CNN神经网络之卷积操作
作者:凌逆战
地址:https://www.cnblogs.com/LXP-Never/p/10763804.html
在看这两个函数之前,我们需要先了解一维卷积(conv1d)和二维卷积(conv2d),二维卷积是将一个特征图在width和height两个方向进行滑动窗口操作,对应位置进行相乘求和;而一维卷积则只是在width或者height方向上进行滑动窗口并相乘求和。
一维卷积:tf.layers.conv1d()
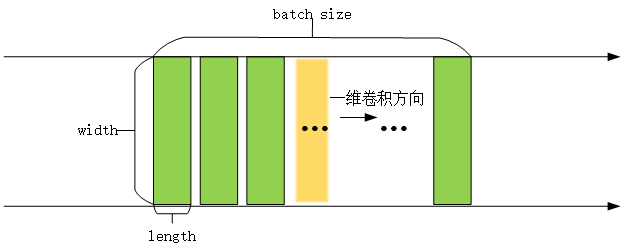
一维卷积常用于序列数据,如自然语言处理领域。
- tf.layers.conv1d(
- inputs,
- filters,
- kernel_size,
- strides=1,
- padding='valid',
- data_format='channels_last',
- dilation_rate=1,
- activation=None,
- use_bias=True,
- kernel_initializer=None,
- bias_initializer=tf.zeros_initializer(),
- kernel_regularizer=None,
- bias_regularizer=None,
- activity_regularizer=None,
- kernel_constraint=None,
- bias_constraint=None,
- trainable=True,
- name=None,
- reuse=None
- )
参数:[1]
- inputs:张量数据输入,一般是[batch, width, length]
- filters:整数,输出空间的维度,可以理解为卷积核(滤波器)的个数
kernel_size:单个整数或元组/列表,指定1D(一维,一行或者一列)卷积窗口的长度。- strides:单个整数或元组/列表,指定卷积的步长,默认为1
- padding:"SAME" or "VALID" (不区分大小写)是否用0填充,
- SAME用0填充;
- VALID不使用0填充,舍去不匹配的多余项。
- activation:激活函数
- ues_bias:该层是否使用偏差
- kernel_initializer:卷积核的初始化
- bias_initializer:偏置向量的初始化器
- kernel_regularizer:卷积核的正则化项
- bias_regularizer:偏置的正则化项
- activity_regularizer:输出的正则化函数
- reuse:Boolean,是否使用相同名称重用前一层的权重
- trainable:Boolean,如果True,将变量添加到图collection中
- data_format:一个字符串,一个channels_last(默认)或channels_first。输入中维度的排序。
- channels_last:对应于形状的输入(batch, length, channels)
- channels_first:对应于形状输入(batch, channels, length)
- name = 取一个名字
返回值:
一维卷积后的张量,
例子
- import tensorflow as tf
- x = tf.get_variable(name="x", shape=[32, 512, 1024], initializer=tf.zeros_initializer)
- x = tf.layers.conv1d(
- x,
- filters=1, # 输出的第三个通道是1
- kernel_size=512, # 不用管它是多大,都不影响输出的shape
- strides=1,
- padding='same',
- data_format='channels_last',
- dilation_rate=1,
- use_bias=True,
- bias_initializer=tf.zeros_initializer())
- print(x) # Tensor("conv1d/BiasAdd:0", shape=(32, 512, 1), dtype=float32)
解析:
- 输入数据的维度为[batch, data_length, data_width]=[32, 512, 1024],一般输入数据input第一维为batch_size,此处为32,意味着有32个样本,第二维度和第三维度分别表示输入的长和宽(512,1024)
- 一维卷积核是二维的,也有长和宽,长为卷积核的数量kernel_size=512,因为卷积核的数量只有一个,所以宽为输入数据的宽度data_width=1024,所以一维卷积核的shape为[512,1024]
- filteres是卷积核的个数,即输出数据的第三维度。filteres=1,第三维度为1
- 所以卷积后的输出数据大小为[32, 512, 1]
二维卷积:tf.layers.conv2d()
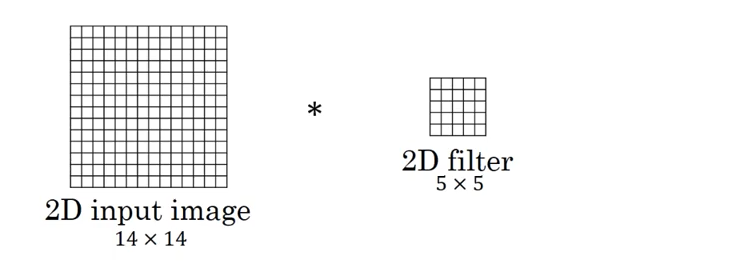
二维卷积常用于计算机视觉、图像处理领域
- tf.layers.conv2d(
- inputs,
- filters,
- kernel_size,
- strides=(1, 1),
- padding='valid',
- data_format='channels_last',
- dilation_rate=(1, 1),
- activation=None,
- use_bias=True,
- kernel_initializer=None,
- bias_initializer=tf.zeros_initializer(),
- kernel_regularizer=None,
- bias_regularizer=None,
- activity_regularizer=None,
- kernel_constraint=None,
- bias_constraint=None,
- trainable=True,
- name=None,
- reuse=None
- )
参数:[4]
