SpringCloud升级之路2020.0.x版-38. 实现自定义 WebClient 的 NamedContextFactory

实现 WeClient 的 NamedContextFactory
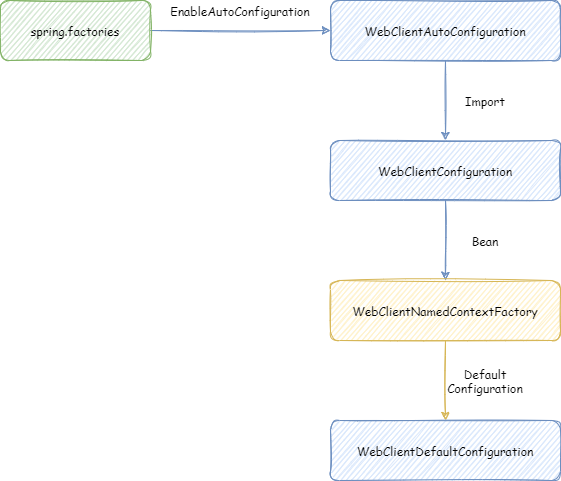
我们要实现的是不同微服务自动配置装载不同的 WebClient Bean,这样就可以通过 NamedContextFactory 实现。我们先来编写下实现这个 NamedContextFactory 整个的加载流程的代码,其结构图如下所示:
# AutoConfiguration
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.github.jojotech.spring.cloud.webflux.auto.WebClientAutoConfiguration
在 spring.factories 定义了自动装载的自动配置类 WebClientAutoConfiguration
@Import(WebClientConfiguration.class)
@Configuration(proxyBeanMethods = false)
public class WebClientAutoConfiguration {
}
WebClientAutoConfiguration 这个自动配置类 Import 了 WebClientConfiguration
@Configuration(proxyBeanMethods = false)
@EnableConfigurationProperties(WebClientConfigurationProperties.class)
public class WebClientConfiguration {
@Bean
public WebClientNamedContextFactory getWebClientNamedContextFactory() {
return new WebClientNamedContextFactory();
}
}
WebClientConfiguration 中创建了 WebClientNamedContextFactory 这个 NamedContextFactory 的 Bean。在这个 NamedContextFactory 中,定义了默认配置 WebClientDefaultConfiguration。在这个默认配置中,主要是给每个微服务都定义了一个 WebClient
定义 WebClient 的配置类
我们编写下上一节定义的配置,包括:
- 微服务名称
- 微服务地址,服务地址,不填写则为 http://微服务名称
- 连接超时,使用 Duration,这样我们可以用更直观的配置了,例如 5ms,6s,7m 等等
- 响应超时,使用 Duration,这样我们可以用更直观的配置了,例如 5ms,6s,7m 等等
- 可以重试的路径,默认只对 GET 方法重试,通过这个配置增加针对某些非 GET 方法的路径的重试;同时,这些路径可以使用 * 等路径匹配符,即 Spring 中的 AntPathMatcher 进行路径匹配多个路径。例如
/query/order/**
WebClientConfigurationProperties
@Data
@NoArgsConstructor
@ConfigurationProperties(prefix = "webclient")
public class WebClientConfigurationProperties {
private Map<String, WebClientProperties> configs;
@Data
@NoArgsConstructor
public static class WebClientProperties {
private static AntPathMatcher antPathMatcher = new AntPathMatcher();
private Cache<String, Boolean> retryablePathsMatchResult = Caffeine.newBuilder().build();
/**
* 服务地址,不填写则为 http://serviceName
*/
private String baseUrl;
/**
* 微服务名称,不填写就是 configs 这个 map 的 key
*/
private String serviceName;
/**
* 可以重试的路径,默认只对 GET 方法重试,通过这个配置增加针对某些非 GET 方法的路径的重试
*/
private List<String> retryablePaths;
/**
* 连接超时
*/
private Duration connectTimeout = Duration.ofMillis(500);
/**
* 响应超时
*/
private Duration responseTimeout = Duration.ofSeconds(8);
/**
* 是否匹配
* @param path
* @return
*/
public boolean retryablePathsMatch(String path) {
if (CollectionUtils.isEmpty(retryablePaths)) {
return false;
}
return retryablePathsMatchResult.get(path, k -> {
return retryablePaths.stream().anyMatch(pattern -> antPathMatcher.match(pattern, path));
});
}
}
}
粘合 WebClient 与 resilience4j
接下来粘合 WebClient 与 resilience4j 实现断路器以及重试逻辑,WebClient 基于 project-reactor 实现,resilience4j 官方提供了与 project-reactor 的粘合库:
<!--粘合 project-reactor 与 resilience4j,这个在异步场景经常会用到-->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-reactor</artifactId>
