RabbitMQ使用 prefetch_count优化队列的消费,使用死信队列和延迟队列实现消息的定时重试,golang版本
RabbitMQ 的优化
channel
生产者,消费者和 RabbitMQ 都会建立连接。为了避免建立过多的 TCP 连接,减少资源额消耗。
AMQP 协议引入了信道(channel),多个 channel 使用同一个 TCP 连接,起到对 TCP 连接的复用。
不过 channel 的连接数是有上限的,过多的连接会导致复用的 TCP 拥堵。
const (
maxChannelMax = (2 << 15) - 1
defaultChannelMax = (2 << 10) - 1
)
通过http://github.com/streadway/amqp这个client来连接 RabbitMQ,这里面定义了最大值65535和默认最大值2047。
prefetch Count
什么是prefetch Count,先举个栗子:
假定 RabbitMQ 队列有 N 个消费队列,RabbitMQ 队列中的消息将以轮询的方式发送给消费者。
消息的数量是 M,那么每个消费者得到的数据就是 M%N。如果某一台的机器中的消费者,因为自身的原因,或者消息本身处理所需要的时间很久,消费的很慢,但是其他消费者分配的消息很快就消费完了,然后处于闲置状态,这就造成资源的浪费,消息队列的吞吐量也降低了。
这时候prefetch Count就登场了,通过引入prefetch Count来避免消费能力有限的消息队列分配过多的消息,而消息处理能力较好的消费者没有消息处理的情况。
RabbitM 会保存一个消费者的列表,每发送一条消息都会为对应的消费者计数,如果达到了所设定的上限,那么 RabbitMQ 就不会向这个消费者再发送任何消息。直到消费者确认了某条消息之后 RabbitMQ 将相应的计数减1,之后消费者可以继续接收消息,直到再次到达计数上限。这种机制可以类比于 TCP/IP 中的"滑动窗口"。
所以消息不会被处理速度很慢的消费者过多霸占,能够很好的分配到其它处理速度较好的消费者中。通俗的说就是消费者最多从 RabbitMQ 中获取的未消费消息的数量。
prefetch Count数量设置为多少合适呢?大概就是30吧,具体可以参见Finding bottlenecks with RabbitMQ 3.3
谈到了prefetch Count,我们还要看了 global 这个参数,RabbitMQ 为了提升相关的性能,在 AMQPO-9-1 协议之上重新定义了 global 这个参数
| global 参数 | AMQPO-9-1 | RabbitMQ |
|---|---|---|
| false | 信道上所有的消费者都需要遵从 prefetchC unt 的限 | 信道上新的消费者需要遵从 prefetchCount 的限定值定值 |
| true | 当前通信链路(Connection) 上所有的消费者都要遵从 prefetchCount 的限定值,就是同一Connection上的消费者共享 | 信道上所有的消费者都需要遵从 prefetchCunt 的上限,就是同一信道上的消费者共享 |
prefetchSize:预读取的单条消息内容大小上限(包含),可以简单理解为消息有效载荷字节数组的最大长度限制,0表示无上限,单位为 B。
如果prefetch Count为 0 呢,表示预读取的消息数量没有上限。
举个错误使用的栗子:
之前一个队列的消费者消费速度过慢,prefetch Count为0,然后新写了一个消费者,prefetch Count设置为30,并且起了10个pod,来处理消息。老的消费者还没有下线也在处理消息。
但是发现消费速度还是很慢,有大量的消息处于 unacked 。如果明白prefetch Count的含义其实就已经可以猜到问题的原因了。
老的消费者prefetch Count为0,所以很多 unacked 消息都被它持有了,虽然新加了几个新的消费者,但是都处于空闲状态,最后停掉了prefetch Count为0的消费者,很快消费速度就正常了。
死信队列
什么是死信队列
一般消息满足下面几种情况就会消息变成死信
消息被否定确认,使用
channel.basicNack或channel.basicReject,并且此时 requeue 属性被设置为false;消息过期,消息在队列的存活时间超过设置的 TT L时间;
队列达到最大长度,消息队列的消息数量已经超过最大队列长度。
当一个消息满足上面的几种条件变成死信(dead message)之后,会被重新推送到死信交换器(DLX ,全称为 Dead-Letter-Exchange)。绑定 DLX 的队列就是死信队列。
所以死信队列也并不是什么特殊的队列,只是绑定到了死信交换机中了,死信交换机也没有什么特殊,我们只是用这个来处理死信队列了,和别的交换机没有本质上的区别。
对于需要处理死信队列的业务,跟我们正常的业务处理一样,也是定义一个独有的路由key,并对应的配置一个死信队列进行监听,然后 key 绑定的死信交换机中。
使用场景
当消息的消费出现问题时,出问题的消息不被丢失,进行消息的暂存,方便后续的排查处理。
代码实现
死信队列的使用,可参看下文,配合延迟队列实现消息重试的机制。
延迟队列
什么是延迟队列
延迟队列就是用来存储进行延迟消费的消息。
什么是延迟消息?
