大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程
知识补充:RDD的依赖关系
RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency)
(1)窄依赖
窄依赖指的是父RDD中的一个分区最多只会被子RDD中的一个分区使用,意味着父RDD的一个分区内的数据是不能被分割的,子RDD的任务可以跟父RDD在同一个Executor一起执行,不需要经过Shuffle阶段去重组数据
窄依赖关系划分为两种:一对一依赖(OneToOneDependency)和范围依赖(RangeDependency)
- 一对一依赖
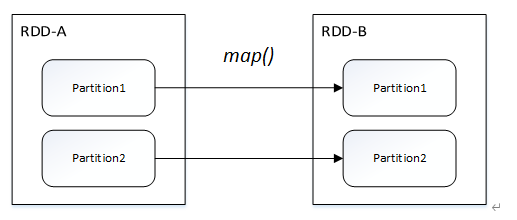
- 范围依赖
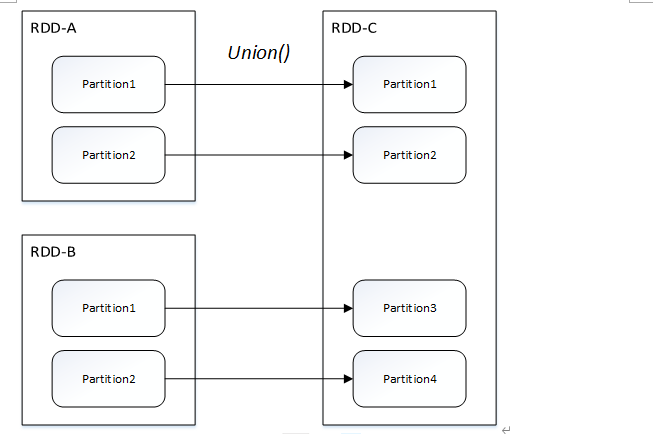
(2)宽依赖
指的是父RDD中的分区可能被多个子RDD分区使用。因为父RDD中一个分区内的数据会被分割,发送给子RDD的多个分区,因此宽依赖也意味着父RDD与子RDD之间存在着Shuffle过程
宽依赖只有一种:Shuffle依赖(ShuffleDependency)
什么是Shuffle:
父RDD的一个分区的数据,要给子RDD的多个分区,shuffle要有网络传输,但是有网络传输的,不一定就是shuflle
窄依赖每个 child RDD 的 partition 的生成操作都是可以并行的,而宽依赖则需要所有的 parent RDD partition shuffle 结果得到后再进行。
以join算子为例

父RDD一个分区中的数据,被分割发送给子RDD的不同分区,所以是宽依赖
特殊情况(同理其他算子)
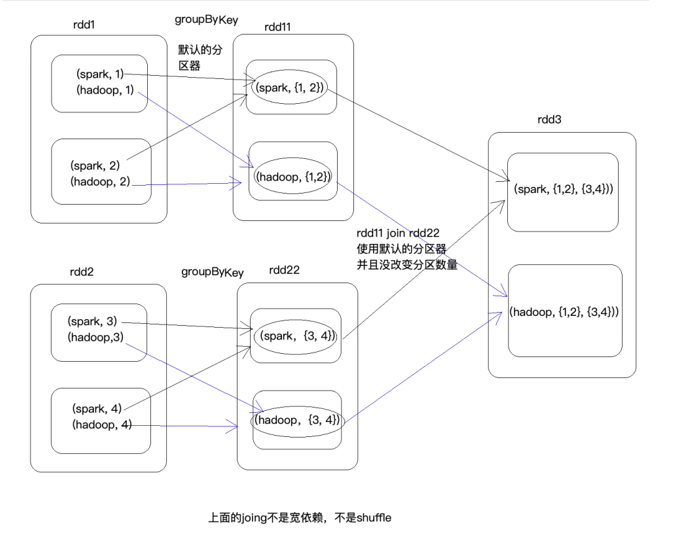
两个RDD使用相同的分区器,事先已经分完组或分好区了,在调用join,使用相同的分区,并且没有改变RDD的分区数量,那就就是窄依赖

3个stage
1.1 提交任务
spark-submit --master spark://feng05:7070 --executor-memory 1g --total-executor-cores 4 --class cn.51doit.spark.WordCount /root/wc.jar hdfs://feng05:9000/wc hdfs:/feng05:9000/out0
