java基础(5)-集合类1
集合的由来
数组是很常用的一种数据结构,但假如我们遇到以下这样的的问题:
- 容器长度不确定
- 能自动排序
- 存储以键值对方式的数据
如果遇到这样的情况,数组就比较难满足了,所以也就有了一种与数组类似的数据结构——集合类。即集合是java中提供的一种容器,可用来存储多个数据
数组和集合的区别
1)长度
数组的长度固定
集合的长度可变
2)内容不同
数组存储的是同一种类型元素
集合可存储不同类型的元素
3)元素数据类型
数组可存储基本数据类型,也可存储引用数据类型
集合只能存储引用类型
数组和集合的联系
- 可使用toArray()和Arrays.asList()方法相互转换
集合的集成体系

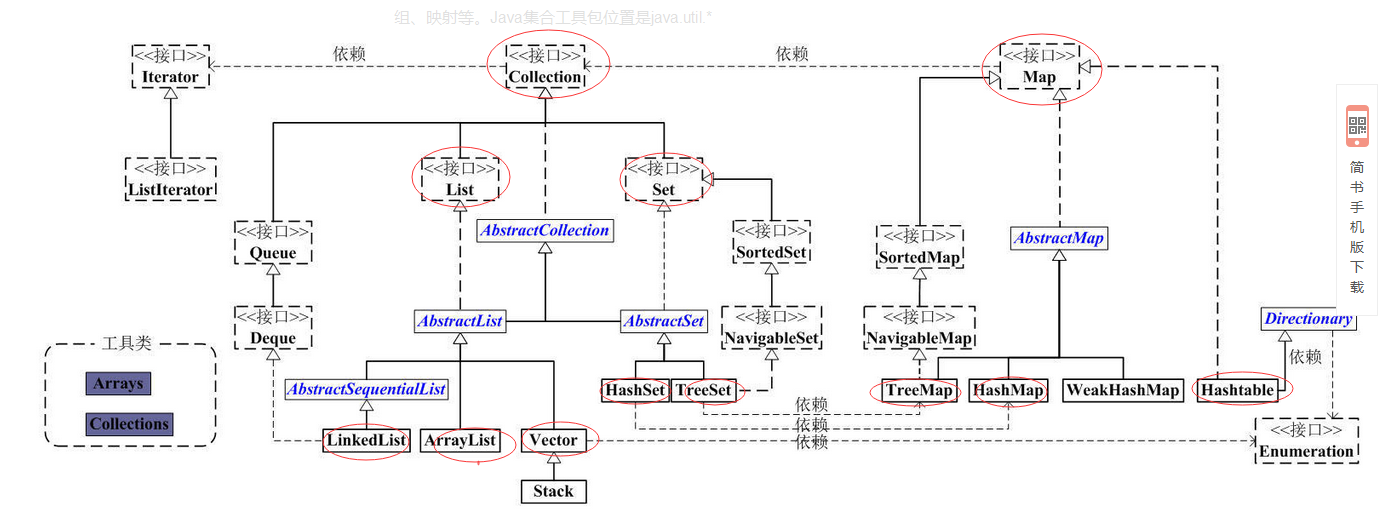
集合按存储结构可以分为单列集合(Collection)和双列集合(Map)
- Collection
Collection:是单列集合的根接口,Collection表示一组对象。两类子接口分别是LIst和Set【还有一类是Queue】
List接口:特点是元素有序,元素可重复。List接口的主要实现类有ArrayList和LinkedList
Set接口:特点是元素无序并且不可重复。Set接口的主要实现类有HashSet(散列存放)和TreeSet(有序存放)
- Map
1)Map提供了一种映射关系,元素是以键值对(key-value)的形式存储的,能够根据key快速查找value,常用子类有Hashtable,HashMap和TreeMap
2)Map中的键值对以Entry类型的对象实例形式存在
3)键(key值)不可重复,value值可以
4)每个建最多只能映射到一个值
5)Map接口提供了分别返回key值集合、value值集合以及Entry(键值对)集合的方法
6)Map支持泛型,形式如:Map<K,V>
Hashtable:底层是哈希表数据结构,不可存入null键null值,给集合是线程同步的。
HashMap:底层是哈希表数据结构,允许使用null键null值,该集合是不同步的
TreeMap:底层是二叉树数据结构,线程不同步,可以用于给map集合中的键进行排序
Map接口与Collection接口的不同
- map是双列的,collection是单列的
- map的键是唯一,collection的子体系set是唯一
- map集合的数据结构只针对键有效,跟值无关,collection集合的数据结构是针对元素有效
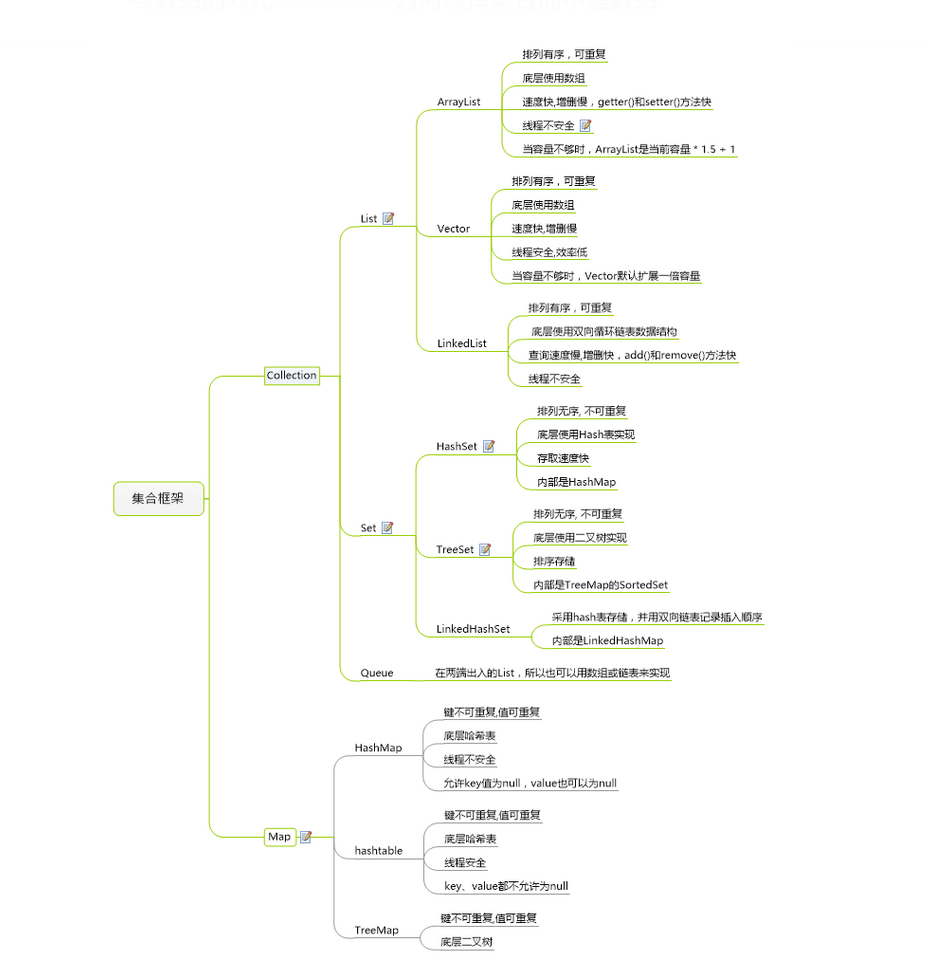
集合框架思维导图

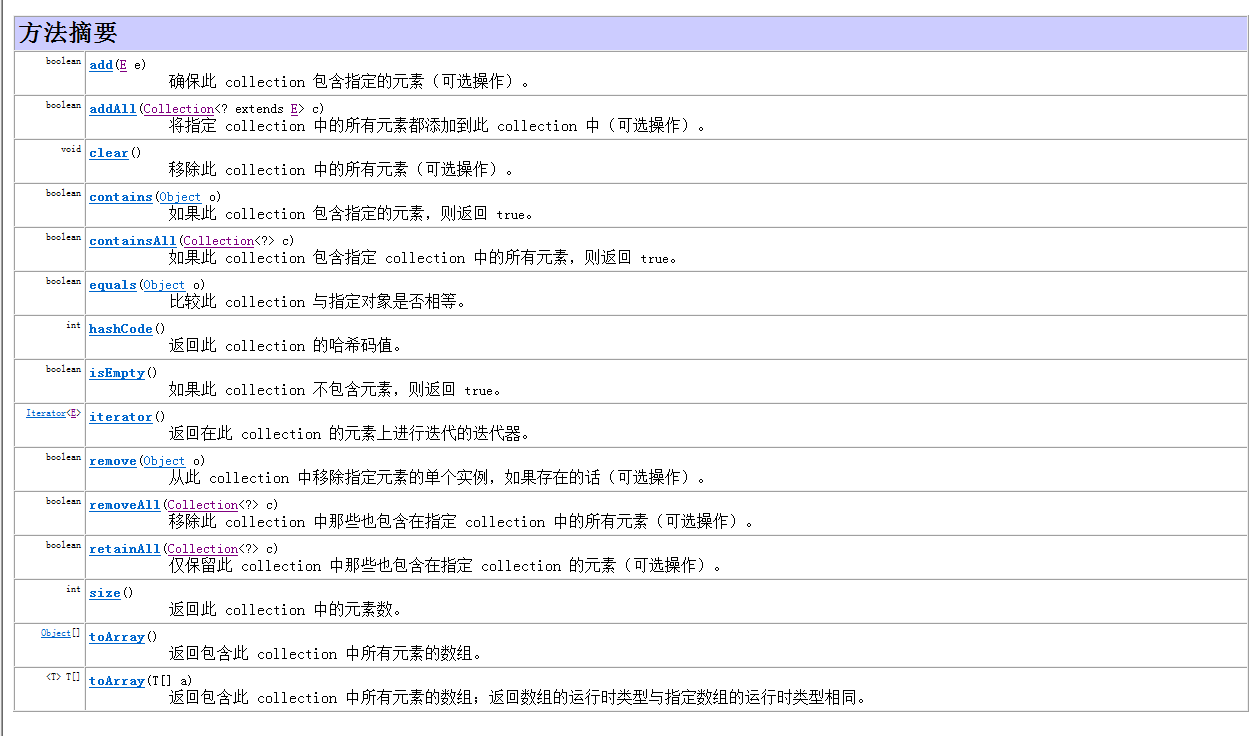
集合中的方法

集合基本功能测试
向集合中添加元素
/*
*向集合中添加一个元素
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo1{
public static void main(String[] args){
//创建集合对象
//Collection c = new Collection();//错误,接口不能实例化,需要找实现类
Collection c = new ArrayList();
//向集合中添加元素:boolean add(Object o);
c.add("10w");
c.add("20w");
c.add("30w");
//输出
System.out.println(c);
}
}
----------------------------------------------
输出结果:[10w, 20w, 30w]
----------------------------------------------
删除集合中所有元素
/*
*删除集合中所有元素
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo2{
public static void main(String[] args){
//创建集合对象
Collection c = new ArrayList();
//向集合中添加元素
c.add("100w");
c.add("200w");
c.add("300w");
System.out.println("删除前:"+c);
//删除集合中所有元素:void clear()
c.clear();
System.out.println("删除后:"+c);
}
}
------------------------------------------
输出结果:
删除前:[100w, 200w, 300w]
删除后:[]
------------------------------------------
删除该集合中指定的元素
/*
* 删除该集合中指定元素