就是不希望消费者马上消费的消息,等待指定的时间才进行消费的消息。
使用场景
1、关闭空闲连接。服务器中,有很多客户端的连接,空闲一段时间之后需要关闭;
2、清理过期数据业务上。比如缓存中的对象,超过了空闲时间,需要从缓存中移出;
3、任务超时处理。在网络协议滑动窗口请求应答式交互时,处理超时未响应的请求;
4、下单之后如果三十分钟之内没有付款就自动取消订单;
5、订餐通知:下单成功后60s之后给用户发送短信通知;
6、当订单一直处于未支付状态时,如何及时的关闭订单,并退还库存;
7、定期检查处于退款状态的订单是否已经退款成功;
8、新创建店铺,N天内没有上传商品,系统如何知道该信息,并发送激活短信;
9、定时任务调度:使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行。
总结下来就是一些延迟处理的业务场景
实现延迟队列的方式
RabbitMQ 中本身并没有直接提供延迟队列的功能,可以通过死信队列和 TTL 。来实现延迟队的功能。
先来了解下过期时间 TTL,消息一旦超过设置的 TTL 值,就会变成死信。这里需要注意的是 TTL 的单位是毫秒。设置过期时间一般与两种方式
1、通过队列属性设置,队列中的消息有相同的过期时间;
2、通过消息本身单独设置,每条消息有自己的的过期时间。
如果两种一起设置,消息的 TTL 以两者之间较小的那个数值为准。
上面两种 TTL 过期时间,消息队列的处理是不同的。第一种,消息一旦过期就会从消息队列中删除,第二种,消息过期了不会马上进行删除操作,删除的操作,是在投递到消费者之前进行判断的。
第一种方式中相同过期时间的消息是在同一个队列中,所以过期的消息总是在头部,只要在头部进行扫描就好了。第二种方式,过期的时间不同,但是消息是在同一个消息队列中的,如果要清理掉所有过期的时间就需要遍历所有的消息,当然这也是不合理的,所以会在消息被消费的时候,进行过期的判断。这个处理思想和 redis 过期 key 的清理有点神似。
Queue TTL
通过 channel.queueDeclare 方法中的 x-expires 参数可以控制队列被自动删除前处于未使用状态的时间。未使用的意思是队列上没有任何的消费者,队列也没有被重新声明,并且在过期时间段内也未调用过 Basic.Get 命令。
if _, err := channel.QueueDeclare("delay.3s.test",
true, false, false, false, amqp.Table{
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": ps.key,
"x-expires": 3000,
},
); err != nil {
return err
}
Message TTL
对于 Message TTL 设置有两种方式
Per-Queue Message TTL
通过在 queue.declare 中设置 x-message-ttl 参数,可以控制在当前队列中,消息的过期时间。不过同一个消息被投到多个队列中,设置x-message-ttl的队列,里面消息的过期,不会对其他队列中相同的消息有影响。不同队列处理消息的过期是隔离的。
if _, err := channel.QueueDeclare("delay.3s.test",
true, false, false, false, amqp.Table{
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": ps.key,
"x-message-ttl": 3000,
},
); err != nil {
return err
}
Per-Message TTL
通过 expiration 就可以设置每条消息的过期时间,需要注意的是 expiration 是字符串类型。
delayQ := "delay.3s.test"
if _, err := channel.QueueDeclare(delayQ,
true, false, false, false, amqp.Table{
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": ps.key,
},
); err != nil {
return err
}
