Linux 服务器的基本性能及测试方法
1. 摘要
一个基于 Linux 操作系统的服务器运行的同时,也会表征出各种各样参数信息。通常来说运维人员、系统管理员会对这些数据会极为敏感,但是这些参数对于开发者来说也十分重要,尤其当程序非正常工作的时候,这些蛛丝马迹往往会帮助快速定位跟踪问题。
这里只是一些简单的工具查看系统的相关参数,当然很多工具也是通过分析加工 /proc、/sys 下的数据来工作的,而那些更加细致、专业的性能监测和调优,可能还需要更加专业的工具(perf、systemtap 等)和技术才能完成哦。毕竟来说,系统性能监控本身就是个大学问。
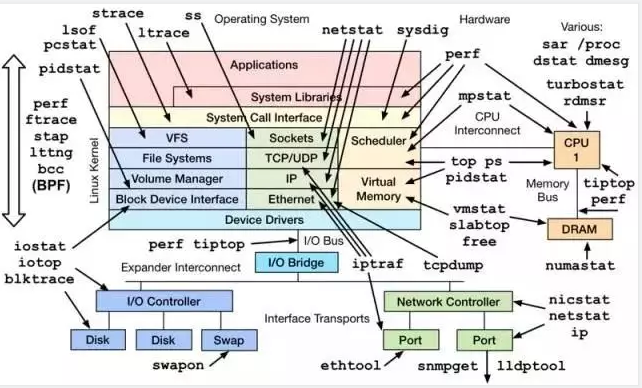
影响Linux服务器性能的主要因素:
- CPU
- 内存
- 磁盘I/O
- 网络I/O
2. 系统性能评估标准

其中:
%user:表示CPU处在用户模式下的时间百分比。
%sys:表示CPU处在系统模式下的时间百分比。
%iowait:表示CPU等待输入输出完成时间的百分比。
swap in:即si,表示虚拟内存的页导入,即从SWAP DISK交换到RAM
swap out:即so,表示虚拟内存的页导出,即从RAM交换到SWAP DISK。
3. 系统性能分析工具
3.1. 常用系统命令
Vmstat、sar、iostat、netstat、free、ps、top等
3.2. 常用组合方式
用vmstat、sar、iostat检测是否是CPU瓶颈
用free、vmstat检测是否是内存瓶颈
用iostat检测是否是磁盘I/O瓶颈
用netstat检测是否是网络带宽瓶颈
4. 系统整体性能评估
执行top命令
[root@mail ~]# top
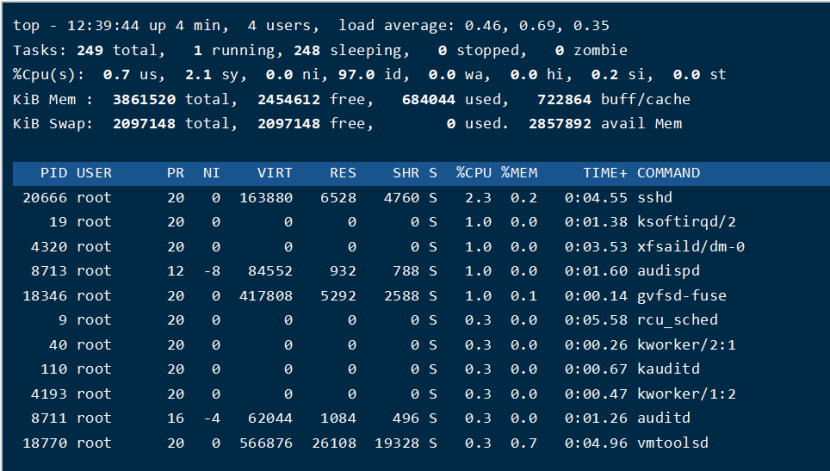
第一行后面的三个load average值是系统在之前 1、5、15分钟的平均负载,也可以看出系统负载是上升、平稳、下降的趋势,当这个值超过 CP可执行单元的数目,则表示 CP的性能已经饱和成为瓶颈了。
第二行统计了系统的任务状态信息。running 很自然不必多说,包括正在 CP上运行的和将要被调度运行的;sleeping 通常是等待事件(比如 IO 操作)完成的任务,细分可以包括 interruptible 和 uninterruptible 的类型;stopped 是一些被暂停的任务,通常发送 SIGSTOP 或者对一个前台任务操作 Ctrl-Z 可以将其暂停;zombie 僵尸任务,虽然进程终止资源会被自动回收,但是含有退出任务的 task descriptor 需要父进程访问后才能释放,这种进程显示为 defunct 状态,无论是因为父进程提前退出还是未 wait 调用,出现这种进程都应该格外注意程序是否设计有误。
