Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Kaiming
He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
The
13th European Conference on Computer Vision (ECCV), 2014
声明:本文所有图片均来自原始文章,自己的理解也未必正确,请查看原图并拍砖
本文的两个亮点:
1. 多尺度训练CNN。
2. 将图像分割后的特征转换为最小计算量,大大加速了detection的速度。
关于第一点:我们知道,卷积保留了图像的spatial信息,同时卷积层其实是不受输入图像大小的限制的,之所以在训练CNN时,需要固定图像尺寸,主要是由于全连接层的输入需要固定维度的。但是,如果在进全连接层之前的一层,我们把无论多大的图都转换到相同维度,这样前面其实是不限制图像大小的。SPP在这里就起到了这个作用。这样做一呢,解除了图像大小的限制,二呢,可以多尺度图像同时进行训练CNN。从作者的实验结果来看,确实是效果提升的。而在VGG的工作中,人为random选择输入图像尺寸进行变换,然后再裁图到224X224进行CNN训练,就提高了分类效果。SPP的这种做法是另外一种多尺度吧,和VGG的这种不是很一样其实,如下图所示,在用SPP的效果,以及用了SPP同时采用多尺度的分类效果,多尺度进行训练CNN效果要比之前提高不少。

Spp在cnn中的框架应用图,基本思路就是用spp代替CNN中最后一个pooling层。其实,用更直白的话理解就是,由一个pooling变成了多个scale的pooling了。这种多尺度的应用,必定会给分类带来好处的,这也是这个文章的一个亮点。如下图所示,只是在pooling的时候,需要注意一下,文章中说到的1X1,2X2,…不是pooling的窗口大小,而是pooling后的大小,即pooling后变成了1x1的一个bin,2X2的4个bins,等等,这个就是multi level的过程,而传统的滑动窗口的方式是single level的方式。于是,在pooling过程中,窗口的大小和步长的大小都需要去计算,这样也有个好处,就是进来的conv5的输出无论出来多大维度的信息,都可以将其pooling到同一个维度上。如下图所示,再把1X1,2X2,…等这些信息组合展开作为fc6的输入。

至此,SPP在CNN中用于分类的效果可见一斑。比较一下,这部分工作还是很牛的,简单的几层CNN,只是多了一个spp ,分类效果提升了不少。对比当今的网络结构,他们只用了最原始的几层CNN,没有做深度加深,就提升了不少效果,速度快,训练起来也是很灵活的,即使你只有CPU也可以,单个GPU也可以,不用去搭建多机多卡什么的,效果就不错了。
上面是SPP在分类中的应用,那么在检测中怎么用呢?其实,很多人赞这篇文章,可能大多数是因为这个(窃以为啊)。我们知道,目前做物体检测的,或者说做视觉的,效果基本上被各种CNN刷新了。检测也是,是基于CNN的R-CNN,也就是region CNN,也是berkely那帮人搞的,原理其实也不算复杂,但是其实相当复杂的。R-CNN的图可以见下图,其流程就是先对一张图用图像分割,比如selective search, random prime, bing等方法分割成若干个小的regions,当然这些regions其实基本上是被视为是一个完整物体的regions,然后将这些regions作为CNN的输入,利用CNN提取这些regions的图像特征,当然是最后一层softmax去掉的,然后进SVM分类器,从而得到这些regions是哪一类,当然由于你已经得到regions了,因而你也能得到这些regions在原始图中的坐标,于是物体检测的任务就完成了。当然,说着是不算复杂,但是仔细分析,其中涉及到几个大模块:1. 分割,regions提取,这个有专门的研究吧,比如selective search, random prime, bing等等,效果下降趋势,当然速度上升趋势。2.