if err := channel.Publish("", delayQ, false, false, amqp.Publishing{
Headers: amqp.Table{"x-retry-count": retryCount + 1},
Body: d.Body,
DeliveryMode: amqp.Persistent,
Expiration: "3000",
}); err != nil {
return err
}
通过延迟队列来处理延迟消费的场景,可以借助于死信队列来处理
延迟队列通常的使用:消费者订阅死信队列 deadQueue,然后需要延迟处理的消息都发送到 delayNormal 中。然后 delayNormal 中的消息 TTL 过期时间到了,消息会被存储到死信队列 deadQueue。我们只需要正常消费,死信队列 deadQueue 中的数据就行了,这样就实现对数据延迟消费的逻辑了。
使用 Queue TTL 设置过期时间
举个线上处理消息重传的的栗子:
消费者处理队列中的消息,一个消息在处理的过程中,会出现错误,针对某些特性的错误,希望这些消息能够退回到队列中,过一段时间在进行消费。当然,如果不进行 Ack,或者 Ack 之后重推到队列中,消费者就能再次进行重试消费。但是这样会有一个问题,消费队列中消息消费很快,刚重推的消息马上就到了队列头部,消费者可能马上又拿到这个消息,然后一直处于重试的死循环,影响其他消息的消费。这时候延迟队列就登场了,我们可以借助于延迟队列,设置特定的延迟时间,让这些消息的重试,发生到之后某个时间点。并且重试一定次数之后,就可以选择丢弃这个消息了。
来看下流程图:
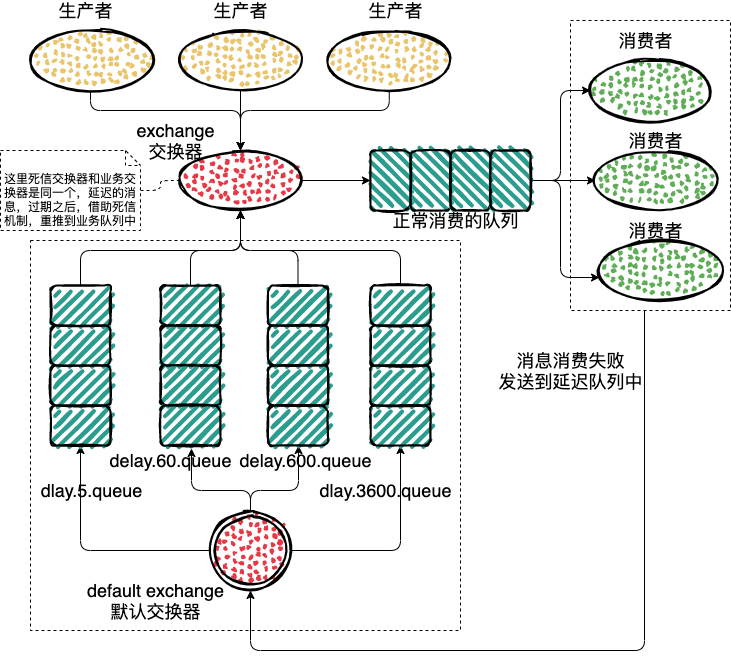
具体的处理步骤:
1、生产者推送消息到 work-exchange 中,然后发送到 work-queue 队列;
2、消费者订阅 work-queue 队列,这是正常的业务消费;
3、对于需要进行延迟重试的消息,发送到延迟队列中;
4、延迟队列会绑定一个死信系列,死信队列的 exchange 和 routing-key,就是上面正常处理业务 work-queue 消息队里的 exchange 和 routing-key,这样过期的消息就能够重推到业务的队列中,每次重推到延迟队列的时候会记录消息重推的次数,如果达到我们设定的上限,就可以丢弃数据,落库或其他的操作了;
5、所以消费者只需要监听处理 work-queue 队列就可以了;
6、无用的延迟队列,到了删除的时间节点,会进行自动的删除。
上代码,文中 Demo 的地址
func (b *Broker) readyConsumes(ps *params) (bool, error) {
key := ps.key
channel, err := b.getChannel(key)
if err != nil {
return true, err
}
queue, err := b.declare(channel, key, ps)
if err != nil {
return true, err
}
if err := channel.Qos(ps.prefetch, 0, false); err != nil {
return true, fmt.Errorf("channel qos error: %s", err)
}
deliveries, err := channel.Consume(queue.Name, "", false, false, false, false, nil)
if err != nil {
return true, fmt.Errorf("queue consume error: %s", err)
}
channelClose := channel.NotifyClose(make(chan *amqp.Error))
pool := make(chan struct{}, ps.concurrency)
go func() {
for i := 0; i < ps.concurrency; i++ {
pool <- struct{}{}
}
}()
for {
select {
case err := <-channelClose:
b.channels.Delete(key)
return true, fmt.Errorf("channel close: %s", err)
