图解AI数学基础 | 概率与统计

作者:韩信子@ShowMeAI
教程地址:http://www.showmeai.tech/tutorials/83
本文地址:http://www.showmeai.tech/article-detail/163
声明:版权所有,转载请联系平台与作者并注明出处
1.概率论及在AI中的使用
概率(Probability),反映随机事件出现的可能性大小。事件\(A\)出现的概率,用\(P(A)\)表示。
概率论(Probability Theory),是研究随机现象数量规律的数学分支,度量事物的不确定性。

机器学习大部分时候处理的都是不确定量或随机量。因此,相对计算机科学的其他许多分支而言,机器学习会更多地使用概率论。很多典型的机器学习算法模型也是基于概率的,比如朴素贝叶斯(Naive Bayesian)等。
在人工智能领域,概率论有广泛的应用:
- 可以借助于概率方法设计算法(概率型模型,如朴素贝叶斯算法)。
- 可以基于概率与统计进行预测分析(如神经网络中的softmax)。
2.随机变量(Random Variable)
简单地说,随机变量是指随机事件的数量表现,是可以『随机』地取不同值的『变量』。通常,用大写字母来表示随机变量本身,而用带数字下标的小写字母来表示随机变量能够取到的值。
- 例如,\(X\)为随机变量,\(x_{1}\)、\(x_{2}\)、\(x_{i}\)是随机变量\(X\)可能的取值。
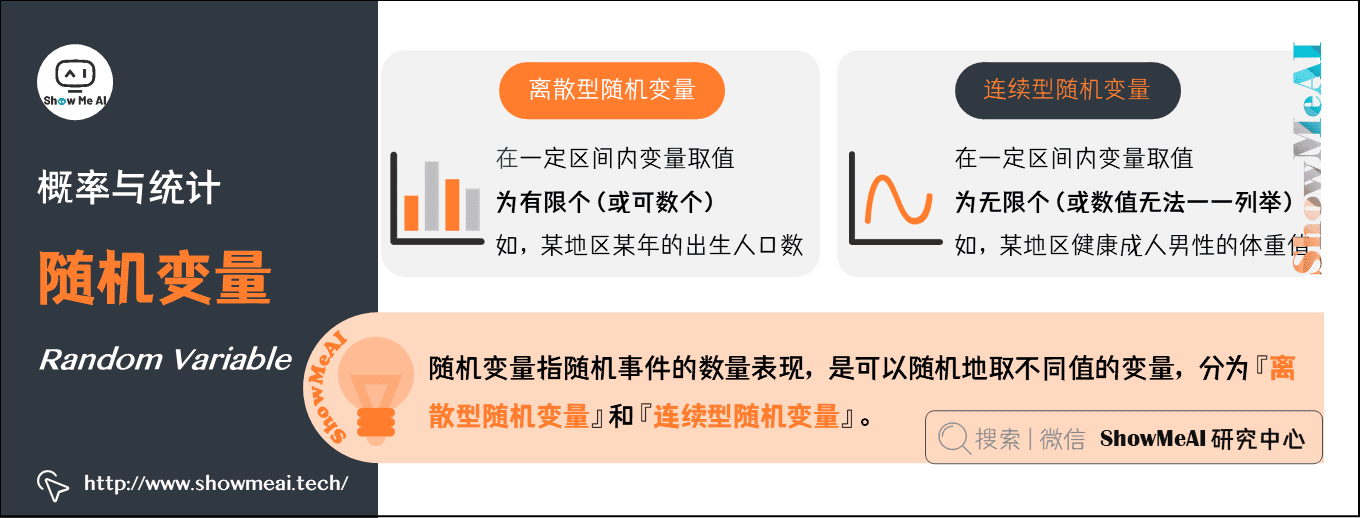
随机变量可以分为『离散型随机变量』和『连续型随机变量』:
离散型随机变量(discrete random variable):即在一定区间内变量取值为有限个(或可数个)。例如,某地区某年的出生人口数。
连续型随机变量(continuous random variable):即在一定区间内变量取值为无限个(或数值无法一一列举出来)。例如,某地区男性健康成人的体重值。
3.随机向量(Random Vector)

将几个随机变量按顺序放在一起,组成向量的形式,就是随机向量。
在样本空间全部都一样的情况下,一个\(n\)维的随机向量是\(x \overrightarrow{(\xi)}=\left(\begin{array}{c}
x_{1}(\xi) \\
x_{2}(\xi) \\
\cdots \\
x_{n}(\xi)
\end{array}\right)\)