</dependency>
参考官方文档,我们可以像下面这样给普通的 WebClient 增加相关组件:
增加重试器:
//由于还是在前面弄好的 spring-cloud 环境下,所以还是可以这样获取配置对应的 retry
Retry retry;
try {
retry = retryRegistry.retry(name, name);
} catch (ConfigurationNotFoundException e) {
retry = retryRegistry.retry(name);
}
Retry finalRetry = retry;
WebClient.builder().filter((clientRequest, exchangeFunction) -> {
return exchangeFunction.exchange(clientRequest)
//核心就是加入 RetryOperator
.transform(RetryOperator.of(finalRetry));
})
这个 RetryOperator 其实就是使用了 project-reactor 中的 retryWhen 方法实现了 resilience4j 的 retry 机制:
@Override
public Publisher<T> apply(Publisher<T> publisher) {
//对于 mono 的处理
if (publisher instanceof Mono) {
Context<T> context = new Context<>(retry.asyncContext());
Mono<T> upstream = (Mono<T>) publisher;
return upstream.doOnNext(context::handleResult)
.retryWhen(reactor.util.retry.Retry.withThrowable(errors -> errors.flatMap(context::handleErrors)))
.doOnSuccess(t -> context.onComplete());
} else if (publisher instanceof Flux) {
//对于 flux 的处理
Context<T> context = new Context<>(retry.asyncContext());
Flux<T> upstream = (Flux<T>) publisher;
return upstream.doOnNext(context::handleResult)
.retryWhen(reactor.util.retry.Retry.withThrowable(errors -> errors.flatMap(context::handleErrors)))
.doOnComplete(context::onComplete);
} else {
//不可能是 mono 或者 flux 以外的其他的
throw new IllegalPublisherException(publisher);
}
}
可以看出,其实主要填充了:
doOnNext(context::handleResult): 在有响应之后调用,将响应结果传入 retry 的 Context,判断是否需要重试以及重试间隔是多久,并且抛出异常RetryDueToResultExceptionretryWhen(reactor.util.retry.Retry.withThrowable(errors -> errors.flatMap(context::handleErrors))):捕捉异常RetryDueToResultException,根据其中的间隔时间,返回 reactor 的重试间隔:Mono.delay(Duration.ofMillis(waitDurationMillis))doOnComplete(context::onComplete):请求完成,没有异常之后,调用 retry 的 complete 进行清理
增加断路器:
//由于还是在前面弄好的 spring-cloud 环境下,所以还是可以这样获取配置对应的 circuitBreaker
CircuitBreaker circuitBreaker;
try {
circuitBreaker = circuitBreakerRegistry.circuitBreaker(instancId, finalServiceName);
} catch (ConfigurationNotFoundException e) {
circuitBreaker = circuitBreakerRegistry.circuitBreaker(instancId);
}
CircuitBreaker finalCircuitBreaker = circuitBreaker;
WebClient.builder().filter((clientRequest, exchangeFunction) -> {
return exchangeFunction.exchange(clientRequest)
//核心就是加入 CircuitBreakerOperator
.transform(CircuitBreakerOperator.of(finalCircuitBreaker));
})
类似的,CircuitBreakerOperator 其实也是粘合断路器与 reactor 的 publisher 中的一些 stage 方法,将结果的成功或者失败记录入断路器,这里需要注意,可能有的链路能走到 onNext,可能有的链路能走到 onComplete,也有可能都走到,所以这两个方法都要记录成功,并且保证只记录一次:
class CircuitBreakerSubscriber<T> extends AbstractSubscriber<T> {
private final CircuitBreaker circuitBreaker;
private final long start;
private final boolean singleProducer;
