基于OceanStor Dorado V3存储之数据保护 Hyper 特性
基于OceanStor Dorado V3存储之数据保护 Hyper 特性
- 1.1 快照
- 1.2 HyperCDP
- 1.3 HyperCopy
- 1.4 克隆(HyperClone)
- 1.5 远程复制
- 1.6 阵列双活(HyperMetro)
- 1.7 两地三中心(3DC)
- 1.8 一体化备份
- 1.9 WORM
快照(HyperSnap)
LUN 快照(HyperSnap For Block)
快照的主流实现机制包括 COW(Copy-On-Write)即写时拷贝技术和 ROW 即写时重定向技术。 COW 机制需要预留快照的写入空间, 在打了快照的数据被第一次修改时,需要把原有数据拷贝到快照预留空间,数据拷贝过程会影响主机写性能。
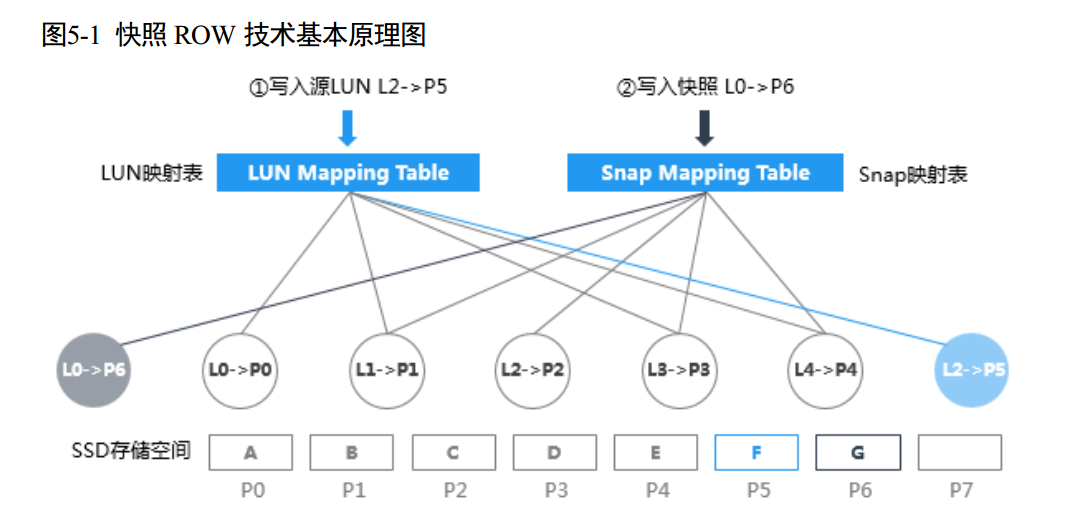
Dorado V3 实现了基于 ROW 的无损快照,对打了快照的数据进行修改时将被重定向写到新位置,系统不需要拷贝原数据,不会增加系统读写开销,解决了 COW 快照机制带来的性能抖动问题。
FS 快照(HyperSnap For File)
Dorado NAS 提供的文件系统快照,支持生成源文件系统在某个时间点上的一致性映像, 在不中断正常业务的前提下,快速得到一份与源文件系统一致的数据副本。副本生成之后立即可用,并且对副本数据的读写操作不再影响源文件系统中的数据。因此通过文件系统快照技术就可以解决如在线备份、数据分析、应用测试等难题。用户可以通过多种方法使用文件系统快照。