其中,\(\xi\)就是样本空间中的样本点。随机变量是1维随机向量的特殊情况。
4.概率分布(Probability Distribution)
广义上,概率分布用于表述随机变量取值的概率规律。或者说,给定某随机变量的取值范围,概率分布表示该随机事件出现的可能性。
狭义地,概率分布指随机变量地概率分布函数,也称累积分布函数(Cumulative Distribution Function,CDF)。

离散型随机变量的概率分布:
使用分布列描述离散型随机变量的概率分布,即给出离散型随机变量的全部取值及每个值的概率。
常见的离散型随机变量的分布有:单点分布、0-1分布、几何分布、二项分布、泊松分布等。
连续型随机变量的概率分布:
如果随机变量\(X\)的分布函数为\(F(x)\),存在非负函数\(f (x)\)使对于任意实数\(x\)有\(F(x)=\int_{-\infty}^{x} f(t) d t\),则称\(X\)为连续型随机变量 ,其中函数\(f(x)\)称为\(X\)的概率密度函数。
常见的连续型随机变量的分布有:正态分布、均匀分布、指数分布、\(t-\)分布、\(F-\)分布、\(\xi^{2}-\)分布等。
机器学习中一个典型的概率分布应用,是分类问题中,很多模型最终会预估得到样本属于每个类别的概率,构成1个概率向量,表征类别概率分布。
5.条件概率(Conditional Probability)
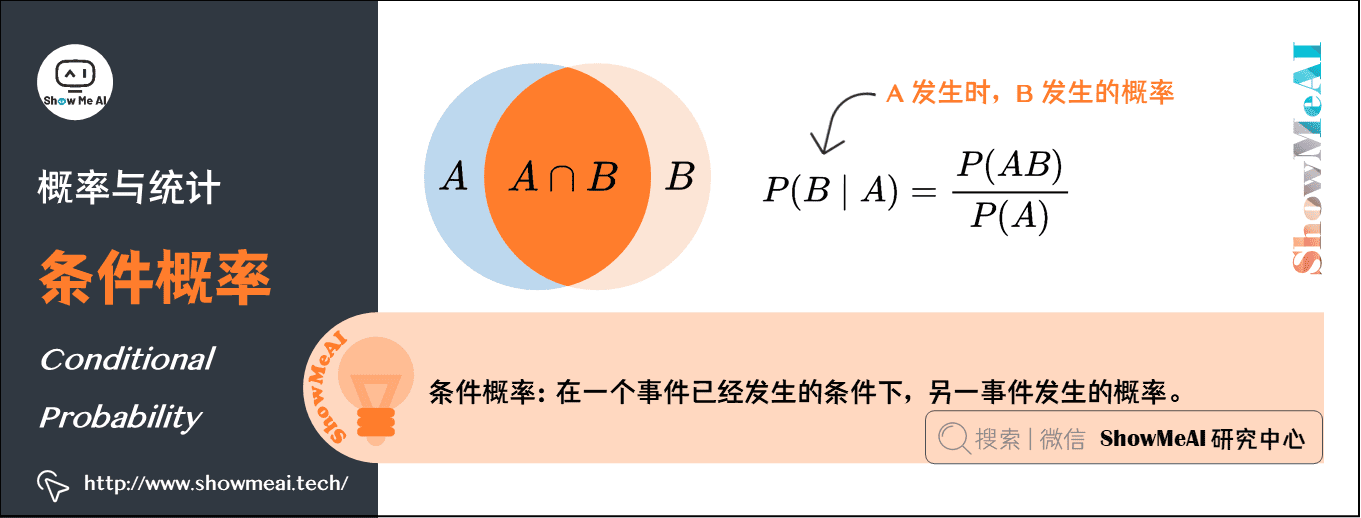
很多情况下我们感兴趣的是,某个事件在给定其它事件发生时出现的概率,这种概率叫条件概率。
给定\(A\)时\(B\)发生的概率记为\(P(B \mid A)\),概率的计算公式为:\(P(B \mid A)=\frac{P(A B)}{P(A)}\)
6.贝叶斯公式(Bayes’ Theorem)
先看看什么是“先验概率”和“后验概率”,以一个例子来说明:
先验概率:某疾病在人群中发病率为0.1%,那某人没有做检验之前,预计患病率为\(P(\text { 患病 })=0.1 \%\),这个概率就叫做『先验概率』。
后验概率:该疾病的检测准确率为95%,即该病患者检测显示阳性的概率为95%(检测显示阴性的概率为5%),即\(P(\text { 显示阳性|患病 })=95\%\);或者说未患病的检测者,检测结果显示阴性的概率为95%,检测显示阳性的概率为5%。那么,检测显示为阳性时,此人的患病概率\(P(\text { 患病| 显示阳性})\)就叫做『后验概率』。
