房屋布局分析《Physics Inspired Optimization on Semantic Transfer Features: An Alternative Method for Room Layout Estimation》
刘天悦 贝壳找房 / 资深工程师

In this paper, we propose an alternative method to estimate room layouts of cluttered indoor scenes. This method enjoys the benefits of two novel techniques. The first one is semantic transfer (ST), which is: (1) a formulation to integrate the relationship between scene clutter and room layout into convolutional neural networks; (2) an architecture that can be end-to-end trained; (3) a practical strategy to initialize weights for very deep networks under unbalanced training data distribution. ST allows us to extract highly robust features under various circumstances, and in order to address the computation redundance hidden in these features we develop a principled and efficient inference scheme named physics inspired optimization (PIO). PIO's basic idea is to formulate some phenomena observed in ST features into mechanics concepts. Evaluations on public datasets LSUN and Hedau show that the proposed method is more accurate than state-of-the-art methods.
语义迁移:
X:原图
Y:semantic 标签
Z:edge 标签
physics inspired optimization (PIO). PIO's basic idea is to formulate some phenomena observed in ST features into mechanics concepts.
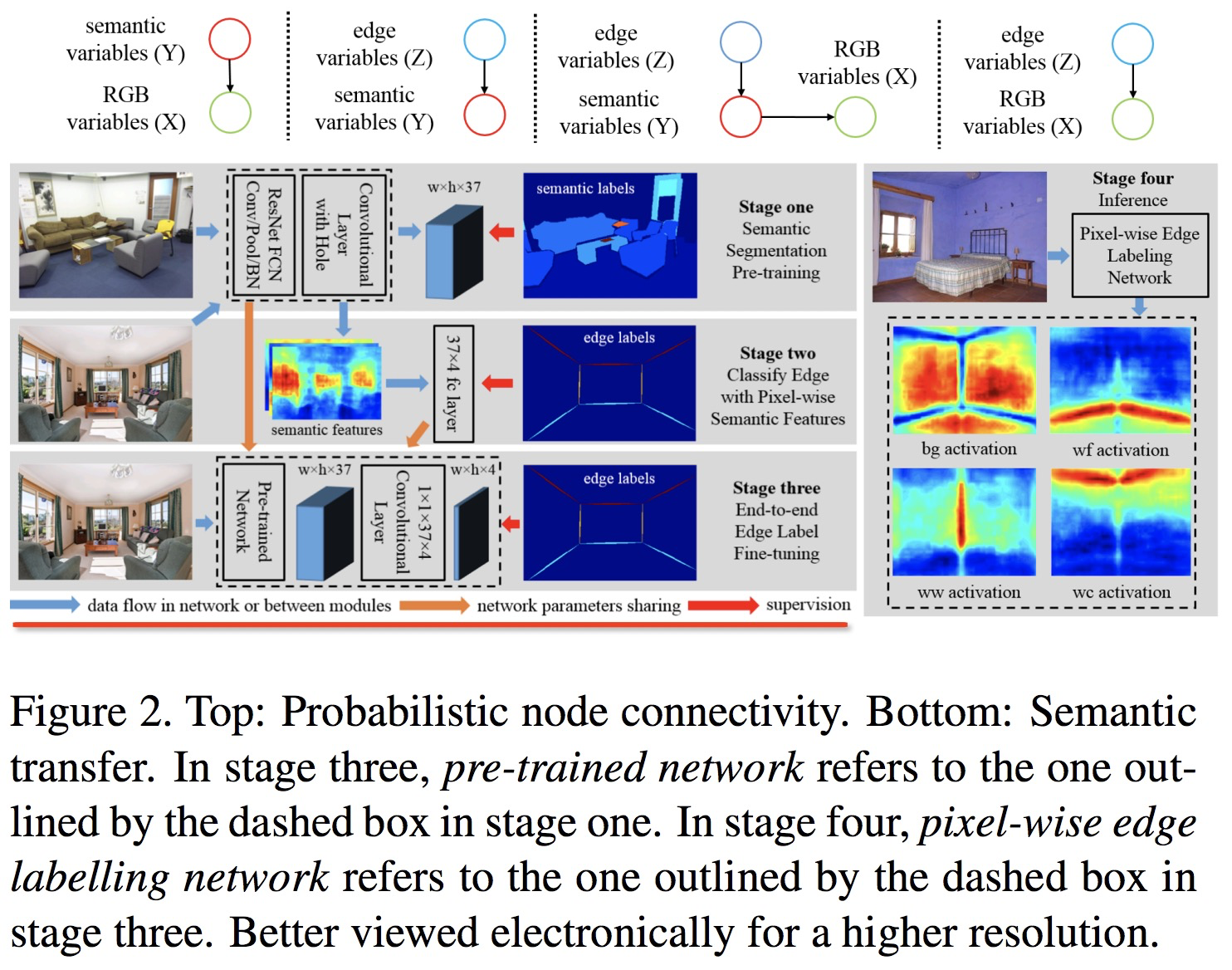


加入透视线的先验判断?
