阿里巴巴大规模神龙裸金属 Kubernetes 集群运维实践
作者 | 姚捷(喽哥)阿里云容器平台集群管理高级技术专家
本文节选自《不一样的 双11 技术:阿里巴巴经济体云原生实践》一书,点击即可完成下载。

导读:值得阿里巴巴技术人骄傲的是 2019 年阿里巴巴 双11 核心系统 100% 以云原生的方式上云,完美支撑了 54.4w 峰值流量以及 2684 亿的成交量。背后承载海量交易的计算力就是来源于容器技术与神龙裸金属的完美融合。
集团上云机器资源形态
阿里巴巴 双11 采用三地五单元架构,除 2 个混部单元外,其他 3 个均是云单元。神龙机型经过 618、99 大促的验证,性能和稳定性已大幅提升,可以稳定支撑 双11。今年 双11 的 3 个交易云单元,已经 100% 基于神龙裸金属,核心交易电商神龙集群规模已达到数万台。
神龙架构
阿里云 ECS 虚拟化技术历经三代,前二代是 Xen 与 KVM,神龙是阿里巴巴自研的第三代 ECS 虚拟化技术产品,它具备以下四大技术特征:
- 存储和网络 VMM 以及 ECS 管控,和计算虚拟化分离部署;
- 计算虚拟化进一步演化至 Near
Metal Hypervisor; - 存储和网络 VMM 通过芯片专用 IP 业务加速;
- 并池支持弹性裸金属和 ECS 虚拟机生产。
简而言之,神龙将网络/存储的虚拟化开销 offload 到一张叫 MOC 卡的 FPGA 硬件加速卡上,降低了原 ECS 约 8% 的计算虚拟化的开销,同时通过大规模 MOC 卡的制造成本优势,摊平了神龙整体的成本开销。神龙类物理机特性,可进行二次虚拟化,使得对于新技术的演进发展留足了空间,对于采用一些多样的虚拟化的技术,像 Kata、Firecracker 等成为了可能。
在阿里巴巴 双11 大规模迁移到神龙架构前,通过在 618/99 大促的验证,我们发现集团电商的容器运行在云上神龙反而比非云物理机的性能要好 10%~15%,这令我们非常诧异。经过分析,我们发现主要是因为虚拟化开销已经 offload 到 MOC 卡上,神龙的 CPU/Mem 是无虚拟化开销的,而上云后运行在神龙上的每个容器都独享 ENI 弹性网卡,性能优势明显。同时每个容器独享一块 ESSD 块存储云盘,单盘 IOPS 高达 100 万,比 SSD 云盘快 50 倍,性能超过了非云的 SATA 和 SSD 本地盘。这也让我们坚定了大规模采用神龙来支撑 双11 的决心。
神龙+容器+Kubernetes
在 All in Cloud 的时代企业 IT 架构正在被重塑,而云原生已经成为释放云计算价值的最短路径。2019 年阿里巴巴 双11 核心系统 100% 以云原生的方式上云,基于神龙服务器、轻量级云原生容器以及兼容 Kubernetes 的调度的新的 ASI(alibaba serverless infra.)调度平台。其中 Kubernetes Pod 容器运行时与神龙裸金属完美融合,Pod 容器作为业务的交付切面,运行在神龙实例上。
下面是 Pod 运行在神龙上的形态:
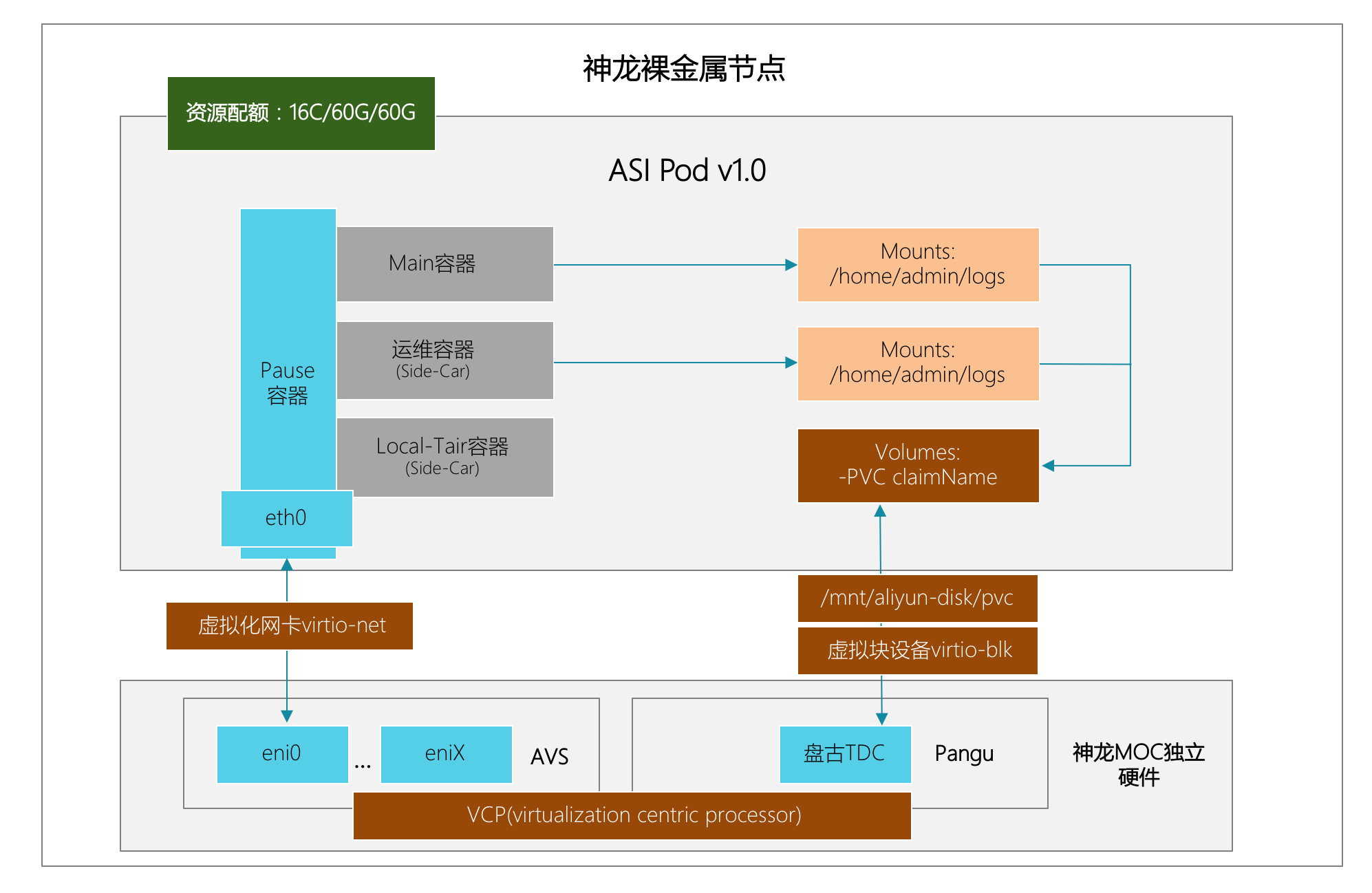
