【Redis集群原理专题】分析一下相关的Redis集群模式下的脑裂问题!
技术格言
世界上并没有完美的程序,但是我们并不因此而沮丧,因为写程序就是一个不断追求完美的过程。
什么是脑裂
字面含义
首先,脑裂从字面上理解就是脑袋裂开了,就是思想分家了,就是有了两个山头,就是有了两个主思想。
技术定义
在高可用集群中,当两台高可用服务器在指定的时间内,由于网络的原因无法互相检测到对方心跳而各自启动故障转移功能,取得了资源以及服务的所有权,而此时的两台高可用服务器对都还活着并作正常运行,这样就会导致同一个服务在两端同时启动而发生冲突的严重问题,最严重的就是两台主机同时占用一个VIP的地址(类似双端导入概念),当用户写入数据的时候可能会分别写入到两端,这样可能会导致服务器两端的数据不一致或造成数据的丢失,这种情况就称为裂脑,也有的人称之为分区集群或者大脑垂直分隔,互相接管对方的资源,出现多个Master的情况,称为脑裂。
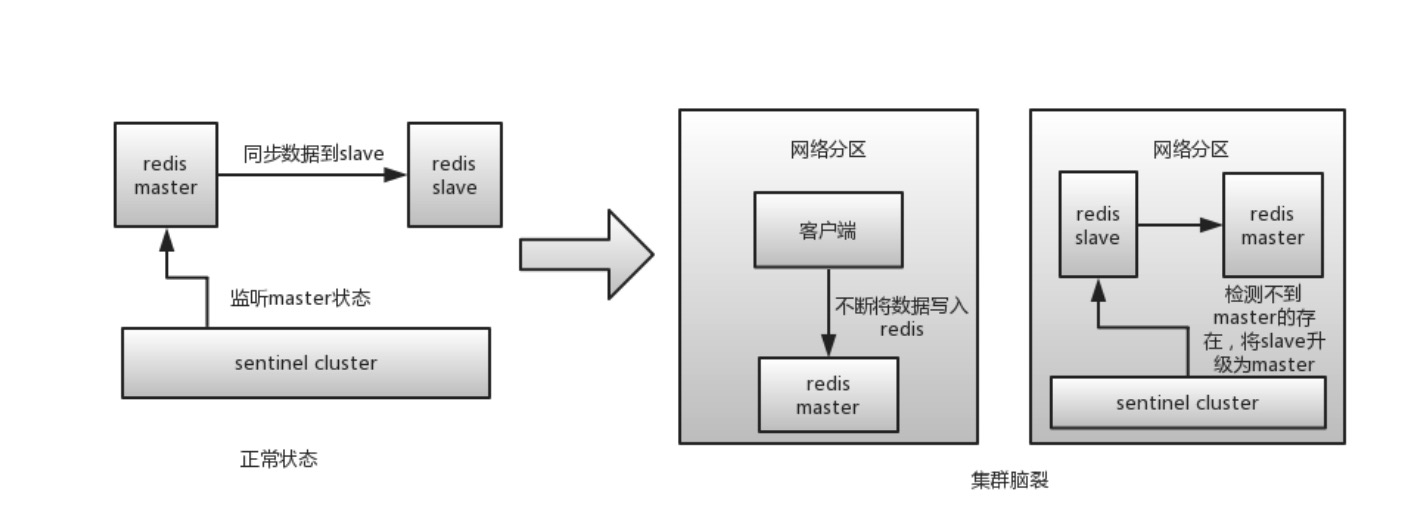
脑裂导致的问题
引起数据的不完整性:在集群节点出现脑裂的时候,如果外部无法判断哪个为主节点,脑裂的集群都可以正常访问的时候,这时候就会出现数据不完整的可能性。
- 服务异常:对外提供服务出现异常。
导致裂脑发生的原因
优先考虑心跳线路上的问题,在可能是心跳服务,软件层面的问题
1)高可用服务器对之间心跳线路故障,导致无法正常的通信。原因比如:
1——心跳线本身就坏了(包括断了,老化);
2——网卡以及相关驱动坏了,IP配置及冲突问题;
3——心跳线间连接的设备故障(交换机的故障或者是网卡的故障);
4——仲裁的服务器出现问题。
2)高可用服务器对上开启了防火墙阻挡了心跳消息的传输;
3)高可用服务器对上的心跳网卡地址等信息配置的不正确,导致发送心跳失败;
4)其他服务配置不当等原因,如心跳的方式不同,心跳广播冲突,软件出现了BUG等。
解决脑裂所出现的问题
添加冗余的心跳线,尽量减少“脑裂”的机会
启用磁盘锁:在发生脑裂的时候可以协调控制对资源的访问设置仲裁机制
实际的生产环境中,我们可以从以下几个方面来防止裂脑的发生:
1)同时使用串行电缆和以太网电缆连接,同时用两条心跳线路,这样一条线路坏了,另一个线路还是好的,依然能传送消息(推荐的)