-->果然是这个思路。。。

倾斜不倾斜和特征差异在哪?
先识别物体,再(根据多视角几何)定量地把倾斜角度优化出来?
“江苏券”那种倾斜、颠倒的异常情形如何优雅处理?——先把当前图片的vanishing point (也就是主方向)识别出来,再检测物体、或回归时带一个方向角?

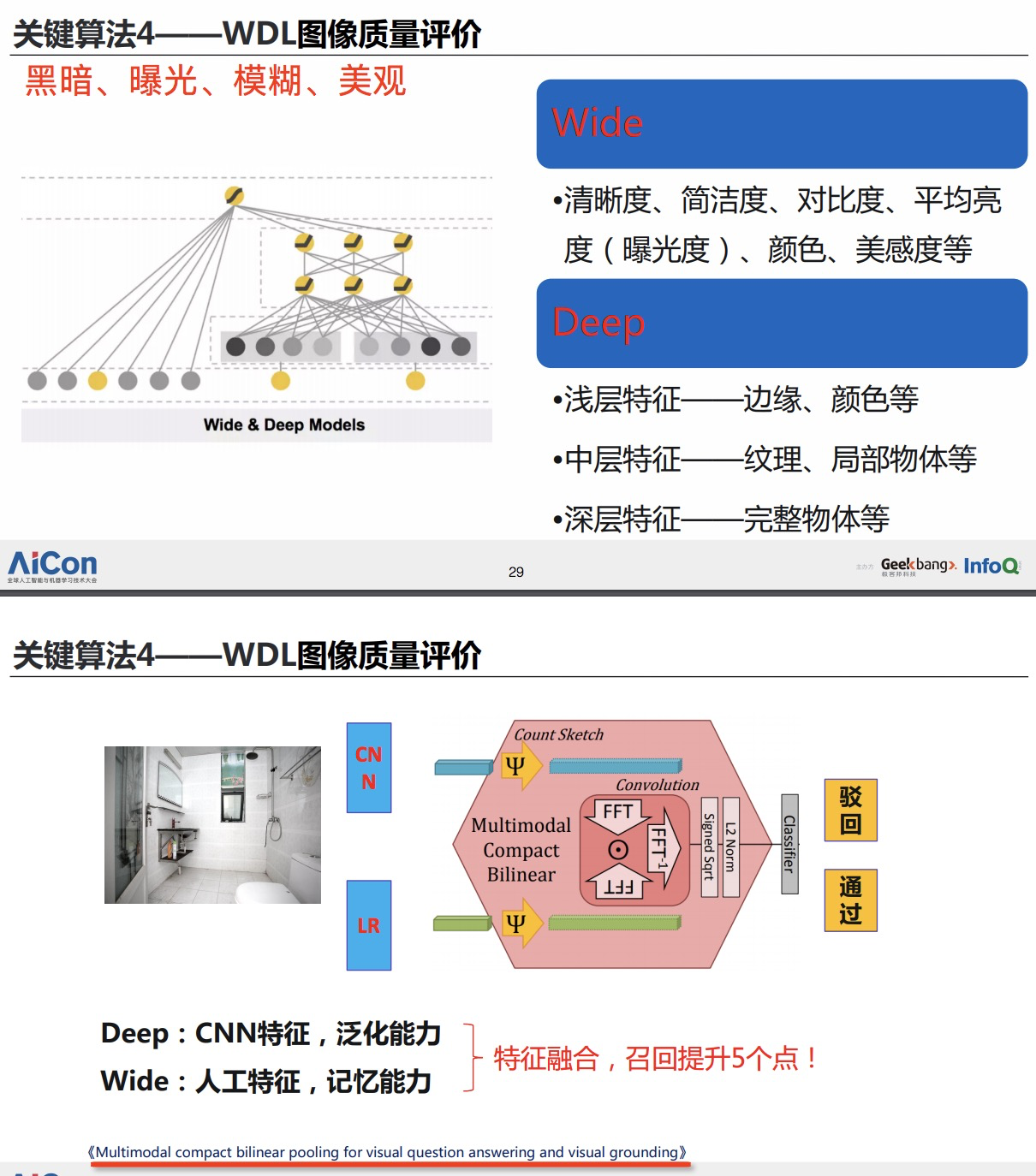
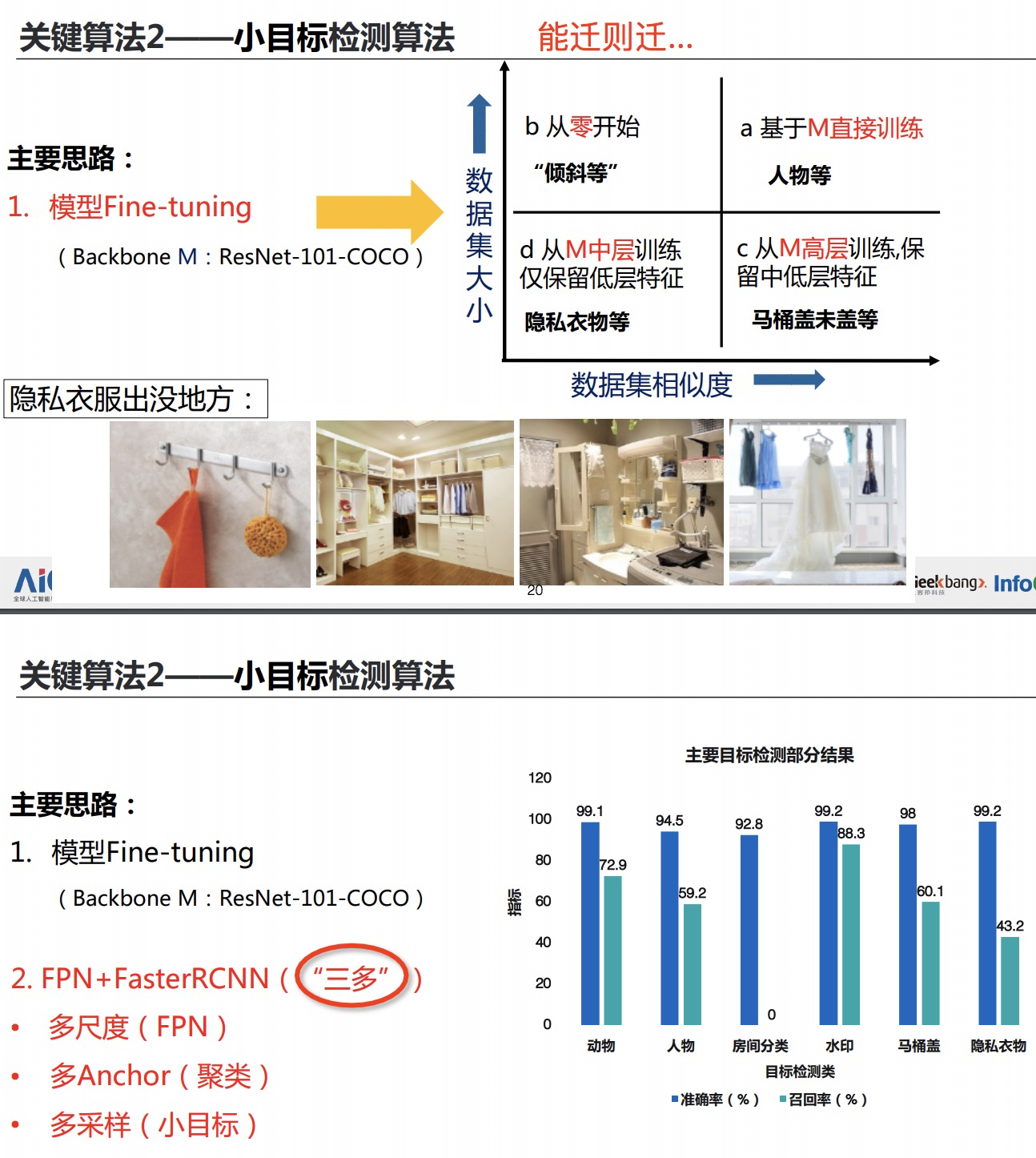
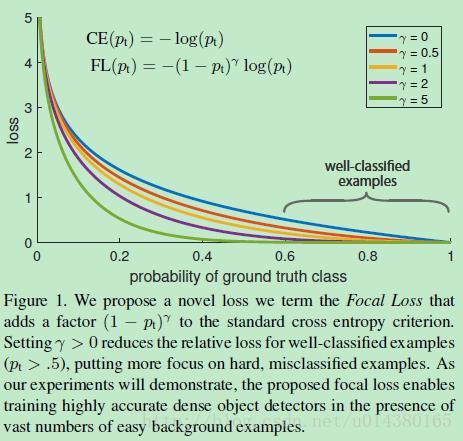
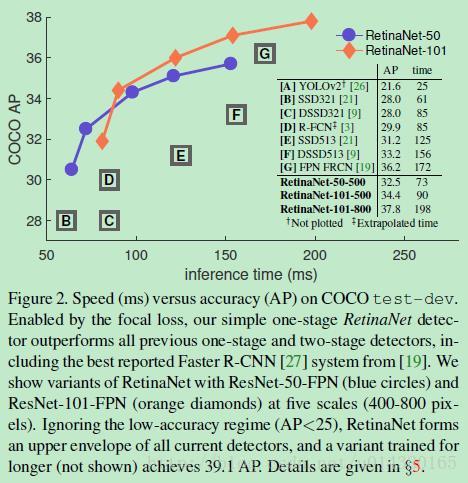
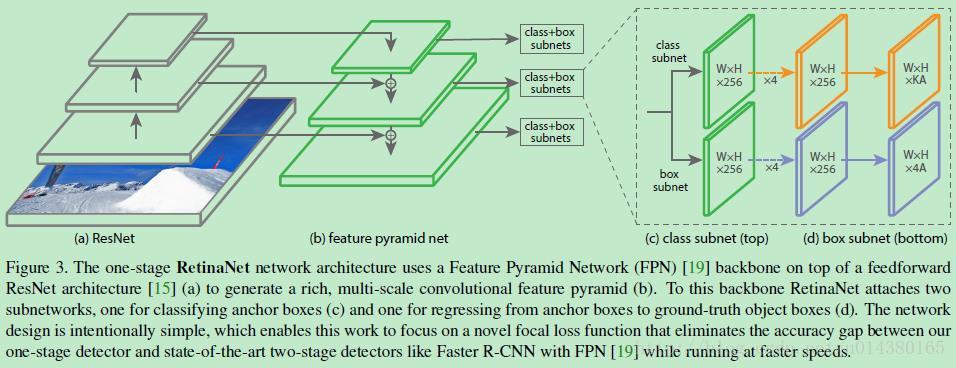
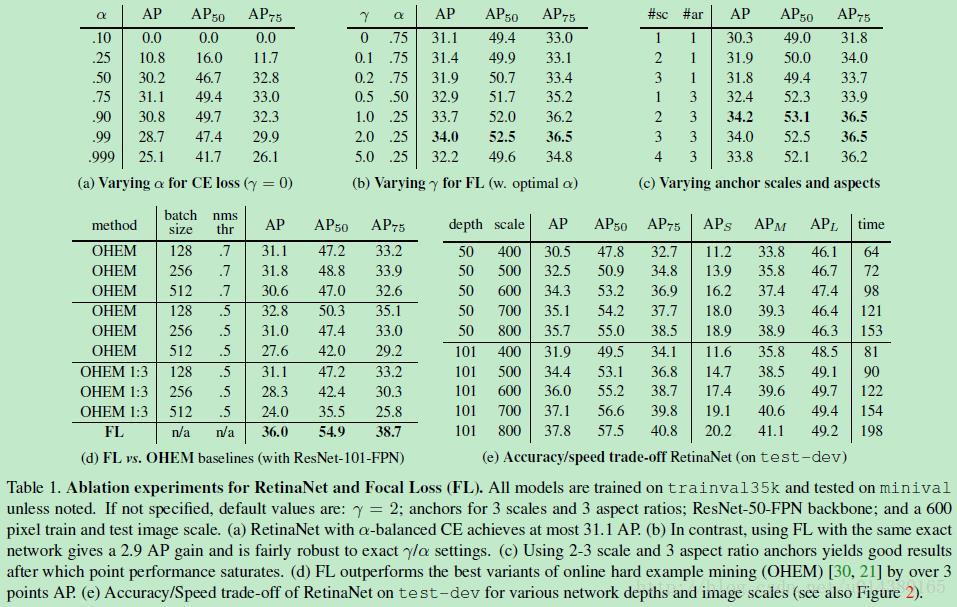
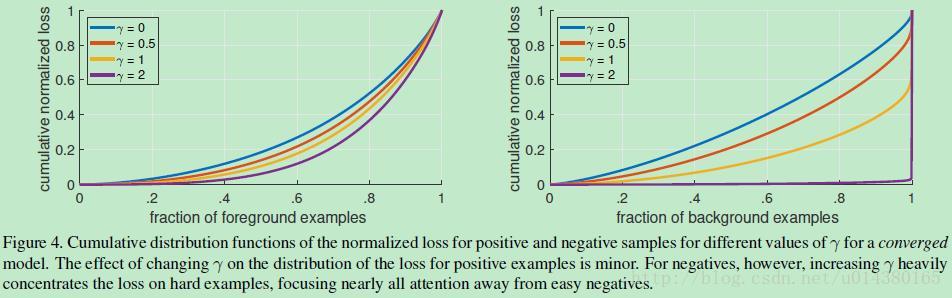
Focal Loss论文:Focal Loss for Dense Object Detection RBG和Kaiming大神的新作。 既然有了出发点,那么就要找one-stage detector的准确率不如two-stage detector的原因,作者认为原因是:样本的类别不均衡导致的。我们知道在object detection领域,一张图像可能生成成千上万的candidate locations,但是其中只有很少一部分是包含object的,这就带来了类别不均衡。那么类别不均衡会带来什么后果呢?