MySQL for OPS 08:MHA 高可用
写在前面的话
主从架构在一般情况下只能满足我们小公司业务并非一刻都不能中断服务。但是对于大型公司而言,对然数据丢失,数据库挂了,我们可以通过技术找回,修复。但是其中修复过程所消耗的时间是不被允许的。此时就需要引入高可用,以保证我们主库在宕机情况下有另外的数据库顶上去,以保证我们的服务 7 x 24 无间断。
数据库基本架构
在日常的小项目中,对于数据库的基本架构一般有以下选型:
1. 一主一从 / 一主多从
2. 多级主从
3. 双主
4. 循环复制
高级一点的高性能架构,也就是需要第三方服务帮助的架构:
1. 读写分离。常见的基于 MySQL Proxy 的有:Atlas / MySQL Router / ProxySQL / MaxScale 等
2. 分布式架构。常见的有:Cobar / TDDL / Mycat 等
最后就是高可用架构:
1. 单活 MMM,谷歌的 mysql-mmm。
2. 单活 MHA,日本人开发的 mysql-master-ha。
3. 多活 MGR,MySQL 5.7.17 以后官方新特性,基于组的复制。
4. 其它的 MariaDB,Percona 自己的 Cluster 架构。
MHA 环境搭建
对于 MHA,可以类比为 Zabbix,拥有 Server 端和 Agent 端,这里就是 Manager 和 Node 端。
整个架构至少包含 3 个数据库,其结构为一主两从,所以这里我们准备了 4 个服务器:

1. 三台服务器都安装 MySQL 数据库并配置好一主两从,具体步骤就不再赘述。
2. 四台服务器都配置 SSH 互信(SSH 免密登录):
# MHA Master 上面生成密钥
rm -rf /root/.ssh
ssh-keygen
cd /root/.ssh
mv id_rsa.pub authorized_keys # 发送密钥到其它主机
scp -r /root/.ssh root@192.168.100.111:/root
scp -r /root/.ssh root@192.168.100.112:/root
scp -r /root/.ssh root@192.168.100.113:/root # 所有服务器上面测试连接,注意每台都单独执行一次,第一次会有个 yes 确认
ssh root@192.168.100.101 date
ssh root@192.168.100.111 date
ssh root@192.168.100.112 date
ssh root@192.168.100.113 date
3. 下载 MHA:
https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
只能下载 RHEL 6 的:
4. 在所有 MySQL 节点安装 Node:
# 安装依赖
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes # 安装 Node
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm # MHA manager 节点还要按照 manager
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
5. 在主库中创建用于 mha 管理的用户:
grant all on *.* to 'mha'@'192.168.100.%' identified by '';
6. 在 Manager 节点添加配置文件,由于一个 Manager 是可以管理多个 node 集群的,所以最好进行项目区分:
# Manager 节点创建配置和日志目录,这里以 test 项目为例
mkdir -p /etc/mha/test/{conf,logs,data,bin} # 添加配置
vim /etc/mha/test/conf/test.conf
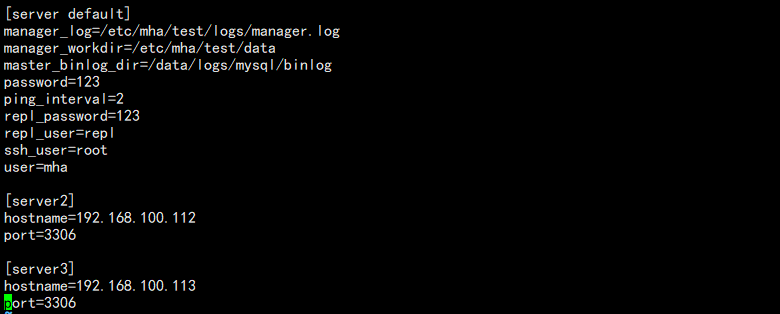
配置详情如下:
[server default]
manager_log=/etc/mha/test/logs/manager.log
manager_workdir=/etc/mha/test/data
master_binlog_dir=/data/logs/mysql/binlog
user=mha
password=123
ping_interval=2
repl_user=repl
repl_password=123
ssh_user=root [server1]
hostname=192.168.100.111
port=3306
[server2]
hostname=192.168.100.112
port=3306
[server3]
hostname=192.168.100.113
port=3306
其中包含 manager 日志路径,工作路径,MySQL binlog 路径,mha 用户,同步用户,ssh 远程用户,以及各个节点。
ping_interval=2 的意思是,每个两秒检测一次,一共检查 3 次,如果三次全失败才算失败。
7. manager 节点测试 SSH 连通性和主从状态:
masterha_check_ssh --conf=/etc/mha/test/conf/test.conf
结果如图:

