Spark 集群安装部署
安装准备
Spark 集群和 Hadoop 类似,也是采用主从架构,Spark 中的主服务器进程就叫 Master(standalone 模式),从服务器进程叫 Worker
Spark 集群规划如下:
- node-01:Master
- node-02:Worker
- node-03:Worker
安装步骤
1. 上传并解压 Spark 安装文件
将 spark-2.4.7-bin-hadoop2.7.tgz 安装包上传到 node-01 的 /root 目录下,并将其解压
# 解压到 /apps 目录中
[root@node-01 ~]# tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz -C apps/
# 删除安装压缩包
[root@node-01 ~]# rm -rf spark-2.4.7-bin-hadoop2.7.tgz
[root@node-03 ~]# cd /root/apps/
# 改名
[root@node-01 apps]# mv spark-2.4.7-bin-hadoop2.7/ spark-2.4.7
2. 配置环境变量
[root@node-01 ~]# vim /etc/profile
#行尾添加
export SPARK_HOME=/root/apps/spark-2.4.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@node-01 ~]# source /etc/profile
3. 配置运行环境
[root@node-01 ~]# cd /root/apps/spark-2.4.7/conf/
# 改名(去掉后面的 template 模板后缀名)
[root@node-01 conf]# mv spark-env.sh.template spark-env.sh
[root@node-01 conf]# vi spark-env.sh
# 行尾添加
export JAVA_HOME=/root/apps/jdk1.8.0_141/
# 设置 Spark Master 所在的主机名(或IP地址)
export SPARK_MASTER_HOST=node-01
export SPARK_MASTER_PORT=7077
4. 修改 slaves 配置
该脚本文件用于设置 Master 下面的 Worker 的主机名(或IP地址)
[root@node-01 ~]# cd /root/apps/spark-2.4.7/conf/
# 改名(去掉后面的 template 模板后缀名)
[root@node-01 conf]# mv slaves.template slaves
[root@node-01 conf]# vi slaves
node-02
node-03
5. 创建启动和关闭 Spark 集群脚本软连接
创建软连接的原因是 hadoop/sbin 目录和 spark/sbin 目录脚本可能命名相同,导致执行命令冲突
[root@node-01 ~]# cd /root/apps/spark-2.4.7/sbin/
[root@node-01 sbin]# ln -s start-all.sh start-all-spark.sh
[root@node-01 sbin]# ln -s stop-all.sh stop-all-spark.sh
5. 将 Spark 安装包复制到集群其他主机上
[root@node-01 ~]# cd /etc
[root@node-01 etc]# scp profile node-02:$PWD
[root@node-01 etc]# scp profile node-03:$PWD
[root@node-02 ~]# source /etc/profile
[root@node-03 ~]# source /etc/profile
[root@node-01 ~]# cd apps/
[root@node-01 apps]# scp -r spark-2.4.7/ node-02:$PWD
[root@node-01 apps]# scp -r spark-2.4.7/ node-03:$PWD
6. 启动 Spark 集群
Spark 的 sbin 目录(里面存放各种 Spark 操作命令)
[root@node-01 ~]# start-all-spark.sh
starting org.apache.spark.deploy.master.Master, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hdp-01.out
hdp-03: starting org.apache.spark.deploy.worker.Worker, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hdp-03.out
