Elasticsearch(ES)分词器的那些事儿
1. 概述
分词器是Elasticsearch中很重要的一个组件,用来将一段文本分析成一个一个的词,Elasticsearch再根据这些词去做倒排索引。
今天我们就来聊聊分词器的相关知识。
2. 内置分词器
2.1 概述
Elasticsearch 中内置了一些分词器,这些分词器只能对英文进行分词处理,无法将中文的词识别出来。
2.2 内置分词器介绍
standard:标准分词器,是Elasticsearch中默认的分词器,可以拆分英文单词,大写字母统一转换成小写。
simple:按非字母的字符分词,例如:数字、标点符号、特殊字符等,会去掉非字母的词,大写字母统一转换成小写。
whitespace:简单按照空格进行分词,相当于按照空格split了一下,大写字母不会转换成小写。
stop:会去掉无意义的词,例如:the、a、an 等,大写字母统一转换成小写。
keyword:不拆分,整个文本当作一个词。
2.3 查看分词效果通用接口
GET http://192.168.1.11:9200/_analyze
参数:
{
"analyzer": "standard",
"text": "I am a man."
}
响应:
{
"tokens": [
{
"token": "i",
"start_offset": 0,
"end_offset": 1,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "am",
"start_offset": 2,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "a",
"start_offset": 5,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "man",
"start_offset": 7,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 3
}
]
}
3. IK分词器
3.1 概述
Elasticsearch中内置的分词器不能对中文进行分词,因此我们需要再安装一个能够支持中文的分词器,IK分词器就是个不错的选择。
3.2 下载IK分词器