所有节点 SSH 都是通的。
masterha_check_repl --conf=/etc/mha/test/conf/test.conf
结果如图:

如果有节点是挂的或者不通,则会报异常。
8. 补充说明 MHA 工具包:
| 命令 | 用途 |
|---|---|
| masterha_manager | 启动 MHA 命令 |
| masterha_check_ssh | SSH 连接检测命令 |
| masterha_check_repl | 主从状态检测命令 |
| masterha_master_monitor | 检测 Master 是否宕机 |
| masterha_check_status | 检测当前 MHA 运行状态 |
| masterha_conf_host | 添加或删除 server 配置 |
| masterha_stop | 停止 MHA |
9. manager 节点启动 MHA:
nohup masterha_manager --conf=/etc/mha/test/conf/test.conf --remove_dead_master_conf --ignore_last_failover < /dev/null> /etc/mha/test/logs/manager.log 2>&1 &
查看状态:
masterha_check_status --conf=/etc/mha/test/conf/test.conf
结果如图:

显示 MHA 正在运行,且 111 为主库。到此,简单的 MHA 高可用架构就搭建完成。
MHA 架构工作原理
1. 监控原理:
MHA manager 节点通过服务提供的 perl 脚本对主从环境的节点信息,网络,系统,SSH 连通性,主从状态进行监控。
所以需要配置互信,否则监控的时候服务器无法连接过去。
2. 当 Master 节点宕机后,从新选主的规则:
a. 如果 master 和 slave 之间存在延时,则指针或 GTID 最接近主库的成为备选主。
b. 如果两个 slave 的指针或 GTID 相同,则 MHA 配置文件中谁在前面谁成为备选主。
c. 如果配置了权重(candiate_master=1),则按照权重选取:
特殊情况:当 slave 的 relay log 落后主 100M 则权重也不会选他。如果配置了 check_repl_delay=0,则无论如何都选他。
3. 数据补偿机制:
在主库宕机时,并非所以的数据都可能同步完成:
a. SSH 还能连接主库,则立即同步主库 binlog 并应用到新主中(也就是 Node 的 save_binary_logs 脚本,系统自动调用)。
b. SSH 不能连接主库,则对比从库之间的 relaylog(也就是 Node 的 apply_diff_relay_logs 脚本的功能)。
4. Failover:
将备选主身份切换,继续对外提供服务,其余从库和新主从新建立主从关系。
5. 剩下的 VIP / 故障切换通知 / 二次数据补偿后面再说。
模拟主库宕机示例
1. 停止主库,模拟主库宕机:
systemctl stop mysqld
此时查看 MHA manager 状态:

Manager 进程退出,查看状态:
masterha_check_status --conf=/etc/mha/test/conf/test.conf
如图:

查看 MHA 配置文件:
发现宕机的主机配置已经被自动删除掉了。
2. 查看新的主从关系:

登录从库 2 看到主库以及变更成为之前的从库 1 了。
3. 此时如果之前的主库恢复了,如何加入 MHA 集群中去:
简单,由于是 GTID 复制,我们都不需要从新导入数据,直接 change master 到新的主库即可。
这是主从得知识点,这里就不再说明。
4. 添加之前被 MHA 删掉的 server 配置:
[server1]
hostname=192.168.100.111
port=
5. 再度启动 MHA:
nohup masterha_manager --conf=/etc/mha/test/conf/test.conf --remove_dead_master_conf --ignore_last_failover < /dev/null> /etc/mha/test/logs/manager.log 2>&1 &
查看 MHA 状态:
masterha_check_status --conf=/etc/mha/test/conf/test.conf
如图:

到此,简单的故障切换完成!
MHA 的 VIP
有过运维经验的人此时就发现问题了,而且是大问题。虽然你主从切换了,但是我们业务的服务配置的数据库 IP 地址宕机的那台数据库的。所以我服务还是挂了。这好像并没有解决我们的问题。
于是突发奇想,当初在使用 LVS 或者 Nginx 搭配 Keepalived 使用的时候,有了 VIP(虚拟网卡 IP)的概念,要是能在这使用就好了。
在早期的 MHA 中确实是使用 Keepalived,后来 MHA 自己加入了 VIP 功能,其实就是加入了脚本执行功能,让我们能自己想办法实现。
1. 这里会用到一个脚本,是 perl 语言写的:master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all'; use Getopt::Long; my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
); # VIP 地址
my $vip = '192.168.100.120/24';
# 虚拟网卡后缀编号
my $key = "1";
# 虚拟网卡使用的网卡
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
); exit &main(); sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n"; if ( $command eq "stop" || $command eq "stopssh" ) { # $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = ;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = ;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) { # all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = ;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = ;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $ssh_user\@$orig_master_host \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
} # A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
} sub usage {
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
这里主要注意红色部分!其脚本原理就是使用 ifconfig 给网卡配置 IP 地址。
我这里网卡是 ens33,所以配置虚拟 IP 在 ens33:1 上面。
把 master_ip_failover 脚本上传到 Manager 节点的 /etc/mha/test/bin 下面。
cd /etc/mha/test/bin
dos2unix master_ip_failover
chmod master_ip_failover
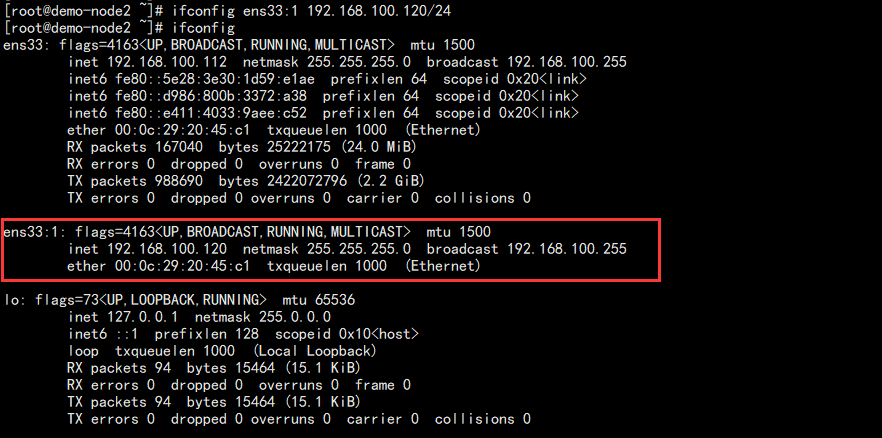
2. 事先给主库配置好虚拟 IP:
ifconfig ens33: 192.168.100.120/
查看:
3. 在 MHA 配置文件中加入脚本路径:
master_ip_failover_script=/etc/mha/test/bin/master_ip_failover
4. 重启 MHA:
# 停止 MHA
masterha_stop --conf=/etc/mha/test/conf/test.conf # 启动 MHA
nohup masterha_manager --conf=/etc/mha/test/conf/test.conf --remove_dead_master_conf --ignore_last_failover < /dev/null> /etc/mha/test/logs/manager.log >& &
至此,VIP 配置完成!
VIP 故障恢复示例
此时我同样停止主库,模拟故障发生:
systemctl stop mysqld
同时 MHA 会自动退出:

查看当前主从关系:
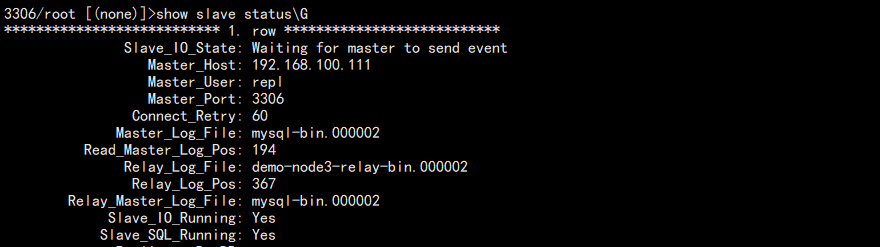
发现主库重新回到了 111 上面。
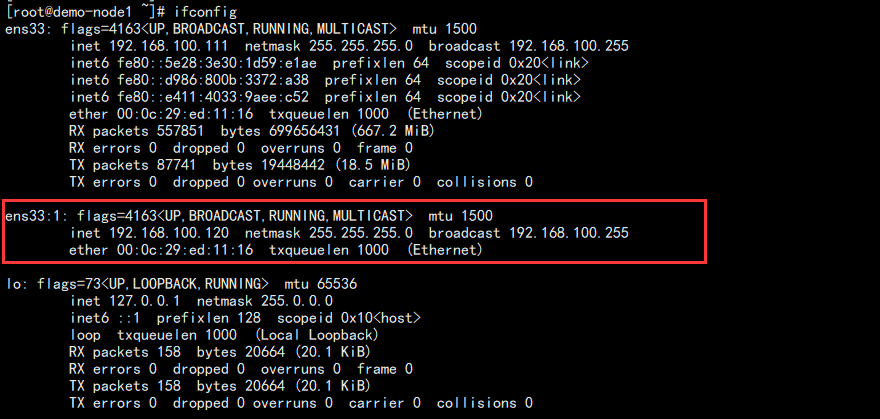
同时 VIP 也漂移到了 111 上面!至此,故障 VIP 切换完成。当然,故障恢复和之前一样:
1. 重新建立主从关系。
2. 给 MHA 配置文件加上被删除的配置。
3. 启动 MHA 服务。
故障告警通知
我们在故障发生时,由于自动切换,我们可能并不知道主库已经宕机了,当然特别去关注除外。为了更好的知道线上的服务情况,我们可能会使用一系列的监控手段。比如 Zabbix 这类。
其实 MHA 是能够让我们发生告警消息的,但其实原理和 VIP 切换一样,都是使用执行脚本的方式。
1. 这里以钉钉机器人发消息为例:
#!/bin/bash
DB_ADDRESS=$(cat /etc/mha/test/logs/manager.log | grep 'Master failover' | tail -1 | cut -d'(' -f2 | cut -d')' -f1)
function SendMessageToDingding(){
Dingding_Url="https://oapi.dingtalk.com/xxxxxxx 这是你自己的钉钉机器人 Token"
# 发送钉钉消息
curl "${Dingding_Url}" -H 'Content-Type: application/json' -d "
{
\"actionCard\": {
\"title\": \"$1\",
\"text\": \"$2\",
\"hideAvatar\": \"0\",
\"btnOrientation\": \"0\",
\"btns\": [
{
\"title\": \"$1\",
\"actionURL\": \"\"
}
]
},
\"msgtype\": \"actionCard\"
}"
}
Subject="数据库主库宕机啦~"
Body="新主库:${DB_ADDRESS}"
SendMessageToDingding $Subject $Body
至于这个脚本写法,可以参照我之前的博客:
将脚本上传到 /etc/mha/test/bin 下面,我给它命名:send_dingding_message,注意修改它的权限。
2. 在配置文件中加入 report_send:
report_script=/etc/mha/test/bin/send_dingding_message
重启 MHA,然后停止主库模拟故障,这样就能收到钉钉通知了:

当然你也可以以其它方式通知,比如邮件。脚本都很简单。
binlog 远程保存
很多时候主库宕机可能出现一个问题,binlog 未及时同步或者本身设置了延时同步。此时如果主库机器已经坏了,这意味着数据就挂了。
那就得想一个办法,类似于将它的 binlog 保留一份到其他机器专门用于出现这样得情况时候从数据库好去这上面查看 binlog 从而实现二次数据补偿。
这就是这个小节需要实现得东西。我们将 binlog 备份保留到 manager 上面。
1. 由于需要用到 MySQL 命令,所以安装 MySQL,并不需要启动,安装方法参考前面得博客:

2. 在 MHA 配置文件中加入 binlog 备份配置:
[binlog1]
no_master=1
hostname=192.168.100.101
master_binlog_dir=/data/backup/mysql/binlog
并创建该目录授权:
mkdir /data/backup/mysql/binlog
chown -R mysql.mysql /data/backup/mysql
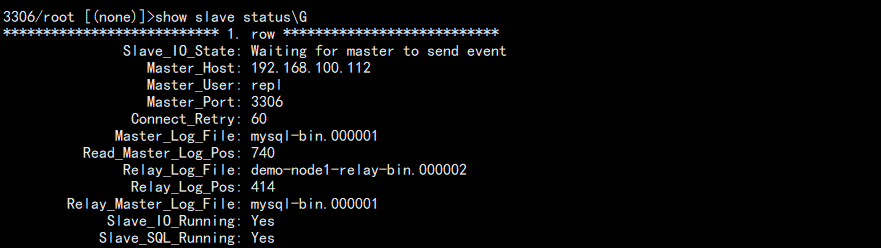
3. 查看当前从库的 binlog 文件名:
show slave status\G
结果:

4. 去 manager 节点拉去该日志:
cd /data/backup/mysql/binlog/
mysqlbinlog -R --host=192.168.100.111 --user=mha --password=123 --raw --stop-never mysql-bin.000003 &
这比如进入目录。
5. 重启 MHA:
masterha_stop --conf=/etc/mha/test/conf/test.conf
nohup masterha_manager --conf=/etc/mha/test/conf/test.conf --remove_dead_master_conf --ignore_last_failover < /dev/null> /etc/mha/test/logs/manager.log 2>&1 &
可以 ps 查看到两个进程:

6. 去主库刷新日志查看:
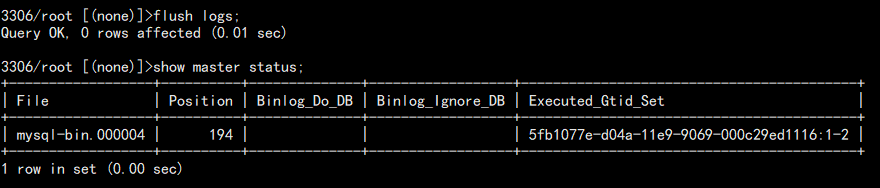
查看备份:

自动已经开始备份新的 binlog 文件。至此异地备份完成,主库宕机,从库会自动读取这里最终实现数据一致。
恢复说明:
这个恢复有点不一样,当从库从 binlog 恢复完成以后。
1. 重新将故障主机加入主从。
2. 清空 binlog 备份,在 MHA 中重新加入 binlog 配置和 server 配置。
3. 重新启动 MHA 架构恢复。
小结
高可用肯定是数据库的一个核心功能,本文的 MHA 主要从高可用 + VIP + 发送告警 + binlog 备份恢复来完善高可用。最好的搭建时候其实就是感慨是设计架构的时候。当然,高可用的架构阿里云也是有的,阿里云的 RDS 就自带高可用。
MySQL for OPS 08:MHA 高可用的更多相关文章
- 【MySQL】MMM和MHA高可用架构
用途 对MySQL主从复制集群的Master的健康监控. 当Master宕机后把写VIP迁移到新Master. 重新配置集群中的其他Slave从新Master同步 MMM架构 主服务器发生故障时, 1 ...
- Mysql MHA高可用集群架构
** 记得之前发过一篇文章,名字叫<浅析MySQL高可用架构>,之后一直有很多小伙伴在公众号后台或其它渠道问我,何时有相关的深入配置管理文章出来,因此,民工哥,也将对前面的各类架构逐一进行 ...
- 搭建MySQL MHA高可用
本文内容参考:http://www.ttlsa.com/mysql/step-one-by-one-deploy-mysql-mha-cluster/ MySQL MHA 高可用集群 环境: Linu ...
- MySQL MHA 高可用集群部署及故障切换
MySQL MHA 高可用集群部署及故障切换 1.概念 2.搭建MySQL + MHA 1.概念: a)MHA概念 : MHA(MasterHigh Availability)是一套优秀的MySQL高 ...
- MHA高可用架构与Atlas读写分离
1.1 MHA简介 1.1.1 MHA软件介绍 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton ...
- MHA 高可用集群搭建(二)
MHA 高可用集群搭建安装scp远程控制http://www.cnblogs.com/kevingrace/p/5662839.html yum install openssh-clients mys ...
- MHA高可用 MHA+Keepalive
MHA高可用 MHA简介 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebo ...
- MHA高可用配置及故障切换
MHA高可用配置及故障切换 目录 MHA高可用配置及故障切换 一.案例概述 二.案例前置知识点 1. MHA概述 2. MHA的组成 (1)MHA Manager(管理节点) (2)MHA Node( ...
- 利用keepalive+mysql replication 实现数据库的高可用
利用keepalive+mysql replication 实现数据库的高可用 http://www.xuchanggang.cn/archives/866.html
随机推荐
- 无法打开锁文件 /var/lib/dpkg/lock-frontend - open
转自:https://blog.csdn.net/sinat_29957455/article/details/89036005 在使用apt-get安装程序的时候报: E: 无法打开锁文件 /var ...
- C#中巧用Lambda表达式实现对象list进行截取
场景 有一个对象的list,每个对象有唯一的属性Id,并且是从1递增,现在要根据此Id属性进行截取. 其中DataTreeNode 实现 Global.Instance.PrepareCompareD ...
- 配置git远程连接gitlab
1.本地git下载 2.配置全局的用户名和邮箱,命令分别为 git config --global user.name "username" git config --global ...
- Thread之模板模式
我们知道,在实际使用线程的时候,真正的执行逻辑都是写在run方法里面,run方法是线程的执行单元,如果我们直接使用Thread类实现多线程,那么run方法本身就是一个空的实现,如下: /** * If ...
- 重新安装和更新所有的 nuget包
重新安装指定项目中所有的 nuget 包 Update-Package -ProjectName MyProject –reinstall 更新指定项目中所有的 nuget 包 Update-Pack ...
- WebSocket实现Java后台消息推送
1.什么是WebSocket WebSocket协议是基于TCP的一种新的网络协议.它实现了浏览器与服务器全双工(full-duplex)通信——允许服务器主动发送信息给客户端. 2.实现原理 在实现 ...
- Windows 10 路由表管理
基本管理命令: route print route命令基本格式: ROUTE [-f] [-p] [-|-] command [destination] [MASK netmask] [gateway ...
- 线上可用django和gunicorn的dockerfile内容
一,基础镜像 [xxx.com.cn/3rd_part/python.3.6.8:alpine3.9-mysqlclient1.4.2] FROM python:3.6.8-alpine3.7 MAI ...
- QQ第三方登录-python_web开发_django框架
准备工作 1. 成为QQ互联的开发者 参考链接: <http://wiki.connect.qq.com/%E6%88%90%E4%B8%BA%E5%BC%80%E5%8F%91%E8%80%8 ...
- 201871010113-刘兴瑞《面向对象程序设计(java)》第六-七周学习总结
项目 内容 这个作业属于哪个课程 <任课教师博客主页链接> https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 <作业链接地址>htt ...