HyperCDP
OceanStor Dorado V3 的 HyperCDP 提供对 LUN 的高密快照功能,通过 HyperCDP 生成的快照称为 HyperCDP 快照。 HyperCDP 的快照最小间隔支持 10 秒,对数据提供持续保护,降低 RPO。
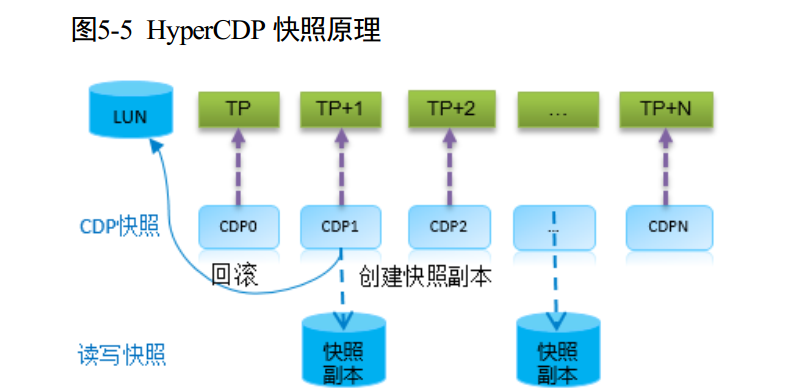
HyperCDP 基于无损快照技术(多时间点、 ROW 技术),每个HyperCDP 对应源 LUN 的一个时间点。 Dorado V3 系统内置 HyperCDP 定时计划,通过配置不同的策略满足客户不同的备份诉求。
HyperCopy
OceanStor Dorado V3R2 版本新增 HyperCopy 功能,通过创建源 LUN 和目标 LUN 的HyperCopy 关系,可以为目标 LUN 同步源 LUN 完整的数据拷贝。创建 HyperCopy 关系时,需要源 LUN 和目标 LUN 的容量相等。目标 LUN 可以是空的,也可以是已有数据的 LUN。
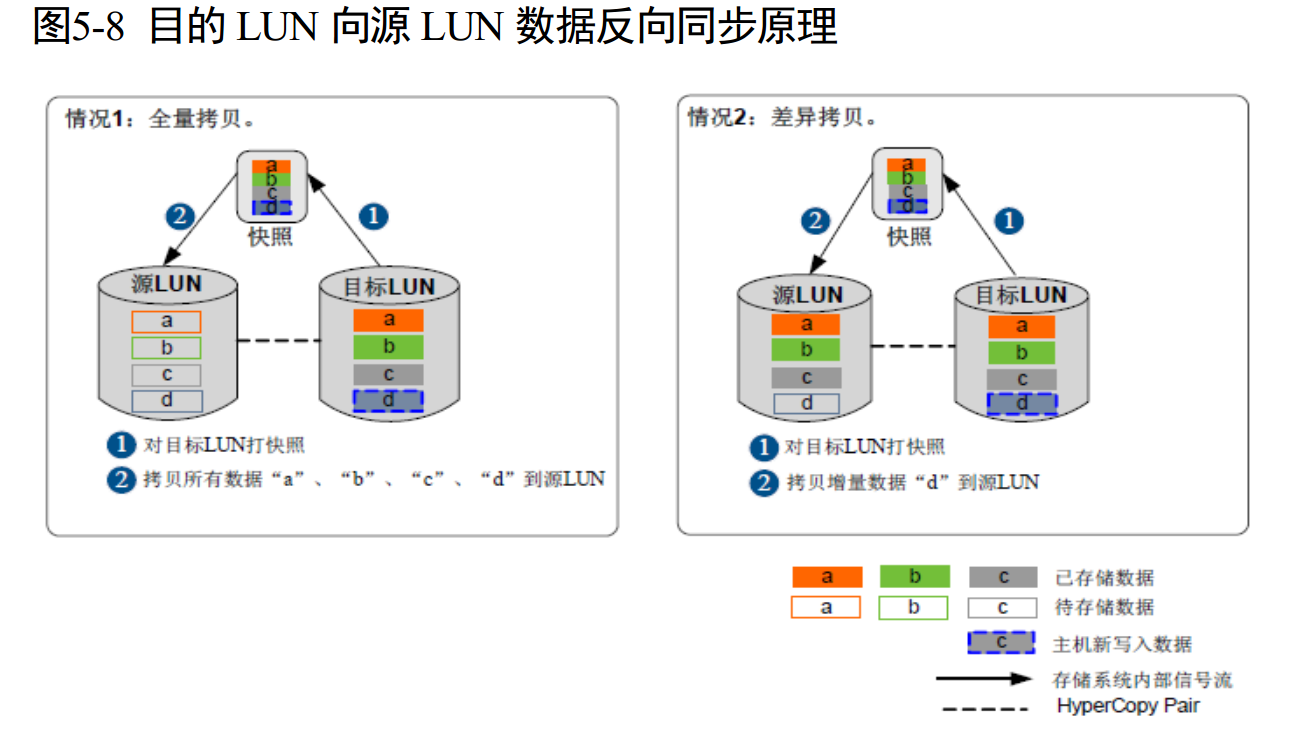
如果目标 LUN 已有数据,则数据将被 HyperCopy 覆盖。创建完成后,用户可以进行数据同步。数据同步过程中,目标 LUN 可以立即读写,无需等待后台拷贝完成。 HyperCopy 也支持 LUN 的一致性组,数据同步支持增量同步和反向增量同步,为源 LUN 数据提供保护和完整备份。 HyperCopy 是阵列内的数据拷贝特性,可以跨控制器,但不支持不同阵列间的数据拷贝。
