Impala简介PB级大数据实时查询分析引擎
1、Impala简介
• Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
• 基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点
• 是CDH平台首选的PB级大数据实时查询分析引擎
官网:http://www.cloudera.com/products/apache-hadoop/impala.html
http://www.impala.io/index.html
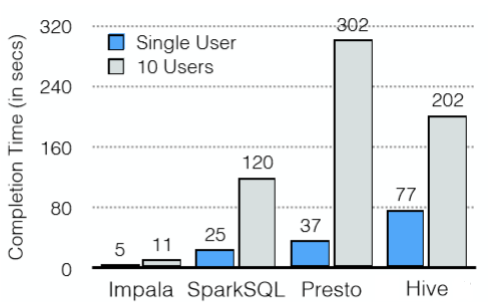
下面是在基于单用户和多用户查询的时候,不同的查询分析器所使用的时间:
2、Impala的特点
• 1、基于内存进行计算,能够对PB级数据进行交互式实时查询、分析
• 2、无需转换为MR,直接读取HDFS数据
• 3、C++编写,LLVM统一编译运行
• 4、兼容HiveSQL
• 5、具有数据仓库的特性,可对hive数据直接做数据分析
• 6、支持Data Local
• 7、支持列式存储
• 8、支持JDBC/ODBC远程访问
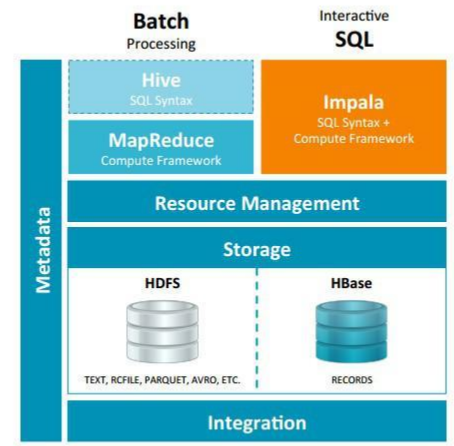 (相比于Hive,Impala不需要启动MapReduce直接同HDFS或HBase进行交互)
(相比于Hive,Impala不需要启动MapReduce直接同HDFS或HBase进行交互)
3、Impala 劣势
• 1、对内存依赖大
• 2、C++编写 开源?!
• 3、完全依赖于hive
• 4、实践过程中 分区超过1w 性能严重下下降
• 5、稳定性不如hive
4、Impala安装
• 安装方式:
– 1、ClouderaManager
– 2、手动安装(待续)
可以使用CDH安装,方便快捷,而且管理起来更加方便,下面是CDH安装以后的CDH管理界面:
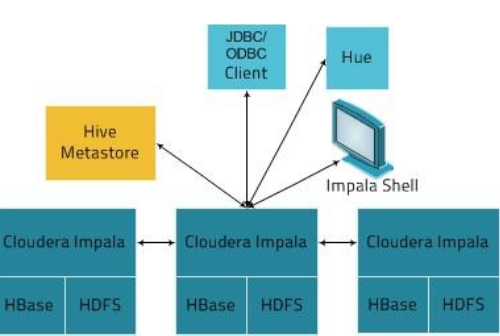
5、Impala核心组件
• Statestore Daemon
• 实例*1 - statestored
– 负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息.
– 负责query的调度
• Catalog Daemon
• 实例*1 - catalogd
– 分发表的元数据信息到各个impalad中
– 接收来自statestore的所有请求
• Impala Daemon
• 实例*N – impalad
– 接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点
– 子节点上的守护进程,负责向statestore保持通信,汇报工作
6、Impala架构
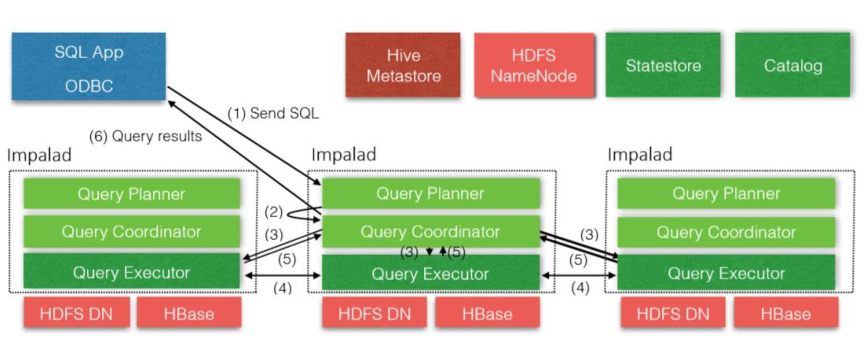
(1) 由Client发送一个执行SQL到任意一台Impalad的Query Planner
(2) 由Query Planner 把SQL发向Query Coordinator
(3) 由Query Coordinator 来调度分配任务到Impalad的所有节点
(4) 各个Impalad节点的Query Executor 进行执行SQL工作
(5) 执行SQL结束以后,将结果返回给Query Coordinator
(6) 再由Query Coordinator 将结果返回给Client
 阅读全文
阅读全文Impala简介PB级大数据实时查询分析引擎的更多相关文章
- Druid:一个用于大数据实时处理的开源分布式系统——大数据实时查询和分析的高容错、高性能开源分布式系统
转自:http://www.36dsj.com/archives/28590 Druid 是一个用于大数据实时查询和分析的高容错.高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分 ...