spark任务执行模式
- Client模式(默认):Driver是在SparkSubmit进程中,是在客户端
- Cluster模式:Driver是在集群中,不在SparkSubmit进程中
1.2 创建SparkContext
使用spark-submit脚本,会启动SparkSubmit进程,然后通过反射调用我们通过--class传入类的main方法。在main方法中,就是我们写的业务逻辑了,先创建SparkContext,向Master申请资源,然后Master跟worker通信,启动executor,然后所有的Executor向Driver反向注册。
1.3 创建RDD并构建DAG
DAG(Directed Acyclic Graph)叫做有向无环图,是一系列RDD转换关系的描述,原始的RDD通过一系列的转化就形成了DAG,然后根据RDD的依赖关系的不同将DAG划分为不同的stage。对于窄依赖,partition的转换处理在Stage中完成计算,没有stage的划分;对于宽依赖,由于有shuffle的存在,只能在parent RDD处理完后,才能开始接下来的计算,会有stage的划分,因此宽依赖是划分Stage的依据。
1.4 切分Stage,生成Task和TaskSet
1.5 将task序列化,调度到Executor中
1.6 executor将task反序列化,得到task,并在线程池中执行这个任务
2. Repartition和coalesce算子的区别
这两个算子都是用于重新分区的,Repartition底层调用的是coalesce,具体减员吗,如下
repartition源码

可见其底层调用的是coalesce,传入的shuffle系数为true
coalesce方法源码
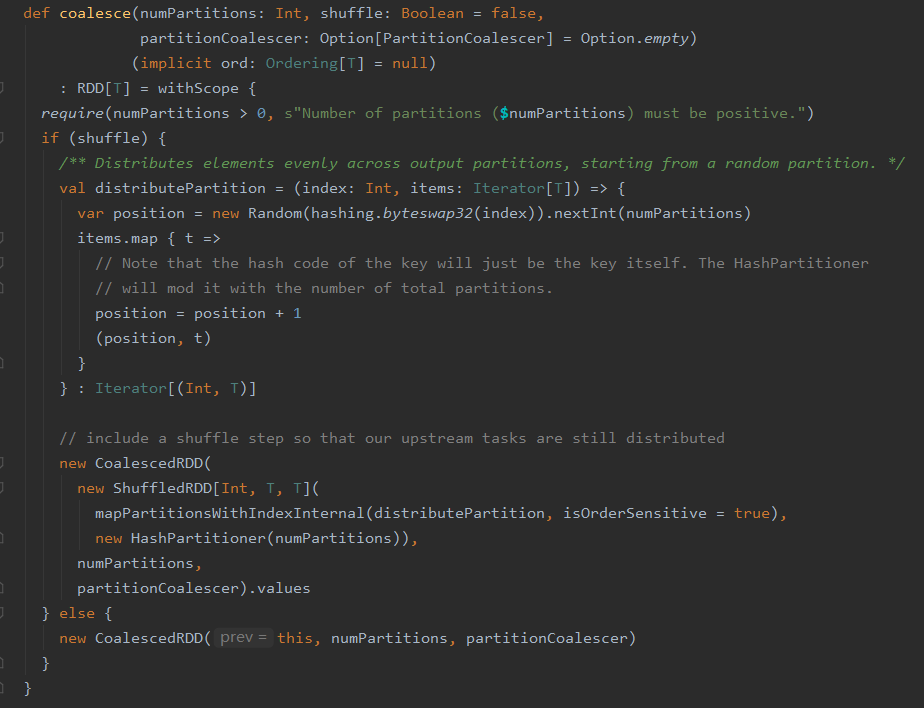
可见当shuffle参数为true时,创建的才是ShuffledRDD,当shuffle参数为false时,创建的是CoalescedRDD
由此不难得出结论:repartition间的父RDD和子RDD一定是宽依赖,Coalesce则不一定,视调用此方法的shuffle定。
3.触发多次actions,速度不一样
触发多次actions时,后触发的action会比前面触发的action快很多,这是为什么?
