LSM树——LSM 将B+树等结构昂贵的随机IO变的更快,而代价就是读操作要处理大量的索引文件(sstable)而不是一个,另外还是一些IO被合并操作消耗。
Basic Compaction
为了保持LSM的读操作相对较快,维护并减少sstable文件的个数是很重要的,所以让我们更深入的看一下合并操作。这个过程有一点儿像一般垃圾回收算法。
当一定数量的sstable文件被创建,例如有5个sstable,每一个有10行,他们被合并为一个50行的文件(或者更少的行数)。这个过程一 直持续着,当更多的有10行的sstable文件被创建,当产生5个文件时,它们就被合并到50行的文件。最终会有5个50行的文件,这时会将这5个50 行的文件合并成一个250行的文件。这个过程不停的创建更大的文件。像下图:
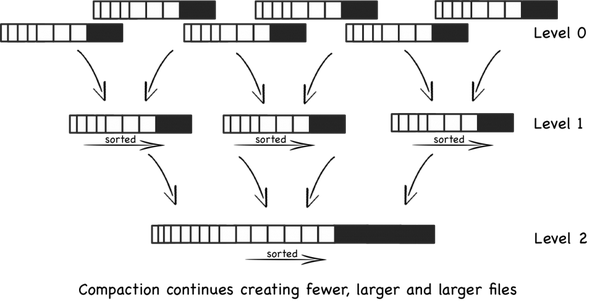
上述的方案有一个问题,就是大量的文件被创建,在最坏的情况下,所有的文件都要搜索。
Levelled Compaction
更新的实现,像 LevelDB 和 Cassandra解决这个问题的方法是:实现了一个分层的,而不是根据文件大小来执行合并操作。这个方法可以减少在最坏情况下需要检索的文件个数,同时也减少了一次合并操作的影响。
按层合并的策略相对于上述的按文件大小合并的策略有二个关键的不同:
- 每一层可以维护指定的文件个数,同时保证不让key重叠。也就是说把key分区到不同的文件。因此在一层查找一个key,只用查找一个文件。第一层是特殊情况,不满足上述条件,key可以分布在多个文件中。
- 每次,文件只会被合并到上一层的一个文件。当一层的文件数满足特定个数时,一个文件会被选出并合并到上一层。这明显不同与另一种合并方式:一些相近大小的文件被合并为一个大文件。
这些改变表明按层合并的策略减小了合并操作的影响,同时减少了空间需求。除此之外,它也有更好的读性能。但是对于大多数场景,总体的IO次数变的更多,一些更简单的写场景不适用。
总结
所以, LSM 是日志和传统的单文件索引(B+ tree,Hash Index)的中立,他提供一个机制来管理更小的独立的索引文件(sstable)。
通过管理一组索引文件而不是单一的索引文件,LSM 将B+树等结构昂贵的随机IO变的更快,而代价就是读操作要处理大量的索引文件(sstable)而不是一个,另外还是一些IO被合并操作消耗。
如果还有不明白的,这还有一些其它的好的介绍。
http://leveldb.googlecode.com/svn/trunk/doc/impl.html
and here
关于 LSM 的一些思考
为什么 LSM 会比传统单个树结构有更好的性能?
我们看到LSM有更好的写性能,同时LSM还有其它一些好处。 sstable文件是不可修改的,这让对他们的锁操作非常简单。一般来说,唯一的竞争资源就是 memtable,相对来说需要相对复杂的锁机制来管理在不同的级别。
所以最后的问题很可能是以写为导向的压力预期如何。如果你对LSM带来的写性能的提高很敏感,这将会很重要。大型互联网企业似乎很看中这个问题。 Yahoo 提出因为事件日志的增加和手机数据的增加,工作场景为从 read-heavy 到 read-write。。许多传统数据库产品似乎更青睐读优化文件结构。
因为可用的内存的增加,通过操作系统提供的大文件缓存,读操作自然会被优化。写性能(内存不可提高)因此变成了主要的关注点,所以采取其它的方法,硬件提升为读性能做的更多,相对于写来说。因此选择一个写优化的文件结构很有意义。
理所当然的,LSM的实现,像LevelDB和Cassandra提供了更好的写性能,相对于单树结构的策略。
Beyond Levelled LSM
这有更多的工作在LSM上, Yahoo开发了一个系统叫作 Pnuts, 组合了LSM与B树,提供了更好的性能。我没有看到这个算法的开放的实现。 IBM和Google也实现了这个算法。也有相关的策略通过相似的属性,但是是通过维护一个拱形的结构。如 Fractal Trees, Stratified Trees.