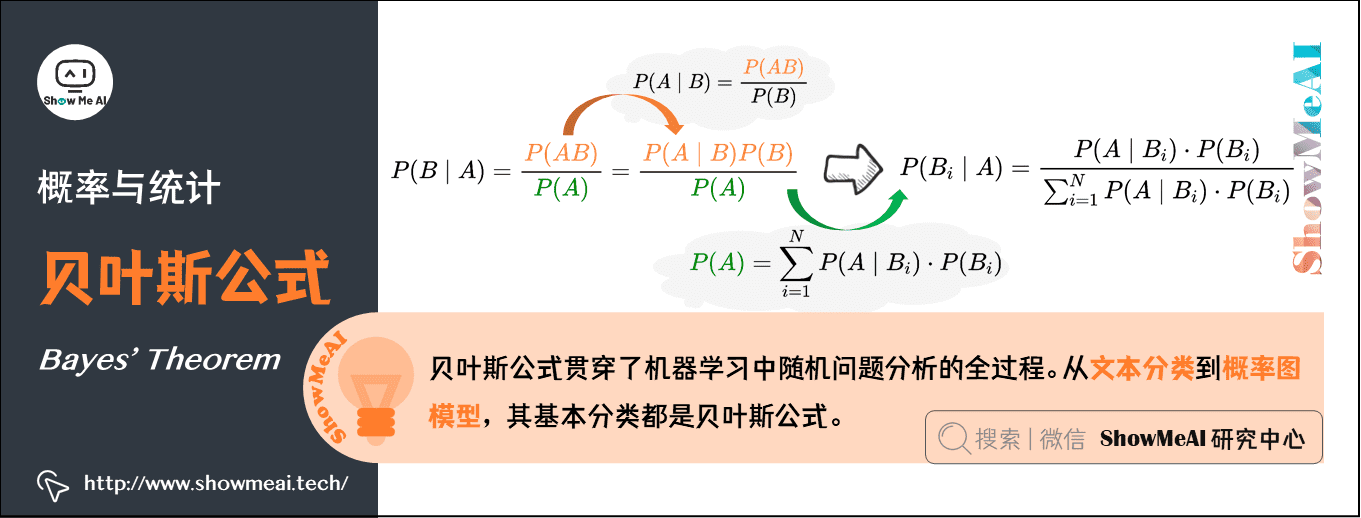
贝叶斯公式:贝叶斯提供了一种利用『先验概率』计算『后验概率』的方法:
条件概率公式:\(P(B \mid A)=\frac{P(A B)}{P(A)}\),\(P(A \mid B)=\frac{P(A B)}{P(B)}\)
由条件概率公式变换得到乘法公式:\(P(A B)=P(B \mid A) P(A)=P(A \mid B) P(B)\)
将条件概率公式和乘法公式结合:\(P(B \mid A)=\frac{P(A \mid B) \cdot P(B)}{P(A)}\)
引入全概率公式:\(P(A)=\sum_{i=1}^{N} P\left(A \mid B_{i}\right) \cdot P\left(B_{i}\right)\)
将全概率代入\(P(B \mid A)\),可以得到贝叶斯公式:\(P\left(B_{i} \mid A\right)=\frac{P\left(A \mid B_{i}\right) \cdot P\left(B_{i}\right)}{\sum_{i=1}^{N} P\left(A \mid B_{i}\right) \cdot P\left(B_{i}\right)}\)
上述例子的计算结果:
\(\begin{aligned}
P(\text { 患病 } \mid \text { 显示阳性 }) &=\frac{P(\text { 显示阳性|患病 }) P(\text { 患病 })}{P(\text { 显示阳性 })} \\
&=\frac{P(\text { 显示阳性|患病 }) P(\text { 患病 })}{P(\text { 显示阳性|患病 }) P(\text { 患病 })+P(\text { 显示阳性|无病) } P(\text { 无病 })} \\
&=\frac{95 \% * 0.1 \%}{95 \% * 0.1 \%+5 \% * 99.9 \%}=1.86 \%
\end{aligned}\)
贝叶斯公式贯穿了机器学习中随机问题分析的全过程。从文本分类到概率图模型,其基本分类都是贝叶斯公式。
期望、方差、协方差等主要反映数据的统计特征。机器学习的一个很大应用就是数据挖掘等,因此这些基本的统计概念也是很有必要掌握。另外,像后面的EM算法中,就需要用到期望的相关概念和性质。
