简易数据分析 06 | 如何导入别人已经写好的 Web Scraper 爬虫

这是简易数据分析系列的第 6 篇文章。
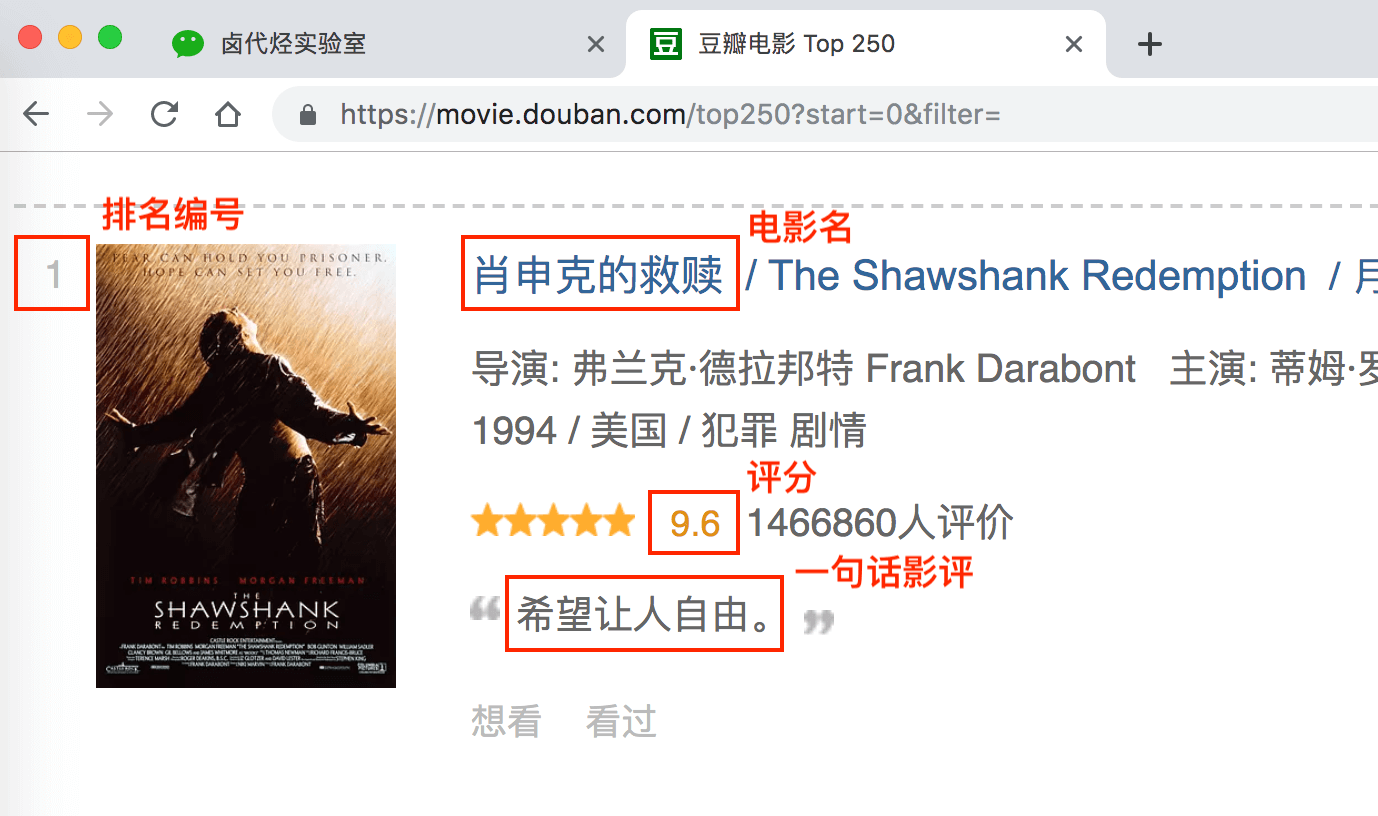
上两期我们学习了如何通过 Web Scraper 批量抓取豆瓣电影 TOP250 的数据,内容都太干了,今天我们说些轻松的,讲讲 Web Scraper 如何导出导入 Sitemap 文件。
前面也没有说,SItemap 是个什么东西,其实它就是我们操作 Web Scraper 后生成的爬虫文件,相当于 python 爬虫的源代码,导入 Web Scraper 一运行就可以爬取数据。学习了这一章节,就可以分享我们的设置好的爬虫文件了。
导出 Sitemap
导出 Sitemap 很简单,比如说我们创建的 top250 Sitemap,点击 Sitemap top250,在下拉菜单里选择 Export Sitemap,就会跳到一个新的面板。
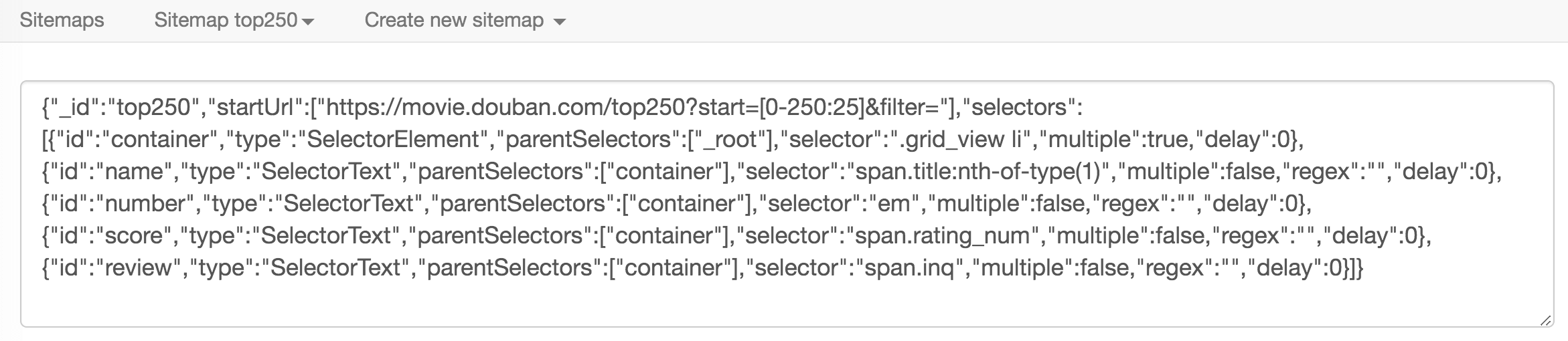
新的面板里有我们创建的 top250 的 Sitemap 信息,我们把它复制下来,再新建一个 TXT 文件,粘贴保存就好了。
导入 Sitemap