case d := <-deliveries:
if ps.concurrency > 0 {
<-pool
}
go func() {
var flag HandleFLag
switch flag = ps.Handle(d.Body); flag {
case HandleSuccess:
d.Ack(false)
case HandleDrop:
d.Nack(false, false)
// 处理需要延迟重试的消息
case HandleRequeue:
if err := b.retry(ps, d); err != nil {
d.Nack(false, true)
} else {
d.Ack(false)
}
default:
d.Nack(false, false)
}
if ps.concurrency > 0 {
pool <- struct{}{}
}
}()
}
}
}
func (b *Broker) retry(ps *params, d amqp.Delivery) error {
channel, err := b.conn.Channel()
if err != nil {
return err
}
defer channel.Close()
retryCount, _ := d.Headers["x-retry-count"].(int32)
// 判断尝试次数的上限
if int(retryCount) >= len(ps.retryQueue) {
return nil
}
delay := ps.retryQueue[retryCount]
delayDuration := time.Duration(delay) * time.Millisecond
delayQ := fmt.Sprintf("delay.%s.%s.%s", delayDuration.String(), b.exchange, ps.key)
if _, err := channel.QueueDeclare(delayQ,
true, false, false, false, amqp.Table{
// 配置死信发送的exchange和routing-key
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": ps.key,
// 消息的过期时间
"x-message-ttl": delay,
// 延迟队列自动删除的时间设置
"x-expires": delay * 2,
},
); err != nil {
return err
}
// exchange为空使用Default Exchange
return channel.Publish("", delayQ, false, false, amqp.Publishing{
// 设置尝试的次数
Headers: amqp.Table{"x-retry-count": retryCount + 1},
Body: d.Body,
DeliveryMode: amqp.Persistent,
})
}
测试一下
先使用docker 启动一个 RabbitMQ
$ sudo mkdir -p /usr/local/docker-rabbitmq/data
$ docker run -d --name rabbitmq3.7.7 -p 5672:5672 -p 15672:15672 -v /usr/local/docker-rabbitmq/data:/var/lib/rabbitmq --hostname rabbitmq -e RABBITMQ_DEFAULT_VHOST=/ -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq:3.7.7-management
账号,密码是 admin
const (
DeadTestExchangeQueue = "dead-test-delayed-queue_queue"
)
func main() {
ch := make(chan os.Signal, 1)
signal.Notify(ch, syscall.SIGHUP, syscall.SIGQUIT, syscall.SIGTERM, syscall.SIGINT)
