Spark学习之路(八)—— Spark SQL 之 DataFrame和Dataset
一、Spark SQL简介
Spark SQL是Spark中的一个子模块,主要用于操作结构化数据。它具有以下特点:
- 能够将SQL查询与Spark程序无缝混合,允许您使用SQL或DataFrame API对结构化数据进行查询;
- 支持多种开发语言;
- 支持多达上百种的外部数据源,包括Hive,Avro,Parquet,ORC,JSON和JDBC等;
- 支持HiveQL语法以及Hive SerDes和UDF,允许你访问现有的Hive仓库;
- 支持标准的JDBC和ODBC连接;
- 支持优化器,列式存储和代码生成等特性;
- 支持扩展并能保证容错。

二、DataFrame & DataSet
2.1 DataFrame
为了支持结构化数据的处理,Spark SQL提供了新的数据结构DataFrame。DataFrame是一个由具名列组成的数据集。它在概念上等同于关系数据库中的表或R/Python语言中的data frame。 由于Spark SQL支持多种语言的开发,所以每种语言都定义了DataFrame的抽象,主要如下:
| 语言 | 主要抽象 |
|---|---|
| Scala | Dataset[T] & DataFrame (Dataset[Row] 的别名) |
| Java | Dataset[T] |
| Python | DataFrame |
| R | DataFrame |
2.2 DataFrame 对比 RDDs
DataFrame和RDDs最主要的区别在于一个面向的是结构化数据,一个面向的是非结构化数据,它们内部的数据结构如下:
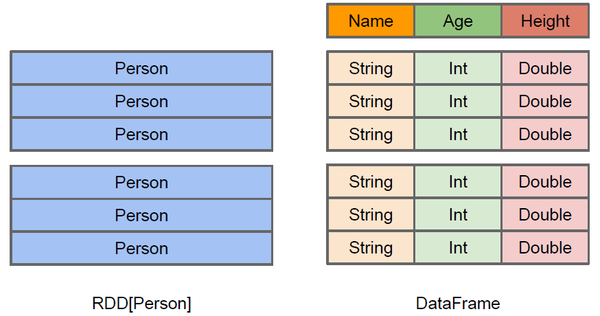
DataFrame内部的有明确Scheme结构,即列名、列字段类型都是已知的,这带来的好处是可以减少数据读取以及更好地优化执行计划,从而保证查询效率。
DataFrame和RDDs应该如何选择?
- 如果你想使用函数式编程而不是DataFrame API,则使用RDDs;
- 如果你的数据是非结构化的(比如流媒体或者字符流),则使用RDDs,
- 如果你的数据是结构化的(如RDBMS中的数据)或者半结构化的(如日志),出于性能上的考虑,应优先使用DataFrame。