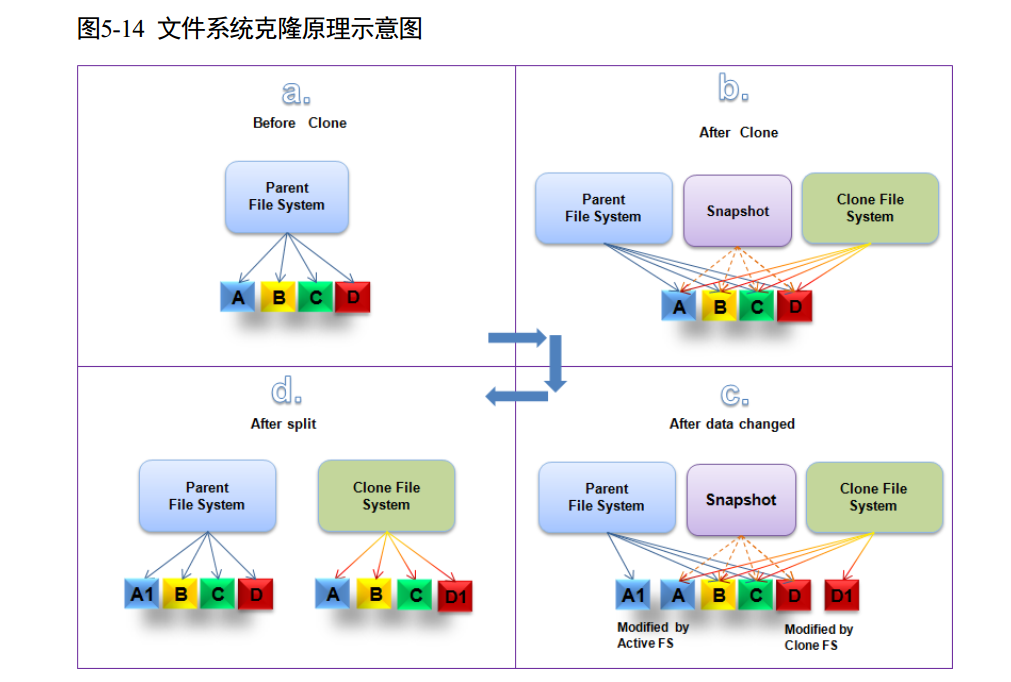
克隆(HyperClone)
LUN 克隆(HyperClone For Block)
OceanStor Dorado V3 的克隆技术是指对源 LUN 或者快照 LUN 产生一份完整的物理数据副本,可以应用于开发、测试场景而不影响源 LUN。HyperClone 支持对普通 LUN 或快照 LUN 创建克隆。创建克隆时, Clone LUN 立即具备源 LUN 相同的数据映像,克隆 LUN 和源 LUN 数据共享,克隆 LUN 创建后可以立即映射给主机使用。 HyperClone 支持克隆分裂操作。克隆分裂是指把克隆 LUN 从源LUN 分裂出去,产生一份独立完整的物理数据副本,克隆 LUN 和源 LUN 间数据不再共享。
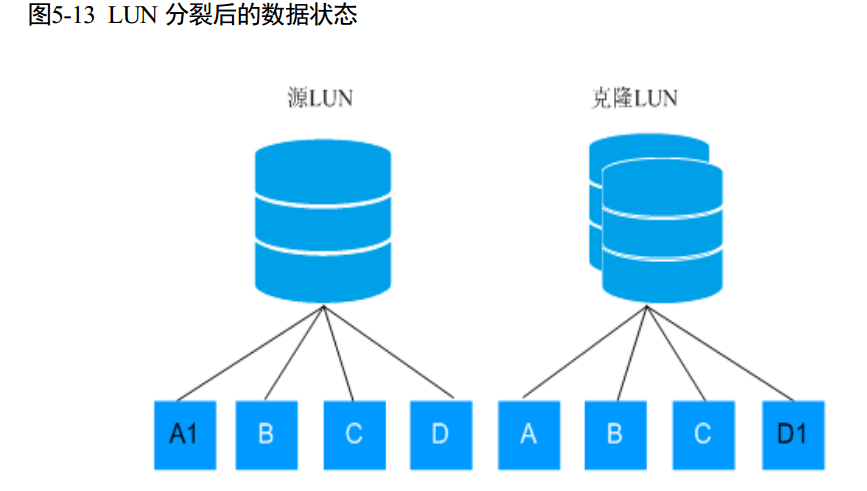
在分裂过程中和分裂完成后,主机都可以不中断的读写 Clone LUN。HyperClone 支持在克隆分裂完成前取消克隆分裂操作,取消分裂操作可以回收分裂过程中已经拷贝的数据,同时保留原有克隆 LUN 与源 LUN 数据的共享关系。HyperClone 基于 LUN 的快照技术,在克隆创建时,克隆调用快照创建一份即时可读写的快照数据,源 LUN 与克隆 LUN 数据共享,如下图所示。克隆 LUN 映射给应用服务器进行读写,此时读出的数据是源 LUN 的数据。