inputs:张量输入。一般是[batch, width, length,channel]filters:整数,输出空间的维度,可以理解为卷积核(滤波器)的个数kernel_size:2个整数或元组/列表,指定2D卷积窗口的高度和宽度。可以是单个整数,以指定所有空间维度的相同值。strides:2个整数或元组/列表,指定卷积沿高度和宽度方向的步幅。可以是单个整数,以指定所有空间维度的相同值。- padding:"SAME" or "VALID" (不区分大小写)是否用0填充,
- SAME用0填充;
- VALID不使用0填充,舍去不匹配的多余项。
data_format:字符串,"channels_last"(默认)或"channels_first"。输入中维度的排序。channels_last:对应于具有形状的输入,(batch, height, width, channels)channels_first:对应于具有形状的输入(batch, channels, height, width)
activation:激活函数use_bias:Boolean, 该层是否使用偏差项kernel_initializer:卷积核的初始化bias_initializer: 偏置向量的初始化。如果为None,将使用默认初始值设定项kernel_regularizer:卷积核的正则化项bias_regularizer: 偏置矢量的正则化项activity_regularizer:输出的正则化函数trainable:Boolean,如果True,将变量添加到图collection中name:图层的namereuse:Boolean,是否使用相同名称重用前一层的权重
返回:
二维卷积后的张量
例子:
- import tensorflow as tf
- x = tf.get_variable(name="x", shape=[1, 3, 3, 5], initializer=tf.zeros_initializer)
- x = tf.layers.conv2d(
- x,
- filters=1, # 结果的第三个通道是1
- kernel_size=[1, 1], # 不用管它是多大,都不影响输出的shape
- strides=[1, 1],
- padding='same',
- data_format='channels_last',
- use_bias=True,
- bias_initializer=tf.zeros_initializer())
- print(x) # shape=(1, 3, 3, 1)
解析:
- input输入是1张 3*3 大小的图片,图像通道数是5,输入shape=(batch, data_length, data_width, data_channel)
- kernel_size卷积核shape是 1*1,数量filters是1strides步长是[1,1],第一维和第二维分别为长度方向和宽度方向的步长 = 1。
- 最后输出的shape为[1,3,3,1] 的张量,即得到一个3*3的feature map(batch,长,宽,输出通道数)
- 长和宽只和strides有关,最后一个维度 = filters。
卷积层中的输出大小计算
设输入图片大小W,Filter大小F*F,步长为S,padding为P,输出图片的大小为N:
$$N=\frac{W-F+2P}{S}+1$$
向下取整后再加1。
在Tensoflow中,Padding有2个选型,'SAME'和'VALID' ,下面举例说明差别:
如果 Padding='SAME',输出尺寸为: W / S(向上取整)
- import tensorflow as tf
- input_image = tf.get_variable(shape=[64, 32, 32, 3], dtype=tf.float32, name="input", initializer=tf.zeros_initializer)
- conv0 = tf.layers.conv2d(input_image, 64, kernel_size=[3, 3], strides=[2, 2], padding='same') # 32/2=16
- conv1 = tf.layers.conv2d(input_image, 64, kernel_size=[5, 5], strides=[2, 2], padding='same')
- # kernel_szie不影响输出尺寸
- print(conv0) # shape=(64, 16, 16, 64)
- print(conv1) # shape=(64, 16, 16, 64)
如果 Padding='VALID',输出尺寸为:(W - F + 1) / S
- import tensorflow as tf
- input_image = tf.get_variable(shape=[64, 32, 32, 3], dtype=tf.float32, name="input", initializer=tf.zeros_initializer)
- conv0 = tf.layers.conv2d(input_image, 64, kernel_size=[3, 3], strides=[2, 2], padding='valid') # (32-3+1)/2=15
- conv1 = tf.layers.conv2d(input_image, 64, kernel_size=[5, 5], strides=[2, 2], padding='valid') # (32-5+1)/2=14
- print(conv0) # shape=(64, 15, 15, 64)
- print(conv1) # shape=(64, 14, 14, 64)
1x1卷积核的作用,加深一层网络,提取更深特征,数据变维,
有效卷积(valid)、同维卷积(same)、完全卷积(full)
a = [1 2 3 4 5] 原数组
b = [8 7 6] 卷积核数组 kernel
使用b作为卷积核对a数组做一维卷积运算的过程如下:
- 原数组: 0 0 1 2 3 4 5 0 0
- 卷积数组: 6 7 8