第三行 CP占用率根据类型有以下几种情况:
(us) user:CP在低 nice 值(高优先级)用户态所占用的时间(nice<=0)。正常情况下只要服务器不是很闲,那么大部分的 CP时间应该都在此执行这类程序
(sy) system:CP处于内核态所占用的时间,操作系统通过系统调用(system call)从用户态陷入内核态,以执行特定的服务;通常情况下该值会比较小,但是当服务器执行的 IO 比较密集的时候,该值会比较大
(ni) nice:CP在高 nice 值(低优先级)用户态以低优先级运行占用的时间(nice>0)。默认新启动的进程 nice=0,是不会计入这里的,除非手动通过 renice 或者 setpriority() 的方式修改程序的nice值
(id) idle:CP在空闲状态(执行 kernel idle handler )所占用的时间
(wa) iowait:等待 IO 完成做占用的时间
(hi) irq:系统处理硬件中断所消耗的时间
(si) softirq:系统处理软中断所消耗的时间,记住软中断分为 softirqs、tasklets (其实是前者的特例)、work queues,不知道这里是统计的是哪些的时间,毕竟 work queues 的执行已经不是中断上下文了
(st) steal:在虚拟机情况下才有意义,因为虚拟机下 CP也是共享物理 CP的,所以这段时间表明虚拟机等待 hypervisor 调度 CP的时间,也意味着这段时间 hypervisor 将 CP调度给别的 CP执行,这个时段的 CP资源被“stolen”了。
第四行和第五行是物理内存和虚拟内存(交换分区)的信息:
total = free + used + buff/cache,现在buffers和cached Mem信息总和到一起了,但是buffers和cached Mem 的关系很多地方都没说清楚。其实通过对比数据,这两个值就是 /proc/meminfo 中的 Buffers 和 Cached 字段:Buffers 是针对 raw disk 的块缓存,主要是以 raw block 的方式缓存文件系统的元数据(比如超级块信息等),这个值一般比较小(20M左右);而 Cached 是针对于某些具体的文件进行读缓存,以增加文件的访问效率而使用的,可以说是用于文件系统中文件缓存使用。