2)检测到裂脑的时候强行的关闭一个心跳节点(需要特殊的节点支持,如stonith,fence),相当于程序上备节点发现心跳线故障,发送关机命令到主节点。
3)多节点集群中,可以通过增加仲裁的机制,确定谁该获得资源,这里面有几个参考的思路:
1——增加一个仲裁机制。例如设置参考的IP,当心跳完全断开的时候,2个节点各自都ping一下参考的IP,不同则表明断点就出现在本段,这样就主动放弃竞争,让能够ping通参考IP的一端去接管服务。
2——通过第三方软件仲裁谁该获得资源,这个在阿里有类似的软件应用
4)做好对裂脑的监控报警(如邮件以及手机短信等),在问题发生的时候能够人为的介入到仲裁,降低损失。当然,在实施高可用方案的时候,要根据业务的实际需求确定是否能够容忍这样的损失。对于一般的网站业务,这个损失是可控的(公司使用)
5)启用磁盘锁。正在服务一方锁住共享磁盘,脑裂发生的时候,让对方完全抢不走共享的磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的乙方不主动解锁,另一方就永远得不到共享磁盘。现实中介入服务节点突然死机或者崩溃,另一方就永远不可能执行解锁命令。后备节点也就截关不了共享的资源和应用服务。于是有人在HA中涉及了“智能”锁,正在服务的一方只在发现心跳线全部断开时才启用磁盘锁,平时就不上锁了
什么是redis脑裂?
如果在redis中,形式上就是有了两个master,记住两个master才是脑裂的前提。
哨兵(sentinel)模式下的脑裂
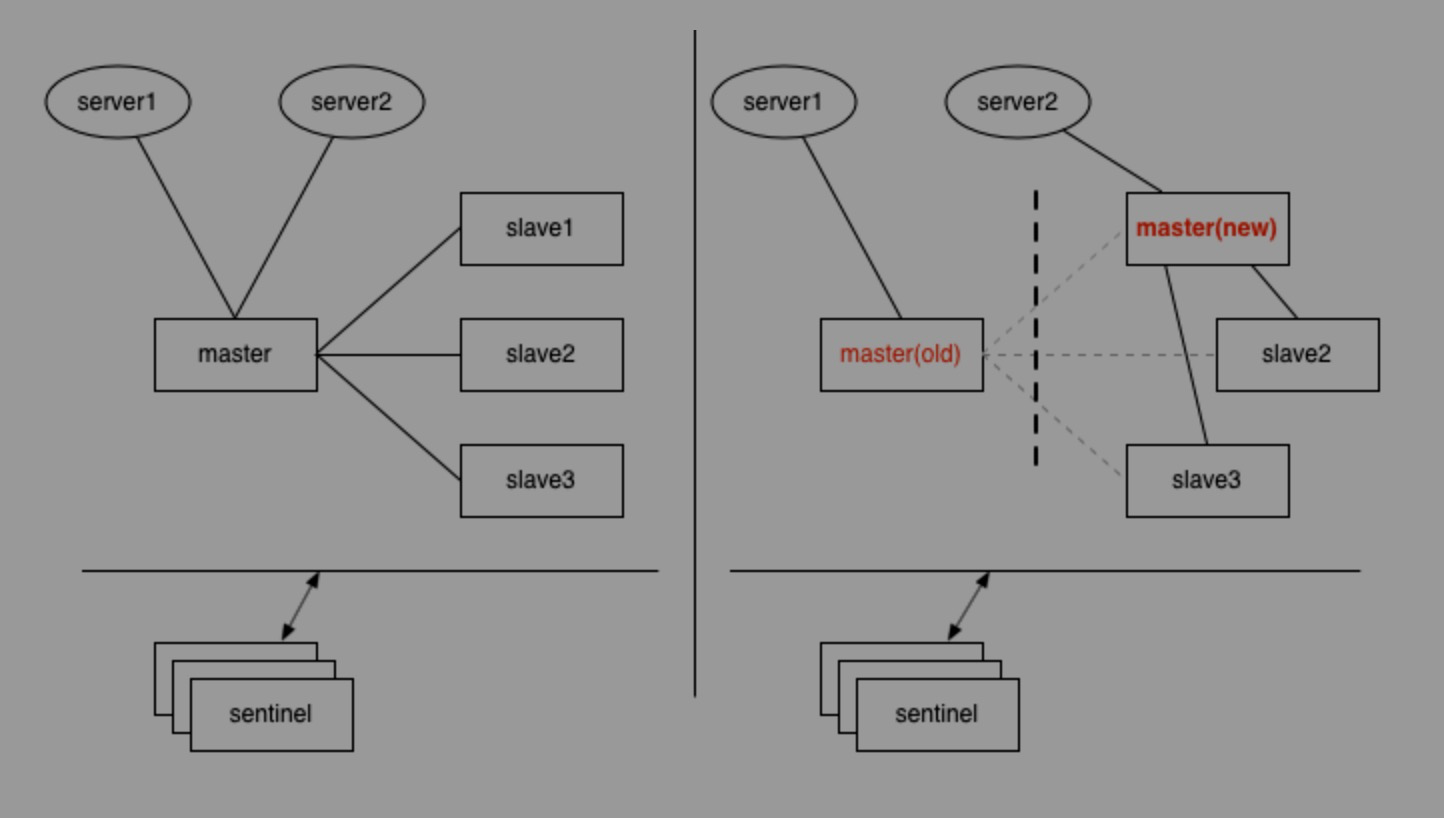
1个master与3个slave组成的哨兵模式(哨兵独立部署于其它机器),刚开始时,2个应用服务器server1、server2都连接在master上,如果master与slave及哨兵之间的网络发生故障,但是哨兵与slave之间通讯正常,这时3个slave其中1个经过哨兵投票后,提升为新master,如果恰好此时server1仍然连接的是旧的master,而server2连接到了新的master上。
