MySQL数据库复制技术应用实战(阶段二)
MySQL数据库复制技术应用实战(阶段二)文档
|
作者 |
刘畅 |
|
时间 |
2020-9-27 |
服务器版本:CentOS Linux release 7.5.1804
|
主机名 |
ip地址 |
服务器配置 |
安装软件 |
密码 |
|
mysql01 |
172.16.1.151 |
2核/2G/60G |
mysql5.7.31(二进制版) |
|
|
mysql02 |
172.16.1.152 |
2核/2G/60G |
mysql5.7.31(二进制版) |
|
|
mysql03 |
172.16.1.153 |
2核/2G/60G |
mysql5.7.31(二进制版) |
目录
1 复制介绍
1.1什么是mysql复制
复制是指从一个MySQL数据库服务器(主)的数据复制到一个或多个MySQL数据库服务器(从),从库读取更新记录,并执行更新记录,使得从库的内容与主库保持一致。MySQL主从复制是一个异步的复制过程。MySQL5.7支持两种复制方式:基于二进制日志文件的位置复制和基于全局事务标识符(GTID)的复制。
1.2 为什么要做MySQL主从复制
1 横向扩展
扩展多个从库以提高性能。在这种场景中,所有写入和更新都必须在主库上进行,所有读取在一个或多个从库上。可以大大提高写入性能和读取性能。
2 数据安全
可作为备份,也可以在从库上备份数据,而不会影响主库。
3 数据分析
实时数据在主库,而数据的分析可以在从库上而不影响主库性能。
1.3 基于二进制日志位置复制的工作原理

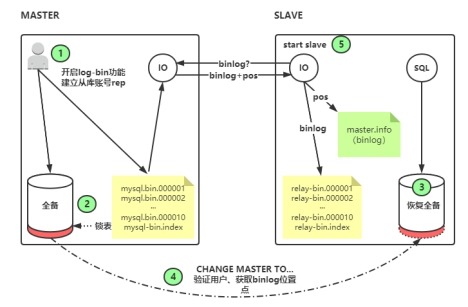
1 Replication线程
(1) master与slave之间实现整个复制过程主要由三个线程完成:两个(SQL线程和IO线程)在slave端,一个(IO线程)在master端。
(2)
要实现MySQL的replication,必须打开master端的Binary Log(mysql-bin.xxx)功能。整个复制过程实际上就是slave从master端获取日志然后在自己身上顺序执行日志中记录的各种操作。
2 复制基本过程(异步的)
(1)
mysql master将insert、delet、update数据的sql语句写入到binlog中。
(2)
slave上的IO线程连接master,请求从指定日志文件的指定位置(或者从最开始)之后的日志内容。
(3)
master收到请求,负责复制的IO根据请求信息读取指定的日志,并返回(日志文件的地址也返回,方便下次直接根据地址请求)。
(4)
slave的IO收到信息后,将日志内容依次写入到slave端的relay log文件的最末端,存master日志文件的地址。
(5)
slave的SQL线程检测到Relay
Log中新加内容后,马上解析该Log文件的内容(Query语句),从而能保证两端的数据是一样的。
1.4
基于全局事务标识符复制GTID工作原理
1 gtid的概念
(1)
从MySQL 5.6.5开始新增了一种基于GTID的复制方式。通过GTID保证了每个在主库上提交的事务在集群中有一个唯一的ID。这种方式强化了数据库的主备一致性,故障恢复以及容错能力。
(2)
在原来基于二进制日志的复制中,从库需要告知主库要从哪个偏移量进行增量同步,如果指定错误会造成数据的遗漏,从而造成数据的不一致。
(3) GTID用于在binlog中唯一标识一个事务,当事务提交时,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog。主从同步时GTID_Event和事务的Binlog都会传递到从库,从库在执行的时候也是用同样的GTID写relaylog,这样主从同步以后,就可通过GTID确定从库同步到的位置了。也就是说,无论是级联情况,还是一主多从情况,都可以通过GTID自动找点儿,而无需像之前那样通过File_name和File_position找点儿了。
2 什么是gtid
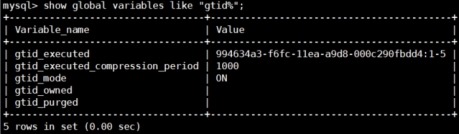
(1) GTID(Global Transaction ID)是对于一个已提交事务的编号,并且是一个全局唯一的编号。GTID实际上是由UUID+TID组成的。其中UUID是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交逐一递增。
(2)
gtid的具体形式为994634a3-f6fc-11ea-a9d8-000c290fbdd4:1,冒号分割前边为mysql服务器的uuid(cat
/usr/local/mysql/data/auto.cnf),后边为TID。
(3)
GTID集合可以包含来自多个MySQL实例的事务,它们之间用逗号分隔。如果来自同一MySQL实例的事务序号有多个范围区间,各组范围之间用冒号分隔。
例如:994634a3-f6fc-11ea-a9d8-000c290fbdd4:1-5:11-18,994634a3-f6fc-11ea-a9d8-000c290fbdd4:1-27
可以使用show master
status实时查看当前事务执行数。
3 gtid的作用
(1)
根据GTID可以知道事务最初是在哪个实例上提交的
1) Gtid采用了新的复制协议,支持以全局统一事务ID (GTID)为基础的复制。
2) 当在主库上提交事务或者被从库应用时,可以定位和追踪每一个事务。
3) GTID复制是全部以事务为基础,使得检查主从一致性变得非常简单。
4) 如果所有主库上提交的事务也同样提交到从库上,一致性就得到了保证。
(2)
GTID的存在方便了Replication的Failover
(3)
相对于传统二进制复制数据安全性更高,故障切换更简单
slave 端配置
gtid_mode = ON # 必选,开启gtid模式
enforce-gtid-consistency = ON #
必选,开启gtid的保护
log-bin = /usr/local/mysql/data/mysql-bin
# 可选,高可用切换,最好开启
log-slave-updates = ON #
可选,高可用切换,最好设置ON
4 gtid的工作原理
|
gtid参数 |
描述 |
|
gtid_executed |
执行过的所有GTID |
|
gtid_purged |
丢弃掉的GTID |
|
gtid_mode |
gtid模式 |
|
gtid_next |
session级别的变量,下一个gtid |
|
gtid_owned |
正在运行的gtid |
|
enforce_gtid_consistency |
保证GTID安全的参数 |