- ASI Pod 运行在神龙裸金属节点上,将网络虚拟化和存储虚拟化 offload 到独立硬件节点 MOC 卡上,并采用 FPGA 芯片加速技术,存储与网络性能均超过普通物理机和 ECS;MOC 有独立的操作系统与内核,可为 AVS(网络处理)与 TDC(存储处理)分配独立的 CPU 核;
- ASI Pod 由 Main 容器(业务主容器),运维容器(star-agent side-car 容器)和其它辅助容器(例如某应用的 Local 缓存容器)构成。Pod 内通过 Pause 容器共享网络命名空间,UTS 命名空间和 PID 命名空间(ASI 关闭了 PID 命名空间的共享);
- Pod 的 Main 容器和运维容器共享数据卷,并通过 PVC 声明云盘,将数据卷挂载到对应的云盘挂载点上。在 ASI 的存储架构下,每一个 Pod 都有一块独立的云盘空间,可支持读写隔离和限制磁盘大小;
- ASI Pod 通过 Pause 容器直通 MOC 卡上的 ENI 弹性网卡;
- ASI Pod 无论内部有多少容器,对外只占用独立的资源,例如 16C(CPU)/60G(内存)/60G(磁盘)。
大规模神龙运维
2019 年 双11 云上核心交易的神龙集群规模已达到数万台,管理和运维如此大规模神龙集群极具挑战,这其中包括云上各类业务实例规格的选择、大规模集群弹性扩缩容、节点资源划分与管控、核心指标统计分析、基础环境监控、宕机分析、节点标签管理、节点重启/锁定/释放、节点自愈、故障机轮转、内核补丁升级、大规模巡检等能力建设。
下面就几个领域细化展开:
实例规格
首先需要针对不同类型业务规划不同的实例规格,包括入口层、核心业务系统、中间件、数据库、缓存服务这些不同特性的基础设施和业务,有些需要高性能的计算、有些需要高网络收发包能力,有些需要高性能的磁盘读写能力。在前期需要系统性整体规划,避免实例规格选择不当影响业务性能和稳定性。实例规格的核心配置参数包括 vcpu、内存、弹性网卡数,云盘数、系统盘大小、数据盘大小、网络收发包能力 (PPS)。
电商核心系统应用的主力机型为 96C/527G,每个 Kubernetes Pod 容器占用一块弹性网卡和一块 EBS 云盘,所以弹性网卡和云盘的限制数非常关键,此次电商上云,神龙将弹性网卡和 EBS 云盘的限制数提高到 64 与 40,有效避免了 CPU 与内存的资源浪费。另外对于不同类型的业务,核心配置也会略有差异,例如入口层 aserver 神龙实例由于需要承担大量的入口流量,对 MOC 的网络收发包能力的要求极高,为避免 AVS 网络软交换 CPU 打满,对于神龙 MOC 卡里的网络和存储的 CPU 分配参数的需求不同,常规计算型神龙实例的 MOC 卡网络/存储的 CPU 分配是 4+8,而 aserver 神龙实例需要配置为 6:6;例如对于云上混部机型,需要为离线任务提供独立的 nvme 本盘实例。为不同类型业务合理规划机型和规格,会极大程度的降低成本,保证性能和稳定性。
资源弹性
