter中使用
1.先安装cmake和gcc brew install cmake brew install gcc 2.下载后确定自己的gcc版本 cd /usr/local/opt/gcc/lib/gcc/ 看到 ...
- C语言之动态内存管理
C语言之动态内存管理 大纲: 储存器原理 为什么存在动态内存的开辟 malloc() free() calloc() realloc() 常见错误 例题 柔性数组 零(上).存储器原理 之前我们提到了 ...
- 前端富文本编辑器vue + tinymce
之前有项目需要用到富文本编辑器,在网上找了好几个后,最终选择了这个功能强大,扩展性强的tinymce tinymce中文文档地址(不全):http://tinymce.ax-z.cn/ tinymce ...
- Distributed | MapReduce
最近终于抽出时间开始学习MIT 6.824,本文为我看MapReduce论文和做lab后的总结. [MapReduce英文论文] lab要用到go语言,这也是我第一次接触.可以参考go语言圣经学习基本 ...