主从在开启GTID模式的情况下,在从节点指定MASTER_AUTO_POSITION=1,START
SLAVE; 时。
(1)
当一个事务在主库端执行并提交时,产生GTID,一同记录到binlog日志中。
(2)
从库会计算Retrieved_Gtid_Set和Executed_Gtid_Set的并集(通过SHOW SLAVE STATUS;可以查看),然后把这个GTID并集发送给主库。
(3)
主库会使用从库请求的GTID集合和自己的Executed_Gtid_Set(通过show
master status;可查看)比较,把从库GTID集合里缺失的事务以binlog的形式全都发送给从库。如果从库缺失的GTID已经被主库pruge了,从库报1236错误,IO线程中断。
(4)
从节点的I/O线程将变更的binlog写入到本地的relay log中。
(5) SQL线程从relay log中获取GTID,然后对比本地gtid_executed是否有记录。
(6)
如果有记录,说明该GTID的事务已经执行,从节点会忽略。
(7)
如果没有记录,从节点就会从relay log中执行该GTID的事务,并记录。
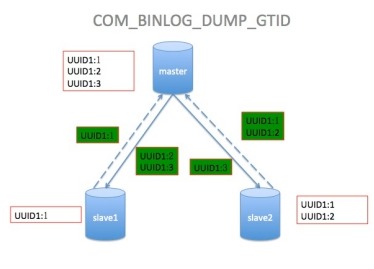
上图表示如下:
slave1 # 将自身的UUID1:1发送给master,然后接收到了UUID1:2,UUID1:3
event
slave2 # 将自身的UUID1:1,UUID1:2发送给master,然后接收到了UUID1:3 event
5 要点
(1)
slave在接受master的binlog时,会校验master的GTID是否已经执行过(一个服务器只能执行一次)。
(2)
为了保证主从数据的一致性,多线程只能同时执行一个GTID。多线程执行在多库复制的情况可用,在单库复制的情况下只能使用一个线程。
6 小结
(1)
全局事务标识符(GTID)是一个唯一的标识符,在5.6版本引入,用于取代基于二进制日志复制的传统方式。
(2) GTID格式:source_id:transaction_id
(3) GTID查看:可通过gtid_executed、gtid_purged和gtid_next系统变量查看。
(4) GTID生成:由gtid_next控制,默认值AUTOMATIC,即每次事务提交自动生成新的GTID。
(5) GTID持久化:GTID存储在binlog文件中。
1.5
mysql二进制复制和mysql
gtid复制的区别
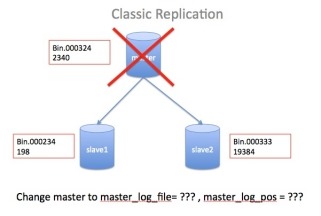
1 基于传统的二进制复制
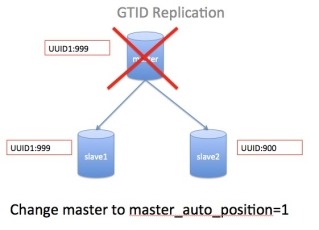
2 gtid复制
3 gtid的局限性
(1)
局限内容
1) 不支持非事务引擎(从库报错,stop slave,start slave;忽略);
2) 不支持create table xxx as
select语句复制(主库直接报错);
3) 不允许一个SQL同时更新一个事务引擎和非事务引擎的表;
4) 在一个复制组中,必须要求统一开启GTID或是关闭GTID;
5) 开启GTID需要重启;
6) 开启GTID后就不在使用原来的传统复制的方式了;
7) 对于create temporary table和drop temporary table语句不支持;
(mysql5.31版本实验没有发现问题)
8) 不支持sal_slave_skip_counter。
(2) create table xxx as select语句限制和解法
1) create table xxx as select的语句,其实会被拆分为两部分,create语句和insert语句,但是如果想一次搞定,MySQL会抛出如下的错误。
mysql> create table test_new as select * from
test;
ERROR 1786 (HY000): Statement violates GTID
consistency: CREATE TABLE ... SELECT.
2) 这种语句其实目标明确,复制表结构,复制数据,insert的部分好解决,难点就在于create table的部分,如果一个表的列有100个,那么拼出这么一个语句来就是一个工程了。除了规规矩矩的拼出建表语句之外,还有一个方法是MySQL特有的用法like。create table xxx as
select的方式可以拆分成两部分,如下。
create table test_new like test;
insert into test_new select * from
test;
(3)
临时表的限制和建议(mysql5.31版本实验没有发现问题)
CREATE TEMPORARY TABLE or DROP TEMPORARY TABLE
statements inside transactions语句。
使用GTID复制模式时,不支持create temporary
table和drop temporary
table。
在autocommit=1的情况下可以创建临时表,Master端创建临时表不产生GTID信息,所以不会同步到slave,但是在删除临时表的时候会产生GTID会导致主从中断。
4 gtid复制和二进制在Replication Failover失败时操作
假设我们有一个如下图的环境此时,Server A的服务器宕机,需要将业务切换到Server B上,同时,我们又需要将Server
C的复制源改成Server
B。
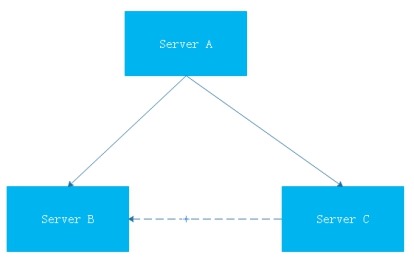
(1)
在MySQL 5.6 GTID出现以前replication
failover的操作过程
复制源修改的命令语法很简单即
CHANGE MASTER TO
MASTER_HOST='xxx',MASTER_LOG_FILE='xxx', MASTER_LOG_POS=<postion>;
而难点在于,由于同一个事务在每台机器上所在的binlog名字和位置都不一样,那么怎么找到ServerC当前同步停止点,对应ServerB的master_log_file和master_log_pos是什么的时候就成为了难题。这也就是为什么M-S复制集群需要使用MMM,MHA这样的额外管理工具的一个重要原因。
(2)
在MySQL
5.6的GTID出现后replication failover的操作过程
操作过程和上面比就显得非常的简单。
由于同一事务的GTID在所有节点上的值一致,那么根据Server C当前停止点的GTID就能唯一定位到ServerB上的GTID。甚至由于MASTER_AUTO_POSITION功能的出现,我们都不需要知道GTID的具体值,直接使用CHANGE MASTER TO
MASTER_HOST='xxx',MASTER_AUTO_POSITION=1;命令就可以直接完成failover的工作。
1.6
mysql /etc/my.cnf文件基础配置
# cat /etc/my.cnf
[client]
port = 3306
default-character-set = utf8
socket =
/usr/local/mysql/data/mysql.sock
[mysql]
no-auto-rehash
[mysqld]
user = mysql
port = 3306
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
socket =
/usr/local/mysql/data/mysql.sock
bind-address = 0.0.0.0
pid-file =
/usr/local/mysql/data/mysqld.pid
character-set-server = utf8
collation-server = utf8_general_ci
log-error =
/usr/local/mysql/data/mysqld.log
slow_query_log = ON
long_query_time = 2
slow_query_log_file =
/usr/local/mysql/data/mysql-slow.log
max_connections = 10240
open_files_limit = 65535
innodb_buffer_pool_size = 1G
innodb_flush_log_at_trx_commit = 2
innodb_log_file_size = 256M
transaction_isolation =
READ-COMMITTE
default-storage-engine = innodb
innodb_file_per_table = on
symbolic-links = 0
explicit_defaults_for_timestamp = 1
skip-name-resolve
lower_case_table_names = 1
server-id = 1
[mysqldump]
quick
max_allowed_packet = 32M
2 基于二进制日志位置复制
2.1 初始配置时增加从服务器
1 master配置
在172.16.1.151节点上进行操作
(1)
修改my.cnf
文件添加如下内容
# vim /etc/my.cnf
[mysqld]
server-id = 1
log-bin =
/usr/local/mysql/data/mysql-bin
binlog_cache_size = 4M
binlog_format = mixed
max_binlog_cache_size = 8M
max_binlog_size = 512M
expire_logs_days = 14
(2)
重启mysql
服务
# systemctl restart mysqld
(3)
登录mysql
# mysql -uroot -p"mysql5.7@2021"
(4)
获取master二进制文件和位置
mysql> show master status;