而 avail Mem 是一个新的参数值,用于指示在不进行交换的情况下,可以给新开启的程序多少内存空间,大致和 free + buff/cached 相当,而这也印证了上面的说法,free + buffers + cached Mem才是真正可用的物理内存。并且,使用交换分区不见得是坏事情,所以交换分区使用率不是什么严重的参数,但是频繁的 swap in/out 就不是好事情了,这种情况需要注意,通常表示物理内存紧缺的情况。
最后是每个程序的资源占用列表,其中 CP的使用率是所有 CPcore 占用率的总和。通常执行 top 的时候,本身该程序会大量的读取 /proc 操作,所以基本该 top 程序本身也会是名列前茅的。
top 虽然非常强大,但是通常用于控制台实时监测系统信息,不适合长时间(几天、几个月)监测系统的负载信息,同时对于短命的进程也会遗漏无法给出统计信息。
5. CPU性能评估
5.1. 利用vmstat命令监控系统CPU
该命令可以显示关于系统各种资源之间相关性能的简要信息,这里我们主要用它来看CPU一个负载情况。下面是vmstat命令在某个系统的输出结果:
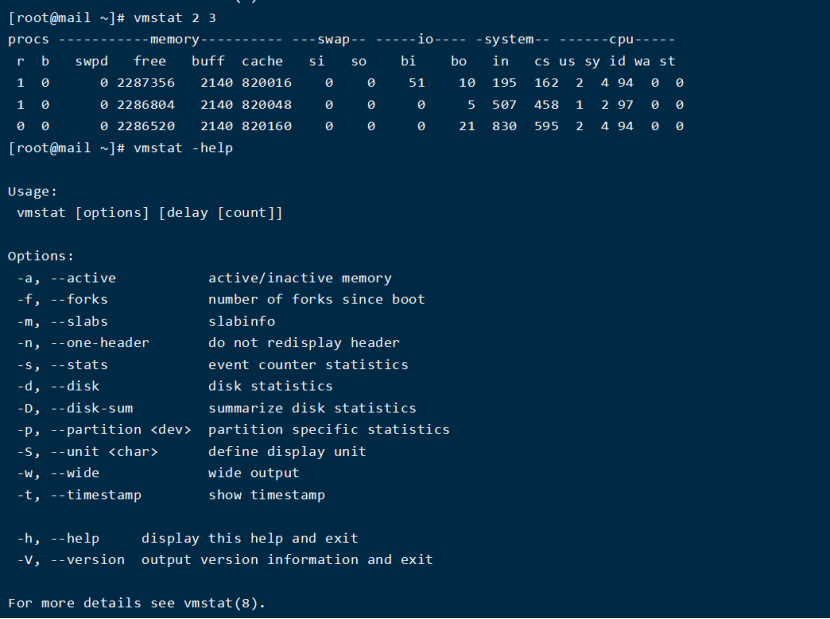
结果分析:
Procs:
r列表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的个数,说明CPU不足,需要增加CPU。
b列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
Cpu:
us列显示了用户进程消耗的CP时间百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法。
sy列显示了内核进程消耗的CPU时间百分比。Sy的值较高时,说明内核消耗的CPU资源很多。
根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。
5.2. 利用sar命令监控系统CPU
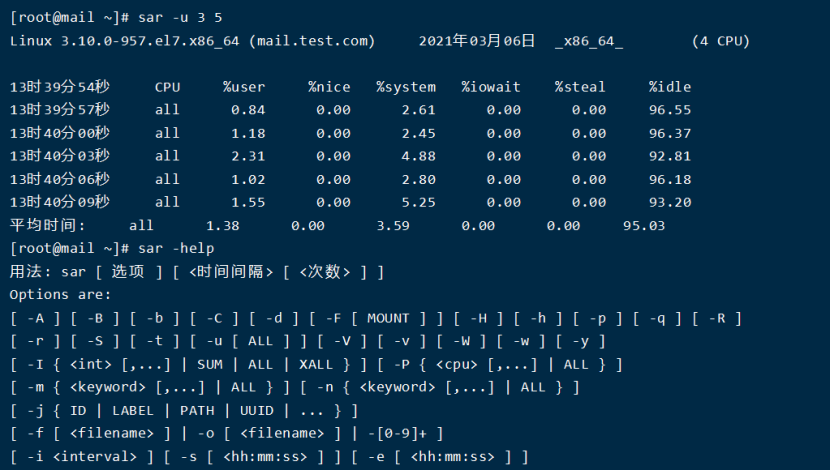
结果分析:
%user列显示了用户进程消耗的CP时间百分比。
%nice列显示了运行正常进程所消耗的CP时间百分比。
%system列显示了系统进程消耗的CPU时间百分比。