2.3 DataSet
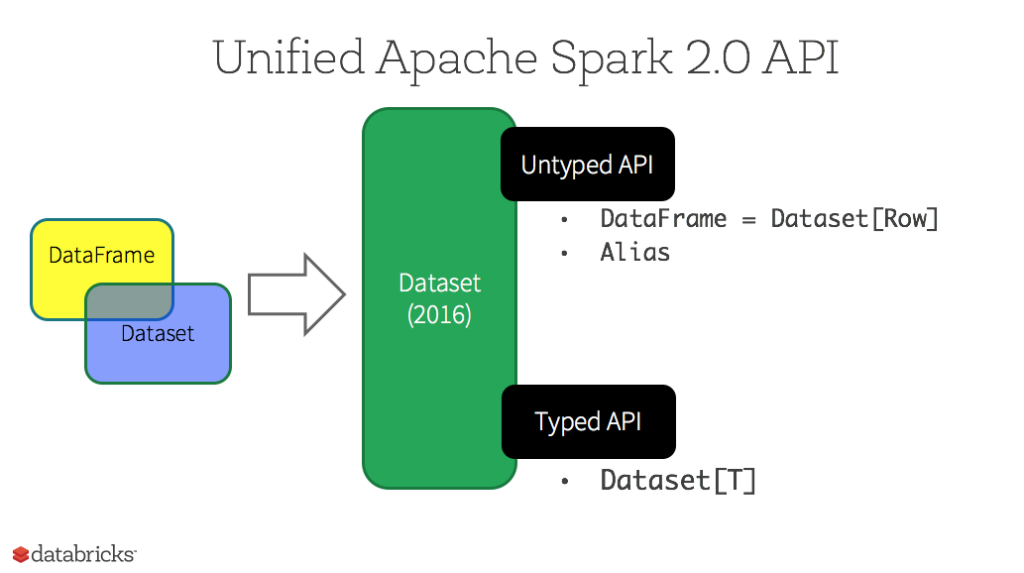
Dataset也是分布式的数据集合,在Spark 1.6版本被引入,它集成了RDD和DataFrame的优点,具备强类型的特点,同时支持Lambda函数,但只能在Scala和Java语言中使用。在Spark 2.0后,为了方便开发者,Spark将DataFrame和Dataset的API融合到一起,提供了结构化的API(Structured API),即用户可以通过一套标准的API就能完成对两者的操作。
这里注意一下:DataFrame被标记为Untyped API,而DataSet被标记为Typed API,后文会对两者做出解释。
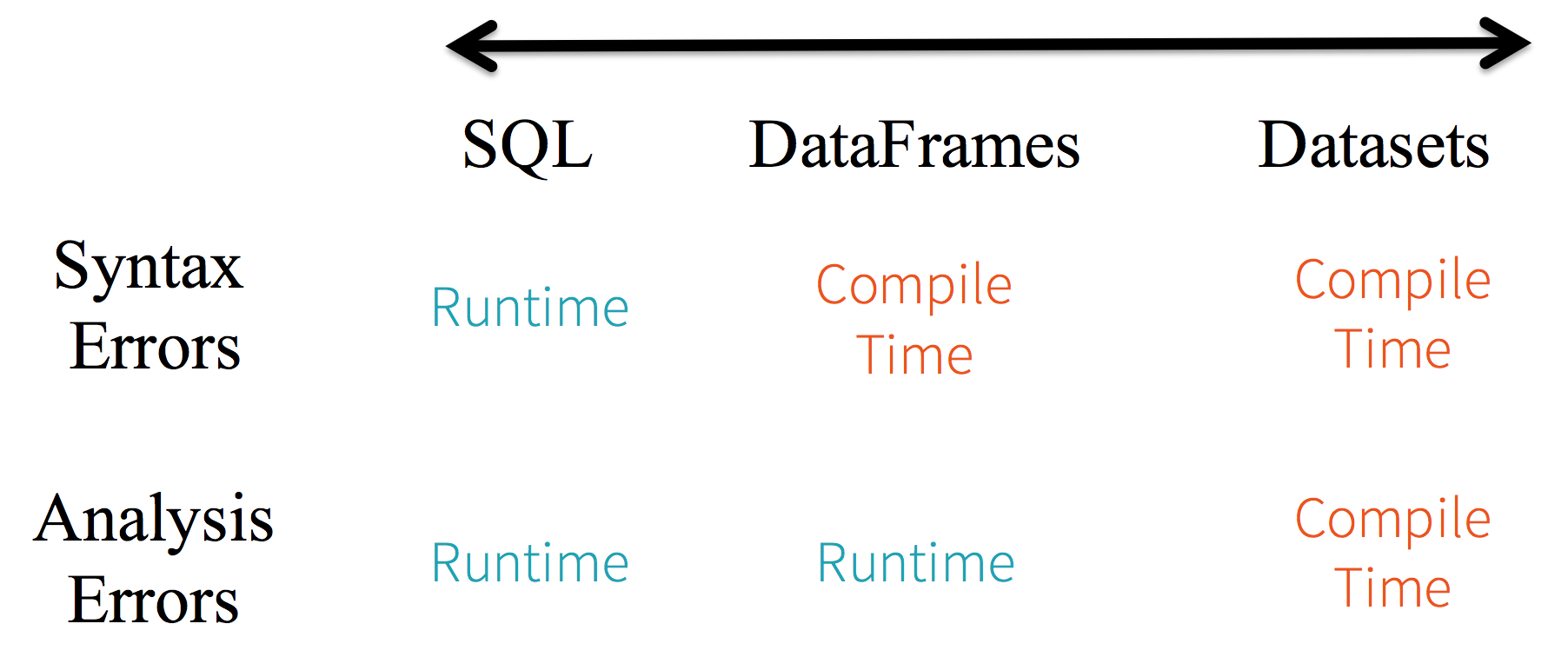
2.4 静态类型与运行时类型安全
静态类型(Static-typing)与运行时类型安全(runtime type-safety) 主要表现如下:
在实际使用中,如果你用的是Spark SQL的查询语句,则直到运行时你才会发现有语法错误,而如果你用的是DataFrame和 Dataset,则在编译时就可以发现错误(这节省了开发时间和整体代价)。DataFrame和Dataset主要区别在于:
在DataFrame中,当你调用了API之外的函数,编译器就会报错,但如果你使用了一个不存在的字段名字,编译器依然无法发现。而Dataset的API都是用Lambda函数和JVM类型对象表示的,所有不匹配的类型参数在编译时就会被发现。
以上这些最终都被解释成关于类型安全图谱,对应开发中的语法和分析错误。在图谱中,Dataset最严格,但对于开发者来说效率最高。
上面的描述可能并没有那么直观,下面的给出一个IDEA中代码编译的示例:
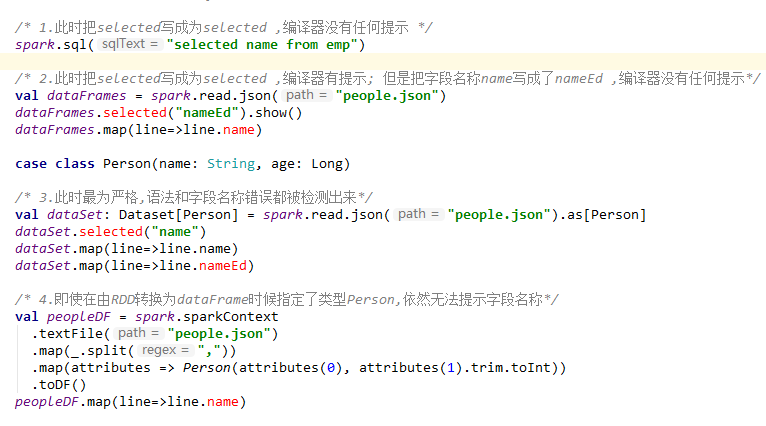
这里一个可能的疑惑是DataFrame明明是有确定的Scheme结构(即列名、列字段类型都是已知的),但是为什么还是无法对列名进行推断和错误判断,这是因为DataFrame是Untyped的。
2.5 Untyped & Typed
