MinkowskiPooling池化(下)
MinkowskiPooling池化(下)
MinkowskiPoolingTranspose
class MinkowskiEngine.MinkowskiPoolingTranspose(kernel_size, stride, dilation=1, kernel_generator=None, dimension=None)
稀疏张量的池转置层。
展开功能,然后将其除以贡献的非零元素的数量。
__init__(kernel_size, stride, dilation=1, kernel_generator=None, dimension=None)
用于稀疏张量的高维解卷层。
Args:
kernel_size (int, optional): 输出张量中内核的大小。如果未提供,则region_offset应该是 RegionType.CUSTOM并且region_offset应该是具有大小的2D矩阵N×D 这样它列出了所有D维度的 N 偏移量。.
stride (int, or list, optional): stride size of the convolution layer. If non-identity is used, the output coordinates will be at least stride ×× tensor_stride away. When a list is given, the length must be D; each element will be used for stride size for the specific axis.
dilation (int, or list, optional): 卷积内核的扩展大小。给出列表时,长度必须为D,并且每个元素都是轴特定的膨胀。所有元素必须> 0。
kernel_generator (MinkowskiEngine.KernelGenerator, optional): 定义自定义内核形状。
dimension(int):定义所有输入和网络的空间的空间尺寸。例如,图像在2D空间中,网格和3D形状在3D空间中。
cpu() → T
将所有模型参数和缓冲区移至CPU。
返回值:
模块:selfcuda(device: Optional[Union[int, torch.device]] = None) → T
将所有模型参数和缓冲区移至GPU。
这也使关联的参数并缓冲不同的对象。因此,在构建优化程序之前,如果模块在优化过程中可以在GPU上运行,则应调用它。
参数:
设备(整数,可选):如果指定,则所有参数均为
复制到该设备
返回值:
模块:self
double() →T
将所有浮点参数和缓冲区强制转换为double数据类型。
返回值:
模块:self
float() →T
将所有浮点参数和缓冲区强制转换为float数据类型。
返回值:
模块:self
forward(input: SparseTensor.SparseTensor, coords: Union[torch.IntTensor, MinkowskiCoords.CoordsKey, SparseTensor.SparseTensor] = None)
input (MinkowskiEngine.SparseTensor): Input sparse tensor to apply a convolution on.
coords ((torch.IntTensor, MinkowskiEngine.CoordsKey, MinkowskiEngine.SparseTensor), optional): If provided, generate results on the provided coordinates. None by default.
to(*args, **kwargs)
Moves and/or casts the parameters and buffers.
This can be called as
to(device=None, dtype=None, non_blocking=False)
to(dtype, non_blocking=False)
to(tensor, non_blocking=False)
to(memory_format=torch.channels_last)
其签名类似于torch.Tensor.to(),但仅接受所需dtype的浮点s。另外,此方法将仅将浮点参数和缓冲区强制转换为dtype (如果给定的话)。device如果给定了整数参数和缓冲区 ,但dtype不变。当 non_blocking被设置时,它试图转换/如果可能异步相对于移动到主机,例如,移动CPU张量与固定内存到CUDA设备。
请参见下面的示例。
Args:
device (torch.device): the desired device of the parameters
and buffers in this module
dtype (torch.dtype): the desired floating point type of
the floating point parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
memory_format (torch.memory_format): the desired memory
format for 4D parameters and buffers in this module (keyword only argument)
Returns:
Module: self
Example:
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
type(dst_type: Union[torch.dtype, str]) → T
Casts all parameters and buffers to dst_type.
Arguments:
dst_type (type or string): the desired type
Returns:
Module: self
MinkowskiGlobalPooling
class MinkowskiEngine.MinkowskiGlobalPooling(average=True, mode=<GlobalPoolingMode.AUTO: 0>)
将所有输入功能集中到一个输出。
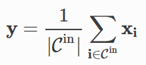
将稀疏坐标减少到原点,即将每个点云减少到原点,返回batch_size点的数量[[0,0,…,0],[0,0,…,1] ,, [0, 0,…,2]],其中坐标的最后一个元素是批处理索引。
Args:
average (bool): 当为True时,返回平均输出。如果不是,则返回所有输入要素的总和。
cpu() → T
将所有模型参数和缓冲区移至CPU。
返回值:
模块:自我
Module: self
cuda(device: Optional[Union[int, torch.device]] = None) → T
将所有模型参数和缓冲区移至GPU。
这也使关联的参数并缓冲不同的对象。因此,在构建优化程序之前,如果模块在优化过程中可以在GPU上运行,则应调用它。
参数:
device (int, optional): if specified, all parameters will be
copied to that device
Returns:
Module: self
double() → T
将所有浮点参数和缓冲区强制转换为double数据类型。
Returns:
Module: self
float() → T
将所有浮点参数和缓冲区强制转换为float数据类型。
返回值:
模块:self
forward(input)
to(*args, **kwargs)
移动和/或强制转换参数和缓冲区。
这可以称为
to(device=None, dtype=None, non_blocking=False)
to(dtype, non_blocking=False)
to(tensor, non_blocking=False)
to(memory_format=torch.channels_last)
其签名类似于torch.Tensor.to(),但仅接受所需dtype的浮点s。另外,此方法将仅将浮点参数和缓冲区强制转换为dtype (如果给定的话)。device如果给定了整数参数和缓冲区 ,dtype不变。当 non_blocking被设置时,它试图转换/如果可能异步相对于移动到主机,例如,移动CPU张量与固定内存到CUDA设备。
请参见下面的示例。
Args:
device (torch.device): the desired device of the parameters
and buffers in this module
dtype (torch.dtype): the desired floating point type of
the floating point parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
memory_format (torch.memory_format): the desired memory
format for 4D parameters and buffers in this module (keyword only argument)
Returns:
Module: self
Example:
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
type(dst_type: Union[torch.dtype, str]) → T
Casts all parameters and buffers to dst_type.