broker := rabbitmq.NewBroker("amqp://admin:admin@127.0.0.1:5672", &rabbitmq.ExchangeConfig{
Name: "worker-exchange",
Type: "direct",
})
broker.LaunchJobs(
rabbitmq.NewDefaultJobber(
"dead-test-key",
HandleMessage,
rabbitmq.WithPrefetch(30),
rabbitmq.WithQueue(DeadTestExchangeQueue),
rabbitmq.WithRetry(help.FIBONACCI, help.Retry{
Delay: "5s",
Max: 6,
Queue: []string{
DeadTestExchangeQueue,
},
}),
),
)
for {
s := <-ch
switch s {
case syscall.SIGQUIT, syscall.SIGTERM, syscall.SIGINT:
fmt.Println("job-test-exchange service exit")
time.Sleep(time.Second)
return
case syscall.SIGHUP:
default:
return
}
}
}
func HandleMessage(data []byte) error {
fmt.Println("receive message", "message", string(data))
return rabbitmq.HandleRequeue
}
接收到的消息,直接进行重试,我们来看下,延迟队列的执行
启动之后,先来看下消息队列的面板

通过控制面板 push 一条数据
可以看到消息在延迟队列中的执行过程,并且没有再用的延迟队列,会在设置的过期时间点,进行自动删除


最后可以看到这条消息被反复重试了多次
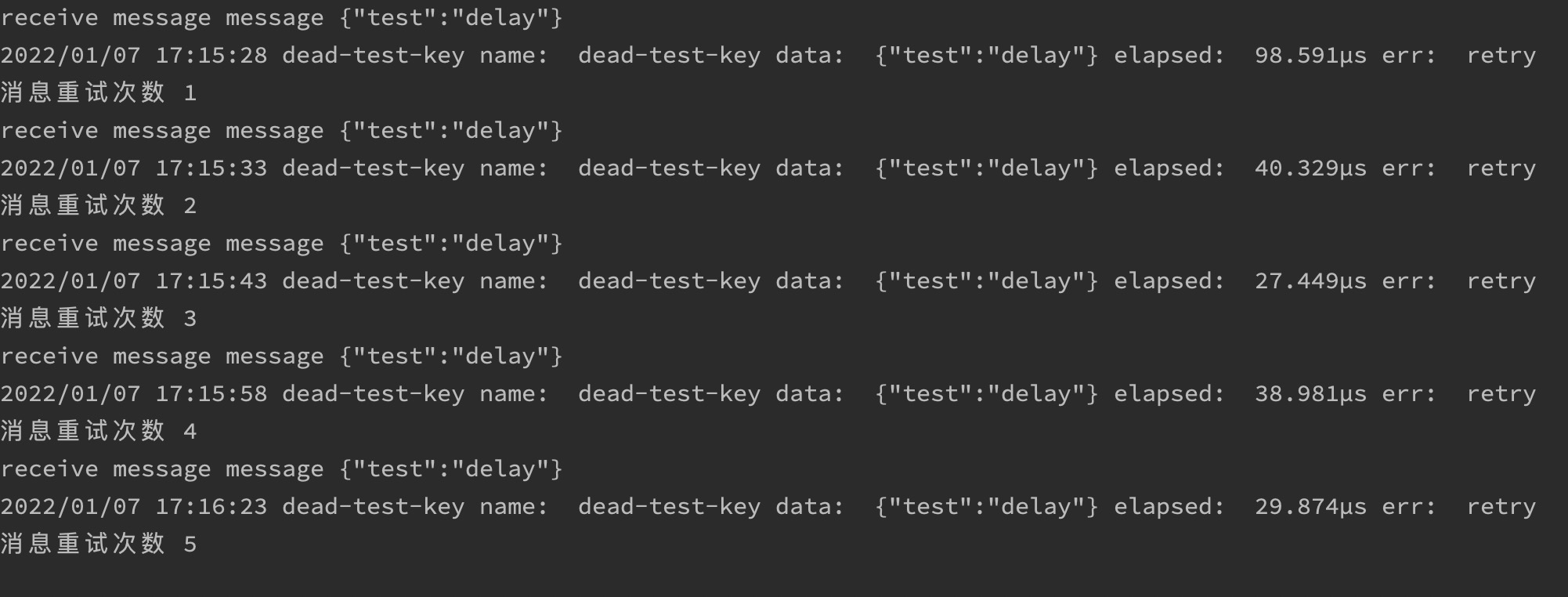
最后达到我们设置的重试上限之后,消息就会被丢失了
使用 Message TTL 设置过期时间
使用 Message TTL这种方式,我们的队列会存在时序的问题,这里来展开分析下:
使用 Message TTL这种方式,所有设置过期的消息是会放到一个队列中的。因为消息的出队是一条一条出的,只有第一个消息被消费了,才能处理第二条消息。如果第一条消息过期10s,第二条过期1s。第二条肯定比第一条先过期,理论上,应该先处理第二条。但是有上面讨论的限制,如果第一条没有被消费,第二条消息是不能被处理的。这就造成了时序问题,当然如果使用Queue TTL就不会有这种情况了,应为相同过期时间的消息在同一个队列中,所以队列头部的消息总是最先过期的消息。那么这种情况如何去避免呢?
可以使用rabbitmq-delayed-message-exchange插件处理。rabbitmq-delayed-message-exchange插件地址
实现原理:
安装插件后会生成新的Exchange类型x-delayed-message,处理的原则是延迟投递。当接收到延迟消息之后,并不是直接投递到目标队列中,而是会把消息存储到 mnesia 数据库中,什么是 mnesia 可参考Mnesia 数据库。当延迟时间到了的时候,通过x-delayed-message推送到目标队列中。然后去消费目标队列,就能避免过期的时序问题了。
来看下如何使用
这里使用一台虚拟机来演示,首先安装 RabbitMQ,安装过程可参考RabbitMQ 3.8.5
然后下载 rabbitmq-delayed-message-exchange 插件
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases/download/3.9.0/rabbitmq_delayed_message_exchange-3.9.0.ez
$ cp rabbitmq_delayed_message_exchange-3.9.0.ez /usr/lib/rabbitmq/lib/rabbitmq_server-3.8.5/plugins
# 查看安装的插件
$ rabbitmq-plugins list
Listing plugins with pattern ".*" ...
