MapReduce03 框架原理InputFormat数据输入
MapReduce 框架原理
1.InputFormat可以对Mapper的输入进行控制
2.Reducer阶段会主动拉取Mapper阶段处理完的数据
3.Shuffle可以对数据进行排序、分区、压缩、合并,核心部分。
4.OutPutFomat可以对Reducer的输出进行控制
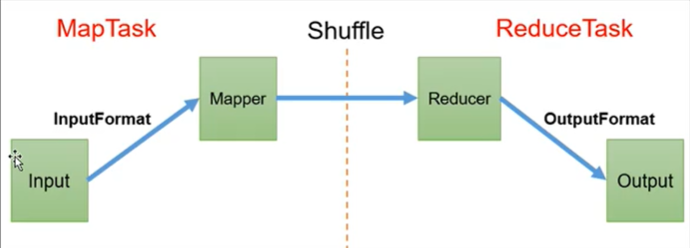
1 InputFormat数据输入
1.1 切片与MapTask并行度决定机制
MapTask:负责 Map 阶段的整个数据处理流程。
MapTask进程对每一个<K,V>调用一次map()方法
MapTask并行度:一次用几个MapTask进程对数据进行处理
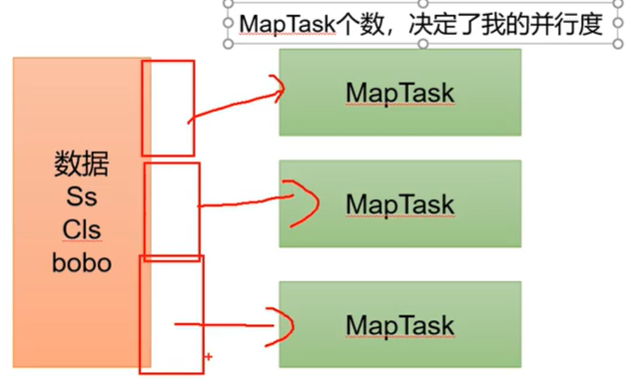
问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进行影响整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。
MapTask的个数是越多越好吗?不是,根据数据的大小决定。不然开启的MapTask的时间比处理数据的时间还长
哪些因素会影响MapTask并行度?
MapTask并行度决定机制
数据块:Block是HFDS物理上把数据分成一块一块。数据块是HDFS存储数据单位
数据切片:只是在逻辑上对输入进行分片,并不会在磁盘上讲其切分粗存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask
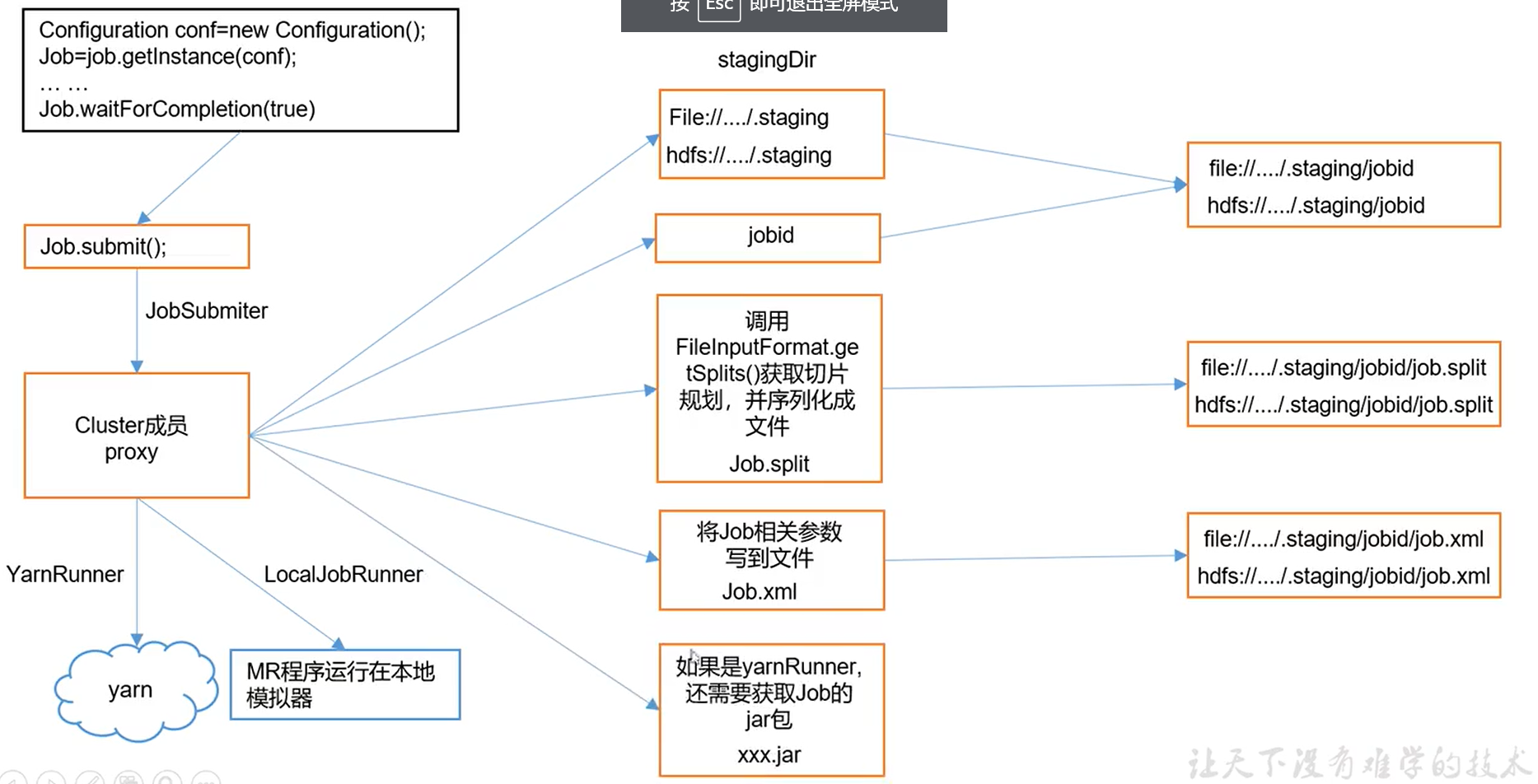
Job提交流程源码
添加断点,开始debug
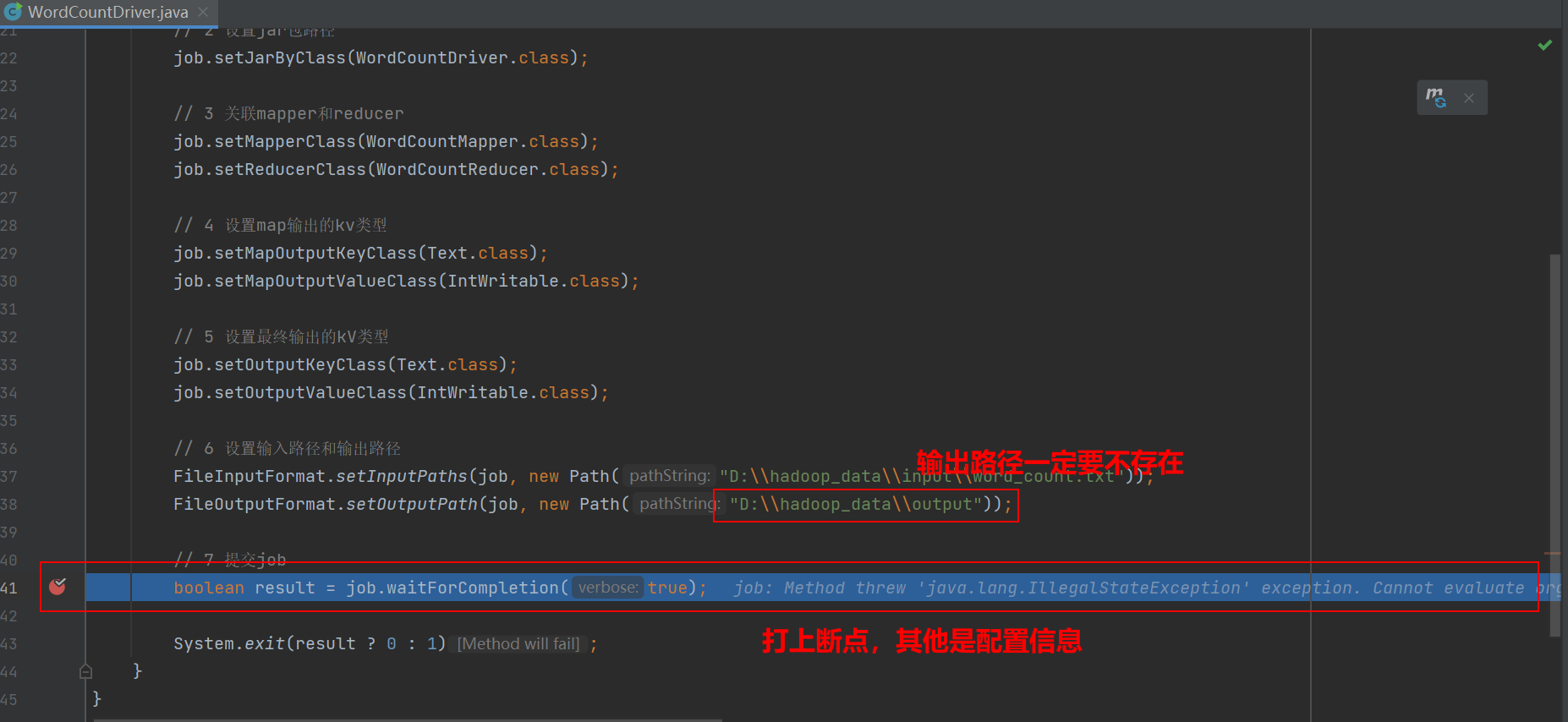
进入waitForCompletion()方法
先执行一行到submit()方法,再进入submit()方法
这个submit()方法就是我们需要关注的地方
waitForCompletion()
submit();
// 1 建立连接
connect();