FS 克隆(HyperClone For File)
Dorado NAS 系统支持克隆文件系统特性。克隆文件系统是父文件系统某个时间点的副本,可以独立共享给客户端读写,从而满足快速部署、应用测试、容灾演练等场景。
远程复制(HyperReplication)
LUN 同步远程复制 (HyperReplication/S For Block)
OceanStor Dorado V3 全闪存系统支持阵列间的同步远程复制功能,对于每个主机的写IO,都会同时写到主 LUN 和从 LUN,直到主 LUN 和从 LUN都返回处理结果后,才会返回主机处理结果,做到数据零丢失。主 LUN 和从 LUN 组成一个远程复制对。
LUN 异步远程复制 (HyperReplication/A For Block)
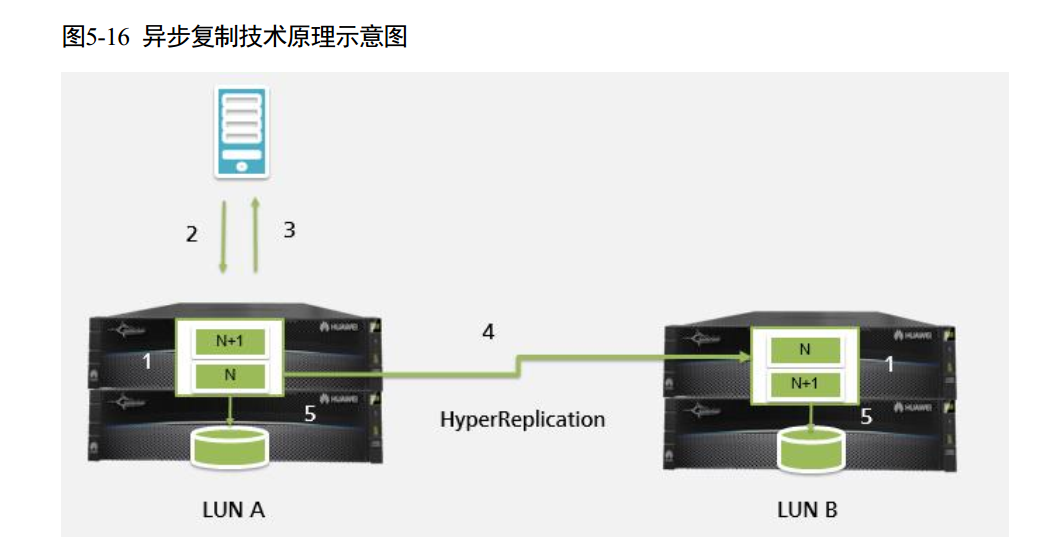
OceanStor Dorado V3 支持异步远程复制,当主站点的主 LUN 和远端复制站点的从LUN 建立异步远程复制关系后,会启动一个初始同步,初始同步完成后,从 LUN 数据状态变为已同步或一致,
阵列双活(HyperMetro)
LUN 双活(HyperMetro For Block)
HyperMetro 是 OceanStor Dorado V3 存储系统实现的阵列级的 Active/Active 双活技术。部署双活的两套存储系统可以放在同一个机房、同一个城市或者相距 100Km 以内的两地,支持 FC 或者 IP 部署(10GE)。 