7.期望(Expectation)
在概率论和统计学中,数学期望是试验中每次可能结果的概率乘以其结果的总和。期望是最基本的数学特征之一,反映随机变量平均值的大小。
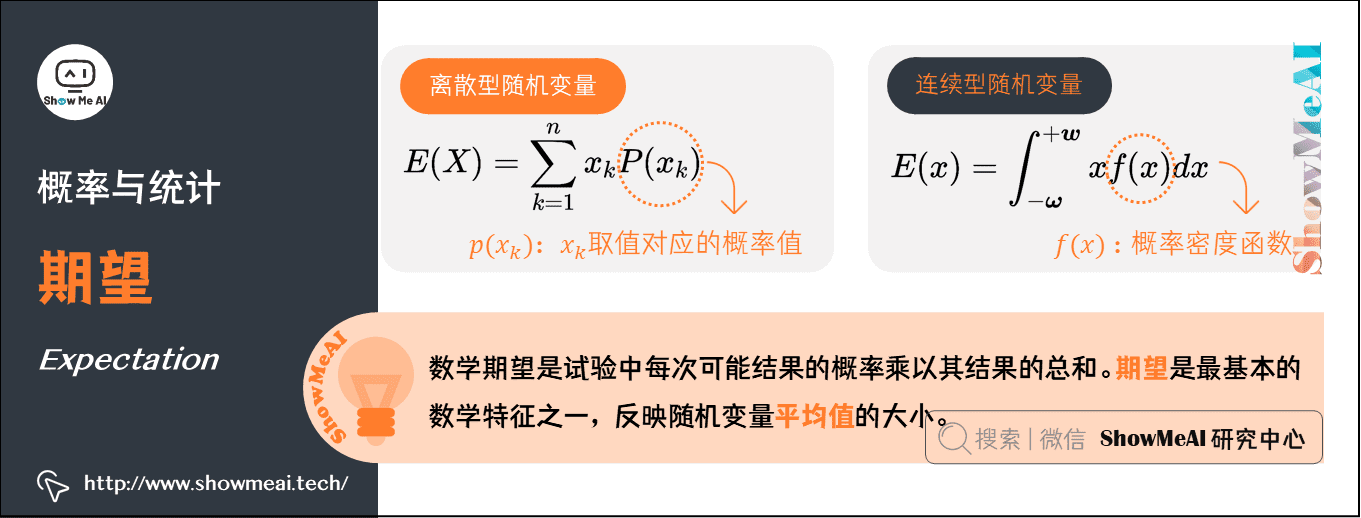
假设\(X\)是一个离散型随机变量,其可能的取值有\(\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}\),各取值对应的概率取值为\(P\left(x_{k}\right)\),\(k=1, 2, \ldots, n\)。其数学期望被定义为:
\]
假设\(x\)是一个连续型随机变量,其概率密度函数为\(f(x)\),其数学期望被定义为:
\]
8.方差(Variance)
在概率论和统计学中,样本方差,是各个样本数据分别与其平均数之差的平方和的平均数。方差用来衡量随机变量与其数学期望之间的偏离程度。
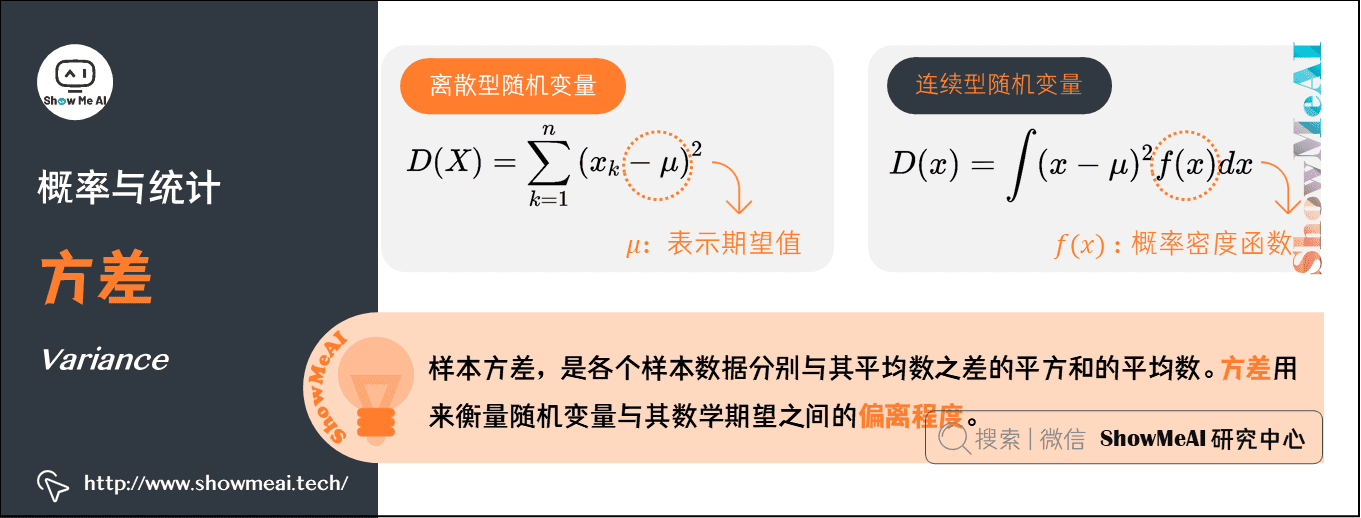
离散型:(\(\mu\)表示期望)
\]
一个快速计算方差的公式(即平方的期望减去期望的平方):
\]
连续型:(\(\mu\)表示期望)
\]
9.协方差(Covariance)

在概率论和统计学中,协方差被用于衡量两个随机变量\(X\)和\(Y\)之间的总体误差。期望值分别为\(E[X]\)与\(E[Y]\)的两个实随机变量\(X\)与\(Y\)之间的协方差为:
\]
以下是几个常用等式:
\(Cov(X, Y)=Cov(Y, X)\)
\(Cov(X, X)=D(X)\)
\(D(X+Y)=D(X)+D(Y)+2 Cov(X, Y)\)
\(Cov(X, Y)=E(X Y)-E(X) E(Y)\)
10.相关系数(Correlation coefficient)

相关系数是最早由统计学家卡尔·皮尔逊设计的统计指标,用以研究变量之间线性相关程度。相关系数有多种定义方式,较为常用的是皮尔逊相关系数。从协方差中会得到引申,就是关联系数,即:(\(\sigma\)是标准差)
\]
这个公式还有另外的一个表达形式:
\]
11.常见分布函数
1)伯努利分布(Bernoulli Distribution)(离散型)
在概率论和统计学中,伯努利分布也叫0-1分布,是单个二值型离散随机变量的分布。
