CUDA计算矩阵相乘
1.最简单的 kernel 函数
__global__ void MatrixMulKernel( float* Md, float* Nd, float* Pd, int Width)
{
int tx = threadIdx.x; // cloumn
int ty = threadIdx.y; // row
float Pvalue = 0;
for (int k = 0; k<Width; k++)
{
float Mdele = Md[ty*Width + k];
float Ndele = Nd[k*Width + tx];
Pvalue += Mdele * Ndele;
}
Pd[ty*Width + tx] = Pvalue;
}
2.适用更大矩阵
第一节中例子缺点是,假如使用更多的块时,每个块中会计算相同的矩阵。而且矩阵元素不能超过512个线程(块最大线程限制)。
改进方法是,假设每个块维度都是方阵形式,且其维度由变量 TILE_WIDTH 指定。矩阵 Pd 的每一维都划分为部分,每个部分包含 TILE_WIDTH 个元素。
#define TILE_WIDTH 4
#define Width 8
__global__ void MatrixMulKernel( float* Md, float* Nd, float* Pd, int Width)
{
int Col = blockId.x*TILE_WIDTH + threadIdx.x; // cloumn
int Row = blockId.y*TILE_WIDTH + threadIdx.y; // row
float Pvalue = 0;
for (int k = 0; k<Width; k++)
{
Pvalue += Md[Row*Width + k] * Nd[k*Width + Col];
}
Pd[ty*Width + tx] = Pvalue;
}
dim3 dimGrid(Width/TILE_WIDTH, Width/TILE_WIDTH);
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH);
CUDA 硬件相关概念
针对 GT200而言
- 每个
SM有最多8个块 - 每个
SM有最多1024个线程
应当注意每个块中分配的线程数,以便能够充分利用SM
- 以32个线程为一个
warp,warp为线程调度单位
3.通过改变储存器提到访问效率
CGMA(Compute to Global Memory Access),尽量提高CGMA比值。
对前面来说,每个for循环内需要两次访问全局内存(Md[Row*Width + k], Nd[k*Width + Col]),两次浮点计算(加法与乘法)。因此 CGMA 为2:2 = 1。
G80 全局存储器带宽为 86.4 GB/s,计算峰值性能 367 Gflops。(每秒取 21.6G 个变量,由于CGMA=1,会进行 21.6G 次浮点计算)
若每个单精度浮点数为 4 字节,那么由于存储器限制,最大浮点操作不会超过 21.6 Gflops。
| 存储器类型 | 变量 | 周期 | 特点 | 访问速度 |
| --- | --- | --- | --- |
| 共享存储器 | 共享变量 | kernel函数 | 每个块中所有线程都可以访问,用于线程间协作高效方式 | 相当快,高度并行访问 |
| 常数存储器 | 常数变量 | 所有网格 | 相当快,并行访问 |
| 寄存器 | 自动变量 | 线程 | 寄存器具有储存容量限制 | 非常块
| 全局存储器 | 全局变量 | | 用于调用不同kernel函数时传递信息 | 慢 |
减少全局存储器流量策略
各个存储器特点:
- 全局存储器,容量大,访问慢
- 共享存储器,容量小,访问块
新算法要点:
- 将共享存储器上数据划分子集,每个子集满足共享存储器容量限制
- 通过线程协作将
M和N中的元素加载到共享存储器中,每个线程负责块中一个元素赋值(Mds[threadIdx.y][threadIdx.x],Nds[threadIdx.y][threadIdx.x]) - 通过加载到共享存储器,使得每个块访问全局内存的次数减小为原来的
TILE_WIDTH分之一(加载到共享内存时读取一次,每个块中使用TILE_WIDTH次)
__global__ void kernel_tile(float* M, float* N, float* P){
int i, k;
float Pvalue = 0;
__shared__ float Mds[tile_width][tile_width];
__shared__ float Nds[tile_width][tile_width];
int Row = threadIdx.y + blockIdx.y*tile_width;