- 6 7 8
- 6 7 8
- 6 7 8
- 6 7 8
- 6 7 8
- 6 7 8
- -------------------------------------
- 结果: 44 65 86 有效卷积 (valid)
- 23 44 65 86 59 同维卷积 (same)
- 8 23 44 65 86 59 30 完全卷积 (full)
参考文献:
[1] tensorflow官方API tf.layers.conv1d
[2] tf.layers.conv1d函数解析(一维卷积)
[3] tf.layer.conv1d、conv2d、conv3d
[4] tensorflow官方API tf.layers.conv2d
- import tensorflow as tf
- # case 2
- input = tf.Variable(tf.random_normal([1, 3, 3, 5]))
- filter = tf.Variable(tf.random_normal([1, 1, 5, 1]))
- op2 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID') # (1, 3, 3, 1)
- # case 3
- input = tf.Variable(tf.random_normal([1, 3, 3, 5]))
- filter = tf.Variable(tf.random_normal([3, 3, 5, 1]))
- op3 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID') # (1, 1, 1, 1)
- # case 4
- input = tf.Variable(tf.random_normal([1, 5, 5, 5]))
- filter = tf.Variable(tf.random_normal([3, 3, 5, 1]))
- op4 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID') # (1, 3, 3, 1)
- # case 5
- input = tf.Variable(tf.random_normal([1, 5, 5, 5]))
- filter = tf.Variable(tf.random_normal([3, 3, 5, 1]))
- op5 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME') # (1, 5, 5, 1)
- # case 6
- input = tf.Variable(tf.random_normal([1, 5, 5, 5]))
- filter = tf.Variable(tf.random_normal([3, 3, 5, 7]))
- op6 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME') # (1, 5, 5, 7)
- # case 7
- input = tf.Variable(tf.random_normal([1, 5, 5, 5]))
- filter = tf.Variable(tf.random_normal([3, 3, 5, 7]))
- op7 = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME') # (1, 3, 3, 7)
- # case 8
- input = tf.Variable(tf.random_normal([10, 5, 5, 5]))
- filter = tf.Variable(tf.random_normal([3, 3, 5, 7]))
- op8 = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME') # (10, 3, 3, 7)
- init = tf.global_variables_initializer()
- with tf.Session() as sess:
- sess.run(init)
- print("case 2")
- print(sess.run(op2).shape) # (1, 3, 3, 1)
- print("case 3")
- print(sess.run(op3).shape) # (1, 1, 1, 1)
- print("case 4")
- print(sess.run(op4).shape) # (1, 3, 3, 1)
- print("case 5")
- print(sess.run(op5).shape) # (1, 5, 5, 1)
- print("case 6")
- print(sess.run(op6).shape) # (1, 5, 5, 7)
- print("case 7")
- print(sess.run(op7).shape) # (1, 3, 3, 7)
- print("case 8")
- print(sess.run(op8).shape) # (10, 3, 3, 7)
CNN神经网络之卷积操作的更多相关文章
- CNN中的卷积操作的参数数计算
之前一直以为卷积是二维的操作,而到今天才发现卷积其实是在volume上的卷积.比如输入的数据是channels*height*width(3*10*10),我们定义一个核函数大小为3*3,则输出是8* ...
- (原)CNN中的卷积、1x1卷积及在pytorch中的验证
转载请注明处处: http://www.cnblogs.com/darkknightzh/p/9017854.html 参考网址: https://pytorch.org/docs/stable/nn ...
- 比CNN表现更好,CV领域全新卷积操作OctConv厉害在哪里?
CNN卷积神经网络问世以来,在计算机视觉领域备受青睐,与传统的神经网络相比,其参数共享性和平移不变性,使得对于图像的处理十分友好,然而,近日由Facebook AI.新家坡国立大学.360人工智能研究 ...
