Hive(九)【自定义函数】
自定义函数
Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
用户自定义函数类别分为以下三种
UDF(User-Defined-Function)
一进一出
UDAF(User-Defined Aggregation Function)
多进一出;如聚集函数
UDTF(User-Defined Table-Generating Functions)
一进多出;如炸裂函数(explode)
临时函数:只存在当前会话,切换或断开就没有了,和当前use的库没有关系
删除临时函数:drop temporary function 函数名 或者 断开会话
永久函数:和库关联,在创建的时候需要指定库a.函数名,在使用的时候如果当前使用的库就是
编程步骤
(1)官方文档:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
(2)继承Hive提供的类
3.x逐渐弃用UDF类,推荐用下面的
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
(3)实现类中的抽象方法
(4)在hive的命令行窗口创建函数
添加jar
add jar linux_jar_path
创建function
create [temporary] function [dbname.]function_name AS class_name;
(5)在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
案例
需求
1.创建工程
2.导入依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
3.创建类
MyLen.java
package com.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* @description: 自定义UDF函数类, 求输入数据长度,只能处理一个hive的基本类型参数
* @author: HaoWu
* @create: 2020/6/30 11:39
*/
//hive3.X的UDF类已废除,推荐用GenericUDF
public class MyLen extends GenericUDF {
/**
* 初始化
*
* @param objectInspectors 输入参数类型的鉴别器对象
* @return 返回值类型的鉴别器对象
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
//判断输入参数的个数
if (objectInspectors.length != 1) {
throw new UDFArgumentLengthException("input args nums Error...");
}
//判断输入参数的类型是否为hive基本类型
if (!objectInspectors[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)) {
throw new UDFArgumentTypeException(0, "input args type Error...");
}
//函数本身返回int,需要返回int类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数处理逻辑
*
* @param deferredObjects
* @return
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
if (deferredObjects[0].get() == null) {
return 0;
}
Object obj = deferredObjects[0];
int len = obj.toString().length();
return len;
}
@Override
public String getDisplayString(String[] strings) {
return "";
}
}
4.打jar包
打包插件
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 指定主类 -->
<mainClass>com.hive.udf.MyLen</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
打包package,然后改名为mylen_udf.jar
5.上传hive所在服务器
[atguigu@hadoop102 datas]$ tree /opt/module/hive/datas/
/opt/module/hive/datas/
└── my_len.jar
6.将jar添加到hive的classpath
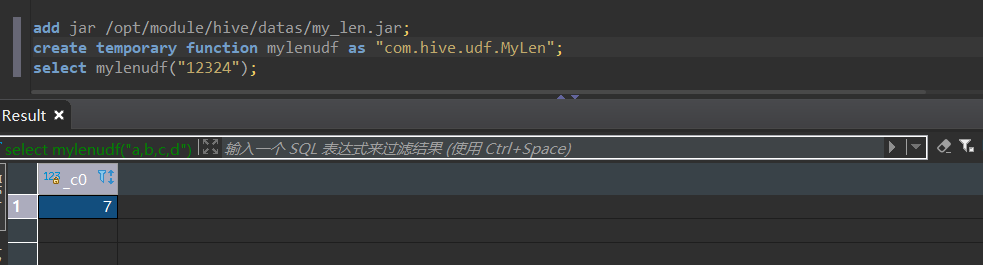
add jar /opt/module/hive/datas/mylen_udf.jar
7.创建临时函数与开发好的java class关联
create temporary function mylenudf as "com.hive.udf.MyLen"
8.测试自定义函数
临时函数和永久函数
创建临时函数
添加jar包的类路径给hive,注意是临时生效
add jar /opt/module/hive/datas/myudf.jar;
创建临时函数
create temporary function my_len as "com.atguigu.hive.udf.MyStringLength";
删除临时函数
drop temporary function my_len;
注意:临时函数只跟会话有关系,只要会话不断,在当前会话下,任意一个库都可以使用。其他会话全都不能使用。
创建永久函数
注意:因为永久函数是永久生效的,我们推出当前会话以后,其他会话也要使用永久函数,因此我们就不能简单的使用add jar来添加hive的类路径了
创建永久函数
注意:此时要使用USING JAR的方式来添加函数的jar包类路径,并且这个路径必须是hdfs路径
create function my_len2 as "com.atguigu.hive.udf.MyStringLength" USING JAR 'hdfs://hadoop102:9820/hivejar/myudf.jar';
删除永久函数
drop function my_len2;
注意:永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