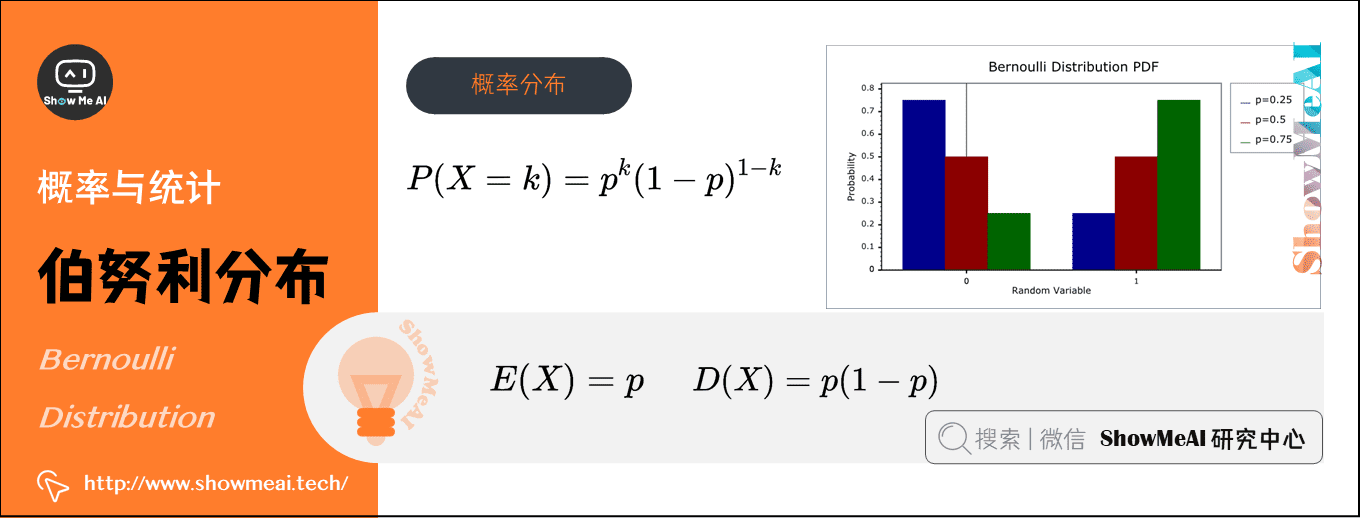
- 概率分布函数:\(P(X=k)=p^{k}(1-p)^{1-k}\)
- 期望:\(E(X)=p\)
- 方差:\(D(X)=p(1-p)\)
2)几何分布(Geometric Distribution)(离散型)
在概率论和统计学中,几何分布是离散型概率分布,数学符号为\(X\sim G(p)\)。其定义为:在\(n\)次伯努利试验中,试验\(k\)次才得到第一次成功的机率(即前\(k-1\)次皆失败,第\(k\)次成功的概率)
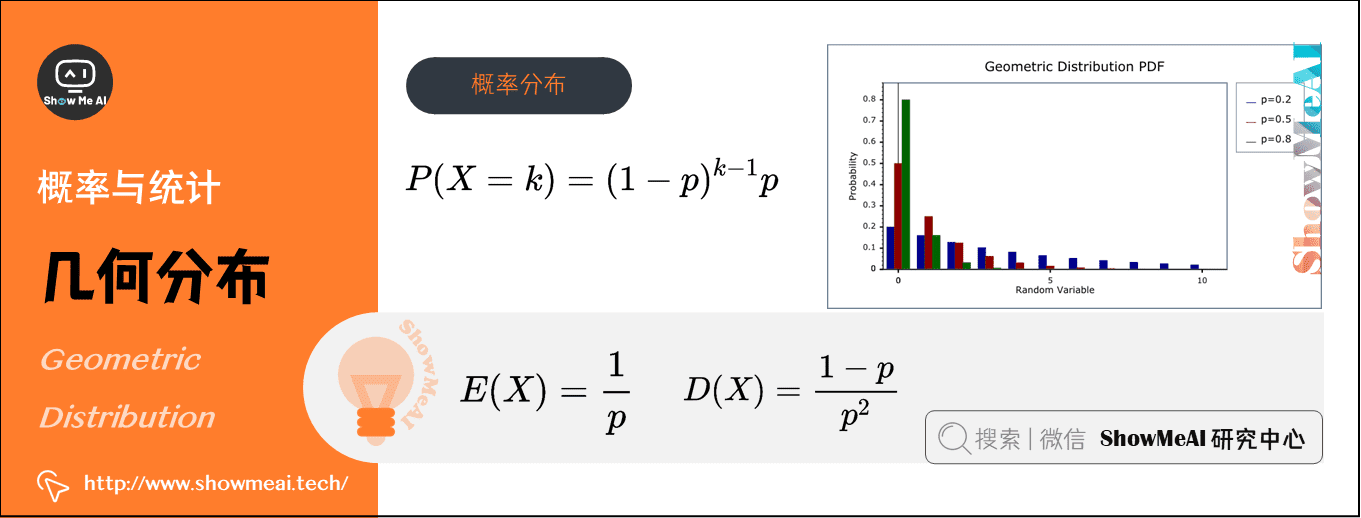
- 概率分布函数:\(P(X=k)=(1-p)^{k-1} p\)
- 期望:\(E(X)=\frac{1}{p}\)
- 方差:\(D(X)=\frac{1-p}{p^{2}}\)
3)二项分布(Binomial Distribution)(离散型)
在概率论和统计学中,二项分布即重复\(n\)次伯努利试验,各次试验之间都相互独立,并且每次试验中只有两种可能的结果,而且这两种结果发生与否相互对立,数学符号为\(X∼B(n,p)\)。
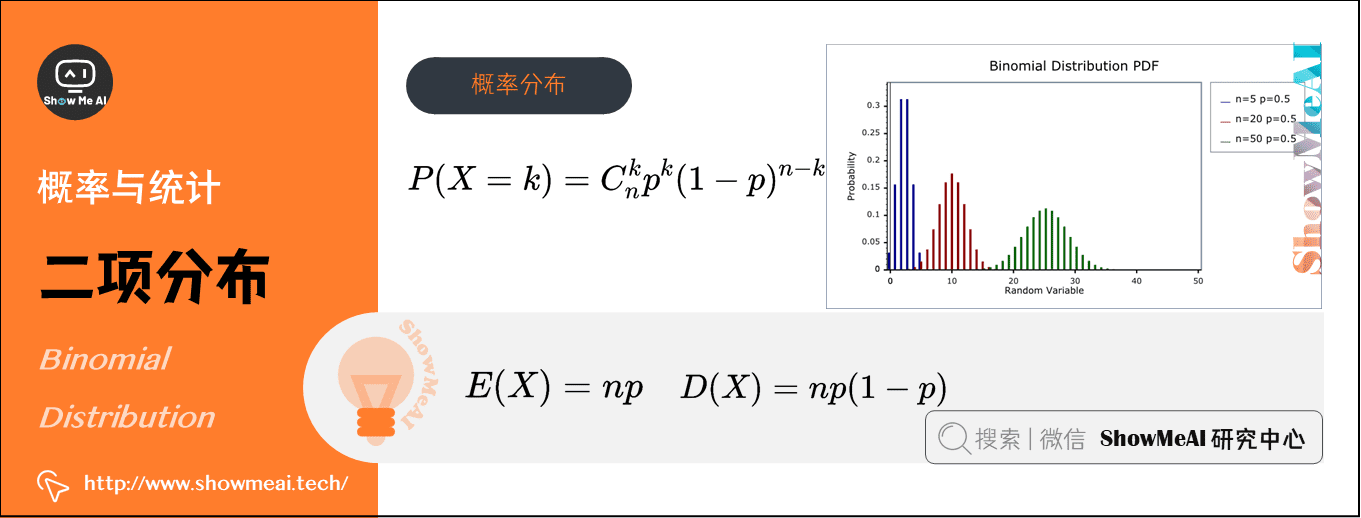
如果每次试验时,事件发生的概率为\(p\),不发生的概率为\(1-p\),则\(n\)次重复独立试验中发生\(k\)次的概率为:\(P(X=k)=C_{n}^{k} p^{k}(1-p)^{n-k}\)
期望:\(E(X)=n p\)
方差:\(D(X)=n p(1-p)\)
4)泊松分布(Poisson Distribution)(离散型)
在概率论和统计学中,泊松分布是一种统计与概率学里常见到的离散概率分布,用于描述某段时间内事件具体的发生概率,数学符号为\(X∼\pi \left ( \lambda \right )\)。
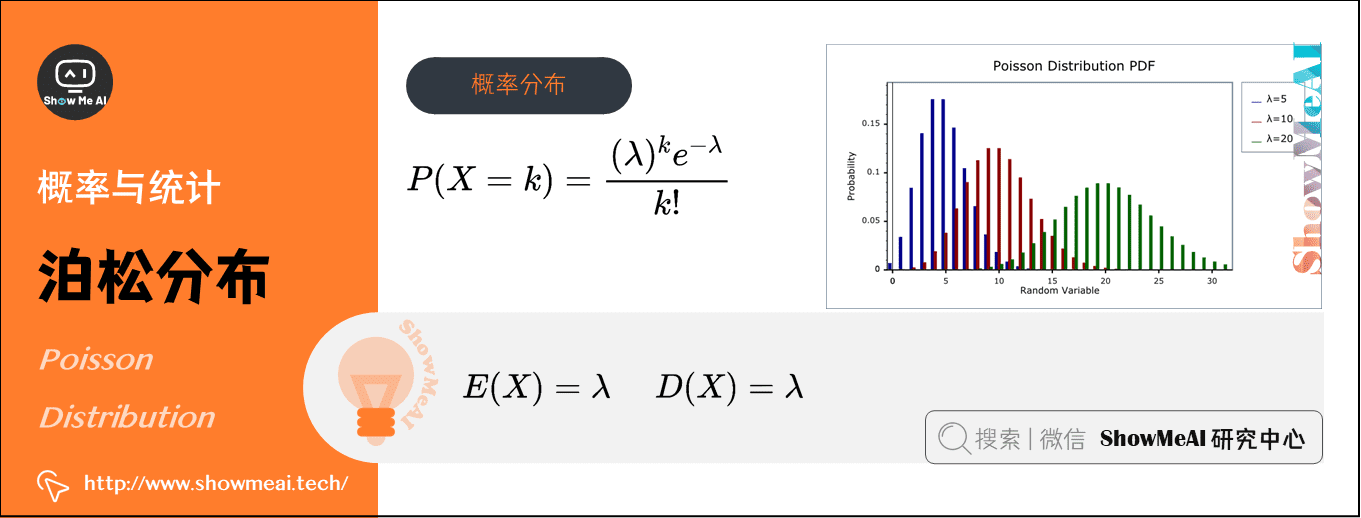
泊松分布的参数\(\lambda\)表示单位时间(或单位面积)内随机事件的平均发生次数,其概率分布函数为:\(P(X=k)=\frac{(\lambda )^{k} e^{-\lambda}}{k !}\)
- 期望:\(E(X)=\lambda\)
- 方差:\(D(X) = \lambda\)
例如,某医院平均每小时出生2.5个婴儿( λ=2.5 ),那么接下来一个小时,会出生几个婴儿?