导入 Sitemap 也很简单,在创建新的 Sitemap 时,点击 Import Sitemap 就好了。
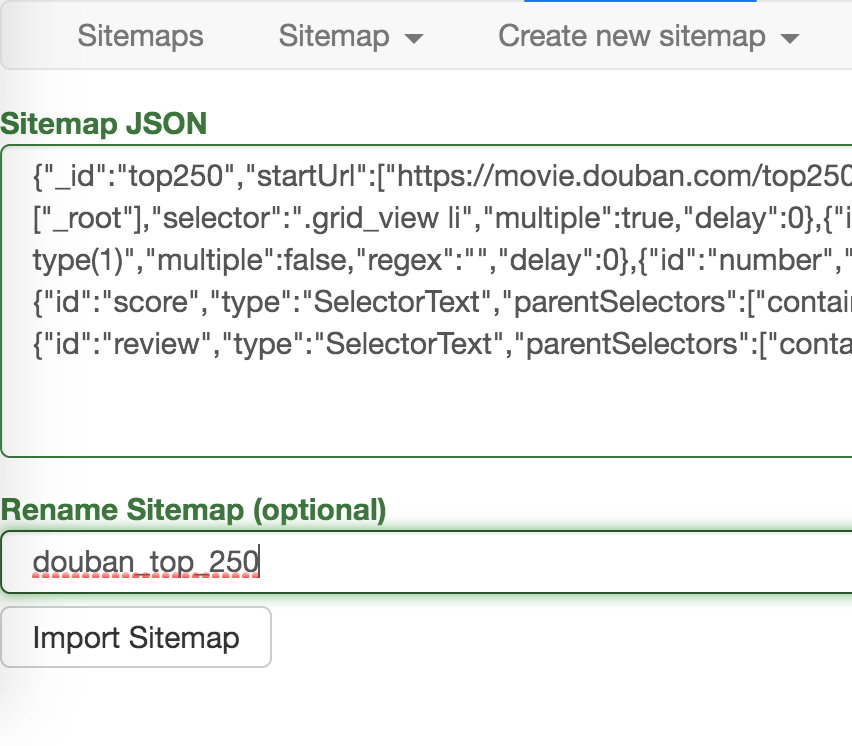
在新的面板里,在 Sitemap JSON 里把我们导出的文字复制进去,Rename Sitemap 里取个名字,最后点击 Import Sitemap 按钮就可以了。
这期我们介绍了 Web Scraper 如何导入导出 Sitemap 爬虫文件,下一期我们对上一期的内容进行扩展,不单单抓取 250 个电影名,还要抓取每个电影对应的排名,名字,评分和一句话影评。
推荐阅读:
简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影

简易数据分析 06 | 如何导入别人已经写好的 Web Scraper 爬虫的更多相关文章
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- Web Scraper 高级用法——使用 CouchDB 存储数据 | 简易数据分析 18
这是简易数据分析系列的第 18 篇文章. 利用 web scraper 抓取数据的时候,大家一定会遇到一个问题:数据是乱序的.在之前的教程里,我建议大家利用 Excel 等工具对数据二次加工排序,但还 ...