然后使用永久函数的时候,需要在指定的库里面操作,或者在其他库里面使用的话得加上 库名.函数名
二.UDTF案例
1.创建类
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;
import java.util.ArrayList;
import java.util.List;
/**
* @description: UDTF函数功能(类似于explode函数功能)
* 入参:将json数组字符串
* 出参:将json数组的每一个元素作为一行输出
*
* @author: HaoWu
* @create: 2020年08月15日
*/
public class ExplodeJSONArrayUDTF extends GenericUDTF {
/*
初始化方法
*/
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//1.获取传入的参数
List<? extends StructField> inputFields = argOIs.getAllStructFieldRefs();
//2.判断参数个数是否为一个?
if (inputFields.size() != 1) {
throw new UDFArgumentException("只需要一个参数");
}
//3.定义返回值名称和类型
//返回的字段名
List<String> fieldNames = new ArrayList<>();
fieldNames.add("action");
//返回的字段类型
List<ObjectInspector> fieldOIs = new ArrayList<>();
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
/*
生成返回的数据
*/
@Override
public void process(Object[] objects) throws HiveException {
//1.获取传入的数据
String jsonArray = objects[0].toString();
//2.将string转化为json数组
JSONArray actions = new JSONArray(jsonArray);
//3.循环取出json数组的元素,依次写出
for (int i = 0; i < actions.length(); i++) {
String[] result = new String[1];
result[0]=actions.getString(i);
//写出
forward(result);
}
}
@Override
public void close() throws HiveException {
}
}
2.打包上传
将hivefunction-1.0-SNAPSHOT.jar上传到hadoop102的/opt/module,然后再将该jar包上传到HDFS的/user/hive/jars路径下
[root@hadoop102 module]$ hadoop fs -mkdir -p /user/hive/jars
[root@hadoop102 module]$ hadoop fs -put warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar /user/hive/jars
3.创建临时函数
hive> create function explode_json_array as 'com.hivescript.ExplodeJSONArrayUDTF' using jar 'hdfs://hadoop102:8020/user/hive/jars/warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar';
Added [/tmp/ca6c5ab9-c76b-406b-9d1f-63aa32523f2f_resources/warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar] to class path
Added resources: [hdfs://hadoop102:8020/user/hive/jars/warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar]
OK
Time taken: 1.093 seconds
4.测试
测试数据
[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]
hive> select explode_json_array('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]');
OK
{"name":"大郎","sex":"男","age":"25"}
{"name":"西门庆","sex":"男","age":"47"}
Time taken: 2.906 seconds, Fetched: 2 row(s)
注意
如果修改了自定义函数重新生成jar包怎么处理?只需要替换HDFS路径上的旧jar包,然后重启Hive客户端即可。
Hive(九)【自定义函数】的更多相关文章
- Hadoop生态圈-hive编写自定义函数
Hadoop生态圈-hive编写自定义函数 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDTF(User-Defined Table-Generating Functions)
Hadoop生态圈-Hive的自定义函数之UDTF(User-Defined Table-Generating Functions) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function)
Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDF(User-Defined-Function)
Hadoop生态圈-Hive的自定义函数之UDF(User-Defined-Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- 【Hive】自定义函数
Hive的自定义函数无法满足实际业务的需要,所以为了扩展性,Hive官方提供了自定义函数来实现需要的业务场景. 1.定义 (1)udf(user defined function): 自定义函数,特 ...
