6.python探测Web服务质量方法之pycurl模块
才开始学习的时候有点忽略了这个模块,觉得既然Python3提供了requests库,为什么多此一举学习这个模块。后来才发现pycurl在探测Web服务器的时候的强大。
pycurl是一个用c语言写的libcurl Python实现,支持的操作协议有FTP,HTTP,HTTPS,TELNET等,可以理解成linux下curl命令功能的python封装。通过调用pycurl提供的方法,实现探测Web服务质量的情况,比如响应的HTTP状态码,请求延时,HTTP头信息,下载速度等,利用这些信息可以定位服务响应卡顿缓慢的具体环节。
安装使用命令:pip install pycurl,如果下载失败参考我上一篇总结的安装方法。
模块常用方法的说明:https://curl.haxx.se/libcurl/c/libcurl-tutorial.html
pycurl.Curl()类实现创建一个libcurl包的Curl句柄对象,无参数。更多介绍libcurl包的介绍见:
下面介绍Curl对象几个常用的方法:
- close()方法,对应libcurl包中的curl_easy_cleanup方法,无参数,实现关闭,回收Curl对象。
- perform()方法,对应libcurl包中的curl_easy_perform方法,无参数,实现Curl对象请求的提交。
- setopt(option,value)方法,对应libcurl包中curl_easy_setopt方法,参数option是通过libcurl的常量来指定的,参数value的值会依赖option,可以是一个字符串,整型,长整型,文件对象,列表,函数等。下面列举常用的常量列表:
c = pycurl.Curl() #创建一个curl对象 c.setopt(pycurl.CONNECTTIMEOUT, ) #连接的等待时间,设置为0则不等待 c.setopt(pycurl.TIMEOUT, ) #请求超时时间 c.setopt(pycurl.NOPROGRESS, ) #是否屏蔽下载进度条,非0则屏蔽 c.setopt(pycurl.MAXREDIRS, ) #指定HTTP重定向的最大数 c.setopt(pycurl.FORBID_REUSE, ) #完成交互后强制断开连接,不重用 c.setopt(pycurl.FRESH_CONNECT,) #强制获取新的连接,即替代缓存中的连接 c.setopt(pycurl.DNS_CACHE_TIMEOUT,) #设置保存DNS信息的时间,默认为120秒 c.setopt(pycurl.URL,"http://www.baidu.com") #指定请求的URL c.setopt(pycurl.USERAGENT,"Mozilla/5.2 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50324)") #配置请求HTTP头的User-Agent c.setopt(pycurl.HEADERFUNCTION, getheader) #将返回的HTTP HEADER定向到回调函数getheader c.setopt(pycurl.WRITEFUNCTION, getbody) #将返回的内容定向到回调函数getbody c.setopt(pycurl.WRITEHEADER, fileobj) #将返回的HTTP HEADER定向到fileobj文件对象 c.setopt(pycurl.WRITEDATA, fileobj) #将返回的HTML内容定向到fileobj文件对象