第一次shuffle时,结果会被溢写进磁盘(由blockmanger管理),后面可以复用这个结果
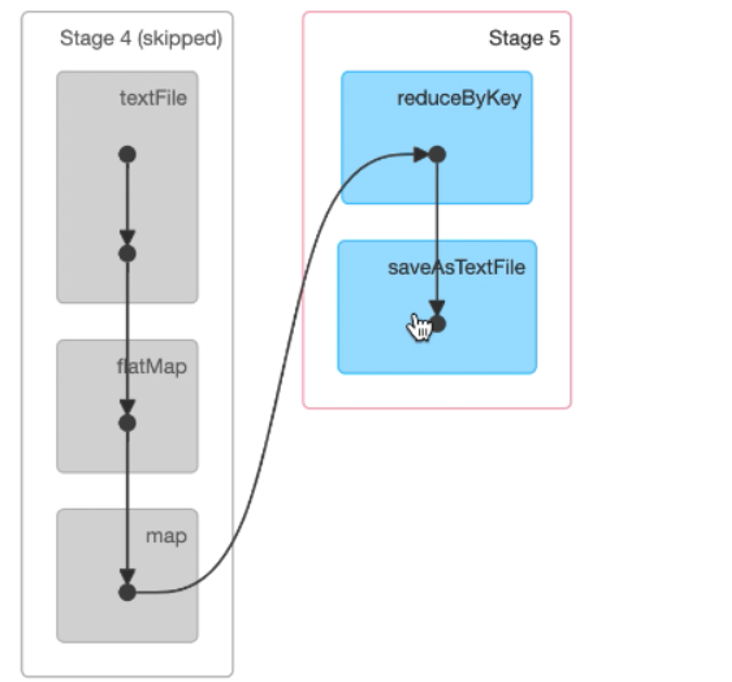
以上是第二次进行action的操作,左边灰色表示的是之前action操作时,相关数据被溢写入磁盘中,此处就直接复用这些结果。所以会很快。
4. RDD的的深入理解
4.1 重要总结
在刚开始学习Spark时,为了方便理解,可以把Spark的RDD就当成Scala的一个普通的集合使用,Scala集合的方法和RDD上的方法很多功能是类似(底层实现不一样)的,比如map、flatMap、filter、reduce等,但是Scala的集合是本地的集合,而RDD是一个抽象、分布式的集合,RDD可以实现分布在多台机器上数据的计算
RDD本身不装真正要计算的数据,RDD里面装的是数据的描述信息,描述了以后从哪里读取数据,对RDD进行哪些操作(调用了什么方法,传入了()什么函数),一旦触发Action,就会形成一个完整的DAG
在spark中,提交的应应⽤程序叫Application,⼀个Application中触发⼀次Action就提交⼀个Job(DAG),⼀个Job可以划分成⼀到多个Stage,⼀个Stage会⽣产多个Task(有⼏个分区就有⼏个Task),Task是Spark中最⼩的任务执⾏单元,在⽤⼀个Stage中,task的计算逻辑是⼀样的,只不过是计算的数据不⼀样。
Task是什么东西?Task就是⼀个java对象(实例),java对象中有属性和⽅法,属性:记录的描述信息(⽐如从哪⾥读取数据,读取哪个⽂件等)。⽅法:具体怎么计算(调⽤哪个算⼦、传⼊了什么函数)
Task是⼀个最小的执⾏单元,Task这个类不能我们⽤户⾃⼰实现,在Spark中,是根据RDD的转换关系(调⽤了哪个算⼦、传⼊了什么函数)⾃动⽣成的Task,这样⾮常的灵活
4.2 源码了解RDD是如何获取数据的(尝试,以map算子为例)
map
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f) //检测传入的函数能否被序列化,若函数中传入一个不能被序列化的引用数据类型就会报错(闭包单词:closure,进一步看源码会涉及)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
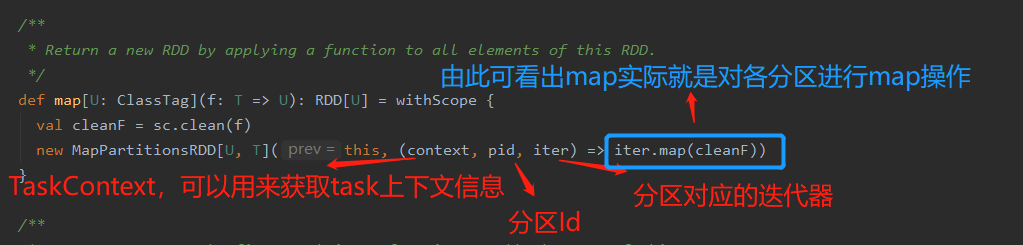
从此段代码可得到一个重要的信息:对RDD进行操作,本质上就是对每个分区进行操作