下载网址:https://github.com/medcl/elasticsearch-analysis-ik
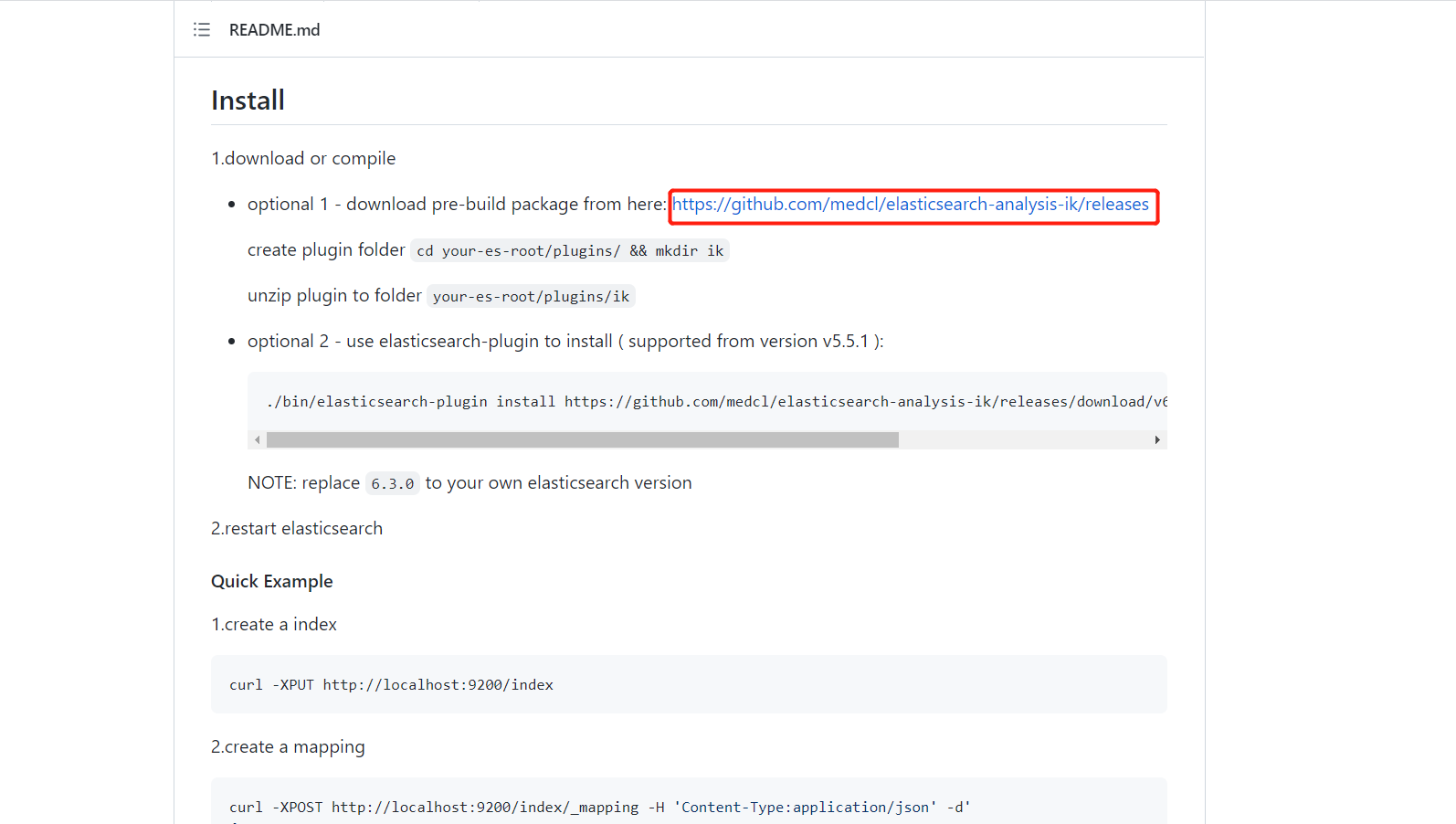
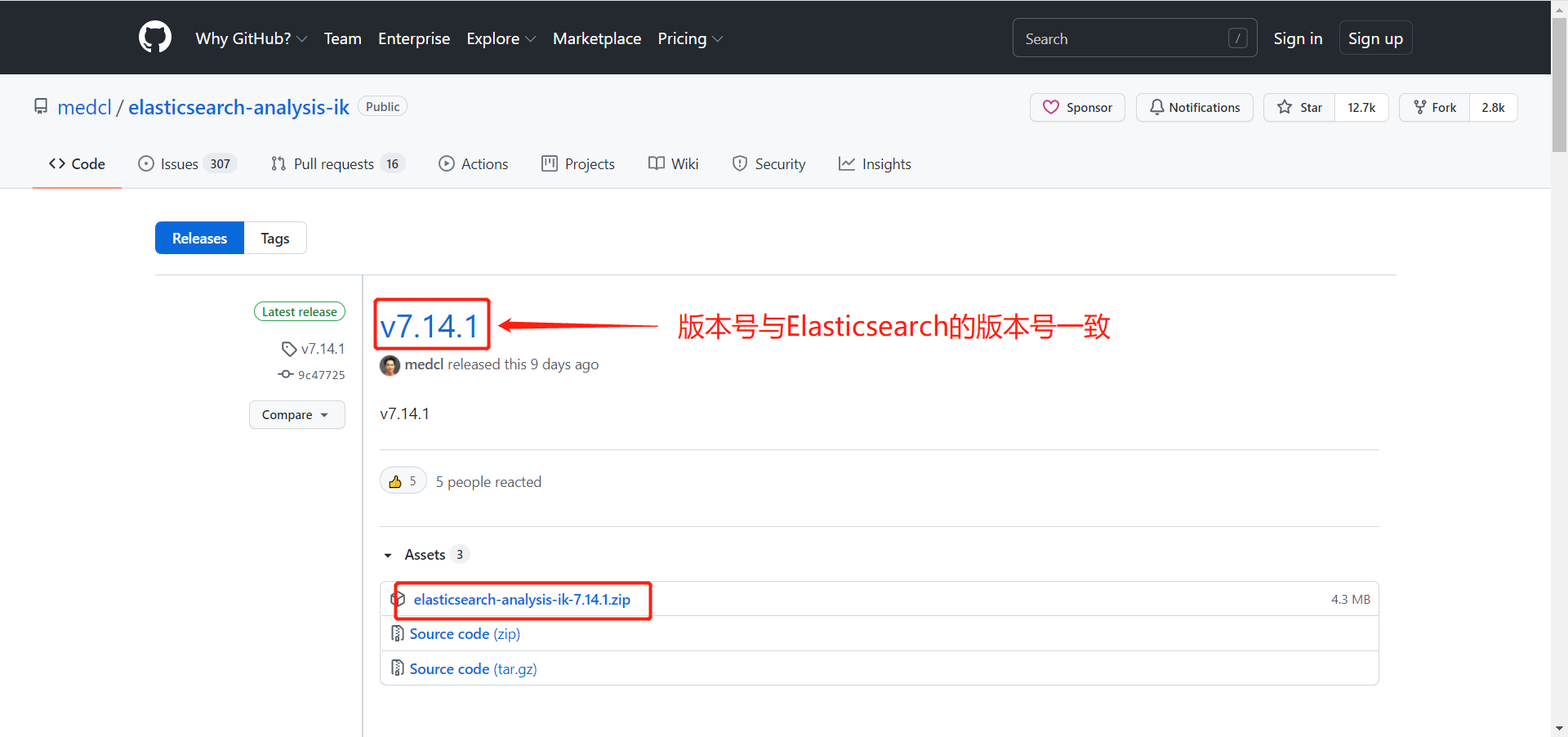
3.3 IK分词器的安装
1)为IK分词器创建目录
# cd /usr/local/elasticsearch-7.14.1/plugins
# mkdir ik
2)将IK分词器压缩包拷贝到CentOS7的目录下,例如:/home
3)将压缩包解压到刚刚创建的目录
# unzip elasticsearch-analysis-ik-7.14.1.zip -d /usr/local/elasticsearch-7.14.1/plugins/ik/
4)重启Elasticsearch
3.4 IK分词器介绍
ik_max_word: 会将文本做最细粒度的拆分,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,适合 Phrase 查询。
IK分词器介绍来源于GitHub:https://github.com/medcl/elasticsearch-analysis-ik
3.5 分词效果
GET http://192.168.1.11:9200/_analyze
参数:
{
"analyzer": "ik_max_word",
"text": "我是一名Java高级程序员"
}
响应:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "一名",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "一",
"start_offset": 2,
"end_offset": 3,
"type": "TYPE_CNUM",
"position": 3
},
{
"token": "名",
"start_offset": 3,
"end_offset": 4,
"type": "COUNT",
"position": 4
},
{
"token": "java",
"start_offset": 4,
"end_offset": 8,
"type": "ENGLISH",
"position": 5
},
{