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo3{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//向集合中添加元素
c.add("10w");
c.add("30w");
c.add("50w");
System.out.println("删除前:"+c);
//删除该集合中中指定的元素:boolean remove(Object o)
c.remove("30w");
System.out.println("删除后:"+c);
}
}
---------------------------------------------
输出结果:
删除前:[10w, 30w, 50w]
删除后:[10w, 50w]
----------------------------------------------
判断该集合中是否包含某个元素
/*
*判断该集合中是否包含某个元素
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo4{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//添加元素
c.add("hadoop");
c.add("spark");
c.add("storm");
System.out.println(c);
//判断该集合中是否包含某个元素:boolean contains(Object o)
System.out.println("判断有没有spark:"+c.contains("spark"));
System.out.println("判断有没有data:"+c.contains("data"));
}
}
---------------------------------------------
输出结果
[hadoop, spark, storm]
判断有没有spark:true
判断有没有data:false
------------------------------------------------
判断集合是否为空
/*
*判断集合是否为空
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo5{
public static void main(String[] args){
//创建集合
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
//向集合2中添加元素
c2.add("java");
c2.add("scala");
c2.add("python");
//判断集合是否为空:boolean isEmpty()
System.out.println("判断集合c1是否为空:"+c1.isEmpty());
System.out.println("判断集合c2是否为空:"+c2.isEmpty());
}
}
---------------------------------------------
输出结果
判断集合c1是否为空:true
判断集合c2是否为空:false
-------------------------------------------
获取该集合中元素的个数
/*
*判断该元素的个数
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo6{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//添加元素
c.add("wujiadogn");
c.add("jiangrui");
c.add("sunqiangkun");
c.add("xuqingyu");
//获取该集合的元素个数: int size()
System.out.println(c.size());
}
}
-------------------------------------
输出结果
4
-------------------------------------
将指定集合的所有元素添加到该集合中
/*
*将指定集合的所有元素添加到该集合中
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo7{
public static void main(String[] args){
//创建集合
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
//添加元素
c1.add("hadoop");
c1.add("spark");
c1.add("storm");
c2.add("wujiadong");
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
//将指定集合中所有元素添加到该元素中:boolean addAll(Collection c)
c1.addAll(c2);//将c2添加到c1中