%iowait列显示了IO等待所占用的CPU时间百分比
%steal列显示了在内存相对紧张的环境下pagein强制对不同的页面进行的steal操作 。
%idle列显示了CPU处在空闲状态的时间百分比。
6. 内存性能评估
6.1. 利用vmstat命令监控内存
该命令可以显示关于系统各种资源之间相关性能的简要信息,这里我们主要用它来看内存情况。下面是vmstat命令在某个系统的输出结果:
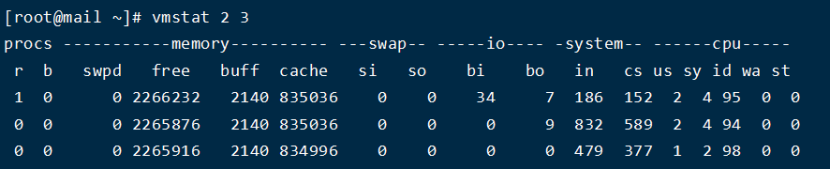
结果分析:
Memory:
swpd列表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si、so的值长期为0,这种情况下一般不用担心,不会影响系统性能。
free列表示当前空闲的物理内存数量(以k为单位)
buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。
cache列表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。
Swap:
si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。
so列表示由内存调入磁盘,也就是内存交换区进入内存的数量。
一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足。需要增加系统内存。
6.2. 利用free指令监控内存
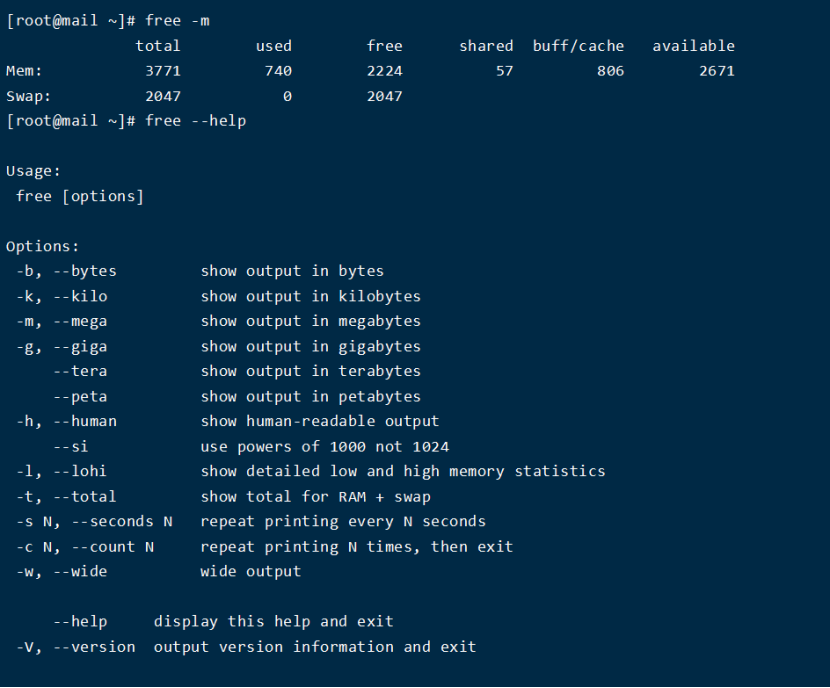
一般有这样一个经验公式:应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能,应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存,20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
7. 磁盘I/O性能评估
7.1. 利用iostat评估磁盘性能
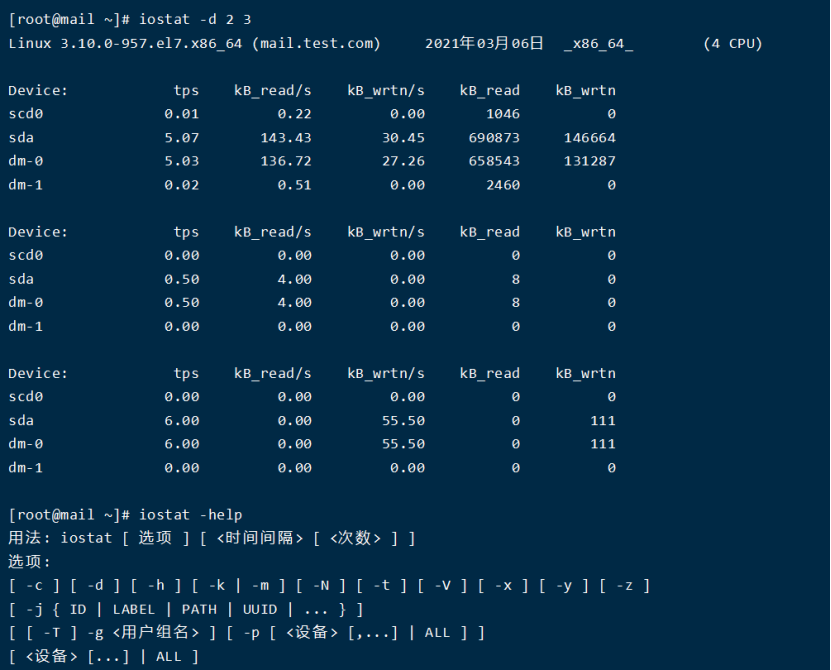
结果分析:
KB_read/s表示每秒读取的数据块数。
KB_wrtn/s表示每秒写入的数据块数。
KB_read表示读取的所有块数。
KB_wrtn表示写入的所有块数。
