机器学习算法中的评价指标(准确率、召回率、F值、ROC、AUC等)
参考链接:https://www.cnblogs.com/Zhi-Z/p/8728168.html
具体更详细的可以查阅周志华的西瓜书第二章,写的非常详细~
一、机器学习性能评估指标
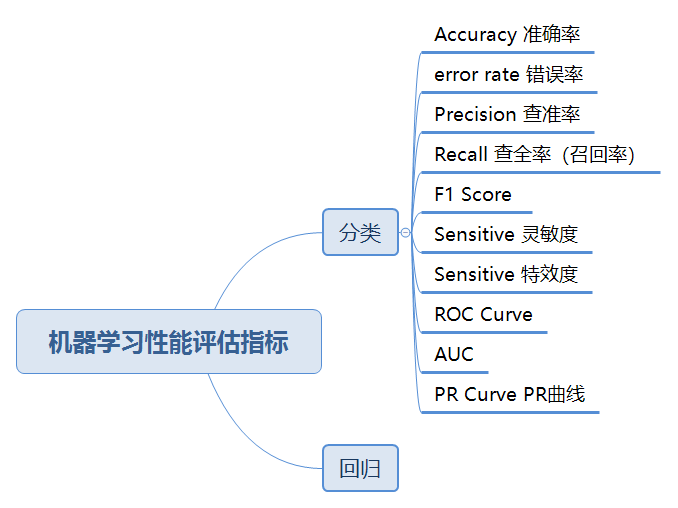
1.准确率(Accurary)
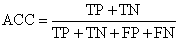
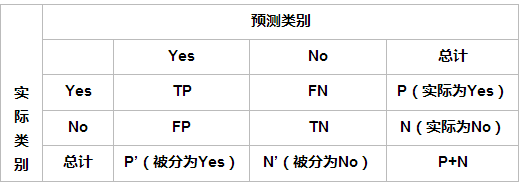
准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
准确率确实是一个很好很直观的评价指标,但是有时候准确率高并不能代表一个算法就好。比如某个地区某天地震的预测,假设我们有一堆的特征作为地震分类的属性,类别只有两个:0:不发生地震、1:发生地震。一个不加思考的分类器,对每一个测试用例都将类别划分为0,那那么它就可能达到99%的准确率,但真的地震来临时,这个分类器毫无察觉,这个分类带来的损失是巨大的。为什么99%的准确率的分类器却不是我们想要的,因为这里数据分布不均衡,类别1的数据太少,完全错分类别1依然可以达到很高的准确率却忽视了我们关注的东西。再举个例子说明下。在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。
2、错误率(Error rate)
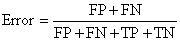
错误率则与准确率相反,描述被分类器错分的比例,对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
3、查准率(Precision)
查准率(precision)定义为: 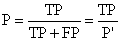
表示被分为正例的示例中实际为正例的比例。
4、查全率(召回率)(recall)
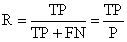
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
5、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。 F-Measure是Precision和Recall加权调和平均:
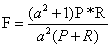
当参数α=1时,就是最常见的F1,也即 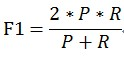
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
6、灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
7、特效度(sensitive)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
8、其他评价指标
8.1 ROC曲线
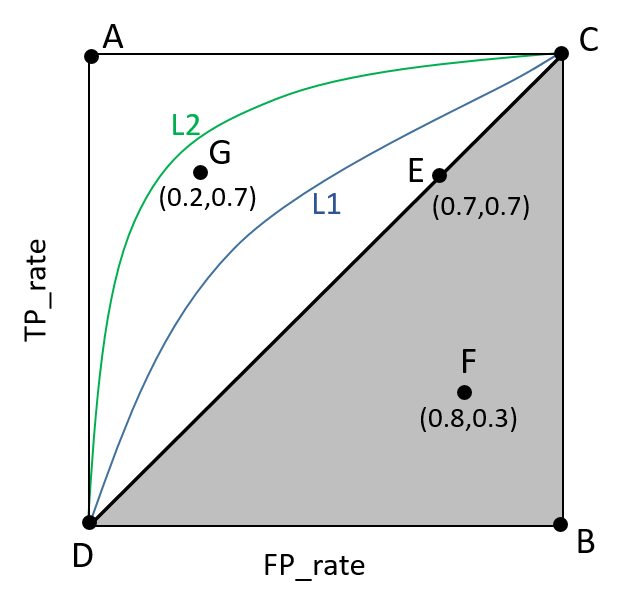
ROC(Receiver Operating Characteristic)曲线是以假正率(FP_rate)和真正率(TP_rate)为轴的曲线,ROC曲线下面的面积我们叫做AUC,如下图所示