没有婴儿出生(\(k=0\))的概率为:\(P(X=0)=\frac{(2.5)^{0} \cdot e^{-2.5}}{0 !} \approx 0.082\)
有1个婴儿出生(\(k=1\))的概率为:\(P(X=1)=\frac{(2.5)^{1} \cdot e^{-2.5}}{1 !} \approx 0.205\)
有2个婴儿出生(\(k=2\))的概率为:\(P(X=2)=\frac{(2.5)^{2} \cdot e^{-2.5}}{2 !} \approx 0.257\)
| k | 0 | 1 | 2 | ··· |
|---|---|---|---|---|
| p | 0.082 | 0.205 | 0.257 | ··· |
通常,柏松分布也叫等待概率,是一种比二项分布应用场景更为丰富的概率模型,在数控、电商优化中也经常能见到它的影子。
5)正态分布(Normal Distribution)(连续型)
在概率论和统计学中,正态分布又叫高斯分布(Gaussian Distribution),其曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形。数学符号为\(X∼N\left(\mu, \sigma^{2}\right)\)。
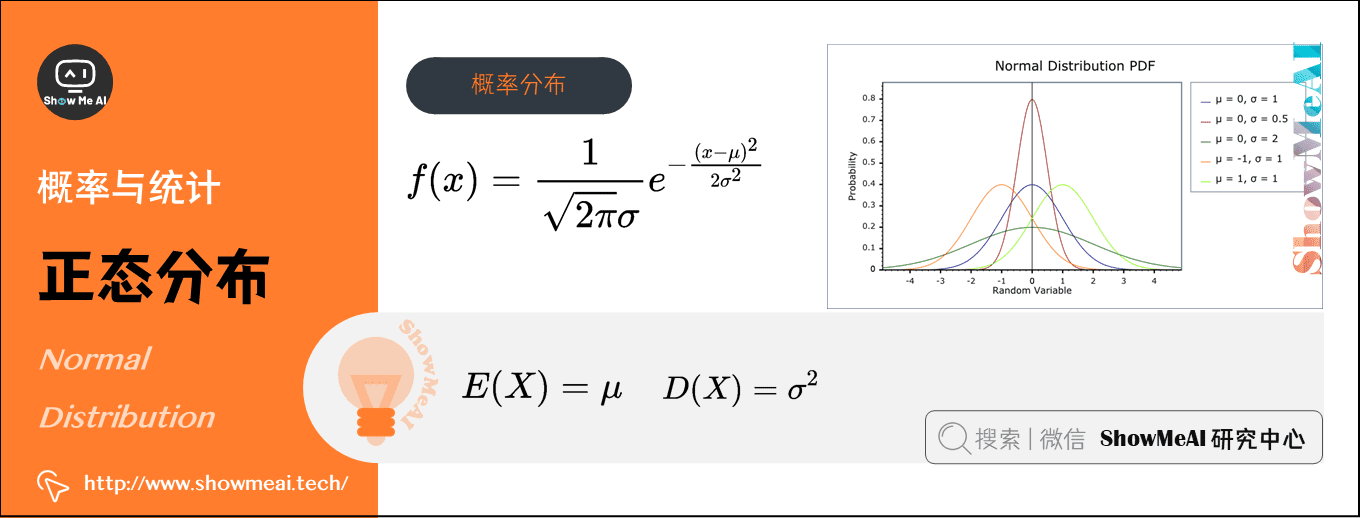
若随机变量\(X\)服从一个数学期望为\(\mu\)、方差为\(\sigma^{2}\)的正态分布,其概率分布函数:\(f(x)=\frac{1}{\sqrt{2 \pi} \sigma} e ^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}}\)
- 期望:\(E(X)=\mu\)
- 方差:\(D(X)=\sigma^{2}\)
6)均匀分布(Uniform Distribution)(连续型)
在概率论和统计学中,均匀分布也叫矩形分布,它是对称概率分布,在相同长度间隔的分布概率是等可能的。
均匀分布由两个参数\(a\)和\(b\)定义,数学符号为\(X∼U (a, b)\)(其中,\(a\)为数轴上较小值,\(b\)为数轴上较大值)。
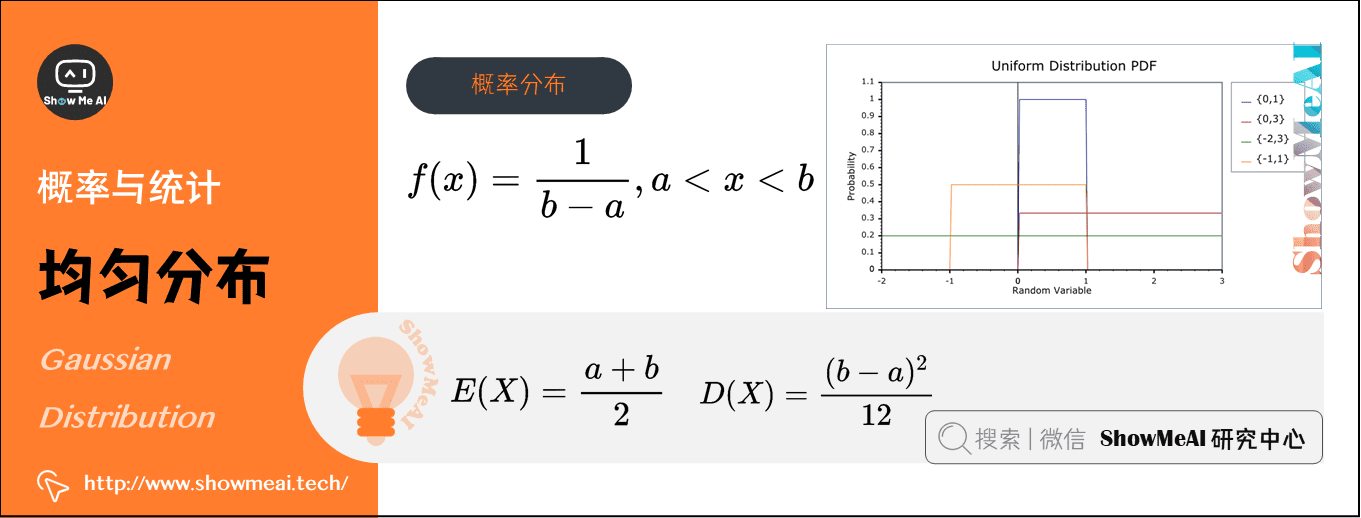
其概率分布函数:$f(x)=\frac{1}{b-a} , a
- 期望:\(E(X)=\frac{a+b}{2}\)
- 方差:\(D(X) = \frac{(b-a)^{2}}{12}\)
7)指数分布(Exponential Distribution)(连续型)
在概率论和统计学中,指数分布与其他分布的最大不同之处在于,随机变量\(X\)指的是不同独立事件发生的时间间隔值,时间越长事件发生的概率指数型增大(减小),数学符号为\(X∼E(\lambda)\)。
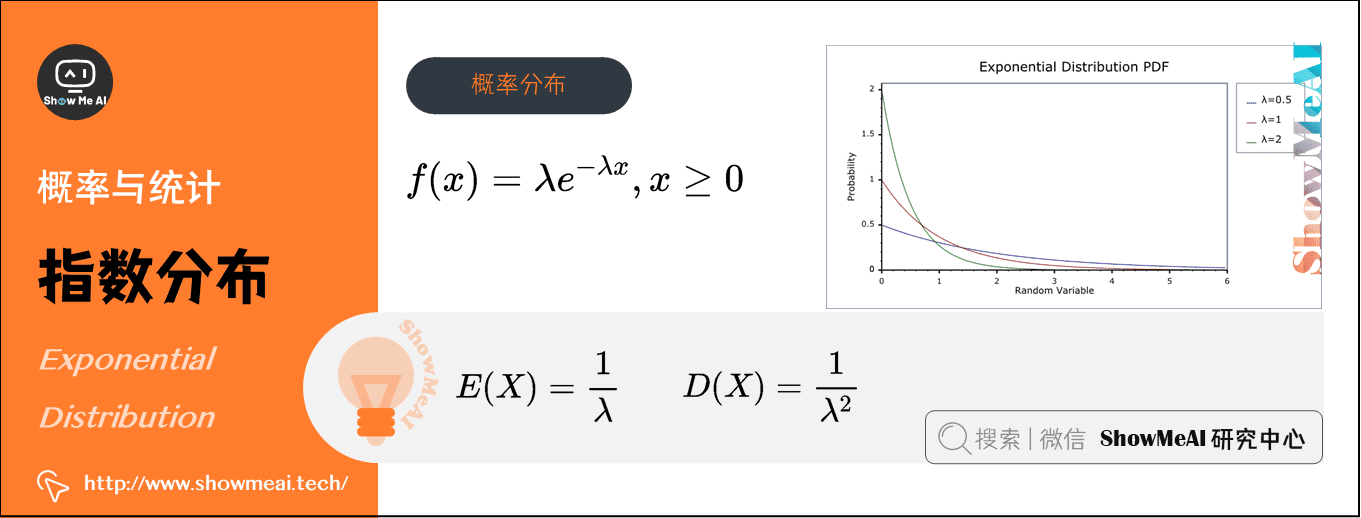
指数分布的参数\(\lambda\)表示单位时间(或单位面积)内随机事件的平均发生次数,其概率分布函数为:\(f(x) = \lambda e^{-\lambda x}, x\ge 0\)
- 期望:\(E(X)=\frac{1}{\lambda}\)
- 方差:\(D(X)=\frac{1}{\lambda^{2}}\)
在我们日常的消费领域,通常的目的是求出在某个时间区间内,会发生随机事件的概率有多大。如:银行窗口服务、交通管理、火车票售票系统、消费市场研究报告中被广泛运用。
例如:某医院平均每小时出生2.5个婴儿( λ=2.5 )。如果到下一个婴儿出生需要的间隔时间为 t (即时间 t 内没有任何婴儿出生)。
- 间隔15分钟(\(X=\frac{1}{4}\))后才有婴儿出生的概率为:\(f(\frac{1}{4}) = 2.5 e^{-2.5 \cdot \frac{1}{4}} \approx 0.9197\)
- 间隔30分钟(\(X=\frac{1}{2}\))后才有婴儿出生的概率为:\(f(\frac{1}{2}) = 2.5 e^{-2.5 \cdot \frac{1}{2}} \approx 0.7163\)
一些总结:


12.拉格朗日乘子法(Lagrange Multiplier)
在求解最优化问题中,拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush Kuhn Tucker)条件是两种最常用的方法。
在机器学习的过程中,我们经常遇到在有限制的情况下,最大化表达式的问题。如:
\(maxf(x,y)s.t. \quad g(x,y)=0\)