"token": "高级",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 6
},
{
"token": "程序员",
"start_offset": 10,
"end_offset": 13,
"type": "CN_WORD",
"position": 7
},
{
"token": "程序",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 8
},
{
"token": "员",
"start_offset": 12,
"end_offset": 13,
"type": "CN_CHAR",
"position": 9
}
]
}
4. 自定义词库
4.1 概述
在进行中文分词时,经常出现分析出的词不是我们想要的,这时我们就需要在IK分词器中自定义我们自己词库。
例如:追风人,分词后,只有 追风 和 人,而没有 追风人,导致倒排索引后查询时,用户搜 追风 或 人 可以搜到 追风人,搜 追风人 反而搜不到 追风人。
4.2 自定义词库
# cd /usr/local/elasticsearch-7.14.1/plugins/ik/config
# vi IKAnalyzer.cfg.xml
在配置文件中增加自己的字典

# vi my.dic
在文本中加入 追风人,保存。
重启Elasticsearch即可。
5. 综述
今天简单聊了一下 Elasticsearch(ES)分词器的相关知识,希望可以对大家的工作有所帮助。
欢迎大家帮忙点赞、评论、加关注 :)
关注追风人聊Java,每天更新Java干货。
Elasticsearch(ES)分词器的那些事儿的更多相关文章
- elasticsearch kibana + 分词器安装详细步骤
elasticsearch kibana + 分词器安装详细步骤 一.准备环境 系统:Centos7 JDK安装包:jdk-8u191-linux-x64.tar.gz ES安装包:elasticse ...
- Elasticsearch之分词器的作用
前提 什么是倒排索引? Analyzer(分词器)的作用是把一段文本中的词按一定规则进行切分.对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言,要用不同的 ...