引用原文讲的两个后果:(1) training is inefficient as most locations are easy negatives that contribute no useful learning signal; (2) en masse, the easy negatives can overwhelm training and lead to degenerate models. 什么意思呢?负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样。其实先前也有一些算法来处理类别不均衡的问题,比如OHEM(online hard example mining),OHEM的主要思想可以用原文的一句话概括:In OHEM each example is scored by its loss, non-maximum suppression (nms) is then applied, and a minibatch is constructed with the highest-loss examples。OHEM算法虽然增加了错分类样本的权重,但是OHEM算法忽略了容易分类的样本。 因此针对类别不均衡问题,作者提出一种新的损失函数:focal loss,这个损失函数是在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。为了证明focal loss的有效性,作者设计了一个dense detector:RetinaNet,并且在训练时采用focal loss训练。实验证明RetinaNet不仅可以达到one-stage detector的速度,也能有two-stage detector的准确率。 focal loss的含义可以看如下Figure1,横坐标是pt,纵坐标是loss。CE(pt)表示标准的交叉熵公式,FL(pt)表示focal loss中用到的改进的交叉熵,可以看出和原来的交叉熵对比多了一个调制系数(modulating factor)。为什么要加上这个调制系数呢?目的是通过减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。首先pt的范围是0到1,所以不管γ是多少,这个调制系数都是大于等于0的。易分类的样本再多,你的权重很小,那么对于total loss的共享也就不会太大。那么怎么控制样本权重呢?举个例子,假设一个二分类,样本x1属于类别1的pt=0.9,样本x2属于类别1的pt=0.6,显然前者更可能是类别1,假设γ=1,那么对于pt=0.9,调制系数则为0.1;对于pt=0.6,调制系数则为0.4,这个调制系数就是这个样本对loss的贡献程度,也就是权重,所以难分的样本(pt=0.6)的权重更大。Figure1中γ=0的蓝色曲线就是标准的交叉熵损失。 Figure2是在COCO数据集上几个模型的实验对比结果。可以看看再AP和time的对比下,本文算法和其他one-stage和two-stage检测算法的差别。 看完实验结果和提出算法的出发点,接下来就要介绍focal loss了。在介绍focal loss之前,先来看看交叉熵损失,这里以二分类为例,p表示概率,公式如下: 因为是二分类,所以y的值是正1或负1,p的范围为0到1。当真实label是1,也就是y=1时,假如某个样本x预测为1这个类的概率p=0.6,那么损失就是-log(0.6),注意这个损失是大于等于0的。如果p=0.9,那么损失就是-log(0.9),所以p=0.6的损失要大于p=0.9的损失,这很容易理解。 为了方便,用pt代替p,如下公式2:。这里的pt就是前面Figure1中的横坐标。 