- 深度学习原理与框架-Tensorflow卷积神经网络-卷积神经网络mnist分类 1.tf.nn.conv2d(卷积操作) 2.tf.nn.max_pool(最大池化操作) 3.tf.nn.dropout(执行dropout操作) 4.tf.nn.softmax_cross_entropy_with_logits(交叉熵损失) 5.tf.truncated_normal(两个标准差内的正态分布)
1. tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') # 对数据进行卷积操作 参数说明:x表示输入数据,w表示卷积核, stride ...
- 卷积神经网络(CNN)中卷积的实现
卷积运算本质上就是在滤波器和输入数据的局部区域间做点积,最直观明了的方法就是用滑窗的方式,c++简单实现如下: 输入:imput[IC][IH][IW] IC = input.channels IH ...
- 神经网络6_CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)概念区分理解
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程,QQ:231469242) https://study.163.com/course/introduction.htm?courseId ...
- CNN中各类卷积总结:残差、shuffle、空洞卷积、变形卷积核、可分离卷积等
CNN从2012年的AlexNet发展至今,科学家们发明出各种各样的CNN模型,一个比一个深,一个比一个准确,一个比一个轻量.我下面会对近几年一些具有变革性的工作进行简单盘点,从这些充满革新性的工作中 ...
- Inception模型和Residual模型卷积操作的keras实现
Inception模型和Residual残差模型是卷积神经网络中对卷积升级的两个操作. 一. Inception模型(by google) 这个模型的trick是将大卷积核变成小卷积核,将多个卷积核 ...
- [转]CNN 中千奇百怪的卷积方式大汇总
https://www.leiphone.com/news/201709/AzBc9Sg44fs57hyY.html 推荐另一篇很好的总结:变形卷积核.可分离卷积?卷积神经网络中十大拍案叫绝的操作. ...
随机推荐
- Windows Phone锁屏背景相关代码
LockScreenManager: 启用应用程序,查看该应用程序是否是当前锁定屏幕背景提供程序,并将自己设置为提供程序. 属性: IsProvidedByCurrentApplication 只读指 ...
- chrome 仿手机
很多网站都通过User-Agent来判断浏览器类型,如果是3G手机,显示手机页面内容,如果是普通浏览器,显示普通网页内容. 谷歌Chrome浏览器,可以很方便地用来当3G手机模拟器.在Windows的 ...
- Qt系统对话框中文化及应用程序实现重启及使用QSS样式表文件及使用程序启动界面
一.应用程序中文化 1).Qt安装目录下有一个目录translations/,在此目录下有qt_zh_CN.ts和 qt_zh_CN.qm把它们拷贝到你的工程目录下. 2).在main函数加入下列代码 ...
- SqlServer 动态SQL(存储过程)中Like 传入参数无正确返回值的问题
最近在做项目时,以动态Sql进行Like语句查询时发现应该返回的结果却一直返回空,后来发现是写法错误: 错误SQL: DECLARE @0 varchar(20) SET @0 = 'XA-LZ' S ...
- 判断本地系统目录下是否存在XML文件,如果不存在就创建一个XMl文件,若存在就在里面执行添加数据
这是我为项目中写的一个测试的例子, 假如,您需要这样一个xml文件, <?xml version="1.0" encoding="utf-8"?> ...
- 分布式流处理框架 Apache Storm —— 编程模型详解
一.简介 二.IComponent接口 三.Spout 3.1 ISpout接口 3.2 BaseRichSpout抽象类 四.Bolt 4.1 IBolt 接口 4. ...
- 附006.Kubernetes RBAC授权
一 RBAC 1.1 RBAC授权 基于角色的访问控制(RBAC)是一种基于个人用户的角色来管理对计算机或网络资源的访问的方法. RBAC使用rbac.authorization.k8s.io API ...
- Spring注解?啥玩意?
目录 基础概念:@Bean 和 @Configuration 使用AnnotationConfigApplicationContext 实例化Spring容器 简单的构造 使用register注册IO ...
- C语言实现Linux网络嗅探器
C语言实现Linux网络嗅探器 0x01 实验简介 网络嗅探器是拦截通过网络接口流入和流出的数据的程序.所以,如果你正在浏览的互联网,嗅探器以数据包的形式抓到它并且显示.在本实验中,我们用 C 语言实 ...
- 使用git提交时报错:error: RPC failed; HTTP 413 curl 22 The requested URL returned error: 413 Request Entity Too Large
Delta compression using up to 4 threads.Compressing objects: 100% (2364/2364), done.Writing objects: ...