Cnn的fine tuning或者训练,你需要用这些待检测或者与检测物体相关的图像做训练数据集,怎么选,这个也会决定其效果的。3. SVM模块,分类器SVM的训练,学问大大的奥。我是菜鸟,不多说了,看原始文章和代码吧https://github.com/rbgirshick/rcnn。
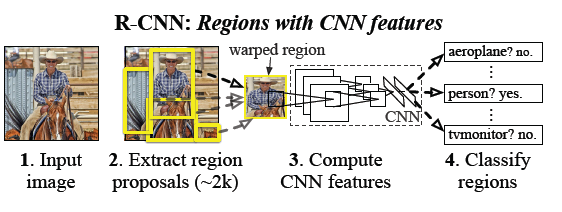
RCNN简直是划时代的出现,刷新了各种物体检测效果。但是,其有个最大问题就是计算量问题。你想啊,那么多regions都进CNN,而根据我们做图像分割的经验,这些regions之间肯定存在重叠的,所以计算量一下子多了太多。Ss的方式,400X500的图,大概有2000多个regions生成啊。
而SPP用在detection中,恰恰就避免了R-CNN重复计算的问题。
其实,之前我们也看过不少文章,比如regionlets等等(文章:Generic Object Detection With Dense Neural Patterns and Regionlets),但是这个方法效果并不是很好,原因是其用直方图的方式将最后卷积层出来的特征统一维度,这样做将CNN中具有spatial的特征全部抹掉了,而且直方图本身也将CNN的良好描述能力抹杀了不少啊。在看看regionlets的文章,我觉得可能有两个原因效果没那么好,一个是图的尺寸太小,另外一个原因是region是随机组合选取的,可能按照selective search等这种方式来选取region再做histogram,我感觉就是average pooling效果应该不错。当时看到regionlets这篇文章时,我们也想用别的组合方式,将最后一层的特征进行组合,但是没想到合适的,水平啊……
SPP用在CNN中用来做detection的框架图如下图所示:
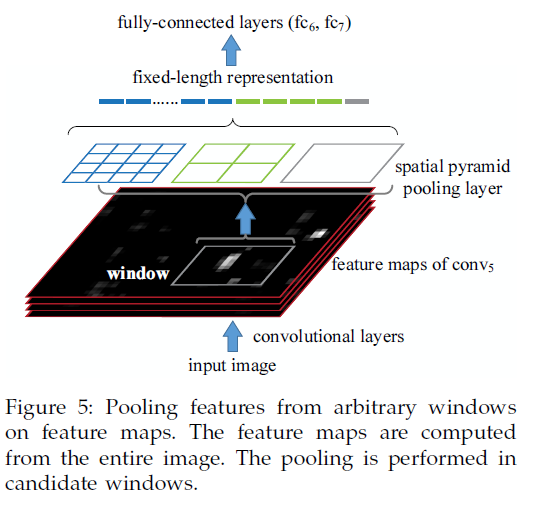
其实,在这里也是要做图像分割的,但是,并不是要所有2000个regions都进CNN提取特征,而是一张原始图进CNN提取特征,这2000个regions不是有坐标吗?因此在conv5之后,也能知道对应的windows是哪里。然后,我们要对这些windows用上面介绍的SPP的方式,用多个尺度的pooling分别进fc层,然后是SVM,从而判断这些windows进而对应的regions是否是某一个目标。这样做能够节省大量计算量,因为在CNN中,其实卷积和pooling占据了80%左右的计算时间,而SPP只是放在最后一个pooling层了,因此,时间节省是大大的,根据作者文章说的,大概快了20-60倍啊。原来我们觉得可能这样以来,就可以工程应用了,但是目前来看,估计时间还是瓶颈,因为其实前面region分割的时间也不少,selective search大约要1s呢。
值得提到的一点是,在文中,作者用的图像大小最小是480的,猜测可能用过小尺寸,但是效果不好。想想也知道,如果用特别小的原始图像,经过一系列conv和pooling后,有些小的region可能会被干掉了。但是把原始图放大了,应该在最后还有保留的。具体原始图像中的坐标怎么和最后conv5出来的对应上,作者文章中给了附录,计算方式和另外一篇文章Generic Object Detection With Dense Neural Patterns and Regionlets中给出的类似,原理就是conv和pooling降维的尺寸一个一个计算。文章第二版的信息量很大,值得好好研读的,细节的东西不少,期待作者早点放出来代码。
代码:https://github.com/ShaoqingRen/SPP_net
PS.最近两周多,在自己机器上搭建caffe windows和spp_net,折腾人的很啊,最终还是搞定了。
测试了一下,个人普通台式机,CPU下,多尺度(5个尺度)的spp下,一张pascal的图大概要50s的时间,这个也是可以理解的,毕竟都要cnn卷积一遍,这个是很费时间的。单个尺度的话,10s一张图。实际测试下来,当图片输入是480时,典型的目标已经无法得到了。
另外,由于要求输入的图像可以是大图片的,而且一次性存了不少张,我怀疑我的GPU不够用,在申请空间时,GPU挂掉。CPU比GPU存储大,就没事。
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition的更多相关文章
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- SPP Net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)论文理解
论文地址:https://arxiv.org/pdf/1406.4729.pdf 论文翻译请移步:http://www.dengfanxin.cn/?p=403 一.背景: 传统的CNN要求输入图像尺 ...