- 腾讯云EMR大数据实时OLAP分析案例解析
OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值.本文基于QQ音乐海量大数据实时分析场景,通过QQ音乐与腾 ...
- 使用Oracle Stream Analytics 21步搭建大数据实时流分析平台
概要: Oracle Stream Analytics(OSA)是企业级大数据流实时分析计算平台.它可以通过使用复杂的关联模式,扩充和机器学习算法来自动处理和分析大规模实时信息.流式传输的大数据可以源 ...
- [NewLife.XCode]分表分库(百亿级大数据存储)
NewLife.XCode是一个有15年历史的开源数据中间件,支持netcore/net45/net40,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量 ...
- 《深度访谈:华为开源数据格式 CarbonData 项目,实现大数据即席查询秒级响应》
深度访谈:华为开源数据格式 CarbonData 项目,实现大数据即席查询秒级响应 Tina 阅读数:146012016 年 7 月 13 日 19:00 华为宣布开源了 CarbonData ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
- Storm 实战:构建大数据实时计算
Storm 实战:构建大数据实时计算(阿里巴巴集团技术丛书,大数据丛书.大型互联网公司大数据实时处理干货分享!来自淘宝一线技术团队的丰富实践,快速掌握Storm技术精髓!) 阿里巴巴集团数据平台事业部 ...
随机推荐
- Java中抽象类与接口的比较
一.基本概念 抽象类:表示这个对象是什么:比如 男人.女人这两个类,他们的抽象类是人,说明男人.女人是人: 接口:表示这个对象能做什么:比如人可以吃东西,狗也可以吃东西,将“吃东西”定义为一个接口,让 ...
- MySQL传输表空间使用方法
1.目标端创建同样的表结构 CREATE TABLE `test` ( `id` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHAR ...
- Ajax异步交互
一.简介 Ajax(Asynchronous JavaScript and XML).一般都写为Ajax. Ajax是与服务器交换数组并更新部分网页的艺术.最初的使用时2005中Google Sugg ...
- dom4j里面封装方法的操作
animal.xml <?xml version="1.0" encoding="UTF-8"?><animal> <cat ...
- thinkphp模板如何转换时间格式?
<!-- 如果有日期输出,即$data.time不为空且不为0,则格式化时间戳,否则默认当前时间戳,并格式化成日期格式 --> {$data.time|default=time()|dat ...
- ubuntu系統如何啟動root用戶登陸?
之前分享過關於這個問題的文章,現在自己在分享一個關於這個問題的文章給大家.為了學習Linux,一氣之下把win10的換成了ubuntu的系統.安裝就不給大家介紹了(網上很多教程). 在我們安裝好之後, ...
- Apache Maven(五):插件
Maven的插件分如下两种: build plugins:该插件在项目构建阶段执行,它们都在<build>标签中设置. reporting plugins : 该插件在网站生成期间执行,他 ...
- js bom和dom
一, 前言 到目前为止,我们已经学过了JavaScript的一些简单的语法.但是这些简单的语法,并没有和浏览器有任何交互. 也就是我们还不能制作一些我们经常看到的网页的一些交互,我们需要继续学习BOM ...
- 003---socket介绍
socket介绍 什么是socket? socket是应用层与tcp/ip协议族通信的中间软件抽象层,它是一组接口.在设计模式中.其实就是一个门面模式.我们无需深入理解tcp/udp协议,socket ...
- Json格式化时间
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")@JsonFormat(timezone = "GMT+8", ...