System.out.println("将集合c2元素添加到c1后的c1:"+c1);
System.out.println("将集合c2元素添加到c1后的c2:"+c2);
}
}
---------------------------------------
输出结果
c1:[hadoop, spark, storm]
c2:[wujiadong]
将集合c2元素添加到c1后的c1:[hadoop, spark, storm, wujiadong]
将集合c2元素添加到c1后的c2:[wujiadong]
---------------------------------------
删除指定集合中的所有元素
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo8{
public static void main(String[] args){
//创建集合
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
//添加元素
c1.add("hadoop1");
c1.add("hadoop2");
c1.add("hadoop3");
c2.add("spark1");
c2.add("spark2");
c2.add("spark3");
c2.add("hadoop1");
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
System.out.println("c1删除c2的元素");
c1.removeAll(c2);
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
}
}
----------------------------------------
输出结果
c1:[hadoop1, hadoop2, hadoop3]
c2:[spark1, spark2, spark3, hadoop1]
c1删除c2的元素
c1:[hadoop2, hadoop3]
c2:[spark1, spark2, spark3, hadoop1]
---------------------------------------------
判断该集合中是否包含指定集合的所有元素
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo8{
public static void main(String[] args){
//创建集合
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
Collection c3 = new ArrayList();
//添加元素
c1.add("hadoop1");
c1.add("hadoop2");
c1.add("hadoop3");
c2.add("spark1");
c2.add("spark2");
c2.add("spark3");
c2.add("hadoop1");
c3.add("hadoop1");
c3.add("hadoop2");
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
System.out.println("c3:"+c3);
System.out.println("c1是否包含c2:"+c1.containsAll(c2));
System.out.println("c1是否包含c3:"+c1.containsAll(c3));
System.out.println("retainAll()返回值表示c1是否发生过改变:"+c1.retainAll(c2));
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
}
}
注释:
boolean retainAll(Collection c):两个集合都有的元素
假假设有两个集合A和B,A和B做交集,最终的结果保存在A中,B不变;返回值表示的是A是否发过生改变
--------------------------------
输出结果
c1:[hadoop1, hadoop2, hadoop3]
c2:[spark1, spark2, spark3, hadoop1]
c3:[hadoop1, hadoop2]
c1是否包含c2:false
c1是否包含c3:true
c1和c2都有的元素retainAll():true
c1:[hadoop1]
c2:[spark1, spark2, spark3, hadoop1]
-------------------------------------
集合的遍历
集合的使用步骤
1)创建集合对象
2)创建元素对象
3)把元素添加到集合
4)遍历集合
a:通过集合对象获取迭代器对象
b:通过迭代器对象的hasNext()方法判断是否有元素