双11 需要海量的计算资源来扛住洪峰流量,但这部分资源不可能常态化持有,所以需要合理划分日常集群与大促集群,并在 双11 前几周,通过大规模节点弹性扩容能力,从阿里云弹性申请大批量神龙,部署在独立的大促集群分组里,并大规模扩容 Kubernetes Pod 交付业务计算资源。在 双11 过后,立即将大促集群中的 Pod 容器批量缩容下线,大促集群神龙实例整体销毁下线,日常只持有常态化神龙实例,通过大规模集群弹性扩缩容能力,可大幅节约大促成本。另外从神龙交付周期而言,今年上云后从申请到创建机器,从小时/天级别缩短到了分钟级,上千台神龙可在 5 分钟内完成申请,包括计算、网络、存储资源;在 10 分钟内完成创建并导入 Kubernetes 集群,集群创建效率大幅度提高,为未来常态化弹性资源池奠定基础。
核心指标
对于大规模神龙集群运维,有三个非常核心的指标可以来衡量集群整体健康度,分别是宕机率、可调度率、在线率。
云上神龙宕机原因通常分为硬件问题和内核问题。通过对日宕机率趋势统计和宕机根因分析,可量化集群的稳定性,避免出现潜在的大规模宕机风险出现。可调度率是衡量集群健康度的关键指标,集群机器会因为各种软硬件原因出现容器无法调度到这些异常机器上,例如 Load 大于 1000、磁盘出现压力、docker 进程不存在,kubelet 进程不存在等,在 Kubernetes 集群中,这批机器的状态会是 notReady。2019 年 双11,我们通过神龙宕机重启与冷迁移特性,极大提升了故障机轮转效率,使神龙集群的可调度率始终维持在 98% 以上,大促资源备容从容。而 双11 神龙的宕机率维持在 0.2‰ 以下,表现相当稳定。
标签管理
随着集群规模的增加,管理难度也随之变大。例如如何能筛选出 "cn-shanghai"Region 下生产环境,且实例规格为 "ecs.ebmc6-inc.26xlarge" 的所有机器。我们通过定义大量的预置标签来实现批量资源管理。在 Kubernetes 架构下,通过定义 Label 来管理机器。Label 是一个 Key-Value 健值对,可在神龙节点上使用标准 Kubernetes 的接口打 Label。例如机器实例规格的 Label 可定义 "sigma.ali/machine-model":"ecs.ebmc6-inc.26xlarge", 机器所在的 Region 可定义为 "sigma.ali/ecs-region-id":"cn-shanghai"。通过完善的标签管理系统,可从几万台神龙节点中快速筛选机器,执行诸如灰度分批次服务发布、批量重启、批量释放等常规运维操作。
宕机分析
对于超大规模集群,日常宕机是非常普遍的事情,对宕机的统计与分析非常关键,可以甄别出是否存在系统性风险。宕机的情况分为很多种,硬件故障会导致宕机,内核的 bug 等也会导致宕机,一旦宕机以后,业务就会中断,有些有状态应用就会受到影响。我们通过 ssh 与端口 ping 巡检对资源池的宕机情况进行了监控,统计宕机历史趋势,一旦有突增的宕机情况就会报警;同时对宕机的机器进行关联分析,如根据机房、环境、单元、分组 进行归类,看是否跟某个特定的机房有关;对机型、CPU 进行分类统计,看是否跟特定的硬件有关系;同时 OS 版本、内核版本进行归类,看是否都发生在某些特定的内核上。
对宕机的根因,也进行了综合的分析,看是硬件故障,还是有主动运维事件。内核的 kdump 机制会在发生 crash 的时候生成 vmcore,我们也对 vmcore 里面提取的信息进行归类,看某一类特定的 vmcore 关联的宕机数有多少。内核日志有些出错的信息,如 mce 日志、soft lockup 的出错信息等,也能发现系统在宕机前后是否有异常。