- Elasticsearch之分词器的工作流程
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch的分词器的一般工作流程: 1.切分关键词 2.去除停用词 3.对于英文单词,把所有字母转为小写(搜索时不区分 ...
- Elasticsearch修改分词器以及自定义分词器
Elasticsearch修改分词器以及自定义分词器 参考博客:https://blog.csdn.net/shuimofengyang/article/details/88973597
- ES 09 - 定制Elasticsearch的分词器 (自定义分词策略)
目录 1 索引的分析 1.1 分析器的组成 1.2 倒排索引的核心原理-normalization 2 ES的默认分词器 3 修改分词器 4 定制分词器 4.1 向索引中添加自定义的分词器 4.2 测 ...
- 【分词器及自定义】Elasticsearch中文分词器及自定义分词器
中文分词器 在lunix下执行下列命令,可以看到本来应该按照中文”北京大学”来查询结果es将其分拆为”北”,”京”,”大”,”学”四个汉字,这显然不符合我的预期.这是因为Es默认的是英文分词器我需要为 ...
- elasticsearch中文分词器(ik)配置
elasticsearch默认的分词:http://localhost:9200/userinfo/_analyze?analyzer=standard&pretty=true&tex ...
- elasticsearch 分析器 分词器
参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html 在全文搜索(Fu ...
- ElasticSearch中分词器组件配置详解
首先要明确一点,ElasticSearch是基于Lucene的,它的很多基础性组件,都是由Apache Lucene提供的,而es则提供了更高层次的封装以及分布式方面的增强与扩展. 所以要想熟练的掌握 ...
随机推荐
- tomcat启动时启动窗口出现乱码一招搞定
先来看看问题(图示),在tomcat的启动窗口打印的启动信息中包含了大量的中文乱码,虽然这些对tomcat本身的使用没有任何影响,但却非常碍眼,影响视觉效果! tomcat启动时启动窗口出现乱码的解决 ...
- JavaGUI输入框事件监听的使用
JavaGUI输入框事件监听的使用 package GUI; import java.awt.*; import java.awt.event.ActionEvent; import java.awt ...
- Vue-axios 封装了一手好axios:)
请求方式 很多种请求方式,重点还是第一种吧 下载 npm install axios --save 下载完成 直接导入 import axios from 'axios' 简单配置 axios({ u ...
- 跟我一起写 Makefile(八)
六.多行变量 还有一种设置变量值的方法是使用define关键字.使用define关键字设置变量的值可以有换行,这有利于定义一系列的命令(前面我们讲过"命令包"的技术就是利用这个 ...
- 在VMware中安装Centos6值得注意的几点
关于在VMware上安装centos6.9时遇到的几个值得说的点 0x01关于分区 分区时候可以选择默认分区,也可以选择自定义布局,这里选择自定义布局 点击sda,选择创建,再选标准分区->创建 ...
- 小程序使用微信地址or小程序跳转设置页
如果你有使用过小程序需要你授权微信地址的情况,那么正常的逻辑应该是这样的: 点击获取地址后,弹窗: 此时我相信选择拒绝的人应该还是比较多的,毕竟这是敏感数据,拒绝后再看页面相关功能是否有使用地址的合适 ...
- C语言 Ubuntu系统 UTF-8 文字处理
关于UTF-8的规则:https://baike.baidu.com/item/UTF-8/481798?fr=aladdin 使用windows系统下的Ubuntu子系统,实现C语言对UTF-8编码 ...
- 安全|常见的Web攻击手段之CSRF攻击
对于常规的Web攻击手段,如XSS.CRSF.SQL注入.(常规的不包括文件上传漏洞.DDoS攻击)等,防范措施相对来说比较容易,对症下药即可,比如XSS的防范需要转义掉输入的尖括号,防止CRSF攻击 ...
- 搞懂Redis协议RESP
RESP (REdis Serialization Protocal) Redis客户端和服务端之间通信的协议.它很简单,建立在TCP协议上,提供简单.高性能.可读性强的数据序列化的规范和语义. 5种 ...
- WSL(Ubuntu)下安装Redis
一.安装 输入命令安装redis-server sudo apt-get install redis-server 安装完成后打开redis.conf文件,找到bind 127.0.0.1,更改为bi ...