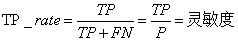 ,
,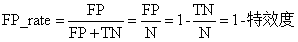
(1)曲线与FP_rate轴围成的面积(记作AUC)越大,说明性能越好,即图上L2曲线对应的性能优于曲线L1对应的性能。即:曲线越靠近A点(左上方)性能越好,曲线越靠近B点(右下方)曲线性能越差。
(2)A点是最完美的performance点,B处是性能最差点。
(3)位于C-D线上的点说明算法性能和random猜测是一样的,如C、D、E点;位于C-D之上(曲线位于白色的三角形内)说明算法性能优于随机猜测,如G点;位于C-D之下(曲线位于灰色的三角形内)说明算法性能差于随机猜测,如F点。
(4)虽然ROC曲线相比较于Precision和Recall等衡量指标更加合理,但是其在高不平衡数据条件下的的表现仍然不能够很好的展示实际情况。
8.2、PR曲线:
即,PR(Precision-Recall),以查全率为横坐标,以查准率为纵坐标的曲线。
举个例子(例子来自Paper:Learning from eImbalanced Data):
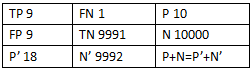
假设N>>P(即Negative的数量远远大于Positive的数量),就算有较多N的sample被预测为P,即FP较大为9,但是由于N很大,FP_rate的值仍然可以很小0.9%,TP_rate=90%(如果利用ROC曲线则会判断其性能很好,但是实际上其性能并不好),但是如果利用PR,P=50%,R=90%,因此在极度不平衡的数据下(Positive的样本较少),PR曲线可能比ROC曲线更实用。
机器学习算法中的评价指标(准确率、召回率、F值、ROC、AUC等)的更多相关文章
- 准确率,召回率,F值,ROC,AUC
度量表 1.准确率 (presion) p=TPTP+FP 理解为你预测对的正例数占你预测正例总量的比率,假设实际有90个正例,10个负例,你预测80(75+,5-)个正例,20(15+,5-)个负例 ...
- 机器学习笔记--classification_report&精确度/召回率/F1值
https://blog.csdn.net/akadiao/article/details/78788864 准确率=正确数/预测正确数=P 召回率=正确数/真实正确数=R F1 F1值是精确度和召回 ...
- 机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)
摘要: 数据挖掘.机器学习和推荐系统中的评测指标—准确率(Precision).召回率(Recall).F值(F-Measure)简介. 引言: 在机器学习.数据挖掘.推荐系统完成建模之后,需要对模型 ...
- 机器学习算法中如何选取超参数:学习速率、正则项系数、minibatch size
机器学习算法中如何选取超参数:学习速率.正则项系数.minibatch size 本文是<Neural networks and deep learning>概览 中第三章的一部分,讲机器 ...
- 机器学习算法中怎样选取超參数:学习速率、正则项系数、minibatch size
本文是<Neural networks and deep learning>概览 中第三章的一部分,讲机器学习算法中,怎样选取初始的超參数的值.(本文会不断补充) 学习速率(learnin ...