HyperMetro 实现了 LUN Active/Active 双活,来自两套存储阵列的两个 LUN 数据实时同步,且都能提供主机读写访问。当任何一端阵列整体故障的情况下主机将切换访问路径到正常的一端继续业务访问;当阵列间链路故障时只有一端继续提供主机读写访问,具体由哪端提供服务将取决于仲裁的结果。仲裁服务器部署在第三方站点,用于两套存储阵列间链路中断时,提供仲裁服务。
FS 双活(HyperMetro For File)
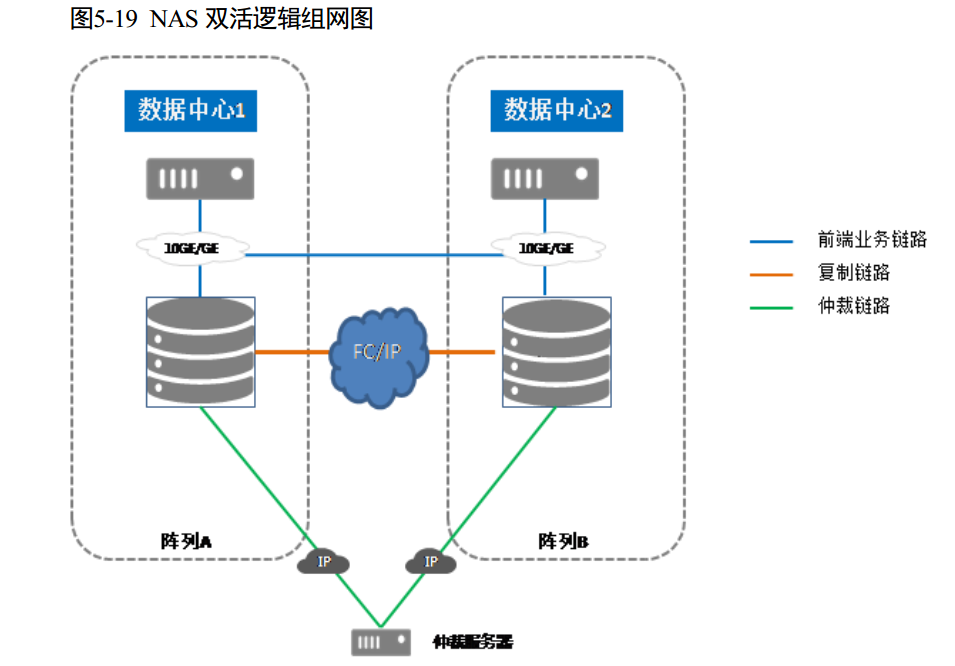
HyperMetro 使主机能够将两个存储系统的文件系统视为单个存储系统上的单个文件系统,并且使两个文件系统上的数据相同。 NAS 双活由主端提供数据读写服务,数据实时同步至从端;当主站点发生故障时,以租户为粒度进行双活切换,从站点将自动接管服务,而不会对应用程序造成任何数据丢失或中断。
两地三中心(3DC)
支持丰富的 3DC(Data Center)组网方式,可以用同步复制和异步复制组成 3DC,也可以是双活和异步复制组成 3DC,包括以下四种组网方式:
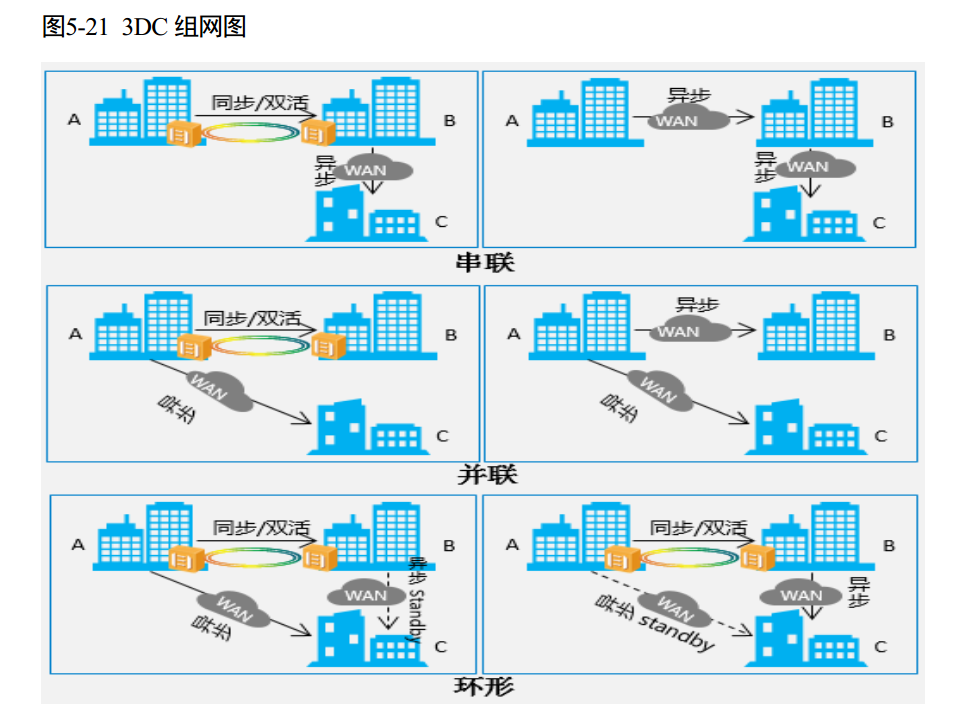
- 同步+异步 级联组网
- 同步+异步 并联组网
- 异步+异步 级联组网
- 异步+异步 并联组网
- 同步+异步 环形组网
- 双活+异步 环形组网
一体化备份(HyperVault for Fil)
OceanStor Dorado V3 存储系统支持一体化备份(HyperVault)特性,可以实现系统内或系统间的文件系统数据备份和恢复。