MapPartitionsRDD(部分)

当进一步点进iterator中去,会发现其返回的还是一个迭代器,源码如下
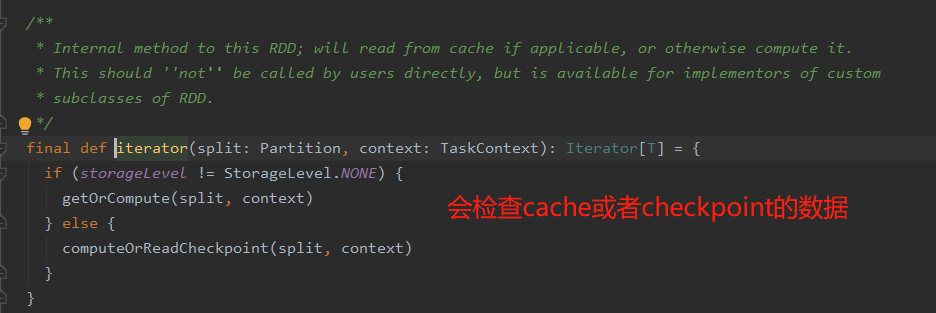
总结: 当触发Action算子时,ShuffleMapTask会进行shuffle准备,将数据通过shufflewrite写入磁盘,其过程为子RDD通过调用父RDD的迭代器获取父RDD的数据,父RDD又通过它的父RDD的迭代器获取父RDD的数据,以此类推,直到HadoopRDD。那么,Hadoop如何从HDFS获取数据的呢?通过网络迭代器从HDFS中拉取数据
4.3 RDD的典型错误例子
object BadStyle {
def main(args: Array[String]): Unit = {
//模式提交任务使用的是Client模式,SparkSubmit进程中包含SparkContext
val conf = new SparkConf().setAppName("BadStyle").setMaster("local[*]")
//Driver
val sc = new SparkContext(conf)
//Driver
val lines: RDD[String] = sc.textFile("/Users/star/Desktop/a.txt")
//Driver
val words: RDD[String] = lines.flatMap(_.split(" "))
//RDD是在Driver端创建的抽象集合
//调用的map方法也是在Driver端调用的
val result = words.map(w => {
//函数式在Executor中被执行的
//lines是RDD,RDD不能再Executor中
lines.map(l => w + l)
})
result.saveAsTextFile("/Users/star/Desktop/c")
println("Driver ############# ")
sc.stop()
println("Driver ############# 任务退出了")
}
}
RDD是在Driver端生成的,其不能在executor中,所以会报错,报错信息显示也是如此
改成如下就正确了
// 此代码在函数外
val count = lines.count()
// 此代码在函数内
w+count
5. Spark任务执行的经典问题
(1)SparkContext哪一端生成的?