接下来介绍一个最基本的对交叉熵的改进,也将作为本文实验的baseline,如下公式3。什么意思呢?增加了一个系数at,跟pt的定义类似,当label=1的时候,at=a;当label=-1的时候,at=1-a,a的范围也是0到1。因此可以通过设定a的值(一般而言假如1这个类的样本数比-1这个类的样本数多很多,那么a会取0到0.5来增加-1这个类的样本的权重)来控制正负样本对总的loss的共享权重。 显然前面的公式3虽然可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重,于是就有了focal loss: 这里的γ称作focusing parameter,γ>=0。 称为调制系数(modulating factor) 作者在实验中采用的是公式5的focal loss(结合了公式3和公式4,这样既能调整正负样本的权重,又能控制难易分类样本的权重): 在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好) 贴一下RetinaNet的结构图:Figure3。因为网络结构不是本文的重点,所以这里就不详细介绍了,感兴趣的可以看论文的第4部分。 实验结果: Figure4是对比forground和background样本在不同γ情况下的累积误差。纵坐标是归一化后的损失,横坐标是总的foreground或background样本数的百分比。可以看出γ的变化对正(forground)样本的累积误差的影响并不大,但是对于负(background)样本的累积误差的影响还是很大的(γ=2时,将近99%的background样本的损失都非常小)。 总结: |
|
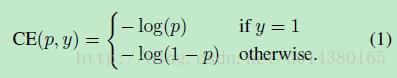