int Col = threadIdx.x + blockIdx.x*tile_width;
for( i = 0; i< width/tile_width; i++ ){
Mds[threadIdx.y][threadIdx.x] = M[Row*width + i*tile_width + threadIdx.x];
Nds[threadIdx.y][threadIdx.x] = N[(threadIdx.y + i*tile_width)*width + Col];
__syncthreads();
for (k = 0; k<tile_width; k++){
Pvalue += Mds[threadIdx.y][k]*Nds[k][threadIdx.x];
}
__syncthreads();
}
P[Row*width + Col] = Pvalue;
}
存储器容量限制
G80 硬件中
- 每个
SM寄存器大小为 8 KB(8192 B) - 每个
SM共享内存大小为 16 KB - 若每个
SM中容纳线程数为 768,那么每个线程可用寄存器不超过 8 KB/768=10 Bytes(两个单精度变量占用 8 Bytes) - 若每个线程占用了多余 10 Bytes,那么就会减少
SM上线程数,且以块为单位减少 - 若每个
SM中容纳 8 个块,那么每个块不能使用超过 2 KB 的存储器
4.数据预取
在 CUDA 中,当某些线程在等待其存储器访问结果时,CUDA 线程模型可以通过允许其他 warp 继续运行,这样就能容许长时间的访问延时。
为了充分利用此特性,需要当使用当前数据元素时预取下一个数据元素,这样就可以正价在储存器访问和已访问的数据使用指令之间的独立指令的数目。
预取技术经常和分块技术结合,解决带宽限制和长时间延迟问题。
例如在第三节中矩阵乘法问题中,使用预取技术后函数流程变为
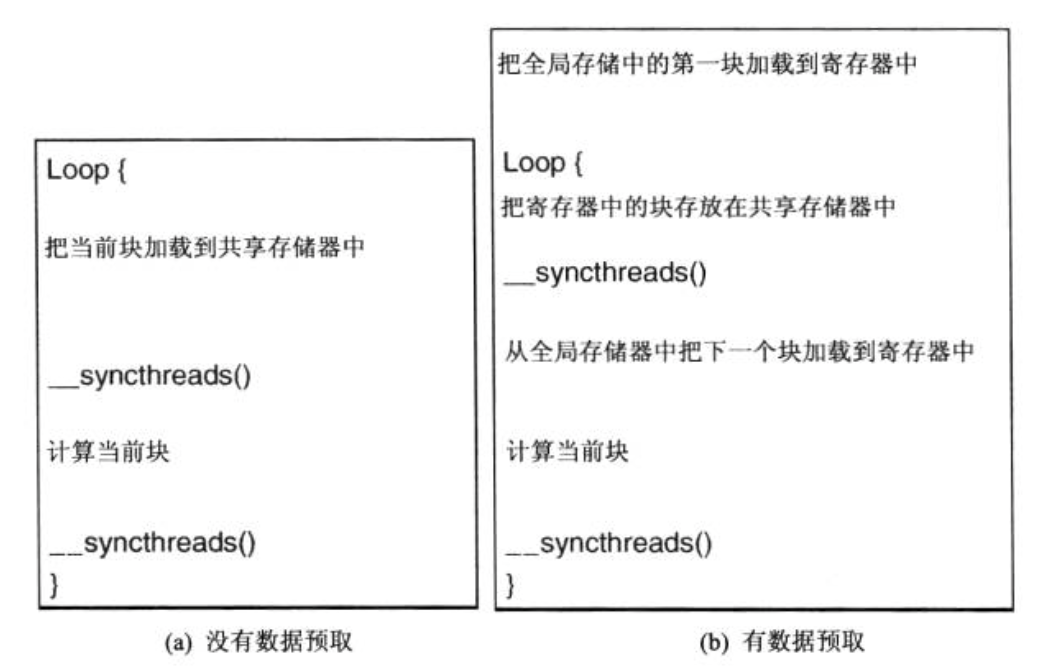
对应程序为
__global__ void kernel_prefetch(float* M, float* N, float* P){
int i;
float Pvalue = 0;
float Mc, Nc;
int Row = threadIdx.y + tile_width*blockIdx.y;
int Col = threadIdx.x + tile_width*blockIdx.x;
__shared__ float Mds[tile_width][tile_width];
__shared__ float Nds[tile_width][tile_width];
Mc = M[Row*width + threadIdx.x];
Nc = N[Col + threadIdx.y*width];
for (i = 1; i<width/tile_width+1; i++){
Mds[threadIdx.y][threadIdx.x] = Mc;
Nds[threadIdx.y][threadIdx.x] = Nc;
__syncthreads();
Mc = M[Row*width + threadIdx.x + i*tile_width];
Nc = N[Col + (threadIdx.y + i*tile_width)*width];
for (int k = 0; k<tile_width; k++){
Pvalue += Mds[threadIdx.y][k]*Nds[k][threadIdx.x];
}
__syncthreads();
}
P[Col + Row*width] = Pvalue;
}
Mc,Nc 为增加的两个储存在寄存器内的变量。
CUDA计算矩阵相乘的更多相关文章
- STL模板之_map,stack(计算矩阵相乘的次数)
#include <map>#include <stack>#include <iostream>using namespace std; struct Node ...
- Java实现矩阵相乘问题
1 问题描述 1.1实验题目 设M1和M2是两个n×n的矩阵,设计算法计算M1×M2 的乘积. 1.2实验目的 (1)提高应用蛮力法设计算法的技能: (2)深刻理解并掌握分治法的设计思想: (3)理解 ...
- CUDA编程-(2)其实写个矩阵相乘并不是那么难
程序代码及图解析: #include <iostream> #include "book.h" __global__ void add( int a, int b, i ...