Driver端(Driver是一个统称,DAGSchedule、TaskScheduler、BlockManager、ShuffleManager、BroadcastManager)
(2)DAG是在哪一端被构建的?
Driver端
(3)RDD是在哪一端生成的?
Driver端
(4)调用RDD的算子(Transformation和Action)是在哪一端调用的
Driver端
(5)RDD在调用Transformation和Action时需要传入一个函数,函数是在哪一端声明【定义】和传入的?
Driver端
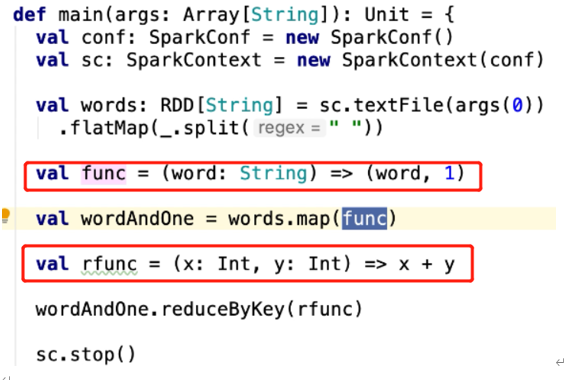
(6)RDD在调用Transformation和Action时需要传入函数,请问传入的函数是在哪一端执行了函数的业务逻辑?
Executor中的Task指定的
(7)Task是在哪一端生成的呢?
Driver端,Task分为ShuffleMapTask和ResultTask
(8)DAG是在哪一端构建好的并被切分成一到多个Stage的
Driver
(9)DAG是哪个类完成的切分Stage的功能?
DAGScheduler
(10)DAGScheduler将切分好的Task以什么样的形式给TaskScheduler
TaskSet
(11)13.自定义的分区器这个类是在哪一端实例化的?
Driver端
(12)分区器中的getParitition方法在哪一端调用的呢?
Executror中的Task
(13)广播变量是在哪一端调用的方法进行广播的?
Driver端
(14)要广播的数据应该在哪一端先创建好再广播呢?
Driver端
(15)广播变量以后能修改吗?
不能修改
(16)广播变量广播到Executor后,一个Executor进程中有几份广播变量的数据
一份全部的广播的数据
6. 购物的相关计算
日志数据样例(以下截取的是其中的一条数据(一行,但便于观看就改成如下形式)):

约定

5.1 小程序的PV,UV,用户的区域分布
ShopKpi(此处没有用bean来封装日志文件的各属性)
package com._51doit.spark06
import com.alibaba.fastjson.{JSON, JSONException, JSONObject}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ShopKpi {
def main(args: Array[String]): Unit = {
//模式提交任务使用的是Client模式,SparkSubmit进程中包含SparkContext
val conf = new SparkConf().setAppName("ShopKpi").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile("E:/javafile/spark/access-new.log")
// 计算pv(访问量)
val pv: Long = lines.count()
// 处理数据
val uidAndProvince: RDD[(String, String)] = lines.map(line => {
var openid: String = null
var province: String = null
var city: String = null
try {
val jsonObject: JSONObject = JSON.parseObject(line)
openid = jsonObject.getString("openid")
province = jsonObject.getString("province")
city = jsonObject.getString("city")
} catch {
case e: JSONException => {
// 处理错误的数据
}
}
if("北京市".equals(city)){
(openid, province)
} else{
(openid, province+city)
}
})
//过滤有问题的数据
val filteredRDD: RDD[(String, String)] = uidAndProvince.filter(t => t._1 != null && !t._1.equals(""))
filteredRDD.cache()
// 日活
val uv: Long = filteredRDD.keys.distinct().count()
// 用户的区域分布
val reduced: RDD[(String, Int)] = filteredRDD.distinct().map(t => (t._2, 1)).reduceByKey(_+_)
println(reduced.collect().toBuffer)
sc.stop()
}
}
补充
Json解析数据的两种形式
第一种(数据不封装到类中,用的时候直接获取):
val jsonObject: JSONObject = JSON.parseObject(line)
openid = jsonObject.getString("openid")
province = jsonObject.getString("province")
第二种(数据封装到bean中,一般使用这这种)