// 1)创建提交 Job 的代理
new Cluster(getConfiguration());
// (1)判断是本地运行环境还是 yarn 集群运行环境
initialize(jobTrackAddr, conf);
// 2 提交 job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的 Stag 路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)获取 jobid ,并创建 Job 路径
JobID jobId = submitClient.getNewJobID();
// 3)拷贝 jar 包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片规划文件,向stag路径写切片文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向 Stag 路径写 XML 配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交 Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(),job.getCredentials());
断点1:连接客户端,有Yarn客户端和本地客户端YarnClinetProtocolProvide@1832、LocalClinetProtocolProvide@1888
断点2:向集群提交job信息,提交的内容:1.整个job运行需要的参数信息.xml 2.切片信息 3.jar包 如果是本地,不会提交jar包。如果是集群模式会提交jar包。
提交完之后,jobState变成了RUNNING,后面监控并打印job信息,提交完毕删除缓存信息(切片信息与该job需要的参数信息)
切片源码
每个文件都会单独切片。切割之前先确定文件是否可以切割。
切片的大小
块的大小是不变的,通过改变另外两个变量的大小改变切片大小
//默认值 :minSize=1 maxSize=long类型的最大值
long splitSize = computeSplitSize(blockSize,minSize,maxSize);
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))
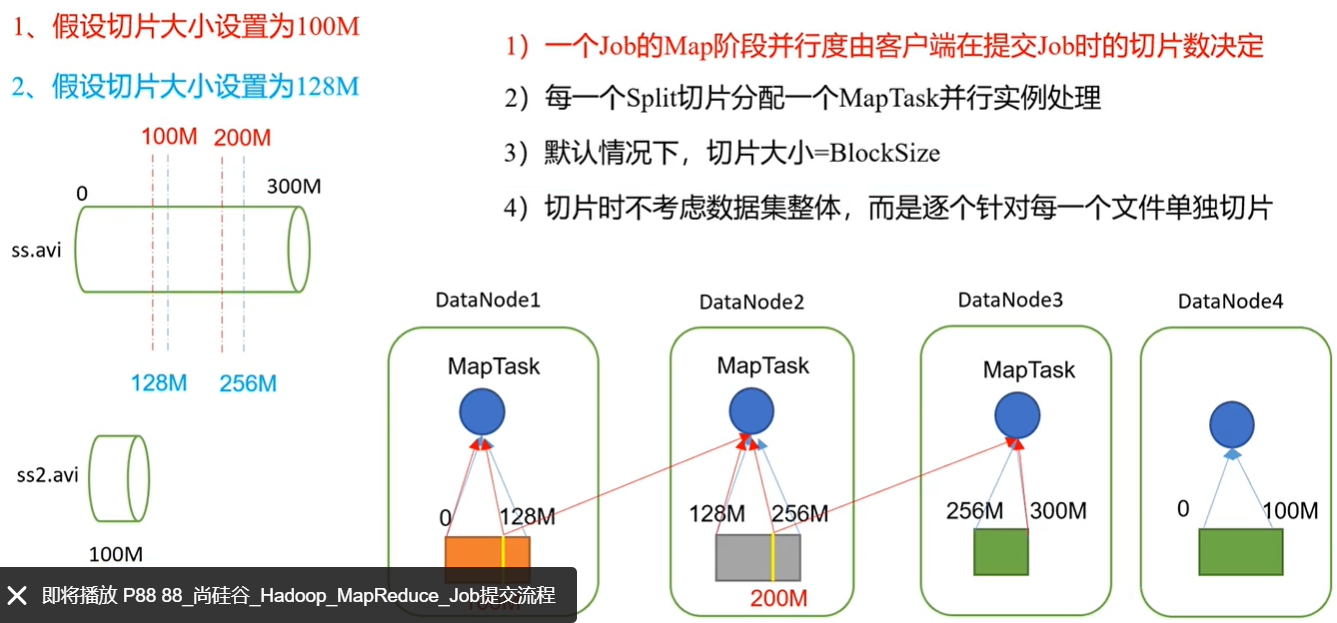
切片的大小如果在本地默认是32M,那么32.1的文件需要切成两片吗?不需要,1.1倍的膨胀范围。0.11.1<321.1,所以切一片就行了。
1.2 FileInputFormat切片机制
1.简单地按照文件的内容长度进行切片
2.切片大小,默认等于BlockSize大小
3.切片时不考虑数据集整体,逐个针对每个文件进行切片

切片流程
- 程序先找到输入的数据目录
- 开始遍历处理目录下的每一个文件,对每一个文件进行单独的切片(FileInputformat切片规则)
- 遍历第一个文件ranan.txt
3.1 获取文件大小fs.sizeOf(ranan.txt)
3.2 计算切片大小
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))
3.3 默认情况下切片大小=块大小
3.4 每次切片时,需要判断剩下的部分是不是大于块的1.1倍,大于就再继续切片,小于剩下的部分就是一块。(源码知识点)
3.5 将切片信息写到一个切片规划文件中
3.6 整个切片的核心过程在getSplit()方法中完成
3.7 InputSplit只记录了切片的元数据信息,比如起始位置、长度,以及所在的节点列表等。逻辑切片 - 提交切片规划文件到YARN上(Job提交),YARN上的MrAppMaster就可以根据切片规划文件计算开启的MapTask个数
1.3 TextInputFormat切片机制
TextInputFormat是FileInputFormat的实现类。输入的key是偏移量,value是一行内容
- FileInputFormat
- TextInputFormat 默认实现类
- CombineFileInputFormat
- CombineTextInputFormat
- NLineInputFormat
思考