可以通过KB_read/s和KB_wrtn/s的值对磁盘的读写性能有一个基本的了解,如果KB_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或者优化程序,如果KB_read/s值很大,表示磁盘直接读取操作很多,可以将读取的数据放入内存中进行操作。
对于这两个选项的值没有一个固定的大小,根据系统应用的不同,会有不同的值,但是有一个规则还是可以遵循的:长期的、超大的数据读写,肯定是不正常的,这种情况一定会影响系统性能。
7.2. 利用sar评估磁盘性能
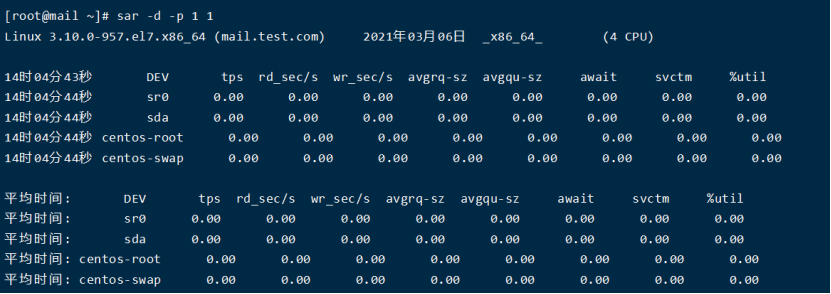
结果分析:
await表示平均每次设备I/O操作的等待时间(以毫秒为单位)。
svctm表示平均每次设备I/O操作的服务时间(以毫秒为单位)。
%util表示一秒中有百分之几的时间用于I/O操作。
对以磁盘IO性能,一般有如下评判标准:
正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。
await值的大小一般取决与svctm的值和I/O队列长度以及I/O请求模式,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util项的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
8. 网络I/O性能评估
网络性能对于服务器的重要性不言而喻,工具 iptraf 可以直观的现实网卡的收发速度信息,比较的简洁方便通过 sar -n DEV 1 也可以得到类似的吞吐量信息,而网卡都标配了最大速率信息,比如百兆网卡千兆网卡,很容易查看设备的利用率。
通常,网卡的传输速率并不是网络开发中最为关切的,而是针对特定的 UDP、TCP 连接的丢包率、重传率,以及网络延时等信息。
8.1. 利用netstat评估网络性能
8.1.1. netstat -s
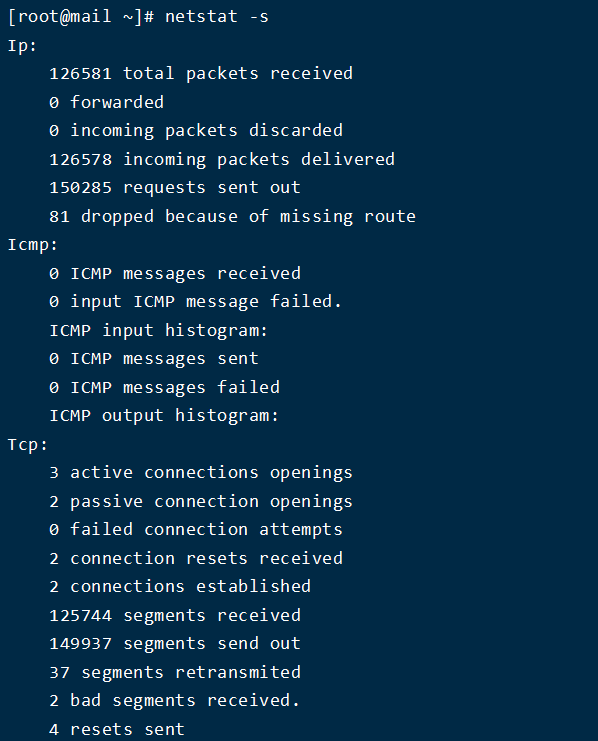
显示自从系统启动以来,各个协议的总体数据信息。虽然参数信息比较丰富有用,但是累计值,除非两次运行做差才能得出当前系统的网络状态信息,亦或者使用 眼睛直观其数值变化趋势。所以netstat通常用来检测端口和连接信息的。
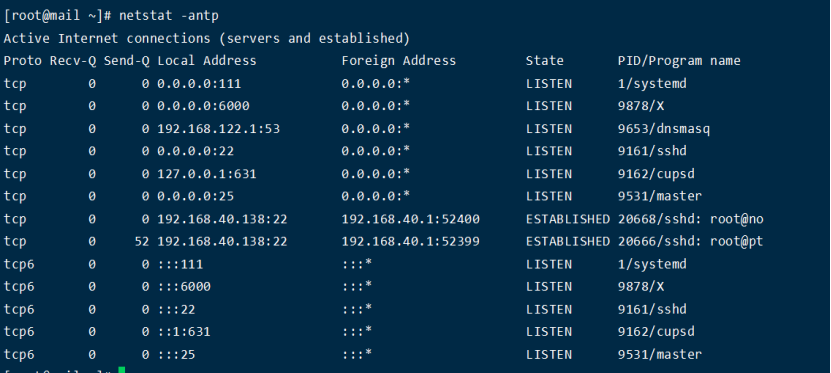
8.1.2. netstat -antp
列出所有TCP的连接:
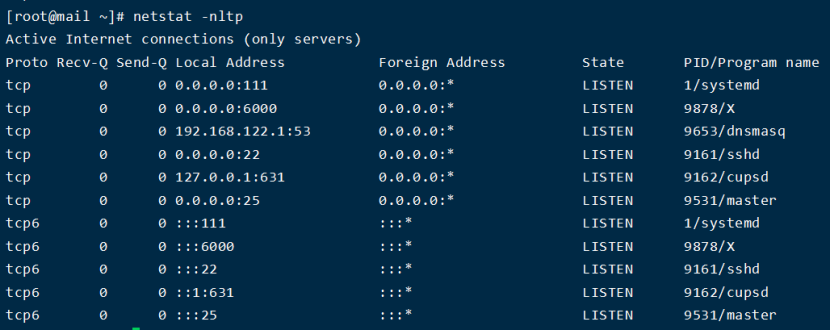
