Sparse R-CNN: End-to-End Object Detection with Learnable Proposals 论文解读
前言
事实上,Sparse R-CNN 很多地方是借鉴了去年 Facebook 发布的 DETR,当时应该也算是惊艳众人。其有两点:
- 无需 nms 进行端到端的目标检测
- 将 NLP 中的 Transformer 引入到了 CV 领域(关于 Transformer 我在这里有提到。)
然而 DETR 需要每个目标的 query 和全局语义信息进行 interact (这里可以理解为进行相关性的计算), DETR 这种密集(dense)计算的性质使得其训练时间长,而且限制了它成为一个彻底的稀疏(sparse)的目标检测算法。Sparse R-CNN 则认为 sparse 性质在于两方面:
- sparse boxes:是指小数量的 starting boxes(初始的 boxes),这已经足以预测一张图中的所有目标了。
- sparse features:暗指每个 box 的 feature 不需要和全图中所有其他的 features 进行interact。
不同类型目标检测框架的比较

算法的分类
目前主流的目标检测算法可以分为:一阶段和两阶段的目标检测算法,两阶段的目标检测算法常常是有先验框(anchor-based)的,而一阶段又分为 anchor-based 和 anchor-free 两种。如果根据定义 object candidates 的方式来分:
Dense object candidates
这类算法常常是一阶段的,它们采用密集的候选目标进行预测。比如,anchor-based 会根据特征图的大小铺设先验框,假如特征图大小是 \(B \times C \times 8 \times 8\)。这张特征图最终会预测出 \(64 \times K \times 4\) 个先验框的偏移(因为这 64 个位置上,每个位置有预设不同长宽比的 K 个先验框,每个先验框有 4 个参数,所以它等于预测了原图上的 64 位置上所有先验框的偏移),先验框根据预测偏移得到最后的预测框。在训练阶段预测框根据预测框与真值框的比较(可能是 IoU 或其他标准)进行正样本的确定,在测试阶段通过后处理来过滤掉多余的框。
同理 anchor-free 的算法,同样也是根据这样网格点式的去预测,不同的是它没有先验框了,可能会直接预测角点的坐标或者中心点偏移长宽或格点到四条边的距离。总之,最后每个格点会得到一个框,选取正样本也许跟 anchor-based 一样,也许就直接根据格点离真值框中心来确定。预测部分是一样的。
Dense to sparse object candidates
这类算法一般是两阶段的,在第一阶段它们像 Dense object candidates 进行预测,但是每个位置不预测类别,只预测是前景还是背景。然后选出可能概率在 top 2k 的框,对特征图或者原图进行截取,通过 roi-aligned 等操作调整到统一的大小,进行第二阶段的预测。第二阶段主要预测每个框的具体类别与位置信息的再次调整。
sparse object candidates
这类算法直接提出 k 个区域或者说 boxes,例如 DETR、Deformable-DETR、Sparse-RCNN。训练的时候通过匈牙利算法进行一对一的匹配,预测的时候只需设置分数进行过滤就行了。
算法的比较
在上述分类中,无论是第一类还是第二类都存在以下的问题:
- 产生太多冗余的结果和十分接近的结果,因此而不得不使用 NMS,而 NMS 会产生很多问题(比如在单阶段的算法中因为分类和回归不一致影响算法表现;物体密集时,将正确的结果给抑制掉了)
- 在训练中多对一的分配规则使得网络对启发式分配规则十分敏感
- 性能表现极大受到尺寸、纵横比和先验框的数量影响
正因此,sparse 类的网络不断提出,实现 one-to-one 的匹配原则,去除了人工预设的先验框与复杂的后处理。
Sparse R-CNN
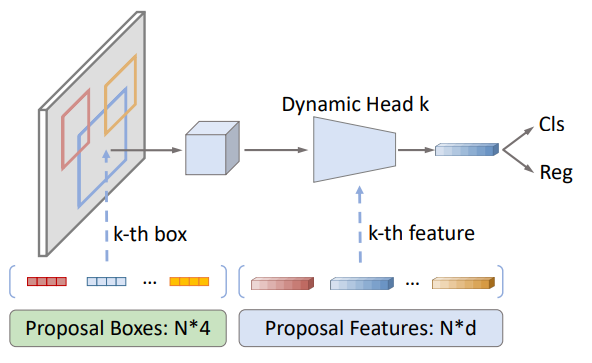
总体结构 (pipeline)