此时我们可以构造\(L(x,y,\lambda )=f(x,y) − \lambda \left ( g(x,y) -c \right )\),其中\(\lambda\)称为拉格朗日乘子。接下来要对拉格朗日函数\(L(x,y,\lambda )\)求导,令其为0,解方程即可。
以下是图文解释:

红线标出的是约束\(g(x,y)=c\)的点的轨迹。蓝线是\(f(x,y)\)的等高线。箭头表示斜率,和等高线的法线平行,从梯度的方向上来看显然有\(d_{1}>d_{2}\)。
红色的线是约束。如果没有这条约束,\(f(x,y)\)的最小值应该会落在最小那圈等高线内部的某一点上。现在加上了约束,正好落在这条红线上的点才可能是满足要求的点。也就是说,应该是在\(f(x,y)\)的等高线正好和约束线\(g(x,y)\)相切的位置。
对约束也求梯度\(\nabla g(x,y)\)(如图中红色箭头所示),可以看出要想让目标函数\(f(x,y)\)的等高线和约束相切\(g(x,y)\),则他们切点的梯度一定在一条直线上。也即在最优化解的时候\(\nabla f(x,y)=λ \nabla g(x,y)-C\),即\(\nabla [f(x,y)+λ(g(x,y)−c)]=0,λ≠0\)。
那么拉格朗日函数\(L(x,y,\lambda )=f(x,y) − \lambda \left ( g(x,y) -c \right )\)在达到极值时与\(f(x,y)\)相等,因为\(F(x,y)\)达到极值时\(g(x,y)−c\)总等于零。
简单的说,\(L(x,y,λ)\)取得最优化解的时候,也就是\(L(x,y,λ)\)取极值的时候。此时\(L(x,y,λ)\)的导数为0,即\(\nabla L(x,y,\lambda )=\nabla \left [ f(x,y) − \lambda \left ( g(x,y) -c \right ) \right ] =0\),可以得出\(f(x,y)\)与\(g(x,y)\)梯度共线,此时就是在条件约束\(g(x,y)\)下,\(f(x,y)\)的最优化解。
在支持向量机模型(SVM)的推导中,很关键的一步就是利用拉格朗日对偶性,将原问题转化为对偶问题。
13.最大似然估计(Maximum Likelihood Estimate)
最大概似估计(MLE)是一种粗略的数学期望,指在模型已定、参数\(\theta\)未知的情况下,通过观测数据估计未知参数\(\theta\)的一种思想或方法。
最大似然估计的哲学内涵就是:我们对某个事件发生的概率未知,但我们做了一些实验,有过一些对这个事件的经历(经验),那么我们认为,这个事件的概率应该是能够与我们做的实验结果最吻合。当然,前提是我们做的实验次数应当足够多。
举个例子,假设我们要统计全国人口的身高。首先假设这个身高服从服从正态分布,但是该分布的均值。我们没有人力与物力去统计全国每个人的身高,但是可以通过采样,获取部分人的身高,然后通过最大似然估计来获取上述假设中的正态分布的均值。
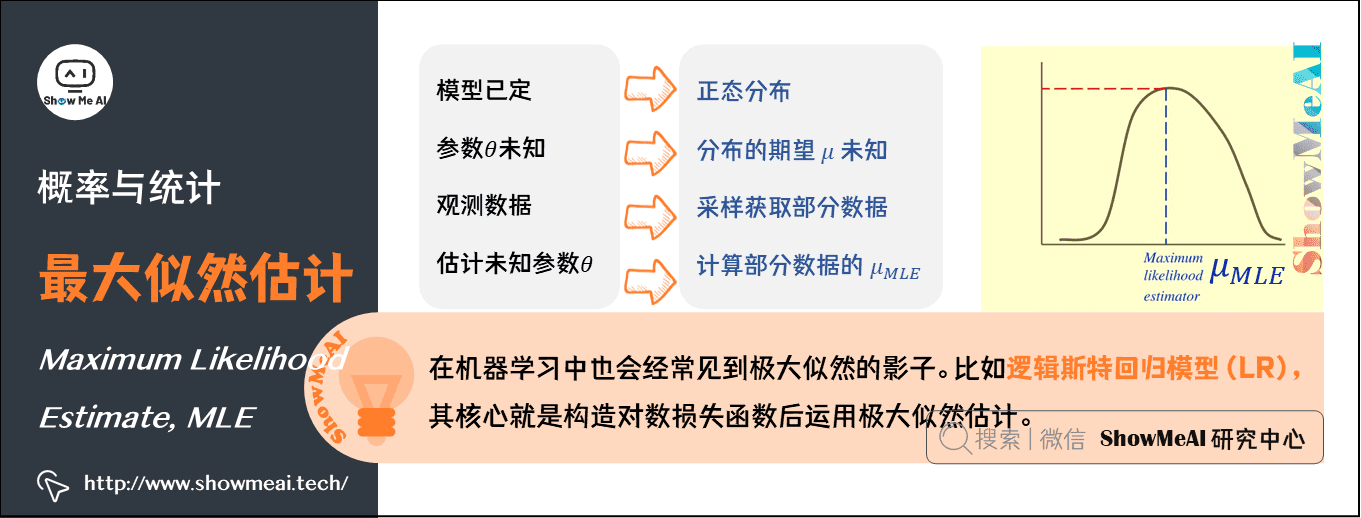
最大似然函数的求解思想是:给定样本取值后,该样本最有可能来自参数\(\theta\)为何值的总体。即:寻找\(\bar{\theta}_{M LE}\)使得观测到样本数据的可能性最大。
最大似然函数估计值的一般求解步骤是:
- 写出似然函数\(L\left(\theta_{1}, \theta_{2}, \cdots, \theta_{n}\right)=\left\{\begin{array}{l}
\prod_{i=1}^{n} p\left(x_{i} ; \theta_{1}, \theta_{2}, \cdots, \theta_{n}\right) \\
\prod_{i=1}^{n} f\left(x_{i} ; \theta_{1}, \theta_{2}, \cdots, \theta_{n}\right)
\end{array}\right.\) - 对似然函数取对数
- 两边同时求导数
- 令导数为0解出似然方程
在机器学习中也会经常见到极大似然的影子。比如后面的逻辑斯特回归模型(LR),其核心就是构造对数损失函数后运用极大似然估计。
ShowMeAI相关文章推荐
ShowMeAI系列教程推荐

图解AI数学基础 | 概率与统计的更多相关文章
- 图解AI数学基础 | 线性代数与矩阵论
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/83 本文地址:http://www.showmeai.tech/article-det ...
- AI数学基础之:概率和上帝视角
目录 简介 蒙题霍尔问题 上帝视角解决概率问题 上帝视角的好处 简介 天要下雨,娘要嫁人.虽然我们不能控制未来的走向,但是可以一定程度上预测为来事情发生的可能性.而这种可能性就叫做概率.什么是概率呢? ...