8.1.3. netstat -nltp
列出本地所有TCP侦听套接字,不要加-a参数
8.2. 利用TCP评估网络性能
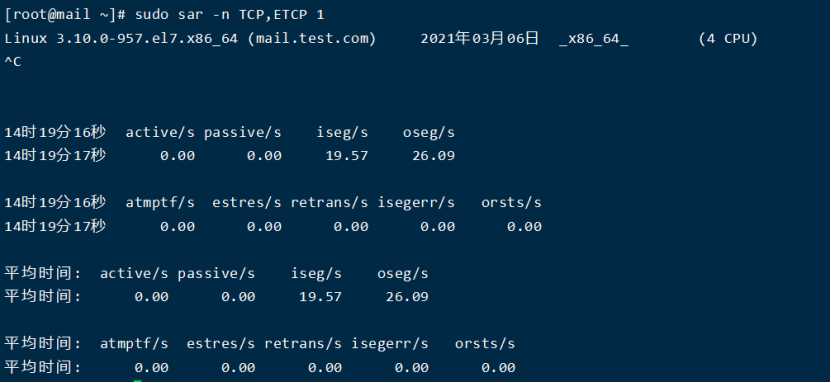
结果分析:
active/s:本地发起的 TCP 连接,比如通过 connect(),TCP 的状态从CLOSED -> SYN-SENT。
passive/s:由远程发起的 TCP 连接,比如通过 accept(),TCP 的状态从LISTEN -> SYN-RCVD。
retrans/s(tcpRetransSegs):每秒钟 TCP 重传数目,通常在网络质量差,或者服务器过载后丢包的情况下,根据 TCP 的确认重传机制会发生重传操作。
isegerr/s(tcpInErrs):每秒钟接收到出错的数据包(比如 checksum 失败)。
8.3. 利用UDP评估网络性能
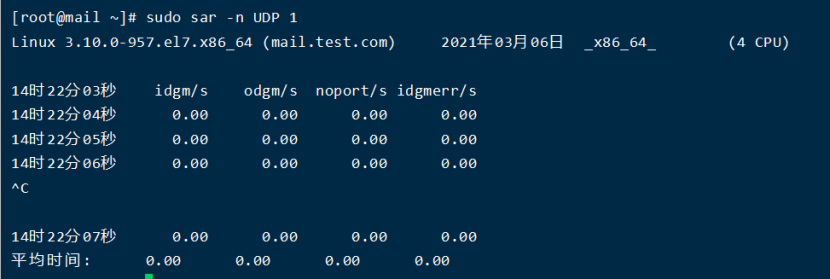
结果分析:
noport/s(udpNoPorts):每秒钟接收到的但是却没有应用程序在指定目的端口的数据报个数。
idgmerr/s(udpInErrors):除了上面原因之外的本机接收到但却无法派发的数据报个数。
当然,这些数据一定程度上可以说明网络可靠性,但也只有同具体的业务需求场景结合起来才具有意义
8.4. 利用iperf评估网络性能
iperf 是一个 TCP/IP 和 UDP/IP 的性能测量工具,能够提供网络吞吐率信息,以及震动、丢包率、最大段和最大传输单元大小等统计信息;从而能够帮助我们测试网络性能,定位网络瓶颈。
8.4.1. 常用公共参数
-i 2 #表示每2秒显示一次报告
-w 80k #对于TCP方式,此设置为TCP窗口大小。对于UDP方式,此设置为接受UDP数据包的缓冲区大小,限制可以接受数据包的最大值
-B 192.168.122.1
#绑定到主机的多个地址中的一个。对于客户端来说,这个参数设置了出栈接口。对于服务器端来说,这个参数设置入栈接口。这个参数只用于具有多网络接口的主机。
#在Iperf的UDP模式下,此参数用于绑 定和加入一个多播组。使用范围在224.0.0.0至239.255.255.255的多播地址
8.4.2. 常用客户端参数
-b 100m #用于udp测试时,设置测试发送的带宽,单位:bit/秒,不设置时默认为:1Mbit/秒
-c #指定服务端ip地址
-d #同时测试上行和下行