Configured: E = explicitly enabled; e = implicitly enabled
| Status: * = running on rabbit@centos7-1
|/
[ ] rabbitmq_amqp1_0 3.8.5
[ ] rabbitmq_auth_backend_cache 3.8.5
[ ] rabbitmq_auth_backend_http 3.8.5
[ ] rabbitmq_auth_backend_ldap 3.8.5
[ ] rabbitmq_auth_backend_oauth2 3.8.5
[ ] rabbitmq_auth_mechanism_ssl 3.8.5
[ ] rabbitmq_consistent_hash_exchange 3.8.5
[E*] rabbitmq_delayed_message_exchange 3.9.0
[ ] rabbitmq_event_exchange 3.8.5
[ ] rabbitmq_federation 3.8.5
$ rabbitmq-plugins enable rabbitmq_delayed_message_exchange
$ systemctl restart rabbitmq-server
修改上面的栗子,使用x-delayed-message
上代码,demo地址
func (b *Broker) declareDelay(key string, job Jobber) error {
keyNew := fmt.Sprintf("delay.%s", key)
channel, err := b.getChannel(fmt.Sprintf("delay.%s", key))
if err != nil {
return err
}
defer channel.Close()
exchangeNew := fmt.Sprintf("delay.%s", b.exchange)
if err := channel.ExchangeDeclare(exchangeNew, "x-delayed-message", true, false, false, false, nil); err != nil {
return fmt.Errorf("exchange declare error: %s", err)
}
queue, err := channel.QueueDeclare(fmt.Sprintf("delay.%s", job.Queue()), true, false, false, false, amqp.Table{
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": key,
})
if err != nil {
return fmt.Errorf("queue declare error: %s", err)
}
if err = channel.QueueBind(queue.Name, keyNew, exchangeNew, false, nil); err != nil {
return fmt.Errorf("queue bind error: %s", err)
}
return nil
}
func (b *Broker) retry(ps *params, d amqp.Delivery) error {
channel, err := b.conn.Channel()
if err != nil {
return err
}
defer channel.Close()
retryCount, _ := d.Headers["x-retry-count"].(int32)
if int(retryCount) >= len(ps.retryQueue) {
return nil
}
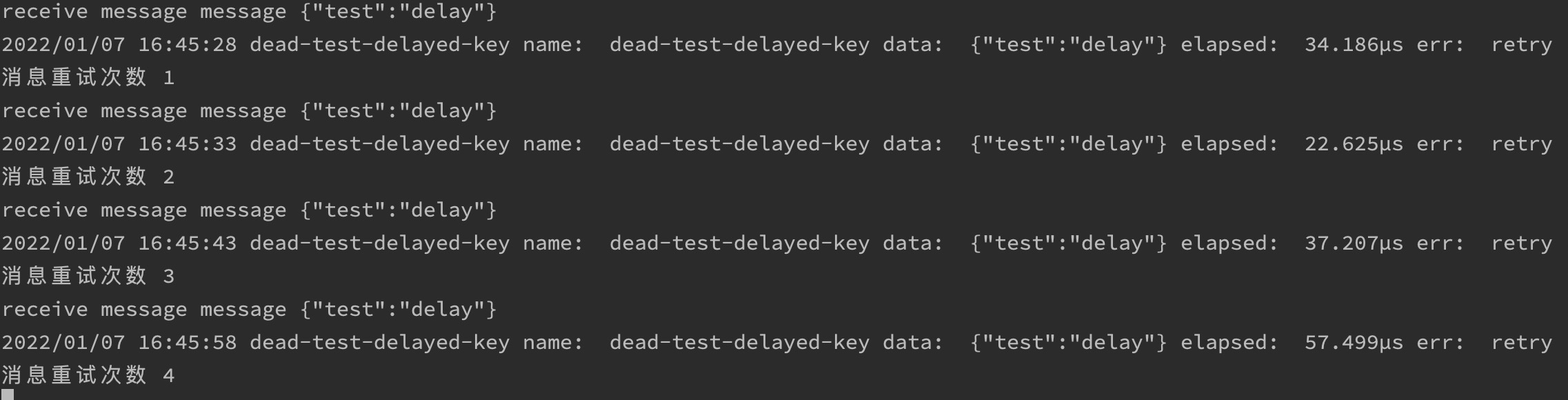
fmt.Println("消息重试次数", retryCount+1)
delay := ps.retryQueue[retryCount]
if err := channel.ExchangeDeclare(fmt.Sprintf("delay.%s", b.exchange), "x-delayed-message", true, false, false, false, amqp.Table{
"x-delayed-type": "direct",
}); err != nil {
return err
}
return channel.Publish(fmt.Sprintf("delay.%s", b.exchange), fmt.Sprintf("delay.%s", ps.key), false, false, amqp.Publishing{
Headers: amqp.Table{"x-retry-count": retryCount + 1},
Body: d.Body,
DeliveryMode: amqp.Persistent,