(5) 创建复制账户
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'
IDENTIFIED BY 'repl@2020';
mysql> flush privileges;
2 slave配置
在172.16.1.152节点上进行操作
(1) 修改my.cnf文件添加如下内容
# vim /etc/my.cnf
[mysqld]
server-id = 2
slave-skip-errors=1007,1022,1050,1062,1169
relay-log=/usr/local/mysql/data/relay-log
max_relay_log_size=512M
relay-log-purge=ON
read-only
(2)
重启mysql服务
# systemctl restart mysqld
(3)
登录mysql
# mysql -uroot -p"mysql5.7@2022"
我这里slvae节点和master节点的root密码不一致,实际操作中最好保持一致,这样主从mysql服务器的数据就完全一致了。
(4)
配置复制连接
mysql> CHANGE MASTER TO
MASTER_HOST='172.16.1.151',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl@2020',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=154;
(5)
启动线程
mysql> start slave;
(6)
查看复制状态
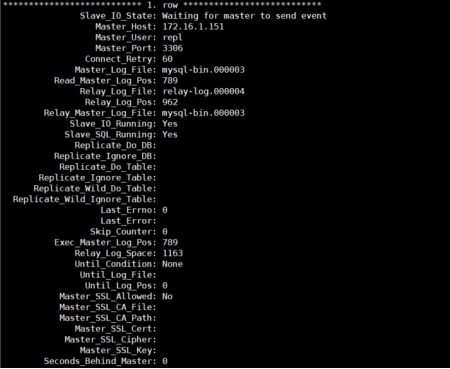
mysql> show slave status\G;
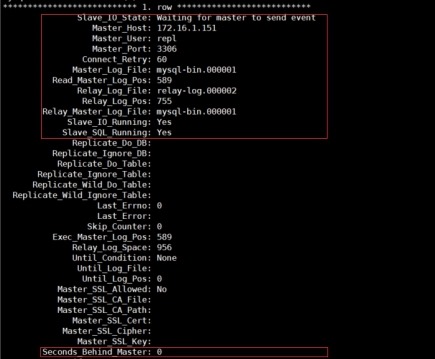
2.2 在线增加从服务器
1 master配置
在172.16.1.151节点上进行操作
(1) 修改my.cnf文件添加如下内容
# vim /etc/my.cnf
[mysqld]
server-id = 1
log-bin =
/usr/local/mysql/data/mysql-bin
binlog_cache_size = 4M
binlog_format = mixed
max_binlog_cache_size = 8M
max_binlog_size = 512M
expire_logs_days = 14
(2) 重启mysql服务
# systemctl restart mysqld
(3)
备份数据库
# mysqldump -uroot -p'mysql5.7@2021' -A -F -R --single-transaction --master-data=1
--events --hex-blob --triggers --flush-privileges | gzip > /tmp/`date
+%F_%H-%M-%S`.sql.bak.gz
##################备份参数说明##################
# 普通备份参数:
# -R: 转储存储的例程(功能和过程);
# -E: --events:转储事件;
# -A: 转储所有数据库,
这将与--databases以及所有已选择的数据库相同;
# -B: 转储多个数据库,增加建库语句和use连接库的语句;
# --hex-blob: 转储十六进制格式的二进制字符串(BINARY,VARBINARY,BLOB);
# --triggers: 为每个转储的表转储触发器;
# --flush-privileges: 转储mysql数据库后,发出FLUSH PRIVILEGES语句;
# --single-transaction: 设置事务的隔离级别为可重复读(REPEATABLE
READ),用于热备,只适用于MySQL
InnoDB引擎。这样能保证在一个事务中所有相同的查询读取到同样的数据,也就大概保证了在dump期间,如果其他innodb引擎的线程修改了表的数据并提交,对该dump线程的数据并无影响,在这期间不会锁表。
# 用于MySQL开启binlog时的参数:
# -F: 开始转储之前刷新服务器中的日志文件;
# --master-data=1: 备份中增加binlog日志文件名及对应的位置点,1不加注释,2加注释;如下(记录-F刷新后binlog日志位置点)
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000016',
MASTER_LOG_POS=154;
# -d:没有行信息,只备份表结构,不备份表数据; Usage: -d <数据库>
<表名称,多个表名称可用空格隔开>
# -t:不要写表创建信息,只备份表数据,不备份表结构;Usage: -t
<数据库> <表名称,多个表名称可用空格隔开>
################################################
(4)
拷贝主库备份到从库服务器(172.16.1.152)上
# scp -rp /tmp/2020-09-21_16-04-26.sql.bak.gz
root@172.16.1.152:/tmp/
(5) 创建复制的账号
# mysql -uroot -p"mysql5.7@2021"
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'
IDENTIFIED BY 'repl@2020';
mysql> flush privileges;
2 slave配置
在172.16.1.152节点上进行操作
(1) 修改my.cnf文件添加如下内容
# vim /etc/my.cnf
[mysqld]
server-id = 2
slave-skip-errors=1007,1022,1050,1062,1169
relay-log=/usr/local/mysql/data/relay-log
max_relay_log_size=512M
relay-log-purge=ON
read-only
(2)
重启数据库
# systemctl restart mysqld
(3)
还原备份的主库
# gzip -d
/tmp/2020-09-21_16-04-26.sql.bak.gz
# mysql -uroot -p'mysql5.7@2022' <
/tmp/2020-09-21_16-04-26.sql.bak
(4)
登录mysql
此时root
密码发生了改变,变成了master的root 密码"mysql5.7@2021"
# mysql -uroot -p"mysql5.7@2021"
(5)
配置复制连接
执行CHANG MASTER语句, 不需要MASTER_LOG_FILE文件和MASTER_LOG_POS配置位置点,因为
在备份主库时
--master-data=1
参数已经记录了下来。
mysql> CHANGE MASTER TO
MASTER_HOST='172.16.1.151',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl@2020';
(6)
开启从库
mysql> start slave;
(7)
查看从库状态
mysql> show slave status/G;
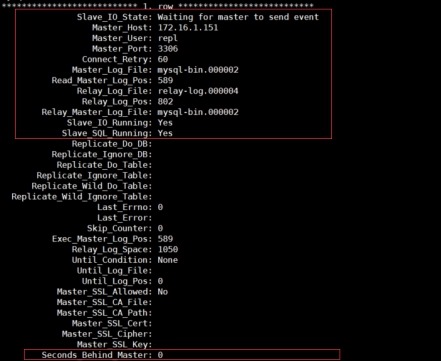
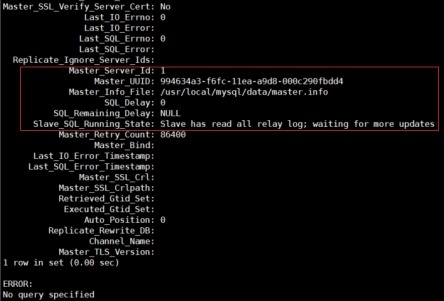
3 基于全局事务标识符GTID复制
3.1 初始配置时增加从服务器
1 master配置
在172.16.1.151节点上进行操作
(1) 修改my.cnf文件添加如下内容
# vim /etc/my.cnf
[mysqld]
server-id = 1
log-bin =
/usr/local/mysql/data/mysql-bin
binlog_cache_size = 4M
binlog_format = mixed
max_binlog_cache_size = 8M
max_binlog_size = 512M
expire_logs_days = 14
gtid_mode = ON
enforce_gtid_consistency = ON
(2) 重启mysql服务
# systemctl restart mysqld
(3) 登录mysql
# mysql -uroot -p"mysql5.7@2021"
(4) 创建复制账户
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'
IDENTIFIED BY 'repl@2020';
mysql> flush privileges;
(5)
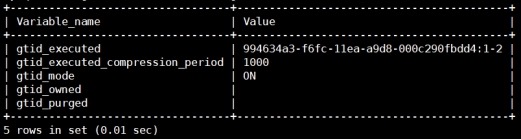
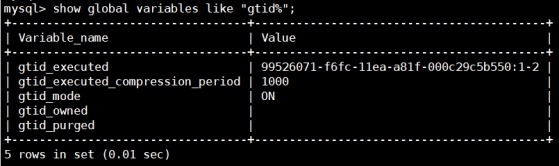
查看gtid
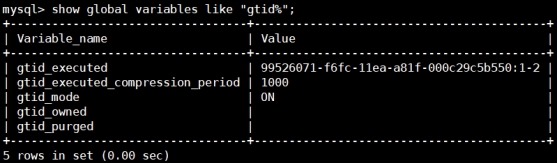
mysql> show global variables like
"gtid%";
2 slave配置
在172.16.1.152节点上进行操作
(1) 修改my.cnf文件添加如下内容
# vim /etc/my.cnf
[mysqld]
server-id = 2
slave-skip-errors=1007,1022,1050,1062,1169
relay-log=/usr/local/mysql/data/relay-log
max_relay_log_size=512M
relay-log-purge=ON
read-only
gtid_mode = ON
enforce_gtid_consistency = ON
(2) 重启mysql服务
# systemctl restart mysqld
(3) 登录mysql
# mysql -uroot -p"mysql5.7@2022"
我这里slvae节点和master节点的root密码不一致,实际操作中最好保持一致,这样主从mysql服务器的数据就完全一致了。
(4) 配置复制连接
mysql> CHANGE MASTER TO
MASTER_HOST='172.16.1.151',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl@2020',
MASTER_AUTO_POSITION=1;
(5) 启动线程
mysql> start slave;
(6) 查看复制状态
mysql> show slave status\G;
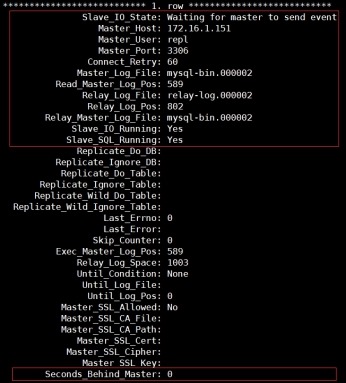
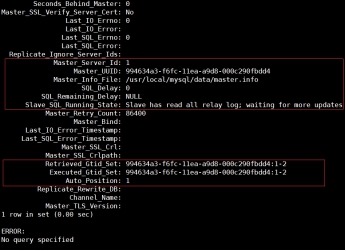
3 查看gtid值
(1) master节点
1) 查看slave节点信息
mysql> show slave hosts;

2) 查看线程信息
mysql> show processlist;

3) 查看gtid信息
mysql> show master status;

mysql> show global variables like
"gtid%";
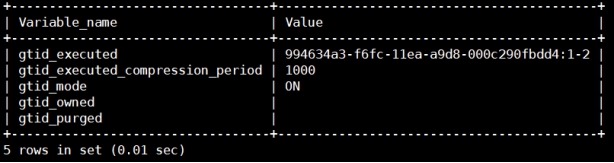
(2) slave节点
1) 查看线程信息
mysql> show processlist;

2) 查看gtid信息
mysql> show slave status\G;

