Mysql中的Join详解
一、Simple Nested-Loop Join(简单的嵌套循环连接)
简单来说嵌套循环连接算法就是一个双层for 循环 ,通过循环外层表的行数据,逐个与内层表的所有行数据进行比较来获取结果,当执行select * from user tb1 left join level tb2 on tb1.id=tb2.user_id
时,我们会按类似下面代码的思路进行数据匹配:

整个匹配过程会如下图:
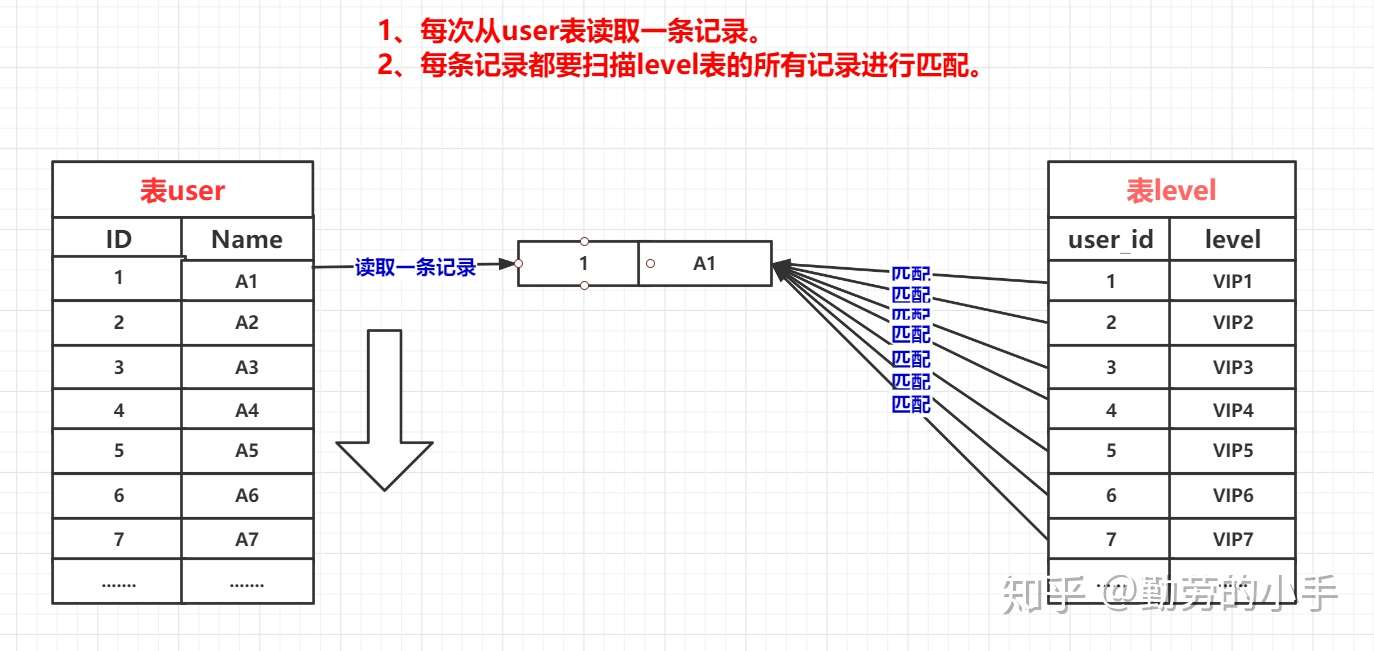
特点:
Nested-Loop Join 简单粗暴容易理解,就是通过双层循环比较数据来获得结果,但是这种算法显然太过于粗鲁,如果每个表有1万条数据,那么对数据比较的次数=1万 * 1万 =1亿次,很显然这种查询效率会非常慢。
当然mysql 肯定不会这么粗暴的去进行表的连接,所以就出现了后面的两种对Nested-Loop Join 优化算法,在执行join 查询时mysql 会根据情况选择 后面的两种优join优化算法的一种进行join查询。
二、Index Nested-Loop Join(索引嵌套循环连接)
Index Nested-Loop Join其优化的思路 主要是为了减少内层表数据的匹配次数, 简单来说Index Nested-Loop Join 就是通过外层表匹配条件 直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较, 这样极大的减少了对内层表的匹配次数,从原来的匹配次数=外层表行数 * 内层表行数,变成了 外层表的行数 * 内层表索引的高度,极大的提升了 join的性能。
案例:
如SQL:select * from user tb1 left join level tb2 on tb1.id=tb2.user_id
当level 表的 user_id 为索引的时候执行过程会如下图:
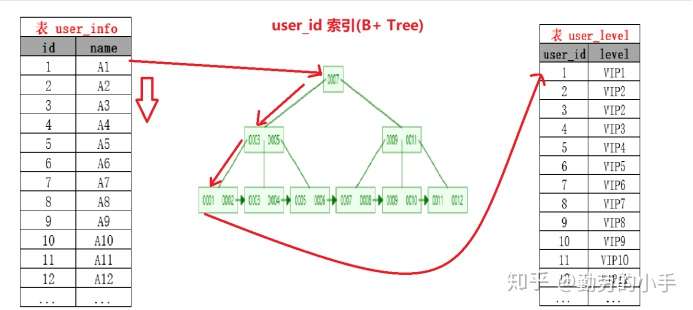
注意:使用Index Nested-Loop Join 算法的前提是匹配的字段必须建立了索引。
三、Block Nested-Loop Join(缓存块嵌套循环连接)
Block Nested-Loop Join 其优化思路是减少内层表的扫表次数,通过简单的嵌套循环查询的图,我们可以看到,左表的每一条记录都会对右表进行一次扫表,扫表的过程其实也就是从内存读取数据的过程,那么这个过程其实是比较消耗性能的。
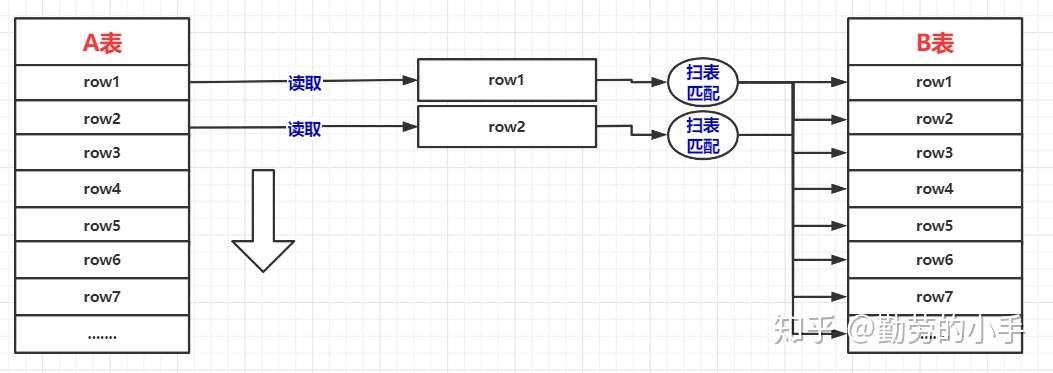
所以缓存块嵌套循环连接算法意在通过一次性缓存外层表的多条数据,以此来减少内层表的扫表次数,从而达到提升性能的目的。如果无法使用Index Nested-Loop Join的时候,数据库是默认使用的是Block Nested-Loop Join算法的。