private final AtomicBoolean successSignaled = new AtomicBoolean(false);
private final AtomicBoolean eventWasEmitted = new AtomicBoolean(false);
protected CircuitBreakerSubscriber(CircuitBreaker circuitBreaker,
CoreSubscriber<? super T> downstreamSubscriber,
boolean singleProducer) {
super(downstreamSubscriber);
this.circuitBreaker = requireNonNull(circuitBreaker);
this.singleProducer = singleProducer;
this.start = circuitBreaker.getCurrentTimestamp();
}
@Override
protected void hookOnNext(T value) {
if (!isDisposed()) {
//正常完成时,断路器也标记成功,因为可能会触发多次(因为 onComplete 也会记录),所以需要 successSignaled 标记只记录一次
if (singleProducer && successSignaled.compareAndSet(false, true)) {
circuitBreaker.onResult(circuitBreaker.getCurrentTimestamp() - start, circuitBreaker.getTimestampUnit(), value);
}
//标记事件已经发出,就是已经执行完 WebClient 的请求,后面判断取消的时候会用到
eventWasEmitted.set(true);
downstreamSubscriber.onNext(value);
}
}
@Override
protected void hookOnComplete() {
//正常完成时,断路器也标记成功,因为可能会触发多次(因为 onNext 也会记录),所以需要 successSignaled 标记只记录一次
if (successSignaled.compareAndSet(false, true)) {
circuitBreaker.onSuccess(circuitBreaker.getCurrentTimestamp() - start, circuitBreaker.getTimestampUnit());
}
downstreamSubscriber.onComplete();
}
@Override
public void hookOnCancel() {
if (!successSignaled.get()) {
//如果事件已经发出,那么也记录成功
if (eventWasEmitted.get()) {
circuitBreaker.onSuccess(circuitBreaker.getCurrentTimestamp() - start, circuitBreaker.getTimestampUnit());
} else {
//否则取消
circuitBreaker.releasePermission();
}
}
}
@Override
protected void hookOnError(Throwable e) {
//记录失败
circuitBreaker.onError(circuitBreaker.getCurrentTimestamp() - start, circuitBreaker.getTimestampUnit(), e);
downstreamSubscriber.onError(e);
}
}
我们会使用这个库进行粘合,但是不会直接使用上面的代码,因为考虑到:
- 需要在重试以及断路中加一些日志,便于日后的优化
- 需要定义重试的 Exception,并且与断路器相结合,将非 2xx 的响应码也封装成特定的异常
- 需要在断路器相关的 Operator 中增加类似于 FeignClient 中的负载均衡的数据更新,使得负载均衡更加智能
在下面一节我们会详细说明我们是如何实现的有断路器以及重试逻辑和负载均衡数据更新的 WebClient。
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

SpringCloud升级之路2020.0.x版-38. 实现自定义 WebClient 的 NamedContextFactory的更多相关文章
- SpringCloud升级之路2020.0.x版-1.背景
本系列为之前系列的整理重启版,随着项目的发展以及项目中的使用,之前系列里面很多东西发生了变化,并且还有一些东西之前系列并没有提到,所以重启这个系列重新整理下,欢迎各位留言交流,谢谢!~ Spring ...
- SpringCloud升级之路2020.0.x版-41. SpringCloudGateway 基本流程讲解(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 接下来,将进入我们升级之路的又一大模块,即网关模块.网关模块我们废弃了已经进入维护状态的 ...
- SpringCloud升级之路2020.0.x版-6.微服务特性相关的依赖说明
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford spring-cl ...
- SpringCloud升级之路2020.0.x版-10.使用Log4j2以及一些核心配置
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford 我们使用 Log4 ...
- SpringCloud升级之路2020.0.x版-43.为何 SpringCloudGateway 中会有链路信息丢失
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 在开始编写我们自己的日志 Filter 之前,还有一个问题我想在这里和大家分享,即在 Sp ...