- 查全率(召回率)、精度(准确率)和F值
文献中的recall rate(查全率或召回率) and precision(精度)是很重要的概念.可惜很多中文网站讲的我都稀里糊涂,只好用google查了个英文的,草翻如下:召回率和精度定义: 从一 ...
- 机器学习算法中的网格搜索GridSearch实现(以k-近邻算法参数寻最优为例)
机器学习算法参数的网格搜索实现: //2019.08.031.scikitlearn库中调用网格搜索的方法为:Grid search,它的搜索方式比较统一简单,其对于算法批判的标准比较复杂,是一种复合 ...
- 机器学习算法中的偏差-方差权衡(Bias-Variance Tradeoff)
简单的以下面曲线拟合例子来讲: 直线拟合后,相比原来的点偏差最大,最后一个图完全拟合了数据点偏差最小:但是拿第一个直线模型去预测未知数据,可能会相比最后一个模型更准确,因为最后一个模型过拟合了,即第一 ...
- 机器学习算法中GBDT和XGBOOST的区别有哪些
首先xgboost是Gradient Boosting的一种高效系统实现,并不是一种单一算法.xgboost里面的基学习器除了用tree(gbtree),也可用线性分类器(gblinear).而GBD ...
随机推荐
- 快速排序平均时间复杂度O(nlogn)的推导
快速排序作为随机算法的一种,不能通过常规方法来计算时间复杂度 wiki上有三种快排平均时间复杂度的分析,本文记录了一种推导方法. 先放快速排序的伪代码,便于回顾.参考 quicksort(int L, ...
- 动态代理中newProxyInstance中三个参数
JDK Proxy(代理对象): Proxy.newProxyInstance 方法的三个参数创建代理对象 增强 person对象 使用代理对象代替person 去执行 doCourt方法参数1 类 ...
- 第二周PTA笔记 均等笔+旋转骰子+两个日期相差天数
均等笔 n个人围成一圈,每人有ai支笔.每人可以向左右相邻的人传递笔,每人每次传递一支笔消耗的能量为1.求使所有人获得均等数量的笔的最小能量. 输入格式: 第一行一个整数n ,表示人的个数(30%的数 ...
- AsExpandable EF多条件查询
我个人学习新技术有一个方法,如果遇到问题会根据以前的经验来寻找一些类似的解决方法.有人会说,如果这个问题在你的学习或者工作生涯中都没有遇到过呢?很简单,通过搜索资料或查阅相关书籍学习别人的经验. 在如 ...
- React-Router基础(<HashRouter>)
<Router>使用URL(即window.location.hash)的哈希部分来保持UI与URL同步的A. 重要说明:哈希历史记录不支持location.key或location.st ...
- Django笔记&教程 2-4 视图常用
Django 自学笔记兼学习教程第2章第4节--视图常用 点击查看教程总目录 1 - shortcut 视图函数需要返回一个HttpResponse对象或者其子类对象. 不过很多时候直接手写建立一个H ...
- 基于EPPlus和NPOI实现的Excel导入导出
基于EPPlus和NPOI实现的Excel导入导出 CollapseNav.Net.Tool.Excel(NuGet地址) 太长不看 导入 excel 文件流将会转为 ExcelTestDto 类型的 ...
- Java是“值传递”还是“引用传递”?
本文是根据stackoverflow网站上的一道题目整理出来的. Java一直是"值传递"而不是引用传递.看一个例子: public class Main{ public stat ...
- HDU 5322 Hope
HDU 5322 Hope 考虑 $ dp[n] $ 表示 长度为 $ n $ 的所有排列的答案. 首先,对于一个排列来说,如果最大值在 $ i $ 位置,那么前 $ i - 1 $ 个数必然与 $ ...
- SR4R数据库:水稻4个SNP集的筛选及其应用
目录 前言 四个SNP集 hapmapSNPs tagSNPs fixedSNPs barcodeSNPs hapmapSNPs的指标统计 tagSNPs的群体结构验证 tagSNPs的遗传多样性 t ...