当level 表的 user_id 不为索引的时候,默认会使用Block Nested-Loop Join算法,匹配的过程类似下图。
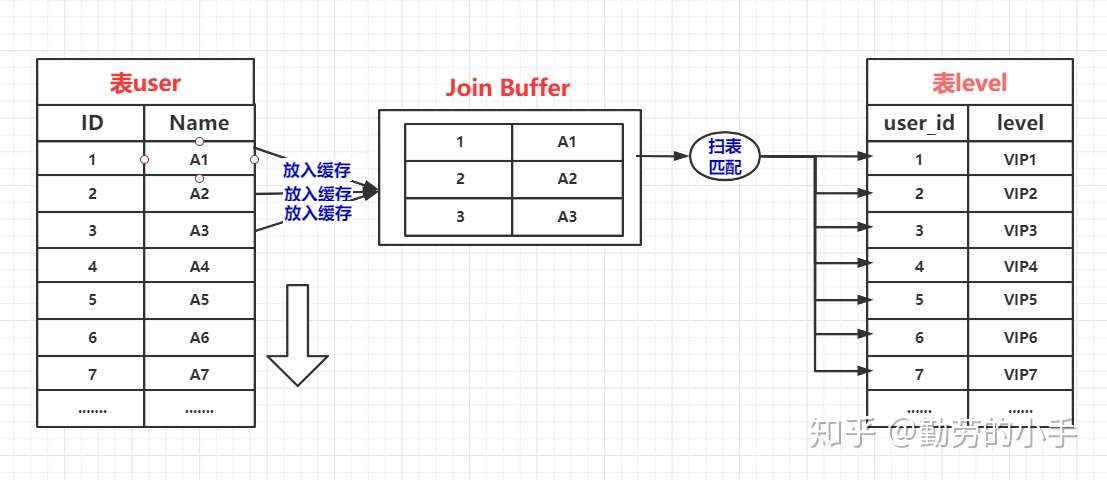
注意:
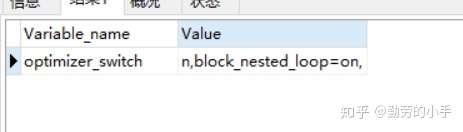
1、使用Block Nested-Loop Join 算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on默认为开启,如果关闭则使用Simple Nested-Loop Join 算法;
通过指令:Show variables like 'optimizer_switc%'; 查看配置
2、设置join buffer 的大小
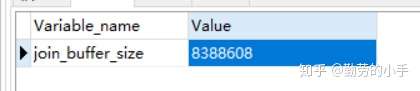
通过join_buffer_size参数可设置join buffer的大小
指令:Show variables like 'join_buffer_size%';
四、Merge Join
sort merge-join,merge join需要首先对两个表按照关联的字段进行排序;排序合并连接原理是先对两个表/行源根据JOIN列进行全扫描后排序,然后再进行连接。排序合并连接可以处理非等值JOIN。排序合并连接非常耗费资源,主因是对要连接的表/结果集进行排序,通常情况下,CBO是不会优先选择该表连接方式。
示例:select * from a,b where a.id<=b.id;
注意:可以使用USE_MERGE(table_name1 table_name2)来强制使用排序合并连接。Sort Merge join 用在没有索引,并且数据已经排序的情况。通常走Sort Merge join的场景:
- RBO模式
- 不等价关联(>,<,>=,<=,<>)
- HASH_JOIN_ENABLED=false
- 数据源已排序
五、Hash Join
Hash Join (WL#2241) 此功能由 Erik Froseth 实现,为 MySQL 中执行内部等价联接的一种方式。例如:SELECT*FROM t1 JOIN t2 ON t1.col1=t2.col1;可以在 8.0.18 中作为 Hash Join 执行。Hash Join 不需要任何索引来执行,并且在大多数情况下比当前的块嵌套循环算法更有效。
示例如下:
根据MySQL官方文档介绍,Hash Join不需要任何索引来执行,并且在大多数情况下比当前的块嵌套循环算法更有效。下面介绍下啥是Hash Join。