- 论文解读2——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
背景 用ConvNet方法解决图像分类.检测问题成为热潮,但这些方法都需要先把图片resize到固定的w*h,再丢进网络里,图片经过resize可能会丢失一些信息.论文作者发明了SPP pooling ...
- SPP NET (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
1. https://www.cnblogs.com/gongxijun/p/7172134.html (SPP 原理) 2.https://www.cnblogs.com/chaofn/p/9305 ...
- 目标检测(二)SSPnet--Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognotion
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun 以前的CNNs都要求输入图像尺寸固定,这种硬性要求也许会降低识别任意尺寸图像的准确度. ...
- Paper Reading - Long-term Recurrent Convolutional Networks for Visual Recognition and Description ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1411.4389 Main Points: A novel Recurrent Convolutional Arch ...
随机推荐
- Python正则表达
```# -*- coding:utf-8 -*-import re re - Support for regular expressions (RE).正则表达式是一个特殊的字符序列,它能帮助你方便 ...
- Oracle 数据类型详解
数据类型(datatype)是列(column)或存储过程中的一个属性. Oracle支持的数据类型可以分为三个基本种类:字符数据类型.数字数据类型以及表示其它数据的数据类型. 字符数据类型 CHAR ...
- Machine Learning的定义
---恢复内容开始--- 所下内容都是对吴恩达教授的机器学习所做的笔记 下面是Arthur Samue对机器学习的定义 在没有明确设置的情况下,是计算机具有学习能力的研究领域. 这是一个比较陈旧一点的 ...
- python30题
1.执行Python 脚本的两种方式 使用python解释器(python aa.py)或在unix系统下赋值成777,执行(./aa.py) 2.简述位.字节的关系 1个byte = 8bit,在A ...
- OpenStack各组件详解和通信流程
一.openstack由来 openstack最早由美国国家航空航天局NASA研发的Nova和Rackspace研发的swift组成.后来以apache许可证授权,旨在为公共及私有云平台建设.open ...
- java线程安全问题原理性分析
1.什么是线程安全问题? 从某个线程开始访问到访问结束的整个过程,如果有一个访问对象被其他线程修改,那么对于当前线程而言就发生了线程安全问题:如果在整个访问过程中,无一对象被其他线程修改,就是线程安全 ...
- SCI收录的期刊查询
SCI 收录的期刊查询(动态) 1.Science Citation Index (SCI)收录期刊查询地址:http://www.isinet.com/cgi-bin/jrnlst/jlopti ...
- 从虚拟机角度看Java多态->(重写override)的实现原理
工具与环境:Windows 7 x64企业版Cygwin x64jdk1.8.0_162 openjdk-8u40-src-b25-10_feb_2015Vs2010 professional 0x0 ...
- sql字段合并与分组聚合
http://blog.csdn.net/cuixianlong/article/details/74024846 1 字段合并 原始数据如下:表名为Employee ID FirstName Las ...
- 【css基础】html图片右上角加上删除按钮
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...