- getinfo(option)方法,对应libcurl包中的curl_easy_getinfo方法,参数option是通过libcurl的常量来指定的。下面列举常用的常用列表:
c = pycurl.Curl() #创建一个curl对象
c.getinfo(pycurl.HTTP_CODE) #返回的HTTP状态码 c.getinfo(pycurl.TOTAL_TIME) #传输结束所消耗的总时间 c.getinfo(pycurl.NAMELOOKUP_TIME) #DNS解析所消耗的时间 c.getinfo(pycurl.CONNECT_TIME) #建立连接所消耗的时间 c.getinfo(pycurl.PRETRANSFER_TIME) #从建立连接到准备传输所消耗的时间 c.getinfo(pycurl.STARTTRANSFER_TIME) #从建立连接到传输开始消耗的时间 c.getinfo(pycurl.REDIRECT_TIME) #重定向所消耗的时间 c.getinfo(pycurl.SIZE_UPLOAD) #上传数据包大小 c.getinfo(pycurl.SIZE_DOWNLOAD) #下载数据包大小 c.getinfo(pycurl.SPEED_DOWNLOAD) #平均下载速度 c.getinfo(pycurl.SPEED_UPLOAD) #平均上传速度 c.getinfo(pycurl.HEADER_SIZE) #HTTP头部大小
实践:实现探测Web服务质量
HTTP服务是最流行的互联网应用之一,服务质量的好坏关系到用户体验以及网站的运营服务水平,最常用的有两个标准,
一为服务的可用性,比如是否处于正常提供服务状态,而不是出现404页面未找到或500页面错误等;
二为服务的响应速度,比如静态类文件下载时间都控制在毫秒级,动态CGI为秒级。
本示例使用pycurl的setopt与getinfo方法实现HTTP服务质量的探测,获取监控URL返回的HTTP状态码,HTTP状态码采用pycurl.HTTP_CODE常量得到,以及从HTTP请求到完成下载期间各环节的响应时间,通过pycurl.NAMELOOKUP_TIME,pycurl.CONNECT_TIME,pycurl.PRETRANSFER_TIME,pycurl.R等常量来实现。另外通过pycurl.WRITEHEADER,pycurl.WRITEDATA常量得到目标URL的HTTP响应头部及页面内容。
import os,sys
import time
import pycurl URL = "www.baidu.com" #探测的目标URL
c = pycurl.Curl() #创建一个Curl对象
c.setopt(pycurl.URL,URL) #定义请求的URL常量
c.setopt(pycurl.CONNECTTIMEOUT,) #定义请求连接的等待时间
c.setopt(pycurl.TIMEOUT,) #定义请求超时时间
c.setopt(pycurl.NOPROGRESS,) #屏蔽下载进度条
c.setopt(pycurl.MAXREDIRS,) #指定HTTP重定向的最大数为1
c.setopt(pycurl.FORBID_REUSE,) #完成交互后强制断开连接,不重用
c.setopt(pycurl.DNS_CACHE_TIMEOUT,) #设置保存DNS信息的时间为30秒 #创建一个文件对象,以“wb”方式打开,用来存储返回的http头部及页面的内容
indexfile = open(os.path.dirname(os.path.realpath(__file__))+"/content.txt","wb")