c:通过迭代器对象的next()方法获取元素并移动到下一个位置
方法一:通过转换成数组进行遍历
/*
*通过将集合转换成数组进行遍历
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo1{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//向数组中添加元素
c.add("hadoop");
c.add("spark");
c.add("storm");
//Object[] toArray():将集合转换成数组,可以实现集合的遍历
Object[] objs = c.toArray();
for(int i=0;i<objs.length;i++){
System.out.println(objs[i]);
}
}
}
----------------------------------------
输出结果
hadoop
spark
storm
---------------------------------------
练习:用集合存储5个学生对象,并把学生对象进行遍历
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo2{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//创建学生对象
Student s1 = new Student("wwww",20);
Student s2 = new Student("jjj",21);
Student s3 = new Student("ddd",22);
Student s4 = new Student("sss",23);
Student s5 = new Student("qqq",24);
//将对象存储到集合中
c.add(s1);
c.add(s2);
c.add(s3);
c.add(s4);
c.add(s5);
//把集合转成数组
Object[] objs = c.toArray();
for(int i=0;i<objs.length;i++){
System.out.println(objs[i]);
}
}
}
class Student{
//成员变量
private String name;
private int age;
//构造方法
public Student(){
super();
}
public Student(String name,int age){
this.name = name;
this.age = age;
}
//getXxx()和setXxx()方法
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return age;
}
public String toString(){
return "Student [name="+name+",age="+age+"]";
}
}
---------------------------------
输出结果
Student [name=wwww,age=20]
Student [name=jjj,age=21]
Student [name=ddd,age=22]
Student [name=sss,age=23]
Student [name=qqq,age=24]
--------------------------------
方法二:集合专用遍历方式:迭代器
import java.util.Collection;
import java.util.ArrayList;
import java.util.Iterator;
public class ObjectArrayDemo3{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
c.add("hadoop");
c.add("spark");
c.add("storm");
// Iterator iterator();迭代器,集合的专用遍历方式
Iterator it = c.iterator();//实际返回的子类对象,这里是多态
/*
System.out.println(it.next());
System.out.println(it.next());
System.out.println(it.next());
*/
while(it.hasNext()){
String s = (String) it.next();
System.out.println(s);
}
}
}
-------------------------------------
输出结果
hadoop
spark
storm
---------------------------------------
练习:用集合存储5个对象,并把学生对象进行遍历,用迭代器遍历
import java.util.Collection;