Expiration: fmt.Sprintf("%d", delay),
})
}
设置重试队列中的消息类型是x-delayed-message,这样就能使用刚刚下来的插件了。
通过面板推送一条消息之后,看下运行的结果
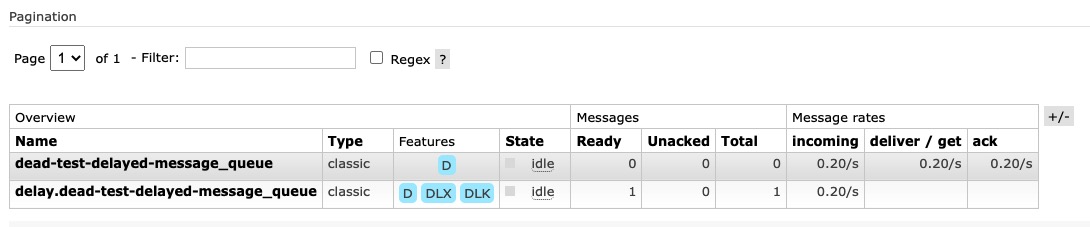
其中dead-test-delayed-message_queue就是我们正常业务消费的队列,delay.dead-test-delayed-message_queue存储的是需要进行延迟消费的消息,这里面的消息,会在过期的时候通过死信的机制,被重推到dead-test-delayed-message_queue中
看下控制台的输出信息
使用插件还是Queue TTL处理延迟队列呢?
rabbitmq-delayed-message-exchange 相关限制:
1、该插件不支持延迟消息的复制,在 RabbitMQ 镜像集群模式下,如果其中的一个节点宕机,会存在消息不可用,只能等该节点重新启动,才可以恢复;
2、目前该插件只支持在磁盘节点上使用,当前还不支持ram节点;
3、不适合具有大量延迟消息的情况(例如:数千或数百万的延迟消息)。
This plugin is considered to be experimental yet fairly stable and potential suitable for production use as long as the user is aware of its limitations.
This plugin is not commercially supported by Pivotal at the moment but it doesn't mean that it will be abandoned or team RabbitMQ is not interested in improving it in the future. It is not, however, a high priority for our small team.
So, give it a try with your workload and decide for yourself.
这是官方对此的解释,大概意思就是,这个还处于试验阶段,但还是相对稳定的。团队对此插件的更新优先级不是很高,所以如果我们遇到问题了,可能还需要自己去修改。
如果有能力更改这个插件,毕竟这个是 erlang 写的,那么就可以选择这个了。
优点也是很明显,开箱即用,处理逻辑比较简单。
Queue TTL相关限制
如果我们需要处理的延迟数据的时间类型很多,那么就需要创建很多的队列。当然,这个方案的优点就是透明,稳定,遇到问题容易排查。
参考
【Finding bottlenecks with RabbitMQ 3.3】https://blog.rabbitmq.com/posts/2014/04/finding-bottlenecks-with-rabbitmq-3-3
【你真的了解延时队列吗】https://juejin.cn/post/6844903648397525006
【RabbitMQ实战指南】https://book.douban.com/subject/27591386/
【人工智能 rabbitmq 基于rabbitmq】https://www.dazhuanlan.com/ajin121212/topics/1209139
【rabbitmq-delayed-message-exchange】https://blog.51cto.com/kangfs/4115341
【Scheduling Messages with RabbitMQ】https://blog.rabbitmq.com/posts/2015/04/scheduling-messages-with-rabbitmq
【Centos7安装RabbitMQ最新版3.8.5,史上最简单实用安装步骤】https://blog.csdn.net/weixin_40584261/article/details/106826044
【RabbitMQ中 prefetch_count,死信队列和延迟队列的使用】https://boilingfrog.github.io/2022/01/07/rabbitmq中高级特性的使用/
RabbitMQ使用 prefetch_count优化队列的消费,使用死信队列和延迟队列实现消息的定时重试,golang版本的更多相关文章
- Spring Boot (26) RabbitMQ延迟队列
延迟消息就是指当消息被发送以后,并不想让消费者立即拿到消息,而是等待指定时间后,消费者才拿到这个消息进行消费. 延迟队列 订单业务: 在电商/点餐中,都有下单后30分钟内没有付款,就自动取消订单. 短 ...
- RabbitMQ 入门教程(PHP版) 延迟队列,延迟任务
延迟任务应用场景 场景一:物联网系统经常会遇到向终端下发命令,如果命令一段时间没有应答,就需要设置成超时. 场景二:订单下单之后30分钟后,如果用户没有付钱,则系统自动取消订单. 场景三:过1分钟给新 ...