WORM(HyperLock for File)
随着科学技术的进步和社会发展,信息呈爆炸式增长,数据的安全访问和应用的问题逐渐受到人们的重视,例如法院案件、医疗病例、金融证券等,这些重要的数据按照法律规定在指定的时间周期内只能读不能写。因此需要对此类数据进行防纂改保护。WORM(Write Once Read Many)特性提供一次写入多次读取技术,是存储业界常用的数据安全访问和归档的方法,旨在防止数据被纂改,实现数据的备案和归档。
OceanStor Dorado V3 存储系统的 WORM 特性又叫 HyperLock 特性,是指文件被写入完成后即可通过去掉文件的写权限,使其进入只读状态。在该状态下文件只能被读取,无法被删除、修改或重命名。通过配置 WORM 特性对存储数据进行保护后,可以防止其被意外纂改,满足企业或组织对重要业务数据安全存储的需求。具有 WORM 特性的文件系统(以下简称 WORM 文件系统)只能由管理员进行设置。根据管理员权限不同, WORM 文件系统可分为法规遵从模式(Regulatory ComplianceWORM,简称 WORM-C)和企业遵从模式(Enterprise WORM,简称 WORM-E)。法规遵从模式主要应用于遵从法规施行数据保护机制的归档场景,而企业遵从模式主要应用于企业内部管理。
WORM文件系统中文件的读写
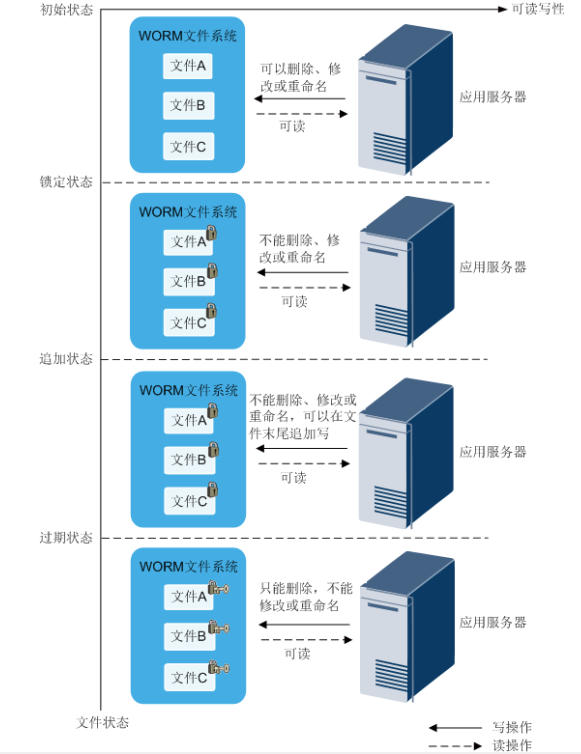
WORM 原理