这当然是一个选择,数据库利用大量的配置,越来越多的数据库为不同的工作场景提供插件式引擎。 Parquet 是一个流行的HDFS的替代,在很多相对的文面做的好很(通过一个列格式提高性能)。MySQL有一个存储抽象,支持大量的存储引擎的插件,例如 Toku (使用 fractal tree based index)。
Mongo3.0 则包含了支持B+和LSM的 Wired Tiger引擎。许多关系数据库可以配置索引结构,使用不同的文件格式。
考虑被使用的硬件,昂贵的SSD,像FusionIO有更好的随机写性能,这适合本地更新的策略方法。更便宜的SSD和机械盘则更适合LSM。
延伸阅读
- There is a nice introductory post
https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/.
- The LSM description in this
http://www.eecs.harvard.edu/~margo/cs165/papers/gp-lsm.pdf
is great and it also discusses interesting extensions.
- These three posts provide a holistic coverage of the algorithm:
http://leveldb.googlecode.com/svn/trunk/doc/impl.html, http://www.datastax.com/dev/blog/leveled-compaction-in-apache-cassandra and http://www.quora.com/How-does-the-Log-Structured-Merge-Tree-work.
- The original Log Structured Merge Tree pape
r http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.44.2782&rep=rep1&type=pdf
. It is a little hard to follow in my opinion.
- The Big Table paper
http://static.googleusercontent.com/media/research.google.com/en/archive/bigtable-osdi06.pdf
is excellent.
http://highscalability.com/blog/2014/8/6/tokutek-white-paper-a-comparison-of-log-structured-merge-lsm.html
on High Scalability.
- Recent work on
http://researcher.ibm.com/researcher/files/us-wtan/DiffIndex-EDBT14-CR.pdf
which builds on the LSM concept.
http://blog.empathybox.com/post/24415262152/ssds-and-distributed-data-systems
on SSDs and the benefits of LSM
来自:
http://lcblog.sinaapp.com/?p=223LSM树——LSM 将B+树等结构昂贵的随机IO变的更快,而代价就是读操作要处理大量的索引文件(sstable)而不是一个,另外还是一些IO被合并操作消耗。的更多相关文章
- 【模板】【P3605】【USACO17JAN】Promotion Counting 晋升者计数——动态开点和线段树合并(树状数组/主席树)
(题面来自Luogu) 题目描述 奶牛们又一次试图创建一家创业公司,还是没有从过去的经验中吸取教训--牛是可怕的管理者! 为了方便,把奶牛从 1⋯N(1≤N≤100,000) 编号,把公司组织成一棵树 ...
- 012-数据结构-树形结构-哈希树[hashtree]、字典树[trietree]、后缀树
一.哈希树概述 1.1..其他树背景 二叉排序树,平衡二叉树,红黑树等二叉排序树.在大数据量时树高很深,我们不断向下找寻值时会比较很多次.二叉排序树自身是有顺序结构的,每个结点除最小结点和最大结点外都 ...
- BZOJ 2243: [SDOI2011]染色 (树链剖分+线段树合并)
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=2243 树链剖分的点剖分+线段树.漏了一个小地方,调了一下午...... 还是要细心啊! 结 ...
- bzoj 2243 [SDOI2011]染色(树链剖分+线段树合并)
[bzoj2243][SDOI2011]染色 2017年10月20日 Description 给定一棵有n个节点的无根树和m个操作,操作有2类: 1.将节点a到节点b路径上所有点都染成颜色c: 2.询 ...