mysql> show global variables like
"gtid%";
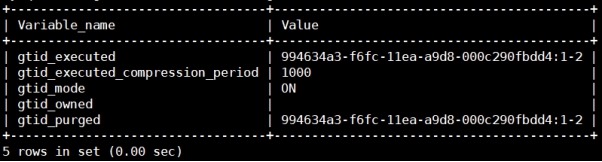
3.2 在线增加从服务器
1 master配置
在172.16.1.151节点上进行操作
(1) 修改my.cnf文件添加如下内容
# vim /etc/my.cnf
[mysqld]
server-id = 1
log-bin =
/usr/local/mysql/data/mysql-bin
binlog_cache_size = 4M
binlog_format = mixed
max_binlog_cache_size = 8M
max_binlog_size = 512M
expire_logs_days = 14
gtid_mode = ON
enforce_gtid_consistency = ON
(2) 重启mysql服务
# systemctl restart mysqld
(3) 登录mysql
# mysql -uroot -p"mysql5.7@2021"
(4) 创建复制账户
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'
IDENTIFIED BY 'repl@2020';
mysql> flush privileges;
(5) 查看gtid
mysql> show global variables like
"gtid%";
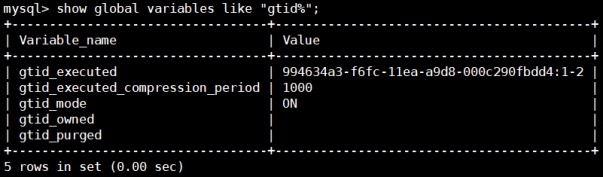
(6) 备份数据库
# mysqldump -uroot -p'mysql5.7@2021' -A -F -R
--single-transaction --master-data=2 --events --hex-blob --triggers
--flush-privileges | gzip > /tmp/`date
+%F_%H-%M-%S`.sql.bak.gz
# ls -l /tmp
-rw-r--r-- 1 root root 189389 Sep 26 21:47
2020-09-26_21-47-09.sql.bak.gz
(7)
拷贝主库备份到从库服务器(172.16.1.152)上
# scp -rp /tmp/2020-09-26_21-47-09.sql.bak.gz root@172.16.1.152:/tmp/
2 slave配置
在172.16.1.152节点上进行操作
(1) 修改my.cnf文件添加如下内容
# vim /etc/my.cnf
[mysqld]
server-id = 2
slave-skip-errors=1007,1022,1050,1062,1169
relay-log=/usr/local/mysql/data/relay-log
max_relay_log_size=512M
relay-log-purge=ON
read-only
gtid_mode = ON
enforce_gtid_consistency = ON
(2) 重启mysql服务
# systemctl restart mysqld
(3) 还原备份的主库
# gzip -d /tmp/2020-09-26_21-47-09.sql.bak.gz
# mysql -uroot -p'mysql5.7@2022'
< /tmp/2020-09-26_21-47-09.sql.bak
说明:
1) 主库备份的sql文件中包含了主库已经执行过的gtid事务
# head -32
/tmp/2020-09-26_21-47-09.sql.bak
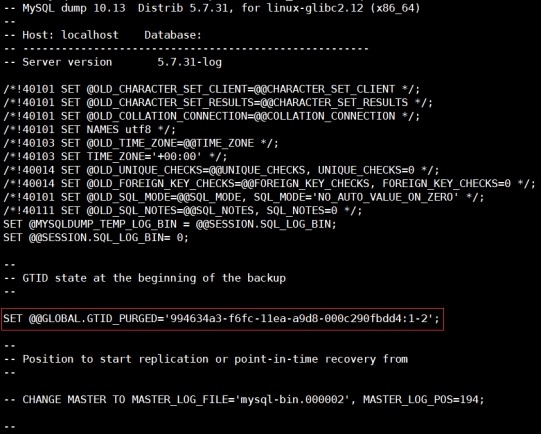
(4) 登录mysql
此时root
密码发生了改变,变成了master的root 密码"mysql5.7@2021"
# mysql -uroot -p"mysql5.7@2021"
查看gtid值
# mysql> show global variables like
"gtid%";
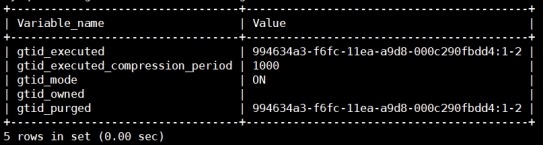
(5) 配置复制连接
mysql> CHANGE MASTER TO
MASTER_HOST='172.16.1.151',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl@2020',
MASTER_AUTO_POSITION=1;
(6) 开启从库
mysql> start slave;
(7) 查看从库状态
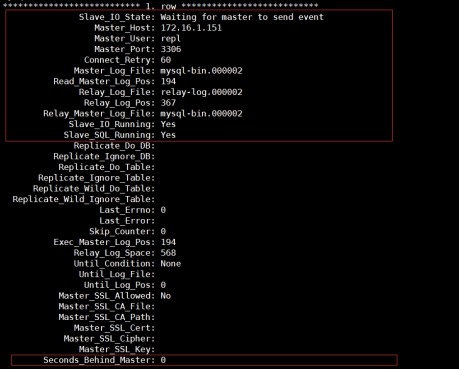
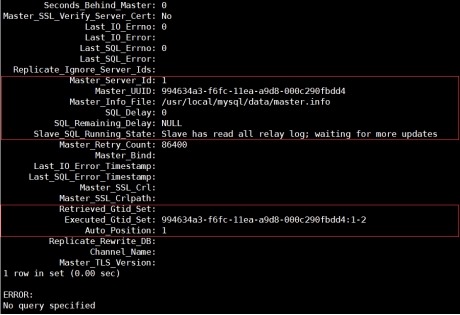
3.3 半同步复制
在"3.2在线增加从服务器"的基础上进行操作
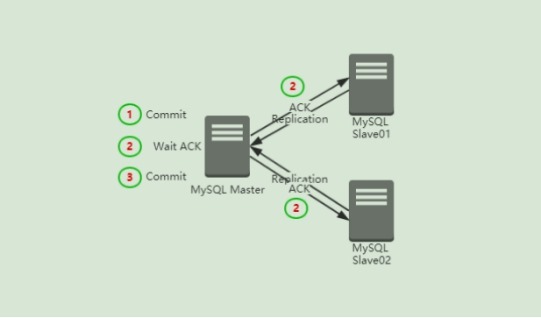
(1) master会等到binlog成功传送并写入至少一个slave的relay log之后才会提交,否则一直等待,直到timeout(默认10s)。
(2) 当出现timeout的时候,master会自动切换半同步为异步,直到至少有一个slave成功收到并发送Acknowledge,master会再切换回半同步模式。结合这个新功能,我们可以做到,在允许损失一定的事务吞吐量的前提下来保证同步数据的绝对安全,因为当你设置timeout为一个足够大的值的情况下,任何提交的数据都会安全抵达slave。
查找mysql插件目录位置
# mysql> show variables like
'plugin_dir';
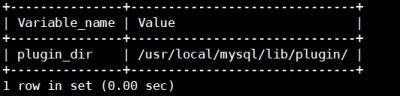
# ll /usr/local/mysql/lib/plugin/|grep
"semisync"

1 master配置
在172.16.1.151节点上进行操作
(1)
加载半同步插件
mysql> install plugin rpl_semi_sync_master soname
'semisync_master.so';
(2)
查看是否加载插件
# mysql> show plugins;

(3) 启动半同步插件
# mysql> set global rpl_semi_sync_master_enabled
= on;
该方法mysql重后失效,需要把如下参数放入到my.cnf文件中,这样mysql重启后mysql
半同步插件也是开启的。
# vim /etc/my.cnf
[mysqld]
rpl_semi_sync_master_enabled = on
2 slave配置
在172.16.1.152节点上进行操作
(1) 加载半同步插件
mysql> install plugin rpl_semi_sync_slave soname
'semisync_slave.so';
(2) 查看是否加载插件
# mysql> show plugins;

(3) 启动半同步插件
注意:slave要重启动IO线程,否则还是异步的方式同步数据。
mysql> set global rpl_semi_sync_slave_enabled = on;
mysql> stop slave IO_THREAD;
mysql> start slave IO_THREAD;
该方法mysql重后失效,需要把如下参数放入到my.cnf文件中,这样mysql重启后mysql
半同步插件也是开启的。
# vim /etc/my.cnf
[mysqld]
rpl_semi_sync_slave_enabled = on
3 半同步几个参数设置
(1)
主库
# mysql> show global status like
'Rpl_semi_sync%';
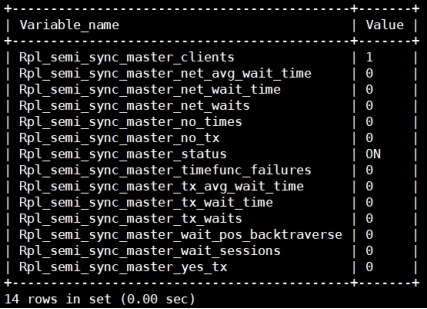
Rpl_semi_sync_master_clients # 半同步模式下Slave一共有多少个。
Rpl_semi_sync_master_no_tx #
往slave发送失败的事务数量。
Rpl_semi_sync_master_status #
是否启用了半同步。
Rpl_semi_sync_master_yes_tx #
往slave发送成功的事务数量。
# mysql> show global variables like
'rpl_semi_sync%';
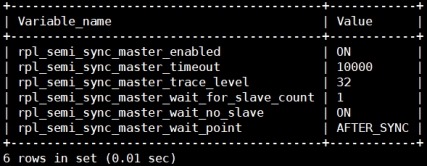
rpl_semi_sync_master_timeout
# Master等待slave响应的时间,单位是毫秒,默认值是10秒,超过这个时间,slave无响应,环境架构将自动转换为异步复制。
rpl_semi_sync_master_trace_level
# 监控等级,一共4个等级(1,16,32,64)。
rpl_semi_sync_master_wait_no_slave
# 是否允许master每个事物提交后都要等待slave的receipt信号,默认为on,每一个事务都会等待,如果slave当掉后,当slave追赶上master的日志时,可以自动的切换为半同步方式,如果为off,则slave追赶上后,也不会采用半同步的方式复制了,需要手工配置。
(2)
从库
# mysql> show global status like
'Rpl_semi_sync%';
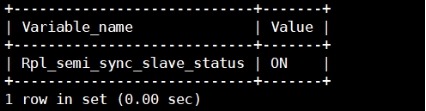
Rpl_semi_sync_slave_status # 是否启用了半同步。
4 数据库复制延迟说明
(1)
在理想的情况下,数据库硬件性能好、数据库、表结构设计合理、SQL语句优化得好。在这样的情况下应该不会有什么延时问题。但事实上公司里数据库的设计、表的设计、SQL语句等都是一个问题。正因为这些问题导致了再厉害的半同步复制都无法解决主从数据延时的问题。
(2)
大部分的数据延时都是因为主库上的SQL执行时间过长,导致在从库也是执行时间长,这样产生的两个时间差赶不上客户在前端应用刷新数据的速度,就会产生刚更新的内容,一刷新居然却没有发生改变。所以最大的问题就是在SQL语句和表、数据库的设计上优化。
3.4 过滤复制
在"3.2在线增加从服务器"的基础上进行操作
5.7.3版本开始支持CHANGE REPLICATION FILTER语句设置从站一个或多个复制过滤规则,动态生效,但需要先停止从站SQL线程,之后再启动SQL线程。
以下配置参数写入到my.cnf中使用上划线"-",动态改变配置参数时使用下划线"_"。
|
replicate-do-db |
复制指定数据库 |
|
replicate-ignore-db |
|
|
replicate-do-table |
|
|
replicate-wild-do-table |
通配符匹配复制表 |
1 slave配置
在172.16.1.152节点上进行操作
实验库表
mysql> create database test;
mysql> use test;
mysql> create table user(name
varchar(50));
mysql> create table info(age
int);
mysql> create database test1;
mysql> use test1;
mysql> create table student(name
varchar(50));
(1)
复制指定数据库
mysql> stop slave sql_thread;
mysql> CHANGE REPLICATION FILTER
replicate_do_db=(test);
mysql> start slave sql_thread;
mysql> show slave status\G;
(2)
不复制指定数据库
mysql> stop slave sql_thread;
mysql> CHANGE REPLICATION FILTER
replicate_ignore_db=(test);
mysql> start slave sql_thread;
mysql> show slave status\G;
(3)
复制指定表
mysql> stop slave sql_thread;
mysql> CHANGE REPLICATION FILTER
replicate_do_table=(test.user);
mysql> start slave sql_thread;
mysql> show slave status\G;
(4)
不复制指定表
mysql> stop slave sql_thread;
mysql> CHANGE REPLICATION FILTER
replicate_ignore_table=(test.user);
mysql> start slave sql_thread;
mysql> show slave status\G;
(5)
通配符匹配复制表
mysql> stop slave sql_thread;
mysql> CHANGE REPLICATION FILTER
replicate_wild_do_table=('test.u%');
mysql> start slave sql_thread;
mysql> show slave status\G;
(6)
通配符匹配不复制表
mysql> stop slave sql_thread;
mysql> CHANGE REPLICATION FILTER
replicate_wild_ignore_table=('test.u%');
mysql> start slave sql_thread;
mysql> show slave status\G;
(7)
小结
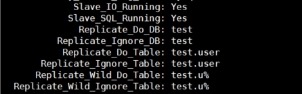
1) 清空复制的方法
mysql> CHANGE REPLICATION FILTER
replicate_do_db=(<不添加要过滤的库>);。
2) 在my.cnf中添加过滤规则
replicate-do-db = test
replicate-wild-ignore-table =
test.u%
3) 过滤的库或表限制和开放规则最好不要冲突。
4) 在从库上先过滤主库上不存在的表或库也是可以的。
5) 如果不允许一个库或表复制,从库上也不存在该库或表,后面又允许该库或表复制,那么复制会停止,报不存在该库或表的错误。
3.5 多源复制
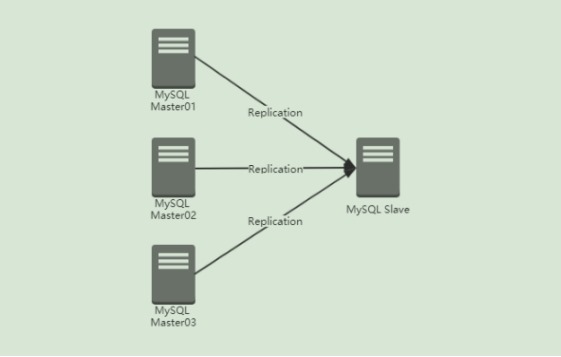
mysql5.7版本引入多源复制,多源复制使得从服务器能够同时从多个源接收事务。
多源复制可用于将多个服务器备份到单个服务器。
在多源复制拓扑中,从服务器为每个主节点创建接收事务的复制通道。
多源复制拓扑中的从服务器需要基于TABLE(mysql.slave_master_info)存储,与FILE(/usr/local/mysql/data/master.info)存储不兼容。
1 master01配置
在172.16.1.151节点上进行操作
(1) 修改my.cnf
# vim /etc/my.cnf
[mysqld]
server-id = 1
log-bin =
/usr/local/mysql/data/mysql-bin
binlog_cache_size = 4M
binlog_format = mixed
max_binlog_cache_size = 8M
max_binlog_size = 512M
expire_logs_days = 14
gtid_mode = ON
enforce_gtid_consistency = ON
(2) 重启mysql
# systemctl restart mysqld
(3) 登录mysql
# mysql -uroot -pmysql5.7@2021
(4) 创建复制账号
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'
IDENTIFIED BY 'repl@2020';
mysql> flush privileges;