首先使用 resnet + fpn 进行特征图的提取,然后使用初始化的 proposal boxes 和 proposal features 进行迭代式地对 proposal boxes 进行修正。
Backbone & Neck
文章的 backbone + neck 是使用的 Resnet50 + FPN 或者 Resnet101 + FPN。其中 Resnet 部分是将 res2 - res5 的输出输入到 FPN 之中,FPN 的最顶层是用 LastLevelMaxPool 得到,但最后只使用了 p2 - p5 (eg. p2 是由 res2 得到的),输出特征的通道均为 256。
Head -> DynamicHead
首先,使用 Embedding 的权重获得 shape 为 (num_proposals, 4) 的初始化 proposal boxes(这里 boxes 的第二维是中心点坐标和宽高在的原图的比例),并将 proposal boxes 初始值设置为 (0.5, 0.5, 1, 1),也就是说最初始的 proposal boxes 在图片中心,宽高与图片相同。作者也提供了其他初始化的方式,比如均匀分布在图片上,没有采用,应该是这个效果最好),proposal features 则是直接采用 shape 为 (num_proposals, proposal_dim) 的 Embedding 的权重。(在文中 num_proposals 为 100/300 即建议框的数量)
RCNNHead
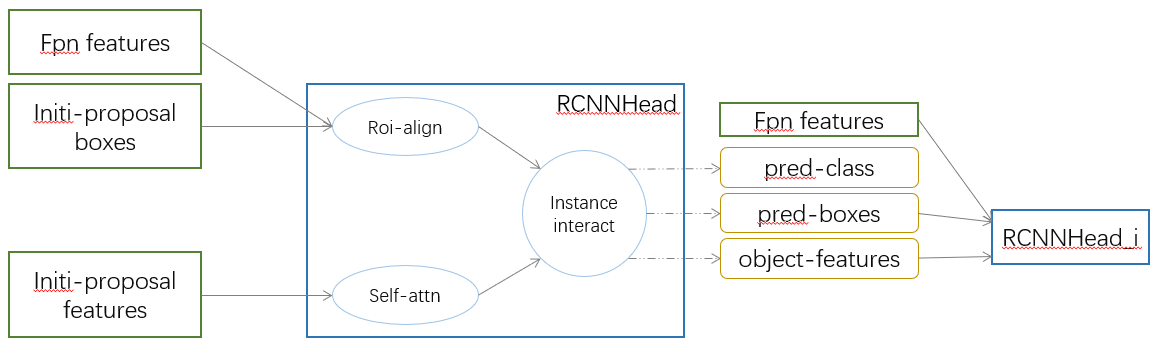
如上图所示,RCNNHead 主要接收三个输入 fpn features, proposal boxes, proposal features,其中后面两个输入使用上述 initial 方式作为初始值,之后使用预测的 boxes 和 features 作为下一个 RCNNHead 的输入。所以这里是一个不断迭代不断修正的过程。首先使用 fpn features 和 proposal boxes 经过 roi-align 得到 roi features,然后和 proposal features 进行 instance interactive(这里比较容易理解这个名字,因为 roi features 和 proposal features 都是 num_proposals 个 proposal 的 feature。输出为 pred_class, pred_boxes, proposal_features 后两者会被送入下一个 RCNNHead。(值得注意的是 boxes 是脱离了计算图后被送入的)
DynamicConv
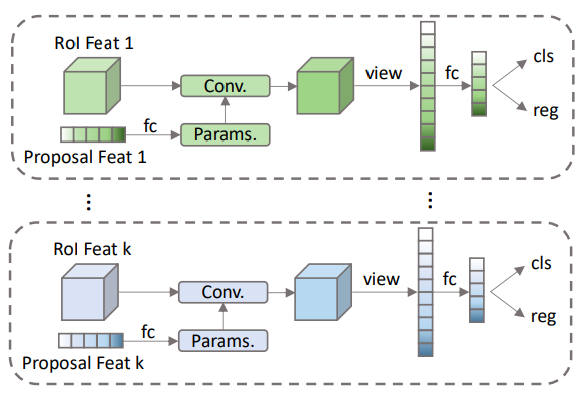
DynamicConv 的作用就是将 roi features 和 proposal features 进行 instance interactive,如上图具体的做法就是 proposal features 通过 fc 层得到相应 params。文章代码是将得到的 params 分为两部分,然后先后与 roi features 进行矩阵相乘,最后经过全连接层得到 features,再送入 RCNNHead 进行 class 和 boxes 的预测。
Learnable proposal boxes
关于 proposal boxes 需要注意以下几点:
- 除了最开始初始化的 proposal boxes,后面都是用的前一个 RCNNHead 预测的 boxes 作为的 proposal boxes。主要作用是获取 fpn features 上相应区域的 features。
- 最初始的 boxes 是相对于图片归一化的数据,但是送入网络前会被调整为真实大小,预测的实际上偏移量,同样会被调整为经偏移量调整后的 boxes。
- RPN 的 proposals 与当前的图片强相关并且提供粗糙的位置信息,然而文章认为后面阶段的 RCNNHead 来 refine 初始的 boxes 代价是很大的,因此文章认为将包含所有潜在目标的位置统计信息(即整张图)让网络直接去选择,会更加有效。
Learnable proposal features