- 斯坦福【概率与统计】课程笔记(六):EDA | 标准差和方差
这一篇比较简单,就不展开记录了,方差和标准差的计算方法记住了就可以. 计算mean 计算每个样本与mean的差值的平方,将其累加后除以(样本数-1)[注:这里的除数可以是n-1也可以是n],即得到方差 ...
- AI 数学基础 : 熵
什么是熵(entropy)? 1.1 熵的引入 事实上,熵的英文原文为entropy,最初由德国物理学家鲁道夫·克劳修斯提出,其表达式为: 它表示一个系系统在不受外部干扰时,其内部最稳定的状态.后来一 ...
- 1、概率vs统计
- 斯坦福【概率与统计】课程笔记(五):EDA | 箱线图
介绍箱线图之前,需要先介绍若干个其需要的术语 min:整个样本的最小值 max:整个样本的最大值 Range:即整个样本的取值范围,Range = max - min Inter-Quartile R ...
- 斯坦福【概率与统计】课程笔记(四):EDA | 茎叶图
茎叶图的只做方法如下: 将每个数字分成茎和叶 对所有茎排序,并纵向从小到大放置好 对相同茎下的叶归到一起并排序,垂直于茎的排列方向放置好 举个例子:我们有一份奥斯卡影后的年龄集合: 34 34 27 ...
- 斯坦福【概率与统计】课程笔记(三):EDA | 直方图
单个定量变量的直方图表示 大家知道,定量变量是连续型变量,即不会像分类变量那样有明显的分类,那么如何将其画成直方图呢?一般来说,会将其按照某个维度来将其分组(group),举个例子. 我们有15个学生 ...
- 斯坦福【概率与统计】课程笔记(二):从EDA开始
探索性数据分析(Exploratory Data Analysis) 本节课程先从统计分析四步骤中的第二步:EDA开始. 课程定义了若干个术语,如果学习过机器学习的同学,应该很容易类比理解: popu ...
随机推荐
- python客户端和Appium服务端联调出现的问题解决办法
按照安装文档搭建完移动端自动化测试环境,包括:SDK.JDK.Node.js.Appium及客户端后,appium-doctor可以成功的检测到各配套版本.如下图: 可是,运行from appium ...
- 《剑指offer》面试题58 - I. 翻转单词顺序
问题描述 输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变.为简单起见,标点符号和普通字母一样处理.例如输入字符串"I am a student. ",则输出&quo ...
- JSP页面打印输出,两种方法。out、《%=
使用out.println()输出: <%@ page contentType="text/html;charset=UTF-8"%> <html> < ...
- 微信小程序云开发框架
概述 一直做后端服务器开发,最近看了一篇文章介绍小程序的云开发模式,觉得挺有意思,就尝试了一下,由本文做个记录. 因为不是专业的小程序开发人员,也没有做过网页开发,所以论述中出现错误难以避免,请多谅解 ...
- 小记录:flask的DEBUG开关
请求站点的如下位置: http://www.ahfu.com/ahfuzhang/?debugger=yes&cmd=resource&f=style.css 居然正常范围了CSS文件 ...
- 返回值Object-注解驱动作用
返回值Object 两个常用实现类 StringHttpMessageConverterhe:负责读取字符串格式的数据和写出字符串格式的数据 MappingJackson2HttpMessageCon ...
- linux中三剑客之一grep命令
目录 一:grep语法格式: 二:参数: 三:正则表达式 1.linux正则表达式 2.普通正则表达式 四:正则与grep实战案例实战: grep简介: linux 三剑客之一,文本过滤器(根据文本内 ...
- windows批处理详解
转:https://mp.weixin.qq.com/s/Ktbl4P16Qye7OxDNEzJI5Q
- BERT-MRC:统一化MRC框架提升NER任务效果
原创作者 | 疯狂的Max 01 背景 命名实体识别任务分为嵌套命名实体识别(nested NER)和普通命名实体识别(flat NER),而序列标注模型只能给一个token标注一个标签,因此对于嵌套 ...
- Lesson2——NumPy Ndarray 对象
NumPy 教程目录 NumPy Ndarray 对象 NumPy 最重要的一个特点是其 $N$ 维数组对象 ndarray,它是一系列同类型数据的集合,以 $0$ 下标为开始进行集合中元素的索引. ...