通过这一系列的宕机分析工作,把相应的问题提交给内核团队,内核专家就会分析 vmcore,属于内核的缺陷会给出 hotfix 解决这些导致宕机的问题。
节点自愈
运维大规模神龙集群不可避免地会遇到软硬件故障,而在云上技术栈更厚,出现问题会更为复杂。如果出问题单纯依靠人工来处理是不现实的,必须依赖自动化能力来解决。1-5-10 节点自愈可提供 1 分钟异常问题发现,5 分钟定位,10 分钟修复的能力。主要的神龙机器异常包括宕机、夯机、主机 load 高、磁盘空间满、too many openfiles、核心服务(Kubelet、Pouch、Star-Agent)不可用等。主要的修复动作包括宕机重启、业务容器驱逐、异常软件重启、磁盘自动清理,其中 80% 以上的问题可通过重启宕机机器与将业务容器驱逐到其他节点完成节点自愈。另外我们通过监听神龙 Reboot 重启与 Redepoly 实例迁移两个系统事件来实现 NC 侧系统或硬件故障的自动化修复。
未来展望
2020 年 双11,阿里巴巴经济体基础设施将会 100% 基于 Kubernetes,基于 runV 安全容器的下一代混部架构将会大规模落地,轻量化容器架构会演进到下一阶段。
在此大背景下,一方面 Kubernetes 节点管理将会朝向阿里巴巴经济体并池管理方向发展,打通云库存管理,提升节点弹性能力,根据业务特性错峰资源利用,进一步降低机器持有时间从而大幅降低成本。
在技术目标上,我们会采用基于 Kubernetes Machine-Operator 的核心引擎,提供高度灵活的节点运维编排能力,支持节点运维状态的终态维持。另一方面,基于完整的全域数据采集和分析能力,提供极致的全链路监控/分析/内核诊断能力,全面提升容器基础环境的稳定性,为轻量化容器/不可变基础设施架构演进提供极致性能观测与诊断的技术保障。
《不一样的 双11 技术:阿里巴巴经济体云原生实践》
双11 的 2684 亿成交额背后是对一个个技术问题的反复尝试与实践。
这一次,我们对云原生技术在 双11 的实践细节进行深挖,筛选了其中 22 篇有代表性的文章进行重新编排,整理成《不一样的 双11 技术:阿里巴巴经济体云原生实践》一书。
将为你带来不一样的 双11 云原生技术亮点:
- 双11 超大规模 K8s 集群实践中,遇到的问题及解决方法详述;
- 云原生化最佳组合:Kubernetes+容器+神龙,实现核心系统 100% 上云的技术细节;
- 双 11 Service Mesh 超大规模落地解决方案。
“阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”
阿里巴巴大规模神龙裸金属 Kubernetes 集群运维实践的更多相关文章
- 灵雀云:etcd 集群运维实践
[编者的话]etcd 是 Kubernetes 集群的数据核心,最严重的情况是,当 etcd 出问题彻底无法恢复的时候,解决问题的办法可能只有重新搭建一个环境.因此围绕 etcd 相关的运维知识就比较 ...