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
- 简易数据分析 02 | Web Scraper 的下载与安装
这是简易数据分析系列的第 2 篇文章. 上篇说了数据分析在生活中的重要性,从这篇开始,我们就要进入分析的实战内容了.数据分析数据分析,没有数据怎么分析?所以我们首先要学会采集数据. 我调研了很多采集数 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- Web Scraper 翻页——利用 Link 选择器翻页 | 简易数据分析 14
这是简易数据分析系列的第 14 篇文章. 今天我们还来聊聊 Web Scraper 翻页的技巧. 这次的更新是受一位读者启发的,他当时想用 Web scraper 爬取一个分页器分页的网页,却发现我之 ...
随机推荐
- 个人博客链接英语MP3提示盗链
今天想在wordpress博客中添加一个MP3进行播放,但是遇到了两个问题. 第一是页面无法正常加载播放器所需要的组件,获取资源返回404错误,查看之后发现时找不到wordpress中的一个svg文件 ...
- OWIN 托管服务器问题:StartOptions WebApp.Start TargetInvocationException
我有一个与OWIN托管的服务器有一个小问题.我试图让它可以访问本地网络,这意味着我不得不添加一些额外的选择: // Start OWIN host StartOptions options = new ...
- painter半透明的 底层窗口全透明背景
- CSS3 Generator提供了13个CSS3较为常用的属性代码生成工具,而且可以通过这款工具除了在线生成效果代码之外,还可以实时看到你修改的效果,以及浏览器的兼容性。
CSS3 Generator提供了13个CSS3较为常用的属性代码生成工具,而且可以通过这款工具除了在线生成效果代码之外,还可以实时看到你修改的效果,以及浏览器的兼容性. CSS3 Generator ...
- Md2All:好用的markdown文件转换工具,文章迁移微信公众号的利器
目录 简介 使用体验 极速上手 更多功能 总结 简介 markdown以简单的语法和强大的功能,征服了无数技术创作者,几乎主流的技术博客网站都开始支持markdown语言撰写博客.但是微信公众号的文章 ...
- Java基础(四) StringBuffer、StringBuilder原理浅析
StringBuilder与StringBuffer作用就是用来处理字符串,但String类本身也具备很多方法可以用来处理字符串,那么为什么还要引入这两个类呢? 关于String的讲解请看Java基础 ...
- Docker+ Kubernetes已成为云计算的主流(二十五)
前言 最近正在抽时间编写k8s的相关教程,很是费时,等相关内容初步完成后,再和大家分享.对于k8s,还是上云更为简单.稳定并且节省成本,因此我们需要对主流云服务的容器服务进行了解,以便更好地应用于生产 ...
- 基于 Kong 和 Kubernetes 的 WebApi 多版本解决方案
前言 大家好,很久没有写博客了,最近半年也是比较的忙,所以给关注我的粉丝们道个歉.去年和朱永光大哥聊的时候提了一下我们的这个方案,他说让我有空写篇博客讲一下,之前是非常的忙,所以这次趁着有些时间就写一 ...
- Spring Cloud全链路追踪实现(Sleuth+Zipkin+RabbitMQ+ES+Kibana)
简介 在微服务架构下存在多个服务之间的相互调用,当某个请求变慢或不可用时,我们如何快速定位服务故障点呢?链路追踪的实现就是为了解决这一问题,本文采用Sleuth+Zipkin+RabbitMQ+ES+ ...
- window系统谷歌浏览器百度搜索框光标不能输入并且不显示光标----自制bug以及解决
--------------------bug无处不在------------------------- 今天在搞代码的时候,保存文件无意中犯了个致命错误,文件名称写入非法字符,可能与Windows系 ...