2 master02配置
在172.16.1.152节点上进行操作
(1) 修改my.cnf
# vim /etc/my.cnf
[mysqld]
server-id = 2
log-bin =
/usr/local/mysql/data/mysql-bin
binlog_cache_size = 4M
binlog_format = mixed
max_binlog_cache_size = 8M
max_binlog_size = 512M
expire_logs_days = 14
gtid_mode = ON
enforce_gtid_consistency = ON
(2) 重启mysql
# systemctl restart mysqld
(3) 登录mysql
# mysql -uroot -pmysql5.7@2022
(4) 创建复制账号
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'
IDENTIFIED BY 'repl@2020';
mysql> flush privileges;
2 slave配置
在172.16.1.153节点上进行操作
(1) 修改my.cnf文件添加如下内容
# vim /etc/my.cnf
[mysqld]
server-id = 3
slave-skip-errors =
1007,1022,1050,1062,1169
relay-log =
/usr/local/mysql/data/relay-log
max_relay_log_size = 512M
relay-log-purge = ON
read-only
gtid_mode = ON
enforce_gtid_consistency = ON
master-info-repository = TABLE
relay-log-info-repository = TABLE
提示:也可以运行时动态修改
mysql> SET GLOBAL
master_info_repository='TABLE';
mysql> SET GLOBAL
relay_log_info_repository='TABLE';
(2) 重启mysql服务
# systemctl restart mysqld
(3) 登录mysql
# mysql -uroot -pmysql5.7@2023
(4)
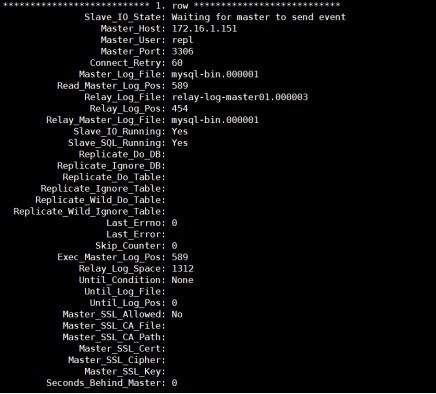
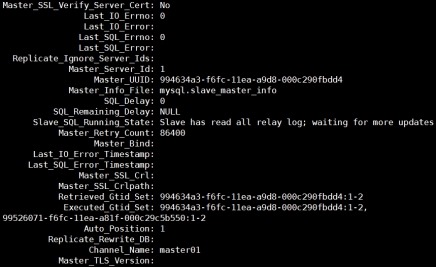
配置复制连接,连接master01
1) 配置连接
mysql> CHANGE MASTER TO
MASTER_HOST='172.16.1.151',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl@2020',
MASTER_AUTO_POSITION=1 FOR CHANNEL
'master01';
2) 指定启动master01通道
mysql> START SLAVE FOR CHANNEL
'master01';
3) 查看slave状态
mysql> show slave status\G;
(5) 配置复制连接,连接master02
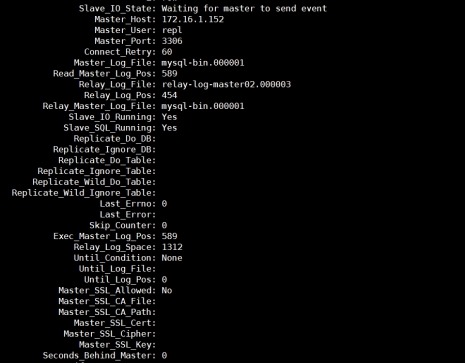
1) 配置连接
mysql> CHANGE MASTER TO
MASTER_HOST='172.16.1.152',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl@2020',
MASTER_AUTO_POSITION=1 FOR CHANNEL
'master02';
2) 指定启动master02通道
mysql> START SLAVE FOR CHANNEL
'master02';
3) 查看slave状态
mysql> show slave status\G;
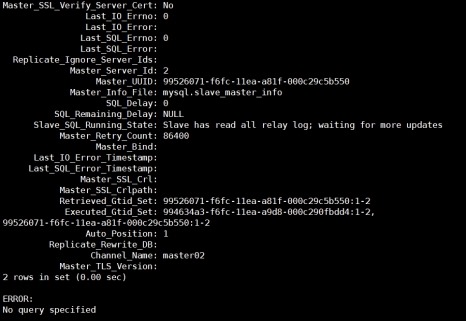
(6)
查看slave gtid
mysql> show global variables like
"gtid%";
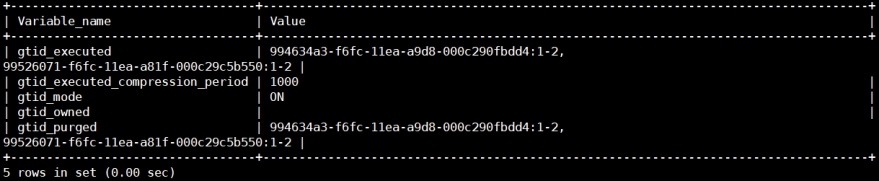
(7)
补充
slave线程名称:thread_types = io_thread、sql_thread
启动命名通道线程:START
SLAVE <thread_types>
FOR CHANNEL '<通道名称>';
启动指定通道:START
SLAVE FOR CHANNEL '<通道名称>';
3.6 多线程复制
在"3.2在线增加从服务器"的基础上进行操作
5.7引入了新的变量slave_parallel_type,值有DATABASE(默认值,基于库的并行复制方式),LOGICAL_CLOCK(基于组提交的并行复制方式)。
基于组提交的并行复制原理为,一个组提交的事务都是可以并行回放,因为这些事务都已进入到事务的prepare(准备)阶段,则说明事务之间没有任何冲突,否则就不可能提交。
使用并行复制可以解决从库的延迟问题。
1 slave配置
在172.16.1.152节点上进行操作
(1)
运行时设置
mysql> stop slave SQL_THREAD;
mysql> set global
slave_parallel_workers=8;
mysql> set global
slave_parallel_type="LOGICAL_CLOCK";
mysql> start slave SQL_THREAD;
(2)
启动添加选项
[mysqld]
slave-parallel-type = LOGICAL_CLOCK
slave-parallel-workers = 8
(3)
slave增加多线程前后对比
1) slave没有增加多线程的线程列表
mysql> show processlist;