数据就不一致了,基于setNX指令的分布式锁,可能会拿到相同的锁;基于incr生成的全局唯一id,也可能出现重复。
集群(cluster)模式下的脑裂
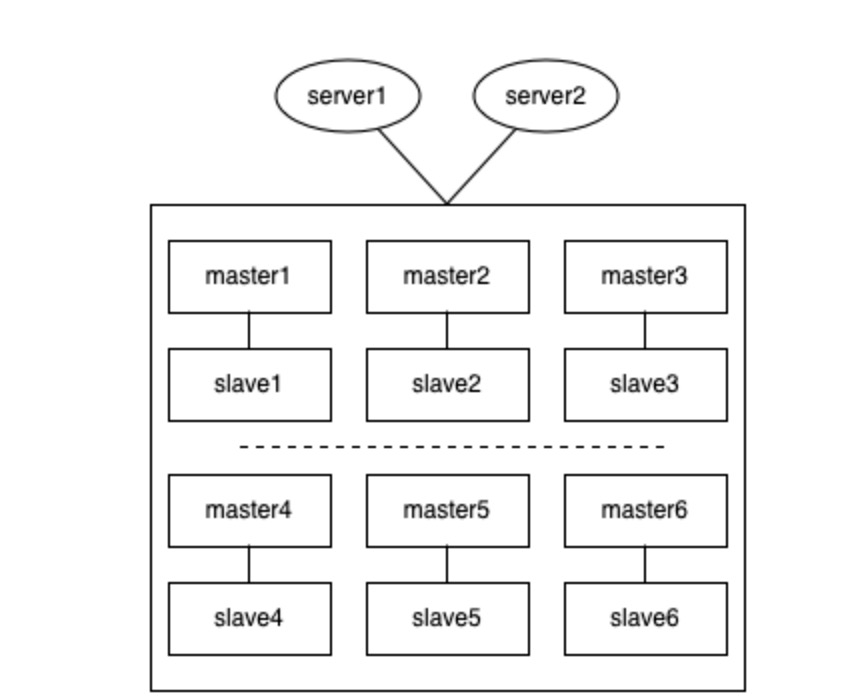
cluster模式下,这种情况要更复杂,例如集群中有6组分片,每给分片节点都有1主1从,如果出现网络分区时,各种节点之间的分区组合都有可能。
手动解决问题
在正常情况下,如果master挂了,那么写入就会失败,如果是手动解决,那么人为会检测master以及slave的网络状况,然后视情况,如果是master挂了,重启master,如果是master与slave之间的连接断了,可以调试网络,这样虽然麻烦,但是是可以保证只有一个master的,所以只要认真负责,不会出现脑裂。
自动解决问题
Redis中有一个哨兵机制,哨兵机制的作用就是通过redis哨兵来检测redis服务的状态,如果一旦发现master挂了,就在slave中选举新的master节点以实现故障自动转移。
问题,就出现在这个自动故障转移上,如果是哨兵和slave同时与master断了联系,即哨兵可以监测到slave,但是监测不到master,而master虽然连接不上slave和哨兵,但是还是在正常运行,这样如果哨兵因为监测不到master,认为它挂了,会在slave中选举新的master,而有一部分应用仍然与旧的master交互。当旧的master与新的master重新建立连接,旧的master会同步新的master中的数据,而旧的master中的数据就会丢失。所以我认为redis脑裂就是自动故障转移造成的。
总结梳理解决方案
如何解决脑裂?
设置每个master限制slave的数量
redis的配置文件中,存在两个参数
min-slaves-to-write 3
min-slaves-max-lag 10
- 第一个参数表示连接到master的最少slave数量
- 第二个参数表示slave连接到master的最大延迟时间
按照上面的配置,要求至少3个slave节点,且数据复制和同步的延迟不能超过10秒,否则的话master就会拒绝写请求,配置了这两个参数之后,如果发生集群脑裂,原先的master节点接收到客户端的写入请求会拒绝,就可以减少数据同步之后的数据丢失。