文章考虑到 4 维的 proposal box 虽然能简单明了地描述 objects,但是很多语义信息、目标的形状、目标的姿势等都丢失了。因此,使用了更高维的 tensor 来编码丰富的实例特征。
其他细节
Each RoI feature is fed into its own exclusive head for object location and classification, where each head is conditioned on specific proposal feature
这里图看起来是一个并行的结构,实际上代码实现的是一个迭代的过程,上一个 head 预测的 boxes 和 proposal features 送入下一个 head,进入 head 后使用 boxes 获得该 head 的 RoI feature。需要注意的是,boxes 虽然使用上一个 head 的结果,但是会和上一个 head 的计算图分离,不会进行梯度回传,proposal boxes 则是会梯度回传到上一个 head。
The proposal feature generates kernel parameters of convolution, then RoI feature is processed by the generated convolution to obtain the final feature.
这里就是上文提到也是上图展示的 proposal features 会通过 fc 得到 param,这个 param 会当作卷积的 kernel。而且文章使用矩阵相乘的形式来实现这种卷积。
Loss
Sparse R-CNN 实际上沿用的 DETR 的 loss 和正样本匹配方式即:使用 Hungarian 算法。
\]
其中 \(\lambda\) 是权重因子,上式的权重因子分别为:2.0,5.0,2.0。我觉得这样设置的原因在于 boxes 的 l1 loss 是归一化后进行计算的,如果按照百分之一的误差,那么 boxes 会降到 0.04(因为有 4 个参数的 l1 loss)。此时分类 loss 和 giou loss 肯定在 0.1 及其以上,这样的话 boxes l1 占比很小,不会作为主要优化的一项,也就不可能降到 0.1 了,便到不到百分之一的误差了。论文的 l1 loss 是计算的左上角和右下角 xyxy 与真值的绝对值之和,而 DETR 则是使用的中心点坐标加上宽高。另外论文使用了 focal loss 作为分类损失函数,DETR 使用的多类别交叉熵。
Experiments
训练方面
优化器选择了 AdamW 使用了 0.0001 的权重衰减,batch—size 为 16,8 块 GPU,学习率为 0.000025, 并在 epoch 为 27 或者 33 时进行十倍的减少。预训练权重是在 ImageNet 上训练的,其余的层都使用 Xavier 进行初始化。采用了多尺度训练和预测。
推理方面
唯一的后处理是将无效的 boxes 进行移除,然后将 boxes 调整为适合原图大小的尺寸(因为图片进行了 resize)。eval 的时候直接全部送入 coco 里面,根据作者介绍 coco 的计算方式会匹配分数最高的 boxes ,其余的不会产生影响。在测试阶段,设定一个分数(因为只有有物体的框分数才比较高)这里 DETR 设置的 0.7。
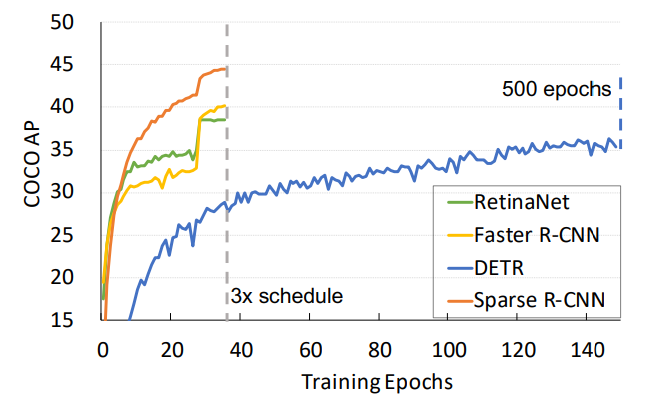
可以看到其只用了 36 epoch 达到了比 DETR 500 epoch 还好的效果。
官方代码位置
Pytorch 代码位置
Paddle 代码位置
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals 论文解读的更多相关文章
- Rank & Sort Loss for Object Detection and Instance Segmentation 论文解读(含核心源码详解)
第一印象 Rank & Sort Loss for Object Detection and Instance Segmentation 这篇文章算是我读的 detection 文章里面比较难 ...