1) slave增加多线程的线程列表
mysql> show global variables like
'slave_parallel%';

mysql> show processlist;
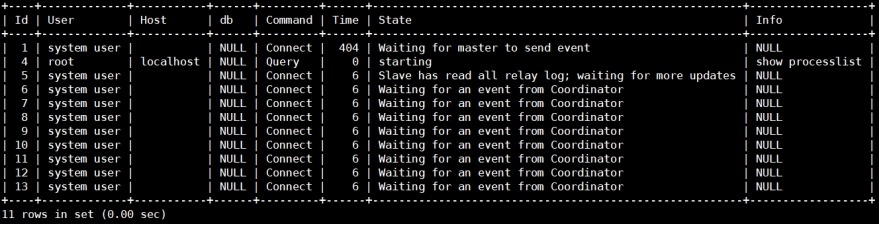
可以发现相较于"slave没有增加多线程的线程列表","slave增加多线程的线程列表"多了8个"Waiting
for an event from Coordinator"线程。
3.7 主主复制
1 master配置
在172.16.1.151节点上进行操作
(1)
修改my.cnf
# vim /etc/my.cnf
[mysqld]
server-id = 1
slave-skip-errors =
1007,1022,1050,1062,1169
relay-log =
/usr/local/mysql/data/relay-log
max_relay_log_size = 512M
relay-log-purge = ON
log-bin =
/usr/local/mysql/data/mysql-bin
binlog_cache_size = 4M
binlog_format = mixed
max_binlog_cache_size = 8M
max_binlog_size = 512M
expire_logs_days = 14
gtid_mode = ON
enforce_gtid_consistency = ON
log-slave-updates
auto_increment_increment = 2
auto_increment_offset = 1
(2)
重启mysql
# systemctl restart mysqld
(3)
登录mysql
# mysql -uroot -pmysql5.7@2021
(4) 创建复制账号
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'
IDENTIFIED BY 'repl@2020';
mysql> flush privileges;
2 slave配置
在172.16.1.152节点上进行操作
(1) 修改my.cnf
# vim /etc/my.cnf
[mysqld]
server-id = 2
slave-skip-errors =
1007,1022,1050,1062,1169
relay-log =
/usr/local/mysql/data/relay-log
max_relay_log_size = 512M
relay-log-purge = ON
log-bin =
/usr/local/mysql/data/mysql-bin
binlog_cache_size = 4M
binlog_format = mixed
max_binlog_cache_size = 8M
max_binlog_size = 512M
expire_logs_days = 14
gtid_mode = ON
enforce_gtid_consistency = ON
log-slave-updates
auto_increment_increment = 2
auto_increment_offset = 2
(2) 重启mysql
# systemctl restart mysqld
(3) 登录mysql
# mysql -uroot -pmysql5.7@2022
# root密码最好和主保持一致,我这里就不一致了
(4) 创建复制账号
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'
IDENTIFIED BY 'repl@2020';
mysql> flush privileges;
3 双主连接配置
(1) master配置
在172.16.1.151节点上进行操作
1) 配置复制连接
mysql> CHANGE MASTER TO
MASTER_HOST='172.16.1.152',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl@2020',
MASTER_AUTO_POSITION=1;
2) 启动slave
mysql> start slave;
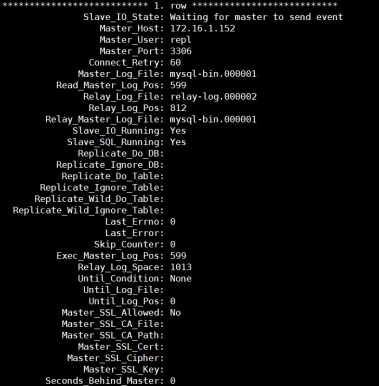
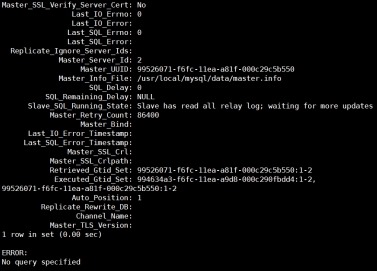
3) 查看slave状态
mysql> show slave status\G;
(2)
slave配置
在172.16.1.152节点上进行操作
1) 配置复制连接
mysql> CHANGE MASTER TO
MASTER_HOST='172.16.1.151',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl@2020',
MASTER_AUTO_POSITION=1;
2) 启动slave
mysql> start
slave;
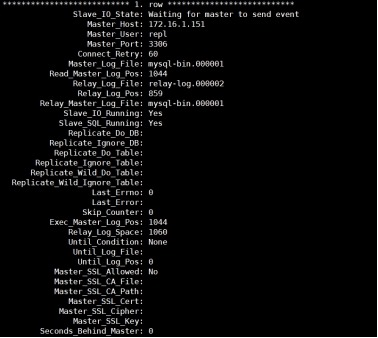
3) 查看slave状态
mysql> show slave status\G;
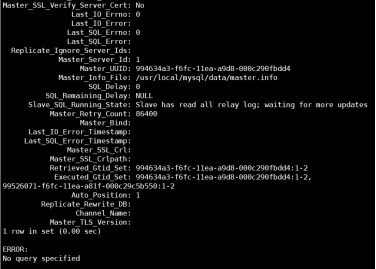
4 mysql双主配置参数说明
log-slave-updates
# 将更新的relaylog日志写入到binlog日志中,方便主服务器为其它从服务器做主从同步。
auto_increment_increment = 2
auto_increment_offset = 1
# 以上两行是解决双主复制主键冲突的问题,第一行表示自动增量值,第二行表示自动增量偏移值(两个mysql服务器设置分别为1和2)。
5 测试
(1)
在mysql01上创建test库、user表,并在user表中插入数据
mysql> create database test;
mysql> use test;
mysql> create table user(id int AUTO_INCREMENT
primary key,name varchar(50));
mysql> insert into user(name)
values("zhangsan");
mysql> insert into user(name)
values("lisi");
(2)
在mysql02上,test库下的user表中插入数据
mysql> use test;
mysql> insert into user(name)
values("wanger");
mysql> insert into user(name)
values("mazi");
(3)
在mysql01或mysql02上查看test库下的user表
mysql> select * from user;

(4)
查看gtid
1) mysql> show global variables like
"gtid%";
mysql01:

mysql02:

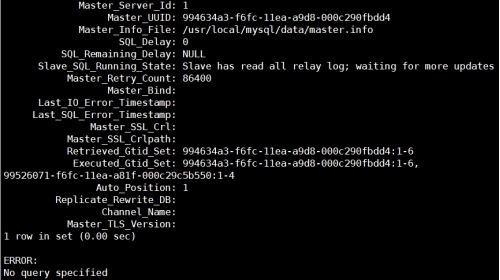
2) mysql> show slave status\G;
mysql01:
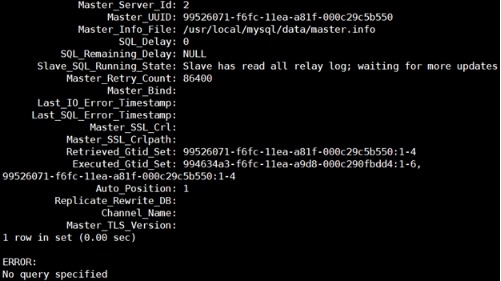
mysql02:
3.8 复制常见问题
在"3.2在线增加从服务器"的基础上进行操作
1 在slave中配置跳过主从复制错误的参数
在172.16.1.152节点上进行操作
# vim /etc/my.cnf
[mysqld]
slave-skip-errors = 1007,1022,1050,1062,1169
参数说明:
1007 # 数据库已存在,创建数据库失败
1022 # 关键字重复,更改记录失败
1050 # 数据表已存在
1062 # 字段值重复,入库失败
1169 # 字段值重复,更新记录失败
(1)
实验:从节点数据表已存在
1) master配置,在172.16.1.151节点上进行操作
mysql> create database test;
mysql> use test;
2) slave配置,在172.16.1.152节点上进行操作
mysql> use test;
mysql> create table user(name
varchar(50));
3) master配置,在172.16.1.151节点上进行操作
mysql> create table user(name
varchar(50));
# 从节点会跳过该操作的gtid
mysql> create table user2(name
varchar(50));
mysql> create table user3(name
varchar(50));
4) 查看slave状态
mysql> show slave status\G;
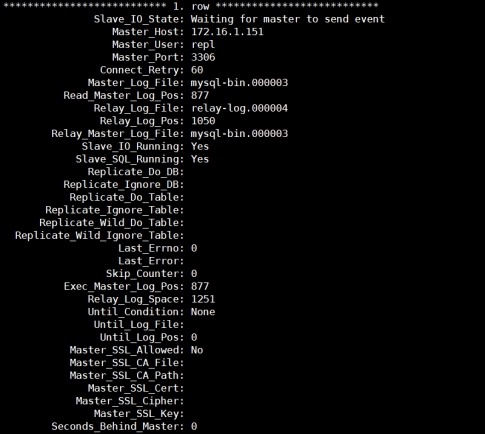
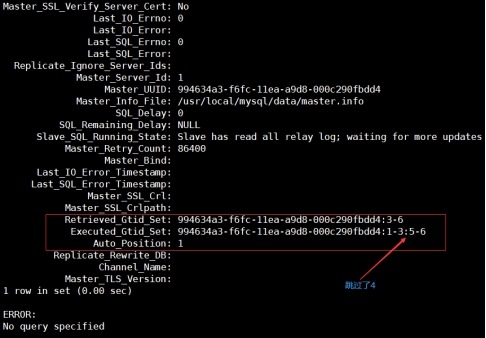
5) 查看gtid变量
master
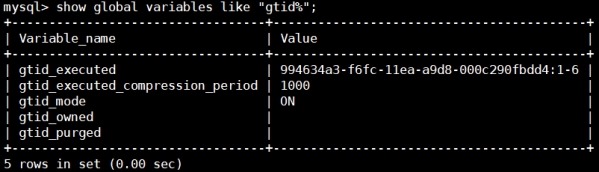
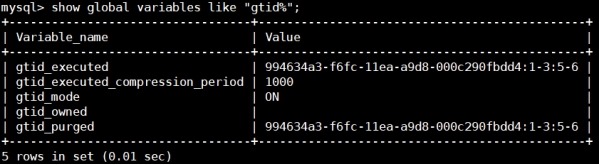
slave
2 没有在slave中配置跳过主从复制错误的参数
(1) 实验:从节点数据表已存在
1) master配置,在172.16.1.151节点上进行操作
mysql> create database test;
mysql> use test;
2) slave配置,在172.16.1.152节点上进行操作
mysql> use test;
mysql> create table user(name
varchar(50));
3) master配置,在172.16.1.151节点上进行操作
mysql> create table user(name
varchar(50));
# 从节点在此操作后会停止SQL线程
mysql> create table user2(name
varchar(50));
mysql> create table user3(name
varchar(50));
4) 查看slave状态
mysql> show slave status\G;
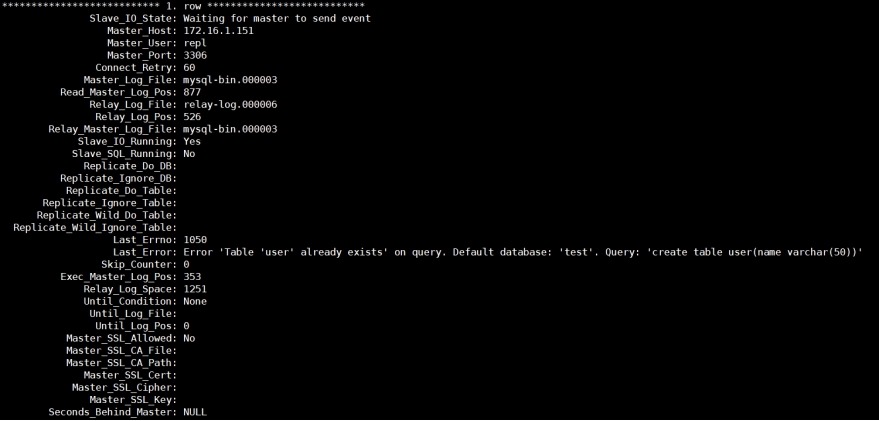
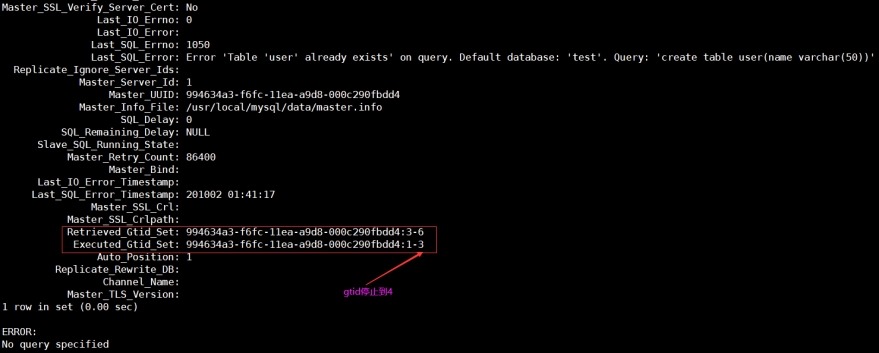
5)查看gtid变量
master
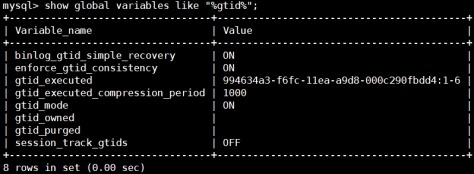
slave
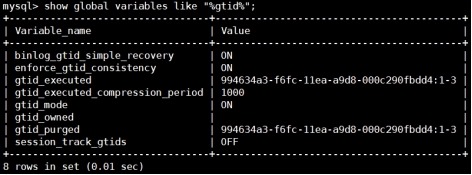
(2)
解决方法
slave配置,在172.16.1.152节点上操作
1) 关闭slave线程
mysql> stop slave;
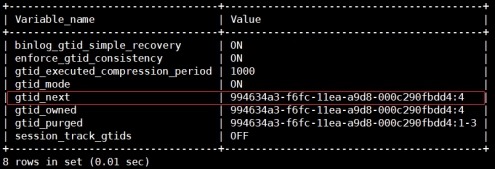
2) 设置gtid_next变量值,跳过冲突的事务
查看gtid_next默认变量值
mysql> show variables like
"%gtid%";
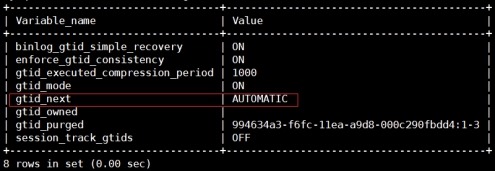
设置gtid_next变量值从4开始(跳过该事务)
mysql> set session
gtid_next='994634a3-f6fc-11ea-a9d8-000c290fbdd4:4';
查看gtid_next变量值
mysql> show variables like
"%gtid%";
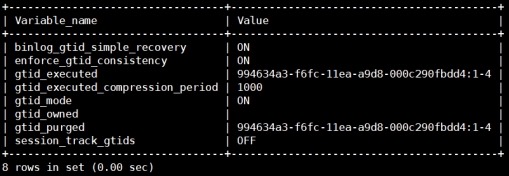
3) 提交事务,生效gtid_executed变量值
mysql> begin;commit;
mysql> show global variables like "%gtid%";
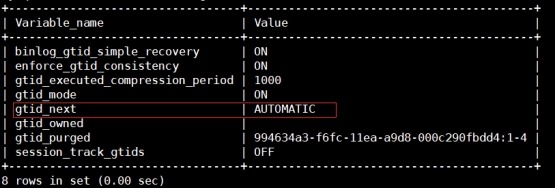
4) 设置gtid_next变量值为默认值AUTOMATIC
mysql> set session gtid_next='AUTOMATIC';
查看gtid_next变量值
mysql> show variables like
"%gtid%";
5) 启动slave
mysql> start slave;
6) 查看slave状态
mysql> show slave status\G;
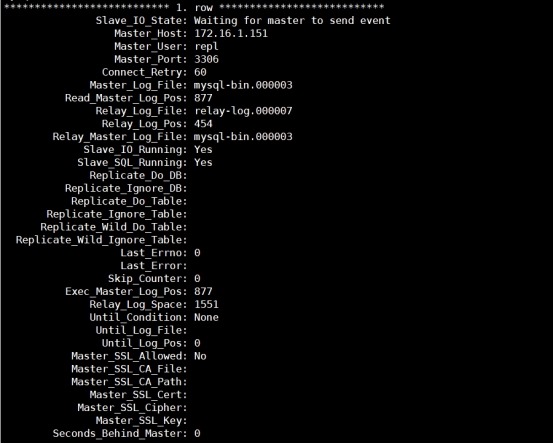
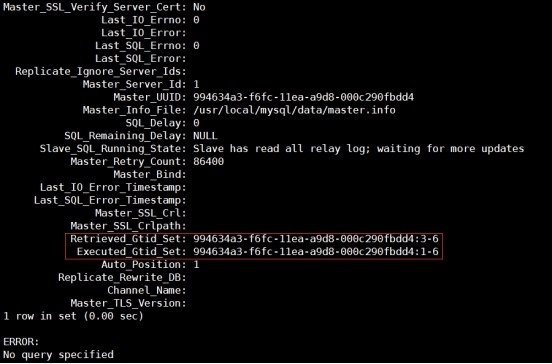
7) 查看gtid变量
master
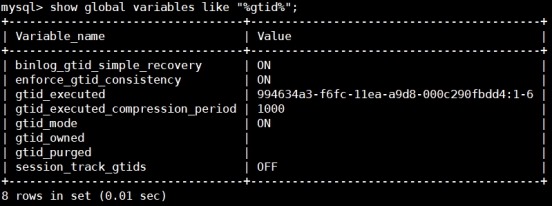
slave
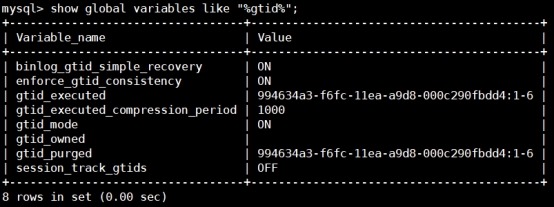
4 复制解决方案
4.1
一主一从
4.2
主主复制
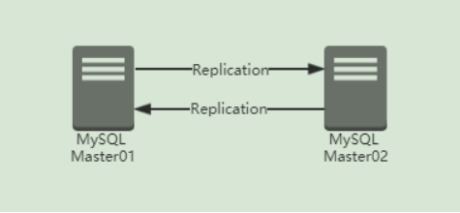
4.3 一主多从
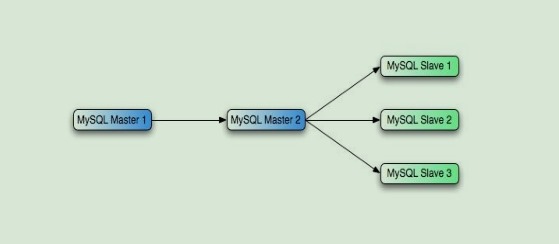
4.4 级联复制(A - - >B- - >C)
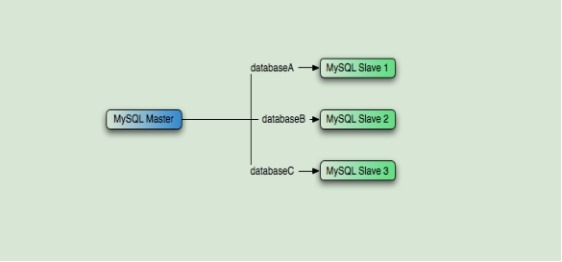
4.5 将主服务器不同的数据库复制到不同的从服务器
4.6 多源复制
4.7 半同步复制
4.8
高可用性