注意:较新版本的redis.conf文件中的参数变成了
min-replicas-to-write 3
min-replicas-max-lag 10
redis中的异步复制情况下的数据丢失问题也能使用这两个参数
总结
官方文档所言,redis并不能保证强一致性(Redis Cluster is not able to guarantee strong consistency. / In general Redis + Sentinel as a whole are a an eventually consistent system) 对于要求强一致性的应用,更应该倾向于相信RDBMS(传统关系型数据库)。
【Redis集群原理专题】分析一下相关的Redis集群模式下的脑裂问题!的更多相关文章
- 5.如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍一下么?redis 的哨兵原理能介绍一下么?
作者:中华石杉 面试题 如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍一下么?redis 的哨兵原理能介绍一下么? 面试官心理分析 其实问这个问题,主要是考考你,redis ...
- redis 脑裂等极端情况分析
脑裂真的是一个很头疼的问题(ps: 脑袋都裂开了,能不疼吗?),看下面的图: 一.哨兵(sentinel)模式下的脑裂 如上图,1个master与3个slave组成的哨兵模式(哨兵独立部署于其它机器) ...
- 支撑微博亿级社交平台,小白也能玩转Redis集群(原理篇)
Redis作为一款性能优异的内存数据库,支撑着微博亿级社交平台,也成为很多互联网公司的标配.这里将以Redis Cluster集群为核心,基于最新的Redis5版本,从原理再到实战,玩转Redis集群 ...
- Zookeeper集群的"脑裂"问题处理 - 运维总结
关于集群中的"脑裂"问题,之前已经在这里详细介绍过,下面重点说下Zookeeper脑裂问题的处理办法.ooKeeper是用来协调(同步)分布式进程的服务,提供了一个简单高性能的协调 ...