- Hive中自定义函数
Hive的自定义的函数的步骤: 1°.自定义UDF extends org.apache.hadoop.hive.ql.exec.UDF 2°.需要实现evaluate函数,evaluate函数支持重 ...
- [Hive_12] Hive 的自定义函数
0. 说明 UDF //user define function //输入单行,输出单行,类似于 format_number(age,'000') UDTF //user define table-g ...
- Hive中如何添加自定义UDF函数以及oozie中使用hive的自定义函数
操作步骤: 1. 修改.hiverc文件 在hive的conf文件夹下面,如果没有.hiverc文件,手工自己创建一个. 参照如下格式添加: add jar /usr/local/hive/exter ...
- Hive(9)-自定义函数
一. 自定义函数分类 当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数. 根据用户自定义函数类别分为以下三种: 1. UDF(User-Defined-Functi ...
- 三 Hive 数据处理 自定义函数UDF和Transform
三 Hive 自定义函数UDF和Transform 开篇提示: 快速链接beeline的方式: ./beeline -u jdbc:hive2://hadoop1:10000 -n hadoop 1 ...
随机推荐
- hdu 5101 Select (二分+单调)
题意: 多多有一个智商值K. 有n个班级,第i个班级有mi个人.智商分别是v1,v2,.....vm. 多多要从这些人中选出两人.要求两人智商和大于K,并且两人不同班.问总共有多少种方案. 数据范围: ...
- eclipse javaEE版下载过程中选择镜像(Select Another Mirror)无反应解决办法,附带eclipse javaEE版下载教程。
1.eclipse javaEE版下载过程中选择镜像(Select Another Mirror)无反应 (复制该网址下载即可 https://mirrors.neusoft.edu.cn/eclip ...
- glibc memcpy() 源码浅谈
其实我本来只是想搞懂为什么memcpy()函数的参数类型是void *的: 我以为会在memcpy()源码中能找到答案,其实并没有,void *只是在传递参数的时候起了作用,可以让memcpy()接受 ...
- 攻防世界 WEB 高手进阶区 csaw-ctf-2016-quals mfw Writeup
攻防世界 WEB 高手进阶区 csaw-ctf-2016-quals mfw Writeup 题目介绍 题目考点 PHP代码审计 git源码泄露 Writeup 进入题目,点击一番,发现可能出现git ...
- 攻防世界 WEB 高手进阶区 easytornado Writeup
攻防世界 WEB 高手进阶区 easytornado Writeup 题目介绍 题目考点 Python模板 tornado 模板注入 Writeup 进入题目, 目录遍历得到 /flag.txt /w ...
- C++ 指针的引用和指向引用的指针
指向引用的指针 简单使用指针的一个例子就是: int a = 1; int *p = &a; 预先强调: 没有指向引用的指针 原因: 因为引用 不是对象,没有地址. 但是指向引用的指针是什么形 ...
- [python]Appium+python +pytest 实现APP自动化,基于安卓
1.安卓环境搭建 &关于app自动化,个人觉得安装过程比较复杂,脚本难度实现和web自动化差不多封装关键字即可,因此,下面会写安装.启动APP以及过程中遇到的一些坑(这一篇偏向解释给个人) & ...
- Linux usb 6. HC/UDC 测试
目录 1. 背景介绍 2. Device (gadget zero) 2.1 gadget zero 创建 2.2 SourceSink Function 2.3 Loopback Function ...
- mbatis动态sql中传入list并使用
<!--Map:不单单forech中的collection属性是map.key,其它所有属性都是map.key,比如下面的departmentId --> <select id=&q ...
- 基于Netty实现自定义消息通信协议(协议设计及解析应用实战)
所谓的协议,是由语法.语义.时序这三个要素组成的一种规范,通信双方按照该协议规范来实现网络数据传输,这样通信双方才能实现数据正常通信和解析. 由于不同的中间件在功能方面有一定差异,所以其实应该是没有一 ...