hash join是一种数据库在进行多表连接时的处理算法,对于多表连接还有两种比较常用的方式:sort merge-join 和 nested loop。大家都知道,oracle,postgresql都已支持hash-join,mysql8.0.17之前版本是不支持的。hash-join本身的实现并不是很复杂,但需要优化器的实现配合才能最难的地方。
多表连接分为以下几种:内连接(inner join),外连接(inner join)和交叉连接。外连接又分为:左外连接,右外连接和全外连接。对于不同的查询方式,使用相同的join算法也会有不同的代价产生,具体使用哪一种连接方式是由优化器通过代价的衡量来决定。
hash-join是CBO 做大数据集连接时的常用方式,对于两个表来讲,优化器使用两个表中较小的表利用连接键在内存中建立hash表,然后扫描较大的表,找出与hash表中匹配的行。因hash表是放在内存中,所以可很快的得到对应的hash表与较大表相匹配的行。
这种方式适用于较小的表完全可以放于内存中的情况,总成本就是访问两个表的成本之和。但如果HASH表太大,无法一次构造在内存中,这时优化器会将它分割成若干不同的partition,不能放入内存的部分就把该分区写入磁盘的temporary segment,此时要有较大的临时段从而尽量提高I/O 的性能;因会多一个写的代价,会降低效率。
可以用USE_HASH(table_name1 table_name2)提示来强制使用散列连接。
六、优化器
好了,接下来要讲一讲优化器了。
大家都知道,优化器的处理是比较复杂,也是sql执行过程张最难的地方,优化器没有最优只有更优。目前的优化器大都属于CBO(COST-BASED OPTIMIZER)类型。优化器的路径选择会依据一些统计信息,如列最大值、最小值、直方图、DISTINCT值等,找出消耗CPU和内存最少的sql执行路径。
优化器作用在于路径选择,多表连接如何确定表连接的顺序和连接方式;不同的数据库有着不同的选择,pg支持动态规划算法,表数量过多的时候使用遗传算法。
这里先看下hash join的实现步骤:
1.hash join的实现分为build table也就是被用来建立hash map的小表和probe table,hash join本身的实现不要去判断哪个是小表,优化器生成执行计划时就已经确定了表的连接顺序;
2.首先依次读取小表的数据,对于每一行数据根据连接条件生成一个hash map中的一个元组;
3.数据缓存在内存中,如内存放不下需dump到外存temporary segment上;
4.依次扫描探测表拿到每一行数据根据join condition生成hash key映射hash map中对应的元组,元组对应的行和探测表的这一行有着同样的hash key, 这时并不能确定这两行就是满足条件的数据,需要再次过一遍join condition和filter,满足条件的数据集返回需要的投影列。
Hash join的代价值:
cost = (outer access cost * # of hash partitions) + inner access cost+JOIN_CONDITION_COST + FILTER_COST
注意:
hash table的大小、需要分配多少个patition是一个问题,分配太大会造成内存浪费,分配太小会导致一旦超过内存限制,会dump到外存,不同数据库有不同的实现方式。
小结:
- Hash join通常将相对小的那个表做hash运算,将关联列数据存储到hash列表中,从另一个表中抽取记录,做hash运算,到hash 列表中找到相应的值,做关联比对。
- Nested loops 是从一张表中读取数,访问另一张表来做匹配(关联属性通常要建index),适用场合是关联表较小时,效率会更高。
- Merge Join 是先将关联表的关联列各自先行做排序,从各自的排序表中抽取数据,到另一个排序表中做匹配。merge join的主要耗时体现在关联了的排序上,故消耗的资源更多。
七、Join 算法总结
不论是Index Nested-Loop Join 还是 Block Nested-Loop Join 都是在Simple Nested-Loop Join的算法的基础上进行优化,这里 Index Nested-Loop Join 和Nested-Loop Join 算法是分别对Join过程中循环匹配次数和IO 次数两个角度进行优化。
Index Nested-Loop Join 是通过索引的机制减少内层表的循环匹配次数达到优化效果,而Block Nested-Loop Join 是通过一次缓存多条数据批量匹配的方式来减少内层表的扫表IO次数,通过 理解join 的算法原理我们可以得出以下表连接查询的优化思路。
1、永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量)
2、为匹配的条件增加索引(减少内层表的循环匹配次数)
3、增大join buffer size的大小(一次缓存的数据越多,那么内层包的扫表次数就越少)
4、减少不必要的字段查询(字段越少,join buffer 所缓存的数据就越多)
Mysql中的Join详解的更多相关文章
- Mysql中explain作用详解
一.MYSQL的索引 1.索引(Index):帮助Mysql高效获取数据的一种数据结构.用于提高查找效率,可以比作字典.可以简单理解为排好序的快速查找的数据结构.2.索引的作用:便于查询和排序(所以添 ...
- MySQL系列详解三:MySQL中各类日志详解-技术流ken
前言 日志文件记录了MySQL数据库的各种类型的活动,MySQL数据库中常见的日志文件有 查询日志,慢查询日志,错误日志,二进制日志,中继日志 .下面分别对他们进行介绍. 查询日志 1.查看查询日志变 ...