在上面我们介绍过DataFrame API被标记为Untyped API,而DataSet API被标记为Typed API。DataFrame的Untyped是相对于语言或API层面而言,它确实有明确的Scheme结构,即列名,列类型都是确定的,但这些信息完全由Spark来维护,Spark只会在运行时检查这些类型和指定类型是否一致。这也就是为什么在Spark 2.0之后,官方推荐把DataFrame看做是DatSet[Row],Row是Spark中定义的一个trait,其子类中封装了列字段的信息。
相对而言,DataSet是Typed的,即强类型。如下面代码,DataSet的类型由Case Class(Scala)或者Java Bean(Java)来明确指定的,在这里即每一行数据代表一个Person,这些信息由JVM来保证正确性,所以字段名错误和类型错误在编译的时候就会被IDE所发现。
case class Person(name: String, age: Long)
val dataSet: Dataset[Person] = spark.read.json("people.json").as[Person]
三、DataFrame & DataSet & RDDs 总结
这里对三者做一下简单的总结:
- RDDs适合非结构化数据的处理,而DataFrame & DataSet更适合结构化数据和半结构化的处理;
- DataFrame & DataSet可以通过统一的Structured API进行访问,而RDDs则更适合函数式编程的场景;
- 相比于DataFrame而言,DataSet是强类型的(Typed),有着更为严格的静态类型检查;
- DataSets、DataFrames、SQL的底层都依赖了RDDs API,并对外提供结构化的访问接口。
四、Spark SQL的运行原理
DataFrame、DataSet和Spark SQL的实际执行流程都是相同的:
- 进行DataFrame/Dataset/SQL编程;
- 如果是有效的代码,即代码没有编译错误,Spark会将其转换为一个逻辑计划;
- Spark将此逻辑计划转换为物理计划,同时进行代码优化;
- Spark然后在集群上执行这个物理计划(基于RDD操作) 。
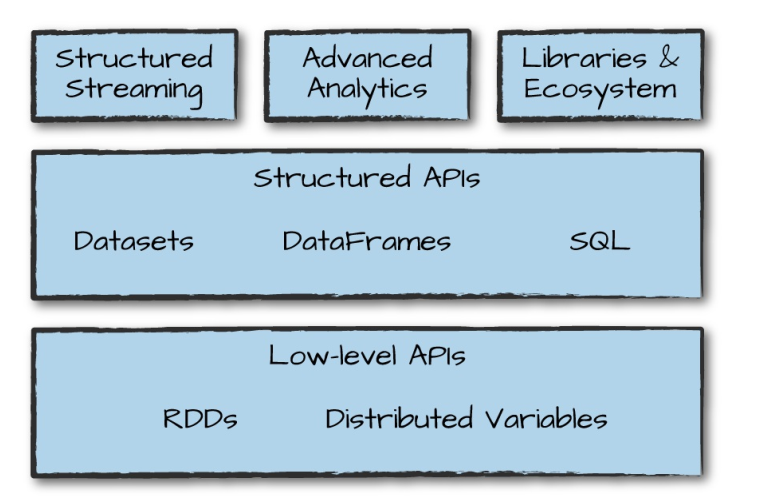
4.1 逻辑计划(Logical Plan)