- etcd 集群运维实践
etcd 是 Kubernetes 集群的数据核心,最严重的情况是,当 etcd 出问题彻底无法恢复的时候,解决问题的办法可能只有重新搭建一个环境.因此围绕 etcd 相关的运维知识就比较重要,etc ...
- PB 级大规模 Elasticsearch 集群运维与调优实践
PB 级大规模 Elasticsearch 集群运维与调优实践 https://mp.weixin.qq.com/s/PDyHT9IuRij20JBgbPTjFA | 导语 腾讯云 Elasticse ...
- 集群运维ansible
ssh免密登录 集群运维 生成秘钥,一路enter cd ~/.ssh/ ssh-keygen -t rsa 讲id_rsa.pub文件追加到授权的key文件中 cat ~/.ssh/id_rsa.p ...
- Kubernetes 集群无损升级实践 转至元数据结尾
一.背景 活跃的社区和广大的用户群,使 Kubernetes 仍然保持3个月一个版本的高频发布节奏.高频的版本发布带来了更多的新功能落地和 bug 及时修复,但是线上环境业务长期运行,任何变更出错都可 ...
- vivo 公司 Kubernetes 集群 Ingress 网关实践
文章转载自:https://mp.weixin.qq.com/s/qPqrJ3un1peeWgG9xO2m-Q 背景 vivo 人工智能计算平台小组从 2018 年底开始建设 AI 计算平台至今,已经 ...
- PB级大规模Elasticsearch集群运维与调优实践
导语 | 腾讯云Elasticsearch 被广泛应用于日志实时分析.结构化数据分析.全文检索等场景中,本文将以情景植入的方式,向大家介绍与腾讯云客户合作过程中遇到的各种典型问题,以及相应的解决思路与 ...
- PB级大规模Elasticsearch集群运维与调优实践【>>戳文章免费体验Elasticsearch服务30天】
[活动]Elasticsearch Service免费体验馆>> Elasticsearch Service自建迁移特惠政策>>Elasticsearch Service新用户 ...
- Elasticsearch 学习之携程机票ElasticSearch集群运维驯服记(强烈推荐)
转自: https://mp.weixin.qq.com/s/wmSTyIGCVhItVNPHcH7nsA 一.整体架构 为什么采用ES作为搜索引擎呢?在做任何事情的时候,不要一上来就急着了解怎么做这 ...
随机推荐
- dubbo集成zookeeper rpc远程调用
注:下面使用dubbo依赖的是zookeeper注册中心,这里没有详细的介绍.在配置之前,请自行准备好zookeeper环境. 后续如果写zookeeper的配置会补放链接 添加Gradle依赖 co ...
- C加加学习之路 1——开始
C++是一门古老而复杂的语言,绝不是一门可以速成的语言,学习它需要有意识的刻意练习和长时间的持续不断的磨练.而大多数人不太能耐得住寂寞,喜欢速成,所以像<21天学通C++>这种书就比较受欢 ...
- 使用SQLserver Management Studio连接VS2012自带数据库
下载 Microsoft® SQL Server® 2008 Management Studio Express http://www.microsoft.com/zh-CN/download/det ...
- Andriod开发环境搭建
一.相关安装文件准备
- 列表渲染.html
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 爬虫基本库的使用---requests库
使用requests---实现Cookies.登录验证.代理设置等操作 处理网页验证和Cookies时,需要写Opener和Handler来处理,为了更方便地实现这些操作,就有了更强大的库reques ...
- 转:NFS原理详解
原文:http://atong.blog.51cto.com/2393905/1343950 一.NFS介绍 1)什么是NFS 它的主要功能是通过网络让不同的机器系统之间可以彼此共享文件和目录.NFS ...
- CheckStyle,定制属于自己的Java编码规范
前言 如今,代码规范几乎是当下稍有追求的团队都要求做到的,但是对于Java编码规范,不同的公司或团队却有着不同的标准.尽管官方提供了一些标准,但是在基本规则的基础上,各大公司又有自己的规范,比如Sun ...
- android内嵌H5页(webview)如何定位
一.切换至webview后再定位元素 (1)获取页面上下文 contexts = driver.contexts (2)切换至webview driver.switch_to.context(cont ...
- Weed:线段树
观察复杂度,是log级别以下回答询问的. O(1)?逗我kx呢? 自然而然地想到线段树. 学长讲的原题啊考场上还不会打. 线段树上的每个节点都表示一个操作区间. 线段树上维护的权值有3个:这个子区间一 ...