5 总结
5.1 mysql清空gtid操作
1 主节点
reset master #
清空gtid信息,binlog日志文件从mysql-bin.000001重新开始。
2 从节点
stop slave # 停止I/O、SQL线程
reset master # 清空gtid信息
reset slave # 清空复制信息(删除master.info文件,中继日志文件从relay-log.000001重新开始)
5.2 slave节点master.info问题
1 在slave节点设置"CHANGE
MASTER TO ……"时,会在"/usr/local/mysql/data/"目录下面生成"master.info"文件。
2 slave节点生成了"master.info"文件后,如果不开启或关闭了slave的I/O、SQL线程,在重启slave的时候,slave的I/O、SQL线程会自动启动。
5.3 从站gtid数值大于主站的gtid
从站报错如下


5.4 mysql auto.cnf
1 auto.cnf中的server-uuid是在mysql初始化时生成的。
2 MySQL启动时,会自动从data_dir/auto.cnf文件中获取server-uuid值,并将这个值存储在全局变量server_uuid(show
global variables like "server_uuid";可查看)中。如果这个值或者这个文件不存在,那么将会创建auto.cnf文件并将mysql初始化时生成的server-uuid值保存其中。
3 如果单独修改uuid值,重启mysql后就会使用该server-uuid的值。
4 server-uuid与server-id一样,用于标识MySQL实例在集群中的唯一性,这两个参数在主从复制中具有重要作用,默认情况下,如果主、从库的server-uuid或者server-id的值一样,将会导致主从复制报错中断。
5.5 mysql gtid说明
1 只有开启了binlog日志的节点才能产生gtid事务
2 mysql.gtid_executed表会记录gtid_executed记录(比如主主,来自自身也来自对面的主,有时可能需重启mysql后才能看到,show
global variables like "%gtid%"命令会看到实时的数据)。
3 主从复制时,mysql复制账户和root密码最好保持一致,以免复制过程中出现问题。
4 查看gtid信息的方法("3.2在线增加从服务器"环境)
实验数据
mysql> create database test;
mysql> use test;
mysql> create table user(name
varchar(50));
mysql> insert into user(name)
values("zhangsan");
(1)
master节点
1) show master status;

2) show global variables like
"gtid%";
(2)
slave节点
1) show slave status\G;
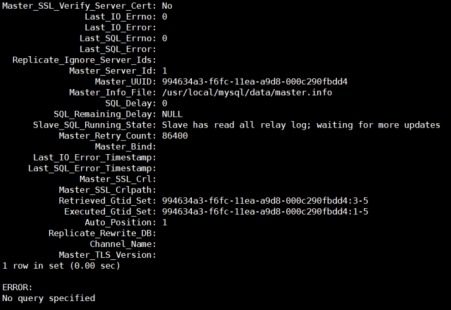
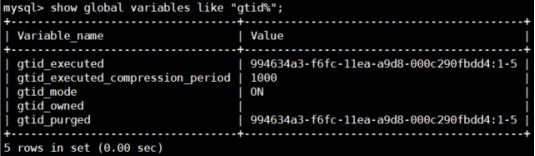
2) show global variables like
"gtid%";
MySQL数据库复制技术应用实战(阶段二)的更多相关文章
- 知识点:Mysql 数据库索引优化实战(4)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) 一:插入订单 业务逻辑:插 ...
- MySQL数据库主从同步实战过程
Linux系统MySQL数据库主从同步实战过程 安装环境说明 系统环境: [root@~]# cat /etc/redhat-release CentOS release 6.5 (Final) ...
- MySQL数据库学习笔记(十二)----开源工具DbUtils的使用(数据库的增删改查)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
- MySQL数据库中的索引(二)——索引的使用,最左前缀原则
上文中,我们了解了MySQL不同引擎下索引的实现原理,在本文我们将继续探讨一下索引的使用以及优化. 创建索引可以大大提高系统的性能. 第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性. ...
- 通过读取excel数据和mysql数据库数据做对比(二)-代码编写测试
通过上一步,环境已搭建好了. 下面开始实战, 首先,编写链接mysql的函数conn_sql.py import pymysql def sql_conn(u,pwd,h,db): conn=pymy ...
- SpringBoot框架:使用mybatis连接mysql数据库完成数据访问(二)
一.导入依赖包 1.在创建项目时勾选: 勾选SQL中的JDBC API.MyBatis Framework.MySQL Driver,创建项目后就会自动配置和引入这些包. 2.在pom.xml文件中添 ...
- 《MySQL数据库》常用语法(二)
表关联关系: -- 内联接 SELECT * FROM m INNER JOIN n ON m.id = n.id; -- 左外联接 SELECT * FROM m LEFT JOIN n ON m. ...
- Java Web下MySQL数据库的增删改查(二)
前文:https://www.cnblogs.com/Arisf/p/14095002.html 在之前图书管理系统上做了改进优化 图书管理系统v2 首先是项目结构: 1.数据库的连接: 1 pack ...
- MYSQL数据库性能调优之二:定位慢查询
windows下开启慢查询: 第一步:先查看版本 第二步查看查询日志和慢查询配置 第三步:配置开启慢查询 在my.ini配置文件的[mysqld]选项下增加: slow_query_log=TRUE ...
随机推荐
- 桌面支持qt版本是多少检查
桌面支持qt版本是多少 # rpm -qa |grep qt |grep 3 |sortqt3-3.3.8b-60.nd7.2.x86_64qt-4.8.6-13.nd7.3.x86_64qt5-qt ...
- OpenStack常见面试题
现在,大多数公司都试图将它们的 IT 基础设施和电信设施迁移到私有云, 如 OpenStack.如果你打算面试 OpenStack 管理员这个岗位,那么下面列出的这些面试问题可能会帮助你通过面试. Q ...
- Linux_rpm包管理
一.rpm包命令规范 1.包的组成 主包:bind-9.7.1-1.el5.i586.rpm 子包:bind-libs-9.7.1-1.el5.i586.rpm bind-utils-9.7.1-1. ...
- ELK学习实验020:ELK使用kafka缓存
首先安装一个kafka集群,但是zookeeper使用单节点,可以让kafka快速跑起来,后续再研究kafka和zokkeeper的集群 1 安装Kafka集群 下面是三个节点都要做 [root@no ...
- STM32的时钟系统RCC详细整理(转载)
一.综述: 1.时钟源 在 STM32 中,一共有 5 个时钟源,分别是 HSI . HSE . LSI . LSE . PLL . ①HSI 是高速内部时钟, RC 振荡器,频率为 8MHz : ② ...
- nginx 配置 conf stream
nginx从1.9.0版本开始,新增了ngx_stream_core_module模块,使nginx支持四层负载均衡.默认编译的时候该模块并未编译进去,需要编译的时候添加--with-stream参数 ...
- Python小白的数学建模课-A1.国赛赛题类型分析
分析赛题类型,才能有的放矢. 评论区留下邮箱地址,送你国奖论文分析 『Python小白的数学建模课 @ Youcans』 带你从数模小白成为国赛达人. 1. 数模竞赛国赛 A题类型分析 年份 题目 要 ...
- Your branch and 'origin/master' have diverged, and have 1 and 1 different commits each, respectively
On branch master Your branch and 'origin/master' have diverged, and have 1 and 1 different commits e ...
- Mysql索引数据结构为什么是B+树?
目录 Mysql索引数据结构 二叉树 红黑树 B-Tree B+Tree Mysql索引数据结构 下面列举了常见的数据结构 二叉树 红黑树 Hash表 B-Tree(B树) Select * from ...
- GO学习-(17) Go语言基础之反射
Go语言基础之反射 本文介绍了Go语言反射的意义和基本使用. 变量的内在机制 Go语言中的变量是分为两部分的: 类型信息:预先定义好的元信息. 值信息:程序运行过程中可动态变化的. 反射介绍 反射是指 ...