- 编程计算2×3阶矩阵A和3×2阶矩阵B之积C。 矩阵相乘的基本方法是: 矩阵A的第i行的所有元素同矩阵B第j列的元素对应相乘, 并把相乘的结果相加,最终得到的值就是矩阵C的第i行第j列的值。 要求: (1)从键盘分别输入矩阵A和B, 输出乘积矩阵C (2) **输入提示信息为: 输入矩阵A之前提示:"Input 2*3 matrix a:\n" 输入矩阵B之前提示
编程计算2×3阶矩阵A和3×2阶矩阵B之积C. 矩阵相乘的基本方法是: 矩阵A的第i行的所有元素同矩阵B第j列的元素对应相乘, 并把相乘的结果相加,最终得到的值就是矩阵C的第i行第j列的值. 要求: ...
- cuda计算的分块
gpu的架构分为streaming multiprocessors 每个streaming multiprocessors(SM)又能分步骤执行很多threads,单个SM内部能同时执行的thread ...
- 利用Hadoop实现超大矩阵相乘之我见(二)
前文 在<利用Hadoop实现超大矩阵相乘之我见(一)>中我们所介绍的方法有着“计算过程中文件占用存储空间大”这个缺陷,本文中我们着重解决这个问题. 矩阵相乘计算思想 传统的矩阵相乘方法为 ...
- 利用Hadoop实现超大矩阵相乘之我见(一)
前记 最近,公司一位挺优秀的总务离职,欢送宴上,她对我说“你是一位挺优秀的程序员”,刚说完,立马道歉说“对不起,我说你是程序员是不是侮辱你了?”我挺诧异,程序员现在是很低端,很被人瞧不起的工作吗?或许 ...
- POJ 2246 Matrix Chain Multiplication(结构体+栈+模拟+矩阵相乘)
题意:给出矩阵相乘的表达式,让你计算需要的相乘次数,如果不能相乘,则输出error. 思路: 参考的网站连接:http://blog.csdn.net/wangjian8006/article/det ...
- MapReduce实现矩阵相乘
矩阵相乘能够查看百度百科的解释http://baike.baidu.com/view/2455255.htm?fr=aladdin 有a和b两个矩阵 a: 1 2 ...
随机推荐
- 网络通信IO的演变过程(一)(一个门外汉的理解)
以前从来不懂IO的底层,只知道一个大概,就是输入输出的管道怼到一起,然后就可以传输数据了. 最近看了周志垒老师的公开课后,醍醐灌顶. 所以做一个简单的记录. 0 计算机组成原理相关 0.1. 计算机的 ...
- 天脉2(ACoreOS653)操作系统学习01
天脉2(ACoreOS653)操作系统学习01 由于我的毕业设计涉及相关嵌入式操作系统,故最近学了学天脉2操作系统. 一.ARINC653标准 1.ARINC653标准是什么? ARINC 653 : ...
- OO_JAVA_表达式求导_单元总结
OO_JAVA_表达式求导_单元总结 这里引用个链接,是我写的另一份博客,讲的是设计层面的问题,下面主要是对自己代码的单元总结. 程序分析 (1)基于度量来分析自己的程序结构 第一次作业 程序结构大致 ...
- Vue报错 type check failed for prop “xxx“. Expected String with value “xx“,got Number with value ‘xx‘
vue报错 [Vue warn]: Invalid prop: type check failed for prop "name". Expected String with ...
- Intellij IDEA 2021.2.3 最新版免费激活教程(可激活至 2099 年,亲测有效)
申明,本教程 Intellij IDEA 最新版破解.激活码均收集与网络,请勿商用,仅供个人学习使用,如有侵权,请联系作者删除.如条件允许,建议大家购买正版. 本教程更新于:2021 年 10 月 ...
- poj 2724 Purifying Machine(二分图最大匹配)
题意: 有2^N块奶酪,编号为00...0到11..1. 有一台机器,有N个开关.每个开关可以置0或置1,或者置*.但是规定N个开关中最多只能有一个开关置*. 一旦打开机器的开关,机器将根据N个开关的 ...
- C#写TXT文档
//C#写TXT文档 String strDir = System.IO.Path.GetDirectoryName(System.Reflection.Assembly.GetExecutingAs ...
- k8s入坑之路(13)服务迁移(定时任务 微服务 传统服务)
定时任务迁移kubernetes 服务迁移步骤 1.安装好java 2.安装好maven 项目打包 mvn package 测试传参运行 java -cp cronjob-demo-1.0-SNAPS ...
- Oracle SQL注入 总结
0x00 Oracle基础 Oracle 基本使用 什么是Oracle数据库? Oracle公司目前是世界上最大的软件提供商之一,与它并列的还有 Microsoft与 Adode.并且随着 Oracl ...
- IDEA中Update resources和Update classes and resources、Redeploy、Restart server的区别
选项 描述 update resources 所有更改的资源都会更新(HTML,JSP,JavaScript,CSS和图像文件) update classes and resources 更改的资源将 ...