WORM 技术使文件只能写入一次数据,不能重复写入且不允许被修改、删除或重命名。 WORM 特性是在普通文件系统的基础上增加了 WORM 属性,使 WORM 文件系统内的文件在保护期内只能被读取。创建 WORM 文件系统后,通过 NFS 或者 CIFS 协议映射给应用服务器。
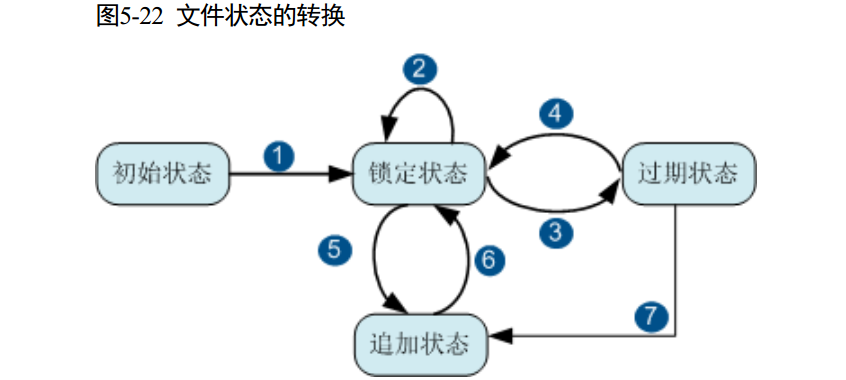
通过使用 WORM 特性,存在于 WORM 文件系统中的文件可以在初始状态、锁定状态、追加状态以及过期状态之间进行转换,从而防止重要数据在指定周期内被意外或恶意纂改。
基于OceanStor Dorado V3存储之数据保护 Hyper 特性的更多相关文章
- 基于OceanStor Dorado V3存储之精简高效 Smart 系列特性
基于OceanStor Dorado V3存储之精简高效 Smart 系列特性 1.1 在线重删 1.2 在线压缩 1.3 智能精简配置 1.4 智能服务质量控制 1.5 异构虚拟化 1.6 ...
- 阿里云基于OSS的云上统一数据保护方案2.0技术解析
近年来,随着越来越多的企业从传统经济向数字经济转型,云已经渐渐成为数据经济IT新常态.核心业务系统上云,云上的业务创新,这些都产生了大量的业务数据,这些数据也成为了企业最重要的资产.资源. 阿里云基于 ...
- 阿里云基于OSS的云上统一数据保护方案2.0正式发布
近年来,随着越来越多的企业从传统经济向数字经济转型,云已经渐渐成为数据经济IT新常态.核心业务系统上云,云上的业务创新,这些都产生了大量的业务数据,这些数据也成为了企业最重要的资产.资源.阿里云基于O ...