c.setopt(pycurl.WRITEHEADER,indexfile) #将返回的HTTP HEADER定向到indexfile文件
c.setopt(pycurl.WRITEDATA,indexfile) #将返回的HTML内容定向到indexfile文件 try:
c.perform()
except:
print("连接错误")
indexfile.close()
c.close()
sys.exit() NAMELOOKUP_TIME = c.getinfo(c.NAMELOOKUP_TIME) #DNS解析所消耗的时间
CONNECT_TIME = c.getinfo(c.CONNECT_TIME) #建立连接所消耗的时间
PRETRANSFER_TIME = c.getinfo(c.PRETRANSFER_TIME) #从建立连接到准备传输所消耗的时间
STARTTRANSFER_TIME = c.getinfo(c.STARTTRANSFER_TIME) #从建立连接到传输开始消耗的时间
TOTAL_TIME = c.getinfo(c.TOTAL_TIME) #传输结束所消耗的总时间
HTTP_CODE = c.getinfo(c.HTTP_CODE) #返回HTTP状态码
SIZE_DOWNLOAD = c.getinfo(c.SIZE_DOWNLOAD) #下载数据包的大小
HEADER_SIZE = c.getinfo(c.HEADER_SIZE) #HTTP头部大小
SPEED_DOWNLOAD = c.getinfo(c.SPEED_DOWNLOAD) #平均下载速度 #打印输出相关数据
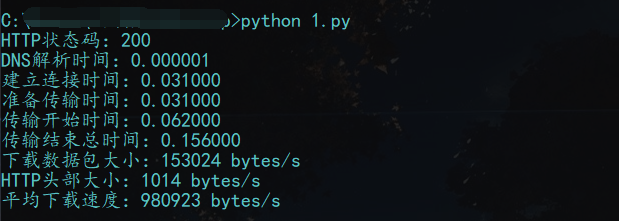
print("HTTP状态码:%s" % HTTP_CODE)
print("DNS解析时间:%2f" % NAMELOOKUP_TIME)
print("建立连接时间:%2f" % CONNECT_TIME)
print("准备传输时间:%2f" % PRETRANSFER_TIME)
print("传输开始时间:%2f" % STARTTRANSFER_TIME)
print("传输结束总时间:%2f" % TOTAL_TIME)
print("下载数据包大小:%d bytes/s" % SIZE_DOWNLOAD)
print("HTTP头部大小:%d bytes/s" % HEADER_SIZE)
print("平均下载速度:%d bytes/s" % SPEED_DOWNLOAD) #关闭文件及Curl对象
indexfile.close()
c.close()
代码来自<<Python 自动化运维>>这本书。
代码执行结果:
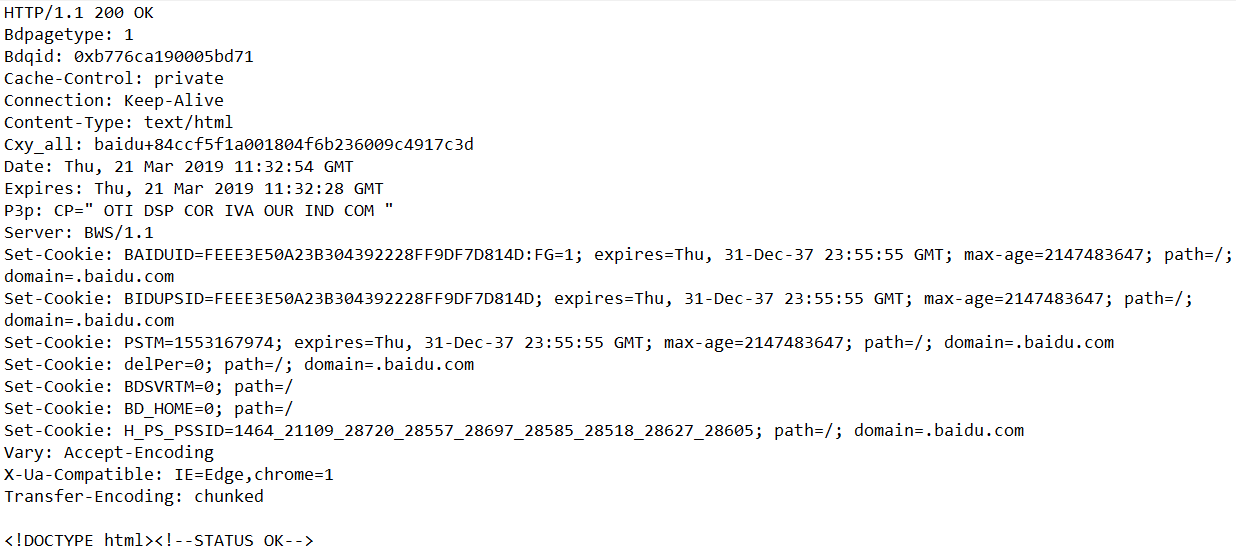
查看获取的HTTP文件头部及页面内容文件content.txt
6.python探测Web服务质量方法之pycurl模块的更多相关文章
- 探测web服务质量方法
- [Python]实践:实现探测Web服务质量
来源:Python 自动化运维 技术与最佳实践 HTTP服务是最流行的互联网应用之一,服务质量的好坏关系到用户体验以及网站的运营服务水平,最常用的有两个标准:1.服务的可用性,比是否处于正常提供服务状 ...
- python3之模板pycurl探测web服务质量
1.pycurl简介 pycURL是libcurl多协议文件传输库的python接口,与urllib模块类似,PycURL可用于从python程序中获取由URL标识的对象,功能很强大,libcurl速 ...