import java.util.ArrayList;
import java.util.Iterator;
public class ObjectArrayDemo4{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
Student s1 = new Student("www",21);
Student s2 = new Student("jjj",22);
Student s3 = new Student("ddd",23);
Student s4 = new Student("sss",24);
Student s5 = new Student("qqq",25);
c.add(s1);
c.add(s2);
c.add(s3);
c.add(s4);
c.add(s5);
Iterator it = c.iterator();
while(it.hasNext()){
// System.out.println(it.next());
Student s = (Student) it.next();
System.out.println(s);
}
}
}
class Student{
//成员变量
private String name;
private int age;
//无参构造方法
public Student(){
super();
}
//有参构造方法
public Student(String name,int age){
this.name = name;
this.age = age;
}
//getXxx方法和setXxx方法
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
public void setAge(int age){
this.age = age;
}
public int age(){
return age;
}
//为什么需要这个方法,没有这个方法输出结果过就是地址值
public String toString(){
return "Student [name="+name+",age="+age+"]";
}
}
-------------------------------------------
输出结果
Student [name=www,age=21]
Student [name=jjj,age=22]
Student [name=ddd,age=23]
Student [name=sss,age=24]
Student [name=qqq,age=25]
--------------------------------------------
练习:存储字符串并遍历
import java.util.Collection;
import java.util.ArrayList;
import java.util.Iterator;
public class ObjectArrayDemo5{
public static void main(String[] args){
//创建集合对象
Collection c = new ArrayList();
//向集合添加元素
c.add("wu");
c.add("sun");
c.add("jiang");
c.add("xu");
c.add("haha");
//通过集合对象获取迭代器对象
Iterator it = c.iterator();
//通过迭代器对象的hasNext()方法判断有没有元素
while(it.hasNext()){
//通过迭代器对象的next()方法获取元素
String s = (String) it.next();
System.out.println(s);
}
}
}
-----------------------------------
输出结果
wu
sun
jiang
xu
haha
------------------------------------
参考资料
java基础(5)-集合类1的更多相关文章
- java基础(8) -集合类-Collecion
集合类-Collecion Collection接口 常用方法 //添加新元素 boolean add (E element); //返回迭代器 Iterator<E> iterator( ...
- 面试【JAVA基础】集合类
1.ArrayList的扩容机制 每次扩容是原来容量的1.5倍,通过移位的方法实现. 使用copyOf的方式进行扩容. 扩容算法是首先获取到扩容前容器的大小.然后通过oldCapacity (oldC ...
- 【java基础之jdk源码】集合类
最近在整理JAVA 基础知识,从jdk源码入手,今天就jdk中 java.util包下集合类进行理解 先看图 从类图结构可以了解 java.util包下的2个大类: 1.Collecton:可以理解为 ...