- SpringBoot RabbitMQ 延迟队列代码实现
场景 用户下单后,如果30min未支付,则删除该订单,这时候就要可以用延迟队列 准备 利用rabbitmq_delayed_message_exchange插件: 首先下载该插件:https://ww ...
- Dyno-queues 分布式延迟队列 之 基本功能
Dyno-queues 分布式延迟队列 之 基本功能 目录 Dyno-queues 分布式延迟队列 之 基本功能 0x00 摘要 0x01 Dyno-queues分布式延迟队列 1.1 设计目标 1. ...
- Rabbitmq消费失败死信队列
Rabbitmq 重消费处理 一 处理流程图: 业务交换机:正常接收发送者,发送过来的消息,交换机类型topic AE交换机: 当业务交换机无法根据指定的routingkey去路由到队列的时候,会全部 ...
- Rabbitmq——实现消费端限流 --NACK重回队列
如果是高并发下,rabbitmq服务器上收到成千上万条消息,那么当打开消费端时,这些消息必定喷涌而来,导致消费端消费不过来甚至挂掉都有可能. 在非自动确认的模式下,可以采用限流模式,rabbitmq ...
- java操作RabbitMQ添加队列、消费队列和三个交换机
假设已经在服务器上安装完RabbitMQ.我写的教程 一.发送消息到队列(生产者) 新建一个maven项目,在pom.xml文件加入以下依赖 <dependencies> <depe ...
- Rabbitmq之高级特性——实现消费端限流&NACK重回队列
如果是高并发下,rabbitmq服务器上收到成千上万条消息,那么当打开消费端时,这些消息必定喷涌而来,导致消费端消费不过来甚至挂掉都有可能. 在非自动确认的模式下,可以采用限流模式,rabbitmq ...
- 【RabbitMQ】一文带你搞定RabbitMQ延迟队列
本文口味:鱼香肉丝 预计阅读:10分钟 一.说明 在上一篇中,介绍了RabbitMQ中的死信队列是什么,何时使用以及如何使用RabbitMQ的死信队列.相信通过上一篇的学习,对于死信队列已经有了更 ...
随机推荐
- 【Java 8】Stream API
转自 Java 8 Stream Java8的两个重大改变,一个是Lambda表达式,另一个就是本节要讲的Stream API表达式.Stream 是Java8中处理集合的关键抽象概念,它可以对集合进 ...
- 第一章-Flink介绍-《Fink原理、实战与性能优化》读书笔记
Flink介绍-<Fink原理.实战与性能优化>读书笔记 1.1 Apache Flink是什么? 在当代数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如 ...
- 第三届“传智杯”全国大学生IT技能大赛(初赛A组)题解
留念 C - 志愿者 排序..按照题目规则说的排就可以.wa了两发我太菜了qwq #include<bits/stdc++.h> using namespace std; const in ...
- JavaXML解析的四种方法(连载)
1. xml简介 XML:指可扩展标记语言, Extensible Markup Language:类似HTML.XML的设计宗旨是传输数据,而非显示数据. 一个xml文档实例: 1 <?xml ...
- 让你用Markdown的方式来做PPT
也许你是以为代码高手,Markdown写作高手,但你是PPT高手吗? 你的成绩有没有被PPT高手抢走过呢? 不会作精美PPT是不是很头疼呢? 今天就给大家介绍了一款PPT制作利器:Slidev~ 说S ...
- 删除空行(嵌套)(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- Indirect函数(Excel函数集团)
此处文章均为本妖原创,供下载.学习.探讨! 文章下载源是Office365国内版1Driver,如有链接问题请联系我. 请勿用于商业!谢谢 下载地址:https://officecommunity-m ...
- JAVA连接MySQ报错:Caused by: javax.net.ssl.SSLException: Received fatal alert: protocol_version
Caused by: javax.net.ssl.SSLException: Received fatal alert: protocol_version at sun.security.ssl.Al ...
- C++封装C语言读写文件
自己项目需要,封装C语言读写文件. 为了兼容低版本的编译器,因为低版本的编译器(比如,Vs2010,Vs2008)他们可能不支持 modern c++. 项目 使用 cmake管理的项目. 可以在 g ...
- 【九度OJ】题目1108:堆栈的使用 解题报告
[九度OJ]题目1108:堆栈的使用 解题报告 标签(空格分隔): 九度OJ http://ac.jobdu.com/problem.php?pid=1108 题目描述: 堆栈是一种基本的数据结构.堆 ...