- Minimum Barrier Salient Object Detection at 80 FPS 论文阅读笔记
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
- [Arxiv1706] Few-Example Object Detection with Model Communication 论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #042eee } p. ...
- object detection[NMS]
非极大抑制,是在对象检测中用的较为频繁的方法,当在一个对象区域,框出了很多框,那么如下图: 上图来自这里 目的就是为了在这些框中找到最适合的那个框.有以下几种方式: 1 nms 2 soft-nms ...
- 『计算机视觉』FPN:feature pyramid networks for object detection
对用卷积神经网络进行目标检测方法的一种改进,通过提取多尺度的特征信息进行融合,进而提高目标检测的精度,特别是在小物体检测上的精度.FPN是ResNet或DenseNet等通用特征提取网络的附加组件,可 ...
- 论文阅读笔记六十三:DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling(CVPR2017)
论文原址:https://arxiv.org/abs/1703.10295 github:https://github.com/lachlants/denet 摘要 本文重新定义了目标检测,将其定义为 ...
- Histograms of Sparse Codes for Object Detection用于目标检测的稀疏码直方图
AbstractObject detection has seen huge progress in recent years, much thanks to the heavily-engineer ...
- (转)Awesome Object Detection
Awesome Object Detection 2018-08-10 09:30:40 This blog is copied from: https://github.com/amusi/awes ...
- 论文阅读之 DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation
DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation Xia ...
随机推荐
- matlab数值类型
matlab数值类型 数值类型的分类 整数类型 整数类型有8种.上面的数字为其内存大小,如:int8,整数所占内存大小为8个字节.除了int64 和 uint64不能进行数值运算之外都可以. 类 ...
- [Web] 通用轮播图代码示例
首先是准备好的几张图片, 它们的路径是: "img/1.jpg", "img/2.jpg", "img/3.jpg", "img/ ...
- Android NDK工程的编译和链接以及使用gdb进行调试
前提条件:已经安装了JDK 6.0.android SDK.NDK r9和eclipsele4.2开发环境. 推荐下载Android开发的综合套件adt-bundle-windows-x86,再下载A ...
- hdu4115 2sat
题意: 两个人玩剪刀石头布,他们玩了n把,给了你A这n把都出了什么,问你B能否会赢,其中A会限制B某些局数出的要相同,某些局数出的要不同,只要B满足他的限制,并且没没有输掉任何一把就算赢( ...
- Python脚本扫描给定网段的MAC地址表(scapy或 python-nmap)
目录 用scapy模块写 用 python-nmap 模块写 python3.7 windows环境 以下两个都可以扫描指定主机或者指定网段的 IP 对应的 MAC 地址,然后保存到 csv 文件中 ...
- YII框架安装步骤(yii框架版本1.1.20,时间是2018/11)
0x01 首先中文官网下载https://www.yiichina.com/download 0x02 解压压缩包到www目录下(方便以后调试) 0x02-1 如果想看一下你的电脑是否能匹配yii框架 ...
- XCTF-ics-05
ics-05 题目描述 其他破坏者会利用工控云管理系统设备维护中心的后门入侵系统 解题步骤 用dirsearch和御剑扫了一下,只有index.php,尝试了一边,也只有index.php,也就是设备 ...
- Python数模笔记-Sklearn(1) 介绍
1.SKlearn 是什么 Sklearn(全称 SciKit-Learn),是基于 Python 语言的机器学习工具包. Sklearn 主要用Python编写,建立在 Numpy.Scipy.Pa ...
- 【python】Leetcode每日一题-删除排序链表中的重复元素
[python]Leetcode每日一题-删除排序链表中的重复元素 [题目描述] 存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除所有重复的元素,使每个元素 只出现一次 . 返回同 ...
- Day003 数据类型
数据类型 强类型语言 要求变量的使用要严格符合规定,所有变量都必须先定义后才能使用(java.c++.c#) 弱类型语言 与强类型语言定义相反(javaScript) Java的数据类型 基本 ...