执行的第一个阶段是将用户代码转换成一个逻辑计划。它首先将用户代码转换成unresolved logical plan(未解决的逻辑计划),之所以这个计划是未解决的,是因为尽管您的代码在语法上是正确的,但是它引用的表或列可能不存在。 Spark使用analyzer(分析器)基于catalog(存储的所有表和DataFrames的信息)进行解析。解析失败则拒绝执行,解析成功则将结果传给Catalyst优化器(Catalyst Optimizer),优化器是一组规则的集合,用于优化逻辑计划,通过谓词下推等方式进行优化,最终输出优化后的逻辑执行计划。
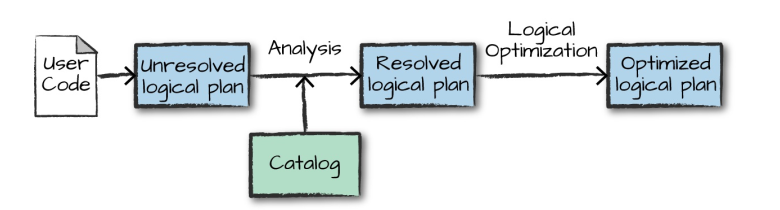
4.2 物理计划(Physical Plan)
得到优化后的逻辑计划后,Spark就开始了物理计划过程。 它通过生成不同的物理执行策略,并通过成本模型来比较它们,从而选择一个最优的物理计划在集群上面执行的。物理规划的输出结果是一系列的RDDs和转换关系(transformations)。
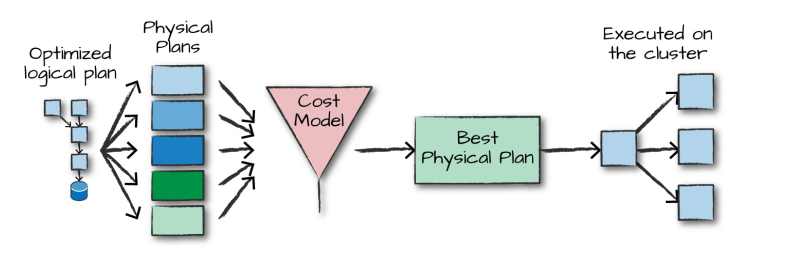
4.3 执行
在选择一个物理计划后,Spark运行其RDDs代码,并在运行时执行进一步的优化,生成本地Java字节码,最后将运行结果返回给用户。
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
- Spark SQL, DataFrames and Datasets Guide
- 且谈 Apache Spark 的 API 三剑客:RDD、DataFrame 和 Dataset(译文)
- A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets(原文)
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(八)—— Spark SQL 之 DataFrame和Dataset的更多相关文章
- Spark学习之路 (十八)SparkSQL简单使用
一.SparkSQL的进化之路 1.0以前: Shark 1.1.x开始: SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Dataframe 1.5.x: S ...