- Zookeeper集群"脑裂"问题 - 运维总结
关于集群中的"脑裂"问题,之前已经在这里详细介绍过,下面重点说下Zookeeper脑裂问题的处理办法.ooKeeper是用来协调(同步)分布式进程的服务,提供了一个简单高性能的协调 ...
- Android平台dalvik模式下java Hook框架ddi的分析(2)--dex文件的注入和调用
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/77942585 前面的博客<Android平台dalvik模式下java Ho ...
- DEBUG模式下, 内存中的变量地址分析
测试函数的模板实现 /// @file my_template.h /// @brief 测试数据类型用的模板实现 #ifndef MY_TEMPLATE_H_2016_0123_1226 #defi ...
- 一文轻松搞懂redis集群原理及搭建与使用
今天早上由于zookeeper和redis集群不在同一虚拟机导致出了点很小错误(人为),所以这里总结一下redis集群的搭建以便日后所需同时也希望能对你有所帮助. 笔主这里使用的是Centos7.如果 ...
- redis 哨兵集群原理及部署
复制粘贴自: https://www.cnblogs.com/kevingrace/p/9004460.html 请点击此链接查看原文. 仅供本人学习参考, 如有侵权, 请联系删除, 多谢! Redi ...
随机推荐
- camera isp(Image Signal Processor)
1. 目标[52RD.com] 手机摄像头模组用ISP功能模块的市场走向及研发方向.为能够正确认识手机摄像模组行业提供技术及市场依据.[52RD.com] 2. ISP在模组上的应用原理[52RD.c ...
- mipi csi接口,1条lane支持多少像素,200w像素需要几条lane,为什么,怎么计算出来的?谢谢!
按帧频FRAME=60HZ, 分辨率480*800来计算;以WVGA 显示分辨率,24BIT图片,60幁为例,在理想状态下(未包含RGB信号前后肩宽度),总传输速率最小为:480*800*8BIT*3 ...
- 21.7.24 test
\(NOIP\) 模拟赛 考差了. T1签到题.注意存在字符串长度为0,不能直接模.\(100\rightarrow0\) 代码: #include<bits/stdc++.h> usin ...
- IDA*、操作打表、并行处理-The Rotation Game HDU - 1667
万恶之源 优秀题解 用文字终究难以穷尽代码的思想 思路 每次操作都有八种选择,相当于一棵每次延申八个子节点的搜索树,故搜索应该是一种方法.而这题要求求最少步数,我们就可以想到可以试试迭代加深搜索(但其 ...
- configure: error: invalid variable name: `'
今天在交叉编译一个编解码库的时候,出现一个莫名其妙的报错,一直找不到原因,后来无意中删除了一个空格,才发现就是这个空格造成的错误. ./configure --host=arm-linux LDFLA ...
- 斐波那契数列 牛客网 剑指Offer
斐波那契数列 牛客网 剑指Offer 题目描述 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0). n<=39 class Solution: ...
- Ubuntu virtualenv 创建 python2 虚拟环境 激活 退出
首先默认安装了virtualenv 创建python2虚拟环境 your-name@node-name:~/virtual_env$ virtualenv -p /usr/bin/python2 py ...
- hdu 5166 Missing number(。。。)
题意: 有一个排列,但少了两个数.给你少了这两个数的排列.找出是哪两个数. 思路: 看代码,,, 代码: int a[1005]; int main(){ int T; cin>>T; w ...
- Spring一套全通—工厂
百知教育 - Spring系列课程 - 工厂 第一章 引言 1. EJB存在的问题 2. 什么是Spring Spring是一个轻量级的JavaEE解决方案,整合众多优秀的设计模式 轻量级 1. 对于 ...
- [bzoj1122]账本
简化问题:如果没有2操作,答案是多少贪心:修改-一定修改最前面的,修改+一定修改最后面的,正确性显然而通过1操作,要完成两步:1.让最终结果为q:2.让前缀和非负,通过贪心可以获得最小值(具体来说,假 ...