在运行MapReduce程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。那么针对不同的数据类型,MapReduce是如何读取这些数据的呢?
FileInputFormat常见的接口实现类包括:TextInputFormat、keyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。
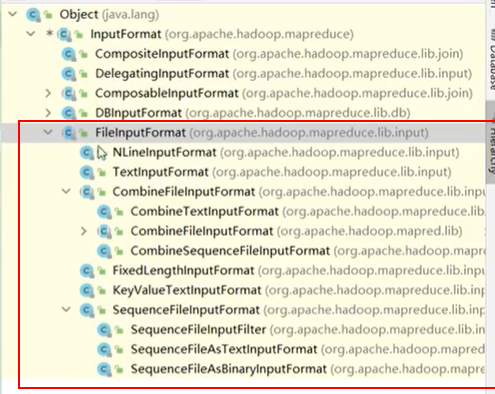
//输入是偏移量,输出是每行内容
class TextInputFormat extends FileInputFormat<LongWritable,Text>
//按分隔符切,左边的是key右边的是value
class KeyValueTextInputFormat extends FileInputFormat<Text,Text>
//一次性读取多行统一处理
class NLineInputFormat extends FileInputFormat<LongWritable,Text>
//一次读取多个文件,一起处理
class CombineTextInputFormat extends CombineFileInputmat<LongWritable,Text>
1.4 CombineTextInputFormat切片机制
应用场景
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,如果有大量的小文件,就会产生多个MapTask,处理效率极其低下。
用于小文件多的场景,可以将多个小文件从逻辑上规划到一个切片种,这样就只用开启一个MapTask处理。
虚拟存储切片最大值设置
虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
//4m
CombineTextInputFormat.setMaxInputSplitSize(job,4194304)
最终存储文件的顺序按文件名称的字典顺序排序

1.5 案例实操
需求
将输入的小文件合并成一个切片处理
输入数据D:\hadoop_data\input\inputcombinetextinputformat