-t 10 #设置传输时间,为10秒
-P 5 #指定发起5个线程
8.4.3. TCP模式下网络测试
服务端:
iperf3 -p 8000 -s -i 1
参数说明: -p : 端口号 -s : 标示服务端 -: 标示udp协议 -i : 检测的时间间隔(单位:秒)络测试
客户端:
iperf3 -c 113.54.158.252 -p 8000 -i 1 -b 10M
客户端
iperf -c 192.168.122.1 -t 60 #在tcp模式下,客户端到服务器192.168.1.1上传带宽测试,测试时间为60秒。
iperf -c 192.168.122.1 -P 30 -t 60 #客户端同时向服务器端发起30个连接线程。
iperf -c 192.168.122.1 -d -t 60 -i 2 #进行上下行带宽测试。
8.4.4. UDP模式下网络测试
服务器端:
iperf3 -p 8000 -s -i 1
参数说明: -p : 端口号 -s : 标示服务端 -: 标示udp协议 -i : 检测的时间间隔(单位:秒)
客户端:
iperf3 - -c 113.54.158.252 -p 8000 -i 1 -b 10M
参数说明: -c : 服务端的ip地址 -p : 端口号 -: 标示udp协议 -b : 每一次发送的数据大小 -t : 总的发送时间(单位:秒) -i : 发送数据的时间间隔(单位:秒) -P : 表示线程个数,不指定则默认单线程
Linux 服务器的基本性能及测试方法的更多相关文章
- Linux服务器安全配置
众所周知,网络安全是一个非常重要的课题,而服务器是网络安全中最关键的环节.Linux被认为是一个比较安全的Internet服务器,作为一种开放源代码操作系统,一旦Linux系统中发现有安全漏洞,Int ...
- .NET跨平台之旅:将QPS 100左右的ASP.NET Core站点部署到Linux服务器上
今天下午我们将生产环境中一个单台服务器 QPS(每秒请求数)在100左右的 ASP.NET Core 站点部署到了 Linux 服务器上,这是我们解决了在 .NET Core 上使用 EnyimMem ...
- 如何使用Linux命令行查看Linux服务器内存使用情况?
一个服务器,最重要的资源之一就是内存,内存够不够用,是直接关系到系统性能的关键所在. 本文介绍如何查看Linux服务器内存使用情况, 1.free命令 free -m [root@localhost ...