- Java基础__Java中自定义集合类
Java基础__Java中集合类 传送门 自定义MyArrayList集合实现:增加数据.取数据.查看集合中数据个数方法 package com.Gary; public class MyArrayL ...
- [Java面经]干货整理, Java面试题(覆盖Java基础,Java高级,JavaEE,数据库,设计模式等)
如若转载请注明出处: http://www.cnblogs.com/wang-meng/p/5898837.html 谢谢.上一篇发了一个找工作的面经, 找工作不宜, 希望这一篇的内容能够帮助到大 ...
- 【JAVA面试题系列一】面试题总汇--JAVA基础部分
JAVA基础 基础部分的顺序: 基本语法,类相关的语法,内部类的语法,继承相关的语法,异常的语法 线程的语法,集合的语法,io 的语法,虚拟机方面的语法 每天几道,持续更新!! 1.一个". ...
- Java基础知识【下】( 转载)
http://blog.csdn.net/silentbalanceyh/article/details/4608360 (最终还是决定重新写一份Java基础相关的内容,原来因为在写这一个章节的时候没 ...
- Java基础应用
Java集合类解析 List.Map.Set三个接口,存取元素时,各有什么特点? List 以特定次序来持有元素,可有重复元素.Set 无法拥有重复元素,内部排序.Map 保存key-value值,v ...
- Java基础知识学习(一)
部门接了新项目,后台使用Java框架play framework,前端是html,前后台通过rest交互,能够支持多端的互联网架构. 因为之前没有Java基础,前端使用的也很少,决定深入学习一下Jav ...
- java基础要点
Java语言是现在比较常用的编程语言,因为Java语言可以编写桌用程序,也可以编写web程序,还能编写嵌入式程序.这是由于相比脚本语言,Java 的运行速度要快.而对于底层语言,Java与平台无关,可 ...
随机推荐
- SQL Server 还原错误“restore database正在异常终止 错误 3154”
今天在还原数据库时,先建立相同名字的数据库,然后在该数据库上右键还原数据库.遇到了这样的一个错误: “备份集中的数据库备份与现有的 'RM_DB' 数据库不同. RESTORE DATABASE 正在 ...
- iOS学习笔记(六)——ViewController
ViewController是iOS应用程序中重要的部分,是应用程序数据和视图之间的重要桥梁,ViewController管理应用中的众多视图.iOS的SDK中提供很多原生ViewController ...
- 导出excel页面假死
如果是asp.net页面 public override void VerifyRenderingInServerForm(Control control) {} 如果是Sharepoint w ...
- 巨蟒django之CRM4 一些小功能
内容回顾: 修改的地方 (1) (2) (3) (4) (5) 整体回顾前几天内容: 现在可以登录的原因,session内部存储了信息 这个时候我们再访问刚才的地址,会发现,跳转到了登录页面login ...
- coursera 《现代操作系统》
什么是独占设备技术?为什么说 “SPOOLing不是独占设备的”? 百度百科没有解释,从教材中找到了: 第二章 取数指令 load To load a value from memory, you ...
- springboot springmvc 支持 https
Spring Mvc和Spring Boot配置Tomcat支持Https 背景 最近在项目开发中需要让自己的后端Restful接口支持https,在参考了很多前辈们的博客后总结了一些. Spring ...
- 如何配置一个路径,能够既适合Linux平台,又适合Windows平台,可以从这个路径中读取文件
如何配置一个路径,能够既适合Linux平台,又适合Windows平台,可以从这个路径中读取文件? 目的:就是希望在项目的配置文件中配上一样的路径,不管协作者使用的是什么平台,都能够读到文件. 比如:L ...
- selenium网页没加载完成就停止加载并自动刷新
判断一个网页10秒没加载完成就停止加载并自动刷新 driver=webdriver.Chome() driver.set_page_load_timeout(10) while True: try: ...
- Openstak(M版)计算节点安装
#############修改hosts文件 10.0.0.11 controller10.0.0.31 compute110.0.0.32 compute210.0.0.41 block110.0. ...
- or and 运算符与 pyhton编码
运算符 # x or y 如果 x 为真,则值为x,否则为y 1 print(4 or 3) # 4 2 print(2 or 3) # 2 3 print(1 or 3) # 1 4 print(0 ...