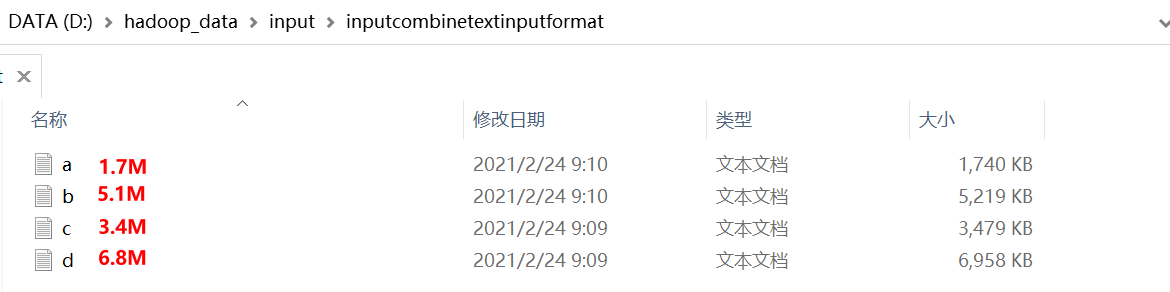
期望:期望一个切片处理4个文件
实现过程
1.使用之前的WordCount程序,观察到切片数个数为4
新建combinetextinputformat包,复制之前的WordCount程序
修改WordCountDriver的输入路径,其余不做修改。
没有修改切片规则,默认按照TextInputFormat切片规则切片,对每一个文件单独切片
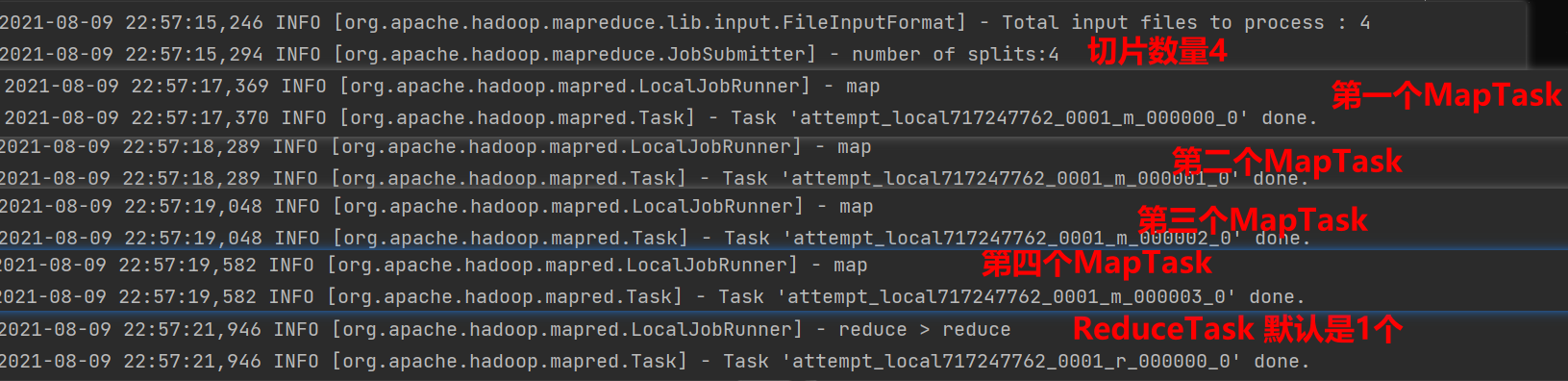
2.在WordCountDriver种增加如下代码,观察到切片个数为3
// 如果不设置 InputFormat,它默认用的是 TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//虚拟存储切片最大值设置 4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
3.在WordCountDriver种增加如下代码,观察到切片个数为1
// 如果不设置 InputFormat,它默认用的是 TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//虚拟存储切片最大值设置 20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
MapReduce03 框架原理InputFormat数据输入的更多相关文章
- MapReduce框架原理-InputFormat数据输入
InputFormat简介 InputFormat:管控MR程序文件输入到Mapper阶段,主要做两项操作:怎么去切片?怎么将切片数据转换成键值对数据. InputFormat是一个抽象类,没有实现怎 ...
- 模拟Select-Options对象实现多项数据输入功能
模拟Select-Options对象实现多项数据输入功能 Select-Options对象可以同时输入多项值并将所输入数据存入内表以供程序使用,不过Select-Options的功能有一定的局限 ...