- SpringBoot 搭建基于 MinIO 的高性能存储服务
1.什么是MinIO MinIO是根据GNU Affero通用公共许可证v3.0发布的高性能对象存储.它与Amazon S3云存储服务兼容.使用MinIO构建用于机器学习,分析和应用程序数据工作负载的 ...
- 【WP8.1开发】基于应用的联系人存储
上一篇文章所吹的牛是访问系统(手机)上的联系人,当然那只是读不能改,这是自然的,要是让你能随便修改用户的联系人信息的话,那后果很严重,有些恶意开发者就有可能把”你的户口改成猪“. 但是,API也允许应 ...
- RichLabel基于Cocos2dx+Lua v3.x
RichLabel 简介 RichLabel基于Cocos2dx+Lua v3.x解析字符串方面使用了labelparser,它可以将一定格式的字符串,转换为lua中的表结构扩展标签极其简单,只需添加 ...
- 基于catalog 创建RMAN存储脚本
--============================== -- 基于catalog 创建RMAN存储脚本 --============================== 简言之,将rman的 ...
- [大牛翻译系列]Hadoop(19)MapReduce 文件处理:基于压缩的高效存储(二)
5.2 基于压缩的高效存储(续) (仅包括技术27) 技术27 在MapReduce,Hive和Pig中使用可分块的LZOP 如果一个文本文件即使经过压缩后仍然比HDFS的块的大小要大,就需要考虑选择 ...
- [大牛翻译系列]Hadoop(18)MapReduce 文件处理:基于压缩的高效存储(一)
5.2 基于压缩的高效存储 (仅包括技术25,和技术26) 数据压缩可以减小数据的大小,节约空间,提高数据传输的效率.在处理文件中,压缩很重要.在处理Hadoop的文件时,更是如此.为了让Hadoop ...
随机推荐
- python自动登录代码
公司有很多管理平台,账号有禁用机制,每个月至少登录一次,否则禁用.导致有时候想登录某个平台的时候,发现账号已经被禁用了,还得走流程解禁.因此用python实现了一下自动登录,每天定时任务运行一次.ps ...
- Z从壹开始前后端分离【 .NET Core2.2/3.0 +Vue2.0 】框架之七 || API项目整体搭建 6.2 轻量级ORM
本文梯子 本文3.0版本文章 前言 零.今天完成的蓝色部分 0.创建实体模型与数据库 1.实体模型 2.创建数据库 一.在 IRepository 层设计接口 二.在 Repository 层实现相应 ...
- 4-1-JS数据类型及相关操作
js的数据类型 判断数据类型 用typeof typeof "John" // alert(typeof "John") 返 ...
- JavaScript初探 三 (学习js数组)
JavaScript初探 (三) JavaScript数组 定义 创建数组 var 数组名 = [元素0,元素1,元素2,--] ; var arr = ["Huawei",&qu ...
- [20191011]通过bash计算sql语句的sql_id.txt
[20191011]通过bash计算sql语句的sql_id.txt --//当我知道如何通过bash计算sql语句的full_hash_value ,就很想通过bash编程计算sql_id.当时受限 ...
- UGUI Manual
以Unity 5.5 的官方文档为例 Canvas UI元素的前后顺序:SetAsFirstSibling, SetAsLastSibling, and SetSiblingIndex BasicLa ...
- 【cf570】D. Tree Requests(dsu on tree)
传送门 题意: 给出一个以\(1\)为根的有根树.之后有\(m\)个询问,每个询问为\(v_i,h_i\),需要回答以\(v_i\)为根的子树中,深度为\(h_i\)的那些结点所代表的字符能否构成回文 ...
- React、Vue、Angular对比 ---- 介绍及优缺点
React 起源于 Facebook 的内部项目,用来架设 Instagram 的网站, 并于 2013年 5 月开源.React 拥有较高的性能,代码逻辑非常简单,越来越多的人已开始关注和使用它.它 ...
- C 指针(pointer)
C 指针(pointer) /* * pointer.c * 指针在C中的应用 * */ #include <stdio.h> int main(void) { /* * i是一个int类 ...
- vue 使用watch监听实现类似百度搜索功能
watch监听方法,watch可以监听多个变量,具体使用方法看代码: HTML: <!doctype html> <html lang="en"> < ...