val logBeanRDD: RDD[LogBeanV2] = lines.map(line => {
var logBean: LogBeanV2 = null
try {
logBean = JSON.parseObject(line, classOf[LogBeanV2])
} catch {
case e: JSONException => {
logger.error("parse json exception, error line is : " + line)
}
}
logBean
})
//过滤订单相关的数据,支付成功的数据
val filtered: RDD[LogBeanV2] = logBeanRDD.filter(bean => bean != null && bean.pay_status == 1)
5.2 用户成交金额
5.3 计算各个省的成交金额
5.4 计算各个省下市成交金额的TopN
5.5 计算各个分类成交的TopN
5.6 计算复购率(比较难)
以上所有解如下
LogBeanV2(用于封装日志中的各个属性)
case class LogBeanV2(
page: String,
event_type: Int,
pay_status: Int,
oid: String,
goods: Array[Good],
total_money: Double,
longitude: Double,
latitude:Double,
province: String,
city: String
)
Good(用于封装LogBeanV2中goods属性中的值)
case class Good(
money: Double,
pid: String,
cid: String,
title: String
)
CalculateUtils(所有计算都被封装到次类中)
package cn._51doit.spark.day06
import java.sql.{Date, DriverManager}
import org.apache.spark.rdd.RDD
object CalculateUtils {
//计算复购率
//在一段时间之内,购买两次即以上的用户
def calculateReBuyRatio(filtered: RDD[LogBeanV2]) = {
val uidAndPayCounts = filtered.map(bean => {
val openid = bean.openid
val date = bean.time.split(" ")(0)
((date, openid), 1)
}).reduceByKey(_ + _)
//关联规则
val levelAndCounts = uidAndPayCounts.map(t => {
//根据用户的购买次数计算会员等级的规则
val level = LevelUtil.getLevel(t._2)
val date = t._1._1
((date, level), 1)
}).reduceByKey(_ + _)
//将日期当做Key
//[(2019-09-25, (L1, 5)), (2019-09-25, (L2-3, 3)), (2019-09-25, (L4-5, 4))]
val dateLevelAndCounts = levelAndCounts.map(t => (t._1._1, (t._1._2, t._2)))
//计算出某一天总的购买用户数量
//[{2019-09-25,12}, {2019-09-26,13}]
val datePayUser = uidAndPayCounts.map(t => {
(t._1._1, 1)
}).reduceByKey(_ + _)
//{2019-09-25 -> ((L2-3, 3), 12)}
val joined: RDD[(String, ((String, Int), Int))] = dateLevelAndCounts.join(datePayUser)
val results: RDD[(String, Iterable[(String, String, Double)])] = joined.map(t => {
val date = t._1
val level = t._2._1._1
val levelCouts = t._2._1._2
val totalUser = t._2._2
(date, level, levelCouts.toDouble / totalUser)
}).groupBy(_._1)
//{(2019-09-25, "L1", 0.6), (2019-09-25, "L4-5", 0.3) , (2019-09-25, "L2-3", 0.1)}
val resArr = results.collect()
//获取一个数据库连接
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123456")
val preparedStatement = connection.prepareStatement("INSERT INTO daily_repay_ratio (`dt`, `L1`, `L2-3`, `L4-5`, `L6+`) VALUES (?, ?, ?, ?, ?)")