Arguments:
dst_type (type or string): the desired type
Returns:
Module: self
MinkowskiPooling池化(下)的更多相关文章
- MinkowskiPooling池化(上)
MinkowskiPooling池化(上) 如果内核大小等于跨步大小(例如kernel_size = [2,1],跨步= [2,1]),则引擎将更快地生成与池化函数相对应的输入输出映射. 如果使用U网 ...
- 卷积和池化的区别、图像的上采样(upsampling)与下采样(subsampled)
1.卷积 当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去. ...
- 【小白学PyTorch】21 Keras的API详解(下)池化、Normalization层
文章来自微信公众号:[机器学习炼丹术].作者WX:cyx645016617. 参考目录: 目录 1 池化层 1.1 最大池化层 1.2 平均池化层 1.3 全局最大池化层 1.4 全局平均池化层 2 ...
- 测试EntityFramework,Z.EntityFramework.Extensions,原生语句在不同的查询中的表现。原来池化与非池化设定是有巨大的影响的。
Insert测试,只测试1000条的情况,多了在实际的项目中应该就要另行处理了. using System; using System.Collections.Generic; using Syste ...
- 由浅入深了解Thrift之客户端连接池化
一.问题描述 在上一篇<由浅入深了解Thrift之服务模型和序列化机制>文章中,我们已经了解了thrift的基本架构和网络服务模型的优缺点.如今的互联网圈中,RPC服务化的思想如火如荼.我 ...
- Deep Learning 学习随记(七)Convolution and Pooling --卷积和池化
图像大小与参数个数: 前面几章都是针对小图像块处理的,这一章则是针对大图像进行处理的.两者在这的区别还是很明显的,小图像(如8*8,MINIST的28*28)可以采用全连接的方式(即输入层和隐含层直接 ...
- 池化 - Apache Commons Pool
对于那些创建耗时较长,或者资源占用较多的对象,比如网络连接,线程之类的资源,通常使用池化来管理这些对象,从而达到提高性能的目的.比如数据库连接池(c3p0, dbcp), java的线程池 Execu ...
- 对象池化技术 org.apache.commons.pool
恰当地使用对象池化技术,可以有效地减少对象生成和初始化时的消耗,提高系统的运行效率.Jakarta Commons Pool组件提供了一整套用于实现对象池化的框架,以及若干种各具特色的对象池实现,可以 ...
- 高可用的池化 Thrift Client 实现(源码分享)
本文将分享一个高可用的池化 Thrift Client 及其源码实现,欢迎阅读源码(Github)并使用,同时欢迎提出宝贵的意见和建议,本人将持续完善. 本文的主要目标读者是对 Thrift 有一定了 ...
随机推荐
- 从苏宁电器到卡巴斯基第27篇:难忘的三年硕士时光 V
一发不可收拾 安全领域的公司都喜欢在看雪或者是吾爱破解这样的网站上发布招聘贴,因为这样的话很容易就能够招到适合的人才,也算是精准营销了.而像我这种想进入安全圈的,也会在这里发布自己的求职简历,以期望能 ...
- POJ2688状态压缩(可以+DFS剪枝)
题意: 给你一个n*m的格子,然后给你一个起点,让你遍历所有的垃圾,就是终点不唯一,问你最小路径是多少? 思路: 水题,方法比较多,最省事的就是直接就一个BFS状态压缩暴搜就行 ...
- 子域名探测工具Aquatone的使用
目录 Aquatone Aquatone的安装 Aquatone的使用 子域名爆破 端口扫描
- NTDDK 从两个最简单的驱动谈起
第 1 章 从两个最简单的驱动谈起 Windows 驱动程序的编写,往往需要开发人员对 Windows 内核有深入了解和大量的内 核调试技巧,稍有不慎,就会造成系统的崩溃.因此,初次涉及 Window ...
- 【Android Jetpack高手日志】DataBinding 从入门到精通
前言 DataBinding 数据绑定库是 Android Jetpack 的一部分,借助该库可以使用声明性格式(而非程序化地)将布局中的界面组件绑定到应用中的数据源.我个人觉得,使用 DataBin ...
- 虚拟机之 Parallels Desktop
去官网看看 在 Mac 虚拟机中跨多个操作系统开发和测试 访问 Microsoft Office for Windows 和 Internet Explorer 快速运行 Windows 应用不会减慢 ...
- C++ scanf_s()函数的用法以及注意事项
前身--scanf() 有的教材里用的scanf(),其实在目前Visual Studio版本中已经弃用了,用scanf_s()函数代替了. 为什么现在要用scanf_s() scanf_s()函数是 ...
- DVWA--SQL Injection
sql注入是危害比较大的一种漏洞,登录数据库可以进行文件上传,敏感信息获取等等. Low 先来看一下源码 <?php if( isset( $_REQUEST[ 'Submit' ] ) ) { ...
- 数据流分析软件SQLFlow的高阶模式Job任务介绍
SQLFlow是一个可视化的在线处理SQL对象依赖关系的工具,只需要上传你的SQL脚本,它可以自动分析SQL里的数据对象,包括database.schema.table.view.column.pro ...
- curl: (35) SSL connect error
curl: (35) SSL connect error weixin_34212762 2018-02-23 20:16:23 230 收藏 文章标签: 运维 版权 阿里云的机器,昨晚githu ...