- Spark学习之路 (十八)SparkSQL简单使用[转]
SparkSQL的进化之路 1.0以前: Shark 1.1.x开始: SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Dataframe 1.5.x: Spar ...
- Spark学习之路(九)—— Spark SQL 之 Structured API
一.创建DataFrame和Dataset 1.1 创建DataFrame Spark中所有功能的入口点是SparkSession,可以使用SparkSession.builder()创建.创建后应用 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- spark结构化数据处理:Spark SQL、DataFrame和Dataset
本文讲解Spark的结构化数据处理,主要包括:Spark SQL.DataFrame.Dataset以及Spark SQL服务等相关内容.本文主要讲解Spark 1.6.x的结构化数据处理相关东东,但 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- Spark学习之路 (八)SparkCore的调优之开发调优[转]
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark学习之路(十一)—— Spark SQL 聚合函数 Aggregations
一.简单聚合 1.1 数据准备 // 需要导入spark sql内置的函数包 import org.apache.spark.sql.functions._ val spark = SparkSess ...
随机推荐
- C#中的SMTP配置Outlook.Com SMTP主机
如果你想以编程方式使用 Outlook.com或Gmail帐户作为 SMTP主机 发送电子邮件,也有为了得到这一切工作的几件事情要注意. 使用基本的System.Net.Mail库, ...
- hibernate validator 专题
JSR-303 原生支持的限制有如下几种 : 限制 说明 @Null 限制只能为 null @NotNull 限制必须不为 null @AssertFalse 限制必须为 false @AssertT ...
- Emoji:搜索将与您找到表情符号背后的故事
眼下.秉已经开始支持emoji搜索,这意味着,你可以插入或粘贴系列emoji表情,让我们的爱.微笑.食品等..些表情随意组合,必应总会带给你非常多有趣的但却没有不论什么实际用途的搜索结果. 这是一项非 ...
- Ninject之旅之十四:Ninject在ASP.NET Web Form程序上的应用(附程序下载)
摘要 ASP.NET Web Forms没有像MVC那样的可扩展性,也不可能使它创建UI页面支持没有构造函数的的激活方式.这个Web Forms应用程序的的局限性阻止了它使用构造函数注入模式,但是仍能 ...
- img前置显示屏装load图片
只需要设置img的background能够 <img src="" alt="" class="detailImg" > cs ...
- wpf实现仿qq消息提示框
原文:wpf实现仿qq消息提示框 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/huangli321456/article/details/5052 ...
- 关于C#你应该知道的2000件事
原文 关于C#你应该知道的2000件事 下面列出了迄今为止你应该了解的关于C#博客的2000件事的所有帖子. 帖子总数= 1,219 大会 #11 -检查IL使用程序Ildasm.exe d #179 ...
- SVN如何迁徙到Git
由于一直都是采用SVN作为源码管理,转到Git不能从头开始吧~~下面就具体说说如何将SVN已有的项目工程迁徙到Git上面 步骤 (1) 安装Git客户端程序(2) 将SVN上面的工程通过Git克隆到本 ...
- 检查Android是否支持指纹识别以及是否已经录入指纹
原文:检查Android是否支持指纹识别以及是否已经录入指纹 Android M 开始,系统中加入了指纹相关功能. 主要用到的类为:FingerprintManager 只提供三个方法: 返回值 方法 ...
- java中==和equels的区别
起初接触java的时候这个问题还是比较迷茫的,最近上班之余刷博客的时候看了一些大神写的文章,自己也来总结一下,直接贴代码: package string; public class demo1 { p ...