resArr.foreach(t => {
val date = t._1
preparedStatement.setString(1, date)
//{(2019-09-25, "L1", 0.6), (2019-09-25, "L2-3", 0.1), (2019-09-25, "L4-5", 0.3)
val list = t._2.toList.sortBy(t => t._2)
for(e <- 0 until list.size) {
//val level = e._2
var tp: (String, String, Double) = (null, null, 0.0)
try {
tp = list(e)
} catch {
case e: Exception => {
}
}
preparedStatement.setDouble(e + 2, tp._3)
}
preparedStatement.executeUpdate()
})
preparedStatement.close()
connection.close()
}
def calculateProvicneAndCityIncomeTopN(filtered: RDD[LogBeanV2]) = {
val reduced: RDD[((String, String), Double)] = filtered.map(bean => {
val province = bean.province
val city = bean.city
val total_money = bean.total_money
((province, city), total_money)
}).reduceByKey(_ + _)
//按照省份进行分组
val result = reduced.groupBy(_._1._1).mapValues(it => it.toList.sortBy(-_._2).take(3))
//将结果写入到数据库
val r = result.collect()
val connection = DriverManager.getConnection("", "", "")
//将数据写入
connection.close()
}
def calculateCategoryIncome(filtered: RDD[LogBeanV2], categoryRDD: RDD[(Int, String)]) = {
val cidAndMoney = filtered.flatMap(bean => {
val goods = bean.goods
goods.map(g => {
val cid = g.cid
val money = g.money
(cid.toInt, money)
})
}).reduceByKey(_ + _)
//
val joined: RDD[(Int, (Double, String))] = cidAndMoney.join(categoryRDD)
val cnameAndMoney: RDD[(String, Double)] = joined.map(t => (t._2._2, t._2._1))
//将数据写入到数据库
cnameAndMoney.foreachPartition(it => {
//获取一个链接
val connection = DriverManager.getConnection("", "", "")
it.foreach(t => {
})
connection.close()
})
}
//计算省份成交金额
def calculateProvinceIncome(filtered: RDD[LogBeanV2]) = {
val provinceAndMoney = filtered.map(bean => {
val province = bean.province
val total_money = bean.total_money
(province, total_money)
}).reduceByKey(_ + _)
//假设数据量比较大,收集到Driver端后再写入,对Driver压力比较大并且写入的效率低
provinceAndMoney.foreachPartition(it => {
val connection = DriverManager.getConnection("", "", "")
val preparedStatement = connection.prepareStatement("INSERT INTO t_province_daily_income VALUES (?, ?, ?)")
it.foreach(t => {
preparedStatement.setDate(1, new Date(System.currentTimeMillis()))
preparedStatement.setString(2, t._1)
preparedStatement.setDouble(3, t._2)
preparedStatement.executeUpdate()
})
preparedStatement.close()
connection.close()
})
}
//计算总的成交金额
def calculateTotalIncome(filtered: RDD[LogBeanV2]) = {
//在Dirver端写入到MySQL中
//sum是一个Action,将计算好的结果收集回Driver
val totalIncome = filtered.map(_.total_money).sum()
//2019-09-26 1000000
//2019-09-27 1100000
val connection = DriverManager.getConnection("", "", "")
val preparedStatement = connection.prepareStatement("INSERT INTO t_daily_income VALUES (?, ?)")
preparedStatement.setDate(1, new Date(System.currentTimeMillis()))
preparedStatement.setDouble(2, totalIncome)
preparedStatement.execute()
preparedStatement.close()
connection.close()
}
}
IncomeCountAdv(计算逻辑)
object IncomeCountAdv {
private val logger: Logger = LoggerFactory.getLogger(this.getClass)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
//指定以后从哪里读取数据
val lines: RDD[String] = sc.textFile(args(0))
//整理数据,解析JSON
val logBeanRDD: RDD[LogBeanV2] = lines.map(line => {
var logBean: LogBeanV2 = null
try {
logBean = JSON.parseObject(line, classOf[LogBeanV2])
} catch {
case e: JSONException => {
logger.error("parse json exception, error line is : " + line)
}
}
logBean
})
//过滤订单相关的数据,支付成功的数据
val filtered: RDD[LogBeanV2] = logBeanRDD.filter(bean => bean != null && bean.pay_status == 1)
filtered.cache()
//计算总的成交金额
CalculateUtils.calculateTotalIncome(filtered)
//计算各个省份的成交金额
CalculateUtils.calculateProvinceIncome(filtered)
//计算各个分类的成交金额
val categoryRDD: RDD[(Int, String)] = sc.parallelize(List((1,"图书"), (3,"家具"), (2, "服装"), (4, "手机")))
CalculateUtils.calculateCategoryIncome(filtered, categoryRDD)
//更各个省份下市成交金额的TopN
CalculateUtils.calculateProvicneAndCityIncomeTopN(filtered)
//计算复购率
CalculateUtils.calculateReBuyRatio(filtered)
sc.stop()
}
}
大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- RDD的依赖关系
RDD的依赖关系 Rdd之间的依赖关系通过rdd中的getDependencies来进行表示, 在提交job后,会通过在DAGShuduler.submitStage-->getMissingP ...
- sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成
4. RDD的依赖关系 6.1 RDD的依赖 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency ...
- 【Spark】RDD的依赖关系和缓存相关知识点
文章目录 RDD的依赖关系 宽依赖 窄依赖 血统 RDD缓存 概述 缓存方式 RDD的依赖关系 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency) 和宽依赖 ...
- 大数据学习(26)—— Spark之RDD
做大数据一定要有一个概念,需要处理的数据量非常大,少则几十T,多则上百P,全部放内存是不可能的,会OOM,必须要用迭代器一条一条处理. RDD叫做弹性分布式数据集,是早期Spark最核心的概念,是一种 ...
- 大数据学习(24)—— Spark入门
在学Spark之前,我们再回顾一下MapReduce的知识,这对我们理解Spark大有裨益. 在大数据的技术分层中,Spark和MapReduce同为计算层的批处理技术,但是Spark比MapRedu ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
随机推荐
- hdu 1083 Courses(二分图最大匹配)
题意: P门课,N个学生. (1<=P<=100 1<=N<=300) 每门课有若干个学生可以成为这门课的代表(即候选人). 又规定每个学生最多只能成为一门课的代 ...
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
- sed 替换命令使用
输入文件不会被修改,sed 只在模式空间中执行替换命令,然后输出模式空间的内容.文本文件 employee.txt 101,John Doe,CEO 102,Jason Smith,IT Manage ...
- AndroidStudio中debug.keystore文件不存在解决办法
Android项目丢失了debug.keystore,直接重新生存一个key. 在cmd下,进入C:\Users\Administrator\.android目录执行命令如下: keytool -g ...
- 彻底解决SLF4J的日志冲突的问题
今天公司同事上线时发现,有的机器打印了日志,而有的机器则一条日志也没有打.以往都是没有问题的. 因此猜测是这次开发间接引入新的日志jar包,日志冲突导致未打印. 排查代码发现,系统使用的是SLF4J框 ...
- Java——去掉小数点后面多余的0
当小数点后位数过多,多余的0没有实际意义,根据业务需求需要去掉多余的0.后端存储浮点型数据一般会用到Bigdecimal 类型,可以调用相关方法去掉小数后多余0,然后转为string. public ...
- LeetCode 114. 二叉树展开为链表 C++
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode ...
- Django笔记&教程 5-1 基础增删查改
Django 自学笔记兼学习教程第5章第1节--基础增删查改 点击查看教程总目录 第四章介绍了模型类models.Model和创建模型,相当于介绍了数据库表和如何创建数据库表. 这一章将介绍如何使用模 ...
- Handler处理器&&使用代理服务器urllib.request.ProxyHandler
urllib.request.urlopen(url) 不能定制请求头 urllib.request.Request(url,headers,data) 可以定制请求头 Handler 定制更高级的 ...
- [uoj76]懒癌
为了方便,称患有懒癌的狗为"坏狗" 记$Q_{i}$为第$i$个人能观察的狗集合,$S$为坏狗集合,那么第$k$天第$i$个人能得到的信息有且仅有$S\ne \empty$.$S\ ...