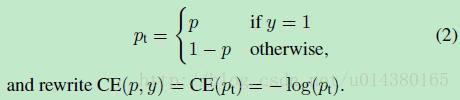
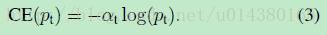
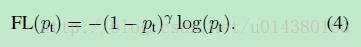
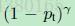
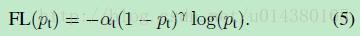
引用:
房屋布局分析《Physics Inspired Optimization on Semantic Transfer Features: An Alternative Method for Room Layout Estimation》的更多相关文章
- JFS 文件系统概述及布局分析
JFS 文件系统概述及布局分析 日志文件系统如何缩短系统重启时间 如果发生系统崩溃,JFS 提供了快速文件系统重启.通过使用数据库日志技术,JFS 能在几秒或几分钟之内把文件系统恢复到一致状态,而非日 ...
- Vtable内存布局分析
vtale 内存布局分析 虚函数表指针与虚函数表布局 考虑如下的 class: class A { public: int a; virtual void f1() {} virtual void f ...
- pdfminer实现pdf布局分析 python (pdfminer realize layout analysis with PDF python)
使用pdfminer实现pdf文件的布局分析 python 参考资料: https://github.com/euske/pdfminer https://stackoverflow.com/ques ...