- SpringCloud升级之路2020.0.x版-37. 实现异步的客户端封装配置管理的意义与设计
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 为何需要封装异步 HTTP 客户端 WebClient 对于同步的请求,我们使用 spri ...
- SpringCloud升级之路2020.0.x版-42.SpringCloudGateway 现有的可供分析的请求日志以及缺陷
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 网关由于是所有外部用户请求的入口,记录这些请求中我们需要的元素,对于线上监控以及业务问题定 ...
- SpringCloud升级之路2020.0.x版-29.Spring Cloud OpenFeign 的解析(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 在使用云原生的很多微服务中,比较小规模的可能直接依靠云服务中的负载均衡器进行内部域名与服务 ...
- SpringCloud升级之路2020.0.x版-34.验证重试配置正确性(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 在前面一节,我们利用 resilience4j 粘合了 OpenFeign 实现了断路器. ...
随机推荐
- ☠全套Java教程_Java基础入门教程,零基础小白自学Java必备教程👾#010 #第十单元 Scanner类、Random类 #
一.本单元知识点概述 (Ⅰ)知识点概述 二.本单元教学目标 (Ⅰ)重点知识目标 1.API的使用2.Scanner类的使用步骤3.Random类的使用 (Ⅱ)能力目标 1.掌握API的使用步骤2.使用 ...
- Windows10系统下Java JDK下载、安装与环境变量配置(全网最全步骤)
1.首先要明确: JDK.JRE.JVM的含义 2.下载目前最新的JDK:Java SE Development Kit 17,传送门::https://www.oracle.com/java/tec ...
- 学习Tomcat(七)之Spring内嵌Tomcat
前面的文章中,我们介绍了Tomcat容器的关键组件和类加载器,但是现在的J2EE开发中更多的是使用SpringBoot内嵌的Tomcat容器,而不是单独安装Tomcat应用.那么Spring是怎么和T ...
- NOI 2021 部分题目题解
最近几天复盘了一下NOI 2021,愈发发觉自己的愚蠢,可惜D2T3仍是不会,于是只写前面的题解 Day1 T1 可以发现,每次相当于将 \(x\to y\) 染上一种全新颜色,然后一条边是重边当且仅 ...
- JAVA String、StringBuffer、StringBuilder类解读
JAVA String.StringBuffer.StringBuilder类解读 字符串广泛应用 在 Java 编程中,在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作 ...
- 你知道什么是JUC了吗?
多线程一直Java开发中的难点,也是面试中的常客,趁着还有时间,打算巩固一下JUC方面知识,我想机会随处可见,但始终都是留给有准备的人的,希望我们都能加油!!! 沉下去,再浮上来,我想我们会变的不一样 ...
- [Beta]the Agiles Scrum Meeting 8
会议时间:2020.5.22 21:00 1.每个人的工作 今天已完成的工作 成员 已完成的工作 issue yjy 帮助解决博客评分功能遇到的问题 tq 暂无 wjx 完成批量创建团队项目功能 班级 ...
- Asp.net Core C#进行筛选、过滤、使用PredicateBuilder进行动态拼接lamdba表达式树并用作条件精准查询,模糊查询
在asp.net core.asp.net 中做where条件过滤筛选的时候写的长而繁琐不利于维护,用PredicateBuilder进行筛选.过滤.LInq配合Ef.core进行动态拼接lamdba ...
- 使用registry搭建docker私服仓库
使用registry搭建docker私服仓库 一.拉取 registry镜像 二.根据镜像启动一个容器 1.创建一个数据卷 2.启动容器 三.随机访问一个私服的接口,看是否可以返回数据 四.推送一个镜 ...
- 2021.9.7考试总结[NOIP模拟49]
T1 Reverse $BFS$暴力$O(n^2)$ 过程中重复枚举了很多点,考虑用链表记录当前点后面可到达的第一个未更新点. 搜索时枚举翻转子串的左端点,之后便可以算出翻转后$1$的位置. $cod ...