- Python学习笔记 - 实现探测Web服务质量
#!/usr/bin/python3# _*_ coding:utf-8 _*_import sys, osimport timeimport pycurl url = "https://d ...
- 使用pycurl探测web服务质量
1:pycurl模块的安装方法 easy_install pycurl pip install pycurl 2:示例代码如下,是在python3下实现的,如若使用python2稍作修改即可 # -* ...
- 探测web服务器质量——pycurl
pycurl是一个用C语言写的libcurl Python实现,功能非常强大,支持的操作协议有FTP.HTTP.HTTPS.TELNET等,可以理解为Linux下curl命令功能的Python封装,简 ...
- Python 的PyCurl模块使用
PycURl是一个C语言写的libcurl的python绑定库.libcurl 是一个自由的,并且容易使用的用在客户端的 URL 传输库.它的功能很强大,PycURL 是一个非常快速(参考多并发操作) ...
- Python之Web前端jQuery扩展
Python之Web前端: 一. jQuery表单验证 二. jQuery扩展 三. 滚动菜单 一. jQuery表单验证: 任何可以交互的站点都有输入表单,只要有可能,就应该对用户输入的数据进行验证 ...
- Python之Web前端Dom, jQuery
Python之Web前端: Dom jQuery ###Dom 一. 什么是Dom? 文档对象模型(Document Object Model,DOM)是一种用于HTML和XML文档的编程接口.它 ...
随机推荐
- js删除局部变量的实现方法
lert('value:'+str+'\ttype:'+typeof(str)) //声明变量前,引用 var str="dd"; alert('value:'+str+'\tty ...
- JVM介绍(二)
1 JVM简介 JVM是我们Javaer的最基本功底了,刚开始学Java的时候,一般都是从“Hello World”开始的,然后会写个复杂点class,然后再找一些开源框架,比如Spring,Hibe ...
- maven打war包后无法依赖本地工程的jar包,造成debug时跳到class文件而不是本地java文件
问题现象:项目结构如下 growup-service | - - - - - -growup-api | - - - - - -growup-core | - - - - - -growup-war ...
- emqtt 2 (我要连服务器)
这一篇,主要分析下,client 是怎么 connect server的,以及成功connect server 之后,会做哪些事情,session是怎么 start的. 由protocol 开始 之前 ...
- linux下安装ZipArchive扩展和libzip扩展
在项目开发的时候,由于要下载多个录音文件,我就需要打包下载这个功能 学习源头: https://www.landui.com/help/show-8079 https://www.aliyun.com ...
- maven环境配置详解,及maven项目的搭建及maven项目聚合
首先:Maven 3.2.1:不同版本中仓库中文件是不一样的,Maven运行,先找用户配置,再找全局配置 1. Maven全局配置:全局统一的配置文件,在maven的安装目录中 2. Maven用户配 ...
- java里的switch循环--你妹考试落榜了
总结:switch循环,不用break.那么程序每一个case都会运行到,直到遇到break停止 package com.aa; //格子区域 //3行3列的格子 public class Bu { ...
- 初学者手册-IDEA常用快捷键
一.快速创建基于某个接口的类(引入相关包) 左键选择接口名称,使用快捷键Alt+enter,然后实现该类 二.打开选中的文件所在的文件夹 点选需要打开的文件,右键菜单,点击“Show in Explo ...
- 1074 Reversing Linked List
题意: 每k个元素反转链表,不足k个就不反转.如原链表为1→2→3→4→5→6,k=3,则反转后的链表为3→2→1→6→5→4:若k=4,则反转后的链表为4→3→2→1→5→6. 思路: 这题会比较烦 ...
- js 格式化相关的时间
javascript Date format(js日期格式化) 方法一: // 对Date的扩展,将 Date 转化为指定格式的String // 月(M).日(d).小时(h).分(m).秒(s). ...