- 安卓动态分析工具【Android】3D布局分析工具
https://blog.csdn.net/fancylovejava/article/details/45787729 https://blog.csdn.net/dunqiangjiaodemog ...
- Android布局分析工具HierarchyView的使用方法
本文是从这里看到的:http://www.2cto.com/kf/201404/296960.html 如果我们想宏观的看看自己的布局,Android SDK中有一个工具HierarchyView.b ...
- cocos布局分析
HBox和VBox布局 HBox只是一个水平布局包装类. HBox里面所有的孩子节点都会水平排列成一行 VBox仅仅是对垂直布局的一个简便的类封装. VBox把它的子节点布局在一竖列中. Layout ...
- 嵌入式开发软件环境:uboot、kernel、rootfs、data布局分析
uboot+linux的整体方案 开发板的datasheet中都有详细的地址空间的划分,其中比较重要的两块是:DDR地址空间和Flash地址空间.DDR空间是系统和应用的运行空间,一般由linux系统 ...
- div整体布局分析
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 布局分析002:入门级的CSS导航弹出菜单
这种弹出菜单非常有意思,也有记录的意义,甚至可以说,掌握了这种弹出菜单,基本上CSS掌握的差不多. 主要涉及下面三个重要知识: CSS的继承性质. relative absolute定位. 子选择符& ...
随机推荐
- 在Electron中最快速预加载脚本
背景 在Electron打开新窗口的时候,提前加载一段JavaScript脚本,以此内置一些属性或接口给被打开的页面.之所以要以注入方式,而不是页面自己引用,原因是不想麻烦页面自行引用,不想修改旧有的 ...
- Python输出16进制不带0x补零,整数转16进制,字符串转16进制
Python输出16进制不带0x补零,整数转16进制,字符串转16进制 在开发中,我们偶尔会遇到需要将数据通过控制台打印出来,以检查数据传输的准确性.例如调试服务端刚接到的二进制数据(里面包含很多 ...
- java开发实习生面试经历
这是我第一次写博客,以前都是查看别人的博客分享学习技术,转眼间我也成为其中一员.从一位初学者到现在的开发实习生,不断前进着,跟随时代的脚步在程序的海洋里漂泊,也意识到自己的各种不足,但我还年轻,头还 ...
- 不能绑定到端口号:9194原因:Cannot assign requested address: JVM_Bind
晚上将老服务器程序从win2008部署在新的云服务器win2012上,其实就是复制过去改改配置,启动时突然报不能绑定到端口号:9194原因:Cannot assign requested addres ...
- Centos8尝鲜
Centos 8阿里云下载地址https://mirrors.aliyun.com/centos/8.0.1905/isos/x86_64/ Centos8的一些变化 网络服务: 在/etc/sysc ...
- Linux系统学习 十七、VSFTP服务—本地用户访问—用户访问控制
FTP相关文件中用户控制列表文件 /etc/vsftpd/ftpusers #该文件永远都是黑名单(针对访问ftp服务,一般不做修改) /etc/vsftpd/user_list ...
- leetcode动态规划--基础题
跳跃游戏 给定一个非负整数数组,你最初位于数组的第一个位置. 数组中的每个元素代表你在该位置可以跳跃的最大长度. 判断你是否能够到达最后一个位置. 思路 根据题目意思,最大跳跃距离,说明可以跳0--n ...
- [C]#include和链接
概述 对于刚接触C语言的同学来说,通常对“在文件中用#include预处理操作符引入文件”和“编译时链接多个文件”这两个操作会有所混淆,这个文章主要为了解析一下它们的区别. #include预处理操作 ...
- python中list的运算,操作及实例
在操作list的时候,经常用到对列表的操作运算,比如说,列表添加,删除操作,其实,这里面经常回遇到这样一个问题,就是列表的操作容易被混淆了. 有人做了一个总结,这个很清晰,我就不多做阐述了: 1.ap ...
- mac怎么连接windows远程桌面
首先需要下载一个软件,因为苹果电脑并没有提供免费的软件给我们,所以不能像windows一样, 直接在任务管理中搜素远程桌面然后输入ip地址,用户名,密码就可以远程连接, 而苹果也有提供一个软件,但要付 ...