- MySQL中事物的详解
1. 事物的定义及特性 事务是一组操作数据库的SQL语句组成的工作单元,该工作单元中所有操作要么同时成功,要么同时失败.事物有如下四个特性,ACID简称“酸性”. 1)原子性:工作单元中所有的操作要么 ...
- Mysql中timestamp用法详解
前言:时间戳(timestamp),一个能表示一份数据在某个特定时间之前已经存在的. 完整的. 可验证的数据,通常是一个字符序列,唯一地标识某一刻的时间.使用数字签名技术产生的数据, 签名的对象包括了 ...
- Python3.7.1学习(七)mysql中pymysql模块详解(一)
pymysql是纯用Python操作MySQL的模块,其使用方法和MySQLdb几乎相同.此次介绍mysql以及在python中如何用pymysql操作数据库, 以及在mysql中存储过程, 触发器以 ...
- MySQL中EXPLAIN命令详解
explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 使用方法,在select语句前加上explain就可以了: 如: expla ...
- Mysql中的delimiter详解
初学mysql时,可能不太明白delimiter的真正用途,delimiter在mysql很多地方出现,比如存储过程.触发器.函数等. 学过oracle的人,再来学mysql就会感到很奇怪,百思不得其 ...
- MySQL中的视图详解
一.什么是视图? 简单来说,视图就是从一张表中导出的虚拟表.视图拥有表的结构,但是在数据库中只有视图的定义,但是没有视图中的数据. 视图是由查询语句从一张表中导出来的数据,不是一张实际的表. 二.视图 ...
- Python中操作mysql的pymysql模块详解
Python中操作mysql的pymysql模块详解 前言 pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同.但目前pymysql支持python3.x而后者不支持 ...
随机推荐
- 《PHP扩展学习系列》系列分享专栏
<PHP扩展学习系列>系列分享专栏 <PHP扩展学习系列>已整理成PDF文档,点击可直接下载至本地查阅https://www.webfalse.com/read/20177 ...
- vmware使用U盘安装系统
创建好系统 创建一个新的硬盘,选择"physicalDrive1" 如果识别不到physicalDrive 1,使用下面的方法. 1.在本机的服务里面启用下面的服务. 2.重启 V ...
- 从 Vue 中 parseHTML 方法来看前端 html 词法分析
先前我们在 从 Vue parseHTML 所用正则来学习常用正则语法 这篇文章中分析了 parseHTML 方法用到的正则表达式,在这个基础上我们可以继续分析 parseHTML 方法. 先来看该方 ...
- C语言:\t\b\n应用
#include <stdio.h> int main() { printf("123\n"); printf("%c\n",'\177'); pr ...
- C语言:判断整除
if (aa%10==0)来判断 不能用if (aa/10==int(aa/10)) 判断
- java课堂动手动脑及课后实验总结
动手动脑一:枚举 输出结果: false false true SMALL MEDIUM LARGE 分析和总结用法 枚举类型的使用是借助ENUM这样一个类,这个类是JAVA枚举类型的公共基本 ...
- ZooKeeper 分布式锁 Curator 源码 04:分布式信号量和互斥锁
前言 分布式信号量,之前在 Redisson 中也介绍过,Redisson 的信号量是将计数维护在 Redis 中的,那现在来看一下 Curator 是如何基于 ZooKeeper 实现信号量的. 使 ...
- Docker的学习体验
由于兴致使然,便想学习一点Docker技术.于是,写了这篇学习Docker的体会.笔拙,见谅. 第一件事--把网线插上 相信很多人都被官网的<Sample application>的 do ...
- 开源协同办公平台部署教程:O2OA PAAS平台部署
一.镜像制作1.将安装介质o2server-5.0.3-linux.zip上传至镜像制作服务器上.(上传目录为/paas/xxhpaas/moka/o2oa)2.使用unzip命令解压安装包,参考命令 ...
- 简明易懂,将细节隐藏,面向新手树立web开发概念——学完Java基础语法,超快速上手springboot+mybatiJavaWeb开发
简明易懂,将细节隐藏,面向新手树立web开发概念 --学完Java基础语法,超快速上手JavaWeb开发 Web本质(先忽视各种协议) Web应用可以理解为浏览器和服务器之间的交互. 我们可以看一个简 ...