hdp-02: starting org.apache.spark.deploy.worker.Worker, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hdp-02.out
[root@hdp-01 sbin]# jps
1690 Master
1742 Jps
再去查看 node-02 和 node-03
[root@node-02 ~]# jps
1557 Jps
1512 Worker
[root@node-03 ~]# jps
1538 Worker
1583 Jps
说明 Spark 集群已经启动成功
- 单独启动 Master:# start-master.sh
- 单独启动 Worker:# start-slave.sh spark://node-01:7077
6. 启动 Spark 的浏览器 Web 页面
这里 Web 的服务器端口号是 8080(端口号 7077 是 RPC 远程调用的通信端口)
打开浏览器输入:http://node-01:8080/ 回车
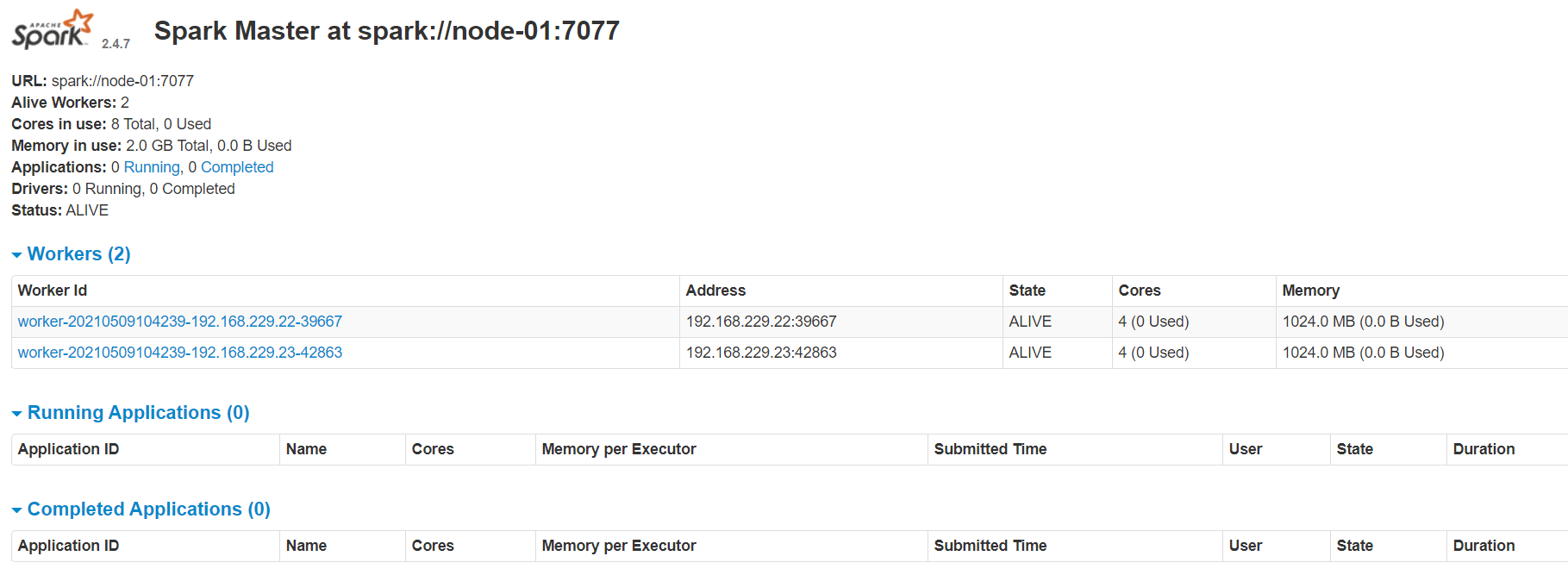
默认情况下 Spark 会占用机器上的所有 cores(CPU)和 memory(内存)
Spark 集群安装部署的更多相关文章
- Hadoop2.2集群安装配置-Spark集群安装部署
配置安装Hadoop2.2.0 部署spark 1.0的流程 一.环境描写叙述 本实验在一台Windows7-64下安装Vmware.在Vmware里安装两虚拟机分别例如以下 主机名spark1(19 ...
- spark集群安装部署
通过Ambari(HDP)或者Cloudera Management (CDH)等集群管理服务安装和部署在此不多介绍,只需要在界面直接操作和配置即可,本文主要通过原生安装,熟悉安装配置流程. 1.选取 ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
- Spark 个人实战系列(1)--Spark 集群安装
前言: CDH4不带yarn和spark, 因此需要自己搭建spark集群. 这边简单描述spark集群的安装过程, 并讲述spark的standalone模式, 以及对相关的脚本进行简单的分析. s ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
随机推荐
- 有关指针和C语言中的常量
常量类型(五种): 字面常量(2,3,6....) ; enum 定义的枚举常量; 字符常量('a','b'....) ; ...
- 梳理一下最近准备蓝桥杯时学习DP问题的想法
学习时间不长,记录的只是学习过程的思路和想法,不能保证正确,代码可以在acwing上AC. 01背包问题: 1.首先是简单的01背包问题 2.先确定状态,f[i][j]表示有第i件物品,时间为j的最大 ...
- Leedcode算法专题训练(字符串)
4. 两个字符串包含的字符是否完全相同 242. Valid Anagram (Easy) Leetcode / 力扣 可以用 HashMap 来映射字符与出现次数,然后比较两个字符串出现的字符数量是 ...
- JavaScript 中对象解构时指定默认值
待解构字段为原始值 正常情况下, const obj = { a: 1, b: 2, }; const { a, b } = obj; console.log(a, b); // 1 2 当被解构字段 ...
- 无法Ping通阿里云服务器的公网IP地址的解决方法
解决步骤: 1.打开控制台2.打开防火墙3.添加规则添加规则的详情页,可以添加全部TCP也可以自定义添加一定端口范围的TCP:
- TypeScript在React项目中的使用总结
序言 本文会侧重于TypeScript(以下简称TS)在项目中与React的结合使用情况,而非TS的基本概念.关于TS的类型查看可以使用在线TS工具TypeScript游乐场 React元素相关 Re ...
- Kubernetes查看可用的apiVersion版本
命令: kubectl api-versions
- B - 抽屉 POJ - 2356 (容斥原理)
The input contains N natural (i.e. positive integer) numbers ( N <= 10000 ). Each of that numbers ...
- hdu4396 多状态spfa
题意: 给你一个图,让你送起点走到终点,至少经过k条边,问你最短路径是多少.... 思路: 把每个点拆成50点,记为dis[i][j] (i 1---50 ,j 1---n); ...
- 病毒木马查杀实战第017篇:U盘病毒之专杀工具的编写
前言 经过前几次的讨论,我们对于这次的U盘病毒已经有了一定的了解,那么这次我们就依据病毒的行为特征,来编写针对于这次U盘病毒的专杀工具. 专杀工具功能说明 因为这次是一个U盘病毒,所以我打算把这次的专 ...