- BZOJ - 2243 染色 (树链剖分+线段树+区间合并)
题目链接 线段树维护区间连续段个数即可.设lc为区间左端点颜色,rc为区间右端点颜色,则合并两区间的时候,如果左区间右端点和右区间左端点颜色相同,则连续段个数-1. 在树链上的区间合并可以定义一个结构 ...
- 有趣的线段树模板合集(线段树,最短/长路,单调栈,线段树合并,线段树分裂,树上差分,Tarjan-LCA,势能线段树,李超线段树)
线段树分裂 以某个键值为中点将线段树分裂成左右两部分,应该类似Treap的分裂吧(我菜不会Treap).一般应用于区间排序. 方法很简单,就是把分裂之后的两棵树的重复的\(\log\)个节点新建出来, ...
- bzoj 2243: [SDOI2011]染色 (树链剖分+线段树 区间合并)
2243: [SDOI2011]染色 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 9854 Solved: 3725[Submit][Status ...
- 【bzoj2325】[ZJOI2011]道馆之战 树链剖分+线段树区间合并
题目描述 给定一棵树,每个节点有上下两个格子,每个格子的状态为能走或不能走.m次操作,每次修改一个节点的状态,或询问:把一条路径上的所有格子拼起来形成一个宽度为2的长方形,从起点端两个格子的任意一个开 ...
- HDU - 6704 K-th occurrence (后缀数组+主席树/后缀自动机+线段树合并+倍增)
题意:给你一个长度为n的字符串和m组询问,每组询问给出l,r,k,求s[l,r]的第k次出现的左端点. 解法一: 求出后缀数组,按照排名建主席树,对于每组询问二分或倍增找出主席树上所对应的的左右端点, ...
随机推荐
- ZFIR_001 ole下载
*&---------------------------------------------------------------------** Report ZFIR_001* Appli ...
- javascript高级语法三
一.js的正则表达式 1.什么是正则表达式 正则表达式(regular expression)是一个描述字符模式的对象,ECMAScript的RegExp类表示正则表达式,而String和RegExp ...
- BigDecimal类型、Long类型判断值是否相等,以及BigDecimal加减乘除
//Long是需要比较精度的,所以要用longValueif(project.getFriendId().longValue() != friendId.longValue()) { return t ...
- Python进阶(2)_进程与线程的概念
1 进程与线程相关概念 1.1 进程 进程定义: 进程就是一个程序在一个数据集上的一次动态执行过程.进程一般由程序.数据集.进程控制块三部分组成,是最小的资源管理单元 程序:用来描述进程要完成哪些功能 ...
- python基础深入(元组、字符串、列表、字典)
python基础深入(元组.字符串.列表.字典) 一.列表 1.追加 >>>list = [1,2,3,4] #用于在列表末尾添加新的对象,只能单个添加,该方法无返回值,但是会修改原 ...
- linux 快速清空文件内容
Tomcat 的catelina.out 如果不配置按照日期产生会在一个文件中产生大量的输出日志. 清除日志如果直接删除catelina.out将无法输出日志.如果想输出日志只能重启Tomcat才会产 ...
- Android开发BUG及解决方法1
错误描述: 问题1: Error:Execution failed for task ':app:transformClassesWithDexForDebug'. > com.Android. ...
- jQuery滑动杆打分插件
在线演示 本地下载
- bowtie2用法
bowtie2的功能:短序列的比对 用法:bowtie2 [options]* -x <bt2-idx> {-1 <m1> -2 <m2> | -U <r&g ...
- INSPIRED启示录 读书笔记 - 第30章 在大公司施展拳脚
十大秘诀 1.了解公司制定决策的方式:知道决策权在谁手里,了解他制定决策的方式,只需要说服他就行了 2.建立人脉网络:主动帮助他人,积累人脉关系 3.臭鼬工程:在工作之余做出产品原型来,产品原型具有超 ...