- Web 软件测试 Checklist 应用系列,第 1 部分: 数据输入
Web 软件测试 Checklist 应用系列,第 1 部分: 数据输入 本文为系列文章"Web 软件测试 Checklist 应用系列"中的第一篇.该系列文章旨在阐述 Check ...
- JAVA用户数据输入
数据输入 首先需要导入扫描仪 然后声明扫描仪 输出输入提示 接收用户数据的数据 输出用户数据的数据 实例: import java.util.Scanner; //导入扫描仪 public class ...
- Python学习教程(learning Python)--1.3 Python数据输入
多数应用程序都有数据输入语句,用于读入数据,和用户进行交互,在Python语言里,可以通过raw_input函数实现数据的从键盘读入数据操作. 基本语法结构:raw_input(prompt) 通常p ...
- 【C语言】-数据输入-scanf( )和getchar( )
格式化输入函数scanf( ) scanf( )功能: 按照指定的格式读入键盘上输入的若干个任意类型的数据,存入到argument参数所指向的内存单元,函数返回值为读入并赋给argument的数据个数 ...
- Java基础知识强化之IO流笔记57:数据输入输出流(操作基本数据类型)
1. 数据输入输出流(操作基本数据类型) (1)数据输入流:DataInputStream DataInputStream(InputStream in) (2)数据输出流:DataOutputStr ...
- ACM 关于数据输入加速
转载请注明出处:http://blog.csdn.net/a1dark 分析:我们都知道运行时间对我们来说很重要.有时候不惜用大量的内存去换取一点时间.有些人可能都比较关注这个问题.首先时间上:cin ...
- C语言数据输入与输出
1 概论 C语言提供了跨平台的数据输入输出函数scanf()和printf()函数,它们可以按照指定的格式来解析常见的数据类型,例如整数,浮点数,字符和字符串等等.数据输入的来源可以是文件,控制台以及 ...
随机推荐
- freeswitch的docker构建过程
概述 Docker是一个开源的应用容器引擎,可以让开发者打包应用以及依赖包到一个轻量级.可移植的容器中,并在任何安装有Docker的机器上运行. Docker 使你能够将应用程序与基础架构分开,从而可 ...
- 使用ssh连接到centos7中docker容器
任务: 使用ssh连接到centos7中docker容器 实验步骤: 实验环境搭建,详情请看上一篇. 因为docker中容器的ip通常来说是和真机以及centos7的ip不属于一个网段,因此直接访问是 ...
- 云知声 Atlas 超算平台: 基于 Fluid + Alluxio 的计算加速实践
Fluid 是云原生基金会 CNCF 下的云原生数据编排和加速项目,由南京大学.阿里云及 Alluxio 社区联合发起并开源.本文主要介绍云知声 Atlas 超算平台基于 Fluid + Alluxi ...
- log4j日志集成
一.介绍 Log4j是Apache的一个开放源代码项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台.文件.GUI组件.甚至是套接口服务 器.NT的事件记录器.UNIX Syslog ...
- Java测试开发--HttpClient常规用法(九)
1.HttpClient可以读取网页(HTTP/HTTPS)内容 2.对url发送get/post请求(带不带参数都可以),进行测试 一.maven项目pom.xml需要引入包 <depende ...
- JMeter学习笔记--并发登录测试
账号密码读取文件 1.设置线程数为30,并发用户量就是30个用户同时登录 2.添加同步定时器 添加 Synchronizing Timer 同步定时器,为了阻塞线程,当线程数达到指定数量,再同时释放, ...
- List<String>转List<Integer>
List<Integer> intList = strList.stream().map(Integer::parseInt).collect(Collectors.toList()); ...
- 不可忽视的Dubbo线程池
问题描述 线上突然出现Dubbo超时调用,时间刚好为Consumer端设置的超时时间. 有好几个不同的接口都报超时了 第1次调用超时,第2次(或第3次)重试调用非常快(正常水平) Dubbo调用超时的 ...
- Alpine容器安装运行ssh
写在前面 本文介绍了在Alpine容器(docker)上安装运行ssh并保证外界(宿主机)能通过ssh登录的方法,给出了相应的命令.在下在探索过程中借鉴了许多前人的经验,在此先行谢过,所有参考内容都会 ...
- go 错误处理设计思考
前段时间准备对线上一个golang系统服务进行内部开源,对代码里面的错误处理进行了一波优化. 优化的几个原因: 错误处理信息随意,未分类未定义.看到错误日志不能第一时间定位 错误的日志重复,有时候一个 ...