Python-beautifulsoup库
#beautifulsoup库的安装
pip install beautifulsoup4
python -m pip install --upgrage pip
from bs4 import BeautifulSoup #----------------beautifulsoup库的使用--------------------------------------
import requests
from bs4 import BeautifulSoup
url = "http://python123.io/ws/demo.html"
r = requests.get(url)
# print(r.text)
demo = r.text
soup = BeautifulSoup(demo,"html.parser") #熬一锅`粥
#print(soup.prettify()) #打印这锅粥 #下行遍历函数:.contents() .children()用于循环 .descendants()
soup.head #获取head标签
soup.head.contents #获取head的子节点,返回类型是列表
soup.body.contents #
len(soup.body.contents) #terurn 5
soup.body.contents[2]
print('以下输出子节点:')
for child in soup.body.children:
print('##',child)
print('以下输出子孙节点:')
for child in soup.body.descendants:
print('**',child) #---上行遍历 .parent .parents(用于循环)
soup.title.parent #return <head><title>This is a python demo page</title></head>
soup.html.parents #返回 html所有内容
soup.parent #返回为空
print('以下输出父节点:')
for par in soup.a.parents:
if par is None:
print('$$$',par)
else:
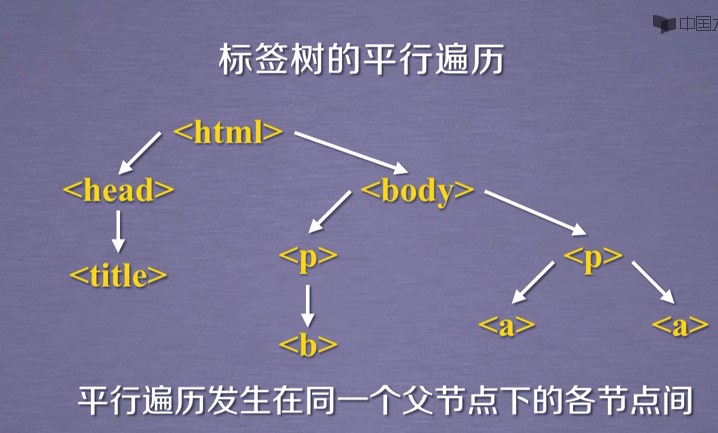
print('%',par.name) #----平行遍历----
# 向后.next_sibling 向前.previous_sibling 加 s 用于遍历
#title 与 p标签 不构成平行关系
soup.a.next_sibling #return ' and ' 所以<a>标签的下一个标签不一定是<a>标签,需要判断
soup.a.next_sibling.next_sibling #return <a ...</a> soup.a.previous_sibling
soup.a.previous_sibling.previous_sibling
print('以下输出下行遍历:')
for sibling in soup.a.next_siblings:
print('##',sibling)
print('以下输出上行遍历:')
for sibling in soup.a.previous_siblings:
print('**',sibling)

Python-beautifulsoup库的更多相关文章
- python BeautifulSoup库的基本使用
Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree). 它提供简单又常用的导航(navigating),搜索以 ...
- python BeautifulSoup库用法总结
1. Beautiful Soup 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- Python BeautifulSoup库的用法
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的Python库,它通过解析器把文档解析为利于人们理解的文档导航模式,有利于查找和修改文档. BeautifulSoup3目前已经 ...
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
- python爬虫从入门到放弃(六)之 BeautifulSoup库的使用
上一篇文章的正则,其实对很多人来说用起来是不方便的,加上需要记很多规则,所以用起来不是特别熟练,而这节我们提到的beautifulsoup就是一个非常强大的工具,爬虫利器. beautifulSoup ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- python下载安装BeautifulSoup库
python下载安装BeautifulSoup库 1.下载https://www.crummy.com/software/BeautifulSoup/bs4/download/4.5/ 2.解压到解压 ...
- python爬虫学习(一):BeautifulSoup库基础及一般元素提取方法
最近在看爬虫相关的东西,一方面是兴趣,另一方面也是借学习爬虫练习python的使用,推荐一个很好的入门教程:中国大学MOOC的<python网络爬虫与信息提取>,是由北京理工的副教授嵩天老 ...
- python库:bs4,BeautifulSoup库、Requests库
Beautiful Soup https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ Beautiful Soup 4.2.0 文档 htt ...
随机推荐
- Fiddler抓包工具的基本操作
Fiddler ——位于客户端和服务器端的HTTP代理 代理:客户端所有请求都先经过fiddler,然后转发到相应服务器 服务器端所有相应都先经过fiddler,然后发送到客户端 1. 常用的HTTP ...
- 解决 Mybatis报错org.apache.ibatis.ognl.NoSuchPropertyException: XXXCriteria$Criterion.noValue
问题 这个noValue一定存在,但是报错. 场景就是存在并发的情况下,尤其是在服务刚刚启动的时候,就会发生这个异常. 但是很不幸,mybatis 3.4.1之前,用的 OGNL都是由这个问题. 分析 ...
- win8 批处理自动填写ip
本文适用于,经常把电脑来回带而又每次都得改ip的人 有木有觉得,这很麻烦,而又必须得这样做? 人真是因为懒惰而变得聪明.如果你不想每次重复填写,有幸百度到了这篇文章,感谢你的阅读. 现在我把研究成果共 ...
- 模块基础 day15
目录 模块的四种形式 内置模块 pip安装的模块 自定义模块 包(模块) import和from···import 循环导入 模块的搜索路径 python文件的两种用途 模块的四种形式 模块就是一系列 ...
- ios下app内嵌h5页面是video适配问题
ios下做新闻详情用h5页面实现然后打包到app中,其中新闻详情页会有视频,安卓下video的poster可以做到适应video大小,但是ios下会按照poster图片大小将video等比撑大,但是视 ...
- Lucas的数论:杜教筛,莫比乌斯反演
Description: 求$\sum\limits_{i=1}^{n} \sum\limits_{j=1}^{n} d(i \times j)$ $d(i)$表示$i$的约数个数和.$n \leq ...
- 分布式系统中session一致性问题
业务场景 在单机系统中,用户登陆之后,服务端会保存用户的会话信息,只要用户不退出重新登陆,在一段时间内用户可以一直访问该网站,无需重复登陆.用户的信息存在服务端的 session 中,session中 ...
- Function题解
这个题最优策略一定是向左上走到某一列再往上一直走. n*q在线暴力可做,离线按y排序,单调栈维护凸壳. 具体来说:对于i<j若A[i]>A[j] 即j的斜率小而且纵截距小,一定比i优,并且 ...
- 从V神到以太坊——以太坊发展简史
以太坊的出现,让人们的认识从比特币飞跃到了区块链本身.使得区块链技术在非金融领域的普遍应用成为可能,同时,也被认为是区块链2.0时代的标志,是区块链技术发展史上重要的里程碑. 以太坊的故事,要从比特币 ...
- map和set的使用及top K问题
1.map和set的应用和比较 map和set都是关联式容器,底层容器都是红黑树. map以键值对的形式进行存储,方便进行查找,关键词起到索引的作用,值则表示与索引相关联的数据,以红黑树的结构实现,插 ...