- 检查Linux服务器性能
如果你的Linux服务器突然负载暴增,告警短信快发爆你的手机,如何在最短时间内找出Linux性能问题所在? 概述通过执行以下命令,可以在1分钟内对系统资源使用情况有个大致的了解. • uptime• ...
- linux下的ssh工具之,本地上传到linux服务器and Linux服务器文件另存为本地。非sftp工具。
首先,当你只有一个ssh工具可以连接linux,但你有想把文件在 linux 和windows(本地)直接的切换.其实可以的: 本文参考 1.将本地的文件,放到ssh远程的linux服务器上: 首先要 ...
- CentOS Linux服务器安全设置
转自:http://www.osyunwei.com/archives/754.html 引言: 我们必须明白:最小的权限+最少的服务=最大的安全 所以,无论是配置任何服务器,我们都必须把不用的服务关 ...
- 配置linux服务器的一些操作
本次课程实验,我们选择的是ubuntu 14.04操作系统,不像使用RDP连接windows服务器那样可以直观的看到远程端的图形界面,只能通过Xshell以命令行进行操作,那么就来说说配置远程linu ...
- 用十条命令在一分钟内检查Linux服务器性能
转自:http://www.infoq.com/cn/news/2015/12/linux-performance 如果你的Linux服务器突然负载暴增,告警短信快发爆你的手机,如何在最短时间内找出L ...
- Linux服务器宕机案例一则
案例环境 操作系统 :Oracle Linux Server release 5.7 64bit 虚拟机 硬件配置 : 物理机型号为DELL R720 资源配置 :RAM 8G Intel(R) Xe ...
随机推荐
- windows 根据 端口号 找到进程ID PID
List process by port number netstat -ano | findstr 8080 Proto Local Address Foreign Address State PI ...
- HTML 网页开发、CSS 基础语法——八.HTML基本语法
表格制作 1.表格基础 创建一个简单的表格至少有三个标签组成,分别是<table>,<tr>,<td>标签. table:表格,定义的是整个的表格大结构. tr:t ...
- Skywalking-13:Skywalking模块加载机制
模块加载机制 基本概述 Module 是 Skywalking 在 OAP 提供的一种管理功能特性的机制.通过 Module 机制,可以方便的定义模块,并且可以提供多种实现,在配置文件中任意选择实现. ...
- Three 之 Animation 初印象
Animation 初印象 动画效果 播放动画需要基本元素 AnimationMixer 一个对象所有动作的管理者 用于场景中特定对象的动画的播放器.一个对象可能有多个动作,Mixer 是用来管理所有 ...
- Multidimension Tools(多维工具)
多维工具 # Process: 创建 NetCDF 栅格图层 arcpy.MakeNetCDFRasterLayer_md("", "", "&quo ...
- 洛谷4400 BlueMary的旅行(分层图+最大流)
qwq 首先,我们观察到题目中提到的每天只能乘坐一次航班的限制,很容易想到建分层图,也就是通过枚举天数,然后每天加入一层新的点. (然而我一开始想的却是erf) 考虑从小到大枚举天数,然后每次新建一层 ...
- 小甲鱼零基础学python第25讲课后习题动手练习--通讯录
小甲鱼零基础学python第25讲课后习题动手练习---通讯录 **************************通讯录要求******************************* 输入指令: ...
- 使用寄存器点亮LED——2
1. 项目:使用stm32寄存器点亮LED, 分别点亮红.绿.蓝3个灯. 2. 步骤 先新建个文件夹保存项目 再新建项目 将startup_stm32f10x_hd.s拷贝到该文件夹下 新建main. ...
- 《手把手教你》系列技巧篇(三十三)-java+ selenium自动化测试-单选和多选按钮操作-上篇(详解教程)
1.简介 在实际自动化测试过程中,我们同样也避免不了会遇到单选和多选的测试,特别是调查问卷或者是答题系统中会经常碰到.因此宏哥在这里直接分享和介绍一下,希望小伙伴或者童鞋们在以后工作中遇到可以有所帮助 ...
- 【UE4 调试】C++ 常见编译 warnnings/errors
error LNK2019: unresolved external symbol "" referenced in function 描述 Link错误.无法解析的外部符号 解决 ...