MYSQL-JDBC批量新增-更新-删除
1 概述
最近在极客时间买了几个专栏,MYSQL实战45讲,SQL必知必会,如果你想深入MYSQL的话,推荐你看MYSQL实战45讲,非常不错,并且一定要看留言区,留言区的质量非常高,丁奇老师太太太负责任了,我在极客时间买了不少课程,丁奇老师对大部分评论都进行了回答,这是在其他专栏中很少见的,文章的内容+留言区的问题+丁奇老师的解答都非常不错。这是目前为止我在极客时间买到的最好的课程。
当然如果你想入门SQL,你可以看下SQL必知必会,该专栏比较简单,属于SQL入门课程。
随着时代的变迁,我越发觉得数据变得越来越重要,无论是大数据、还是人工智能、物联网,本质上都是数据在起作用。大数据是涉及从大量数据中收集,存储,分析和获取的通用平台。人工智能和机器学习是两种更智能更有效的方式筛选数据和信息的技术。移动和物联网设备用于从客户,用户和受众收集数据。
因此最近我一直在研究MYSQL和JDBC的高级用法,形成本篇博客,与大家一起分享。关于MYSQL和JDBC的简单用法和概述,大家可以参考其他博客,我就不重复造轮子了。
2 开启MYSQL服务端日志
找到 my.ini 文件,我的电脑上是在 C:\ProgramData\MySQL\MySQL Server 5.7目录下
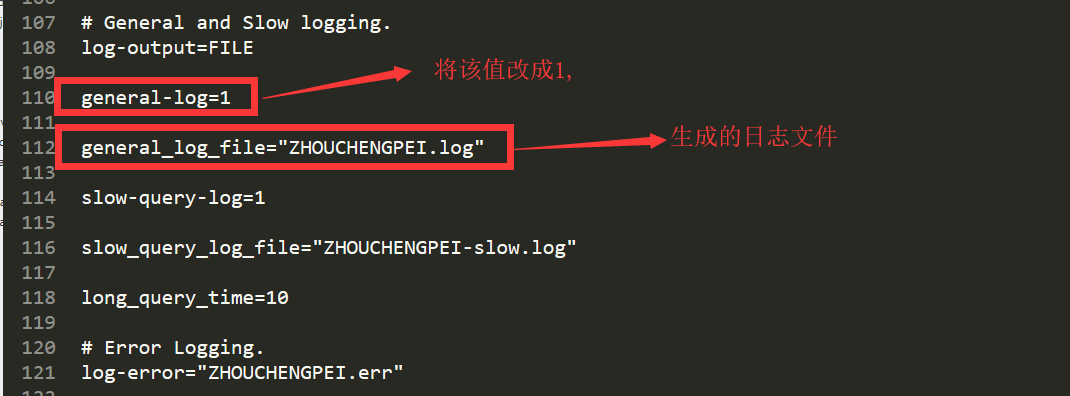
然后重启MYSQL服务器,在my.ini同级的Data目录下,你就可以看到 该日志文件。
3 深入MYSQL/JDBC批量插入
在url后面一定写rewriteBatchedStatements=true,开启批处理。
类似于:jdbc:mysql://127.0.0.1:3306/aaa?characterEncoding=UTF8&useUnicode=true&rewriteBatchedStatements=true
3.1 从一个例子出发
MYSQL 插入 就两种形式
- insert into student('name') values('adai')
- insert into student('name') values('adai'),('hello'),('sky')
对比一下插入效率,3000条数据,数据都是一样的。
第一种:首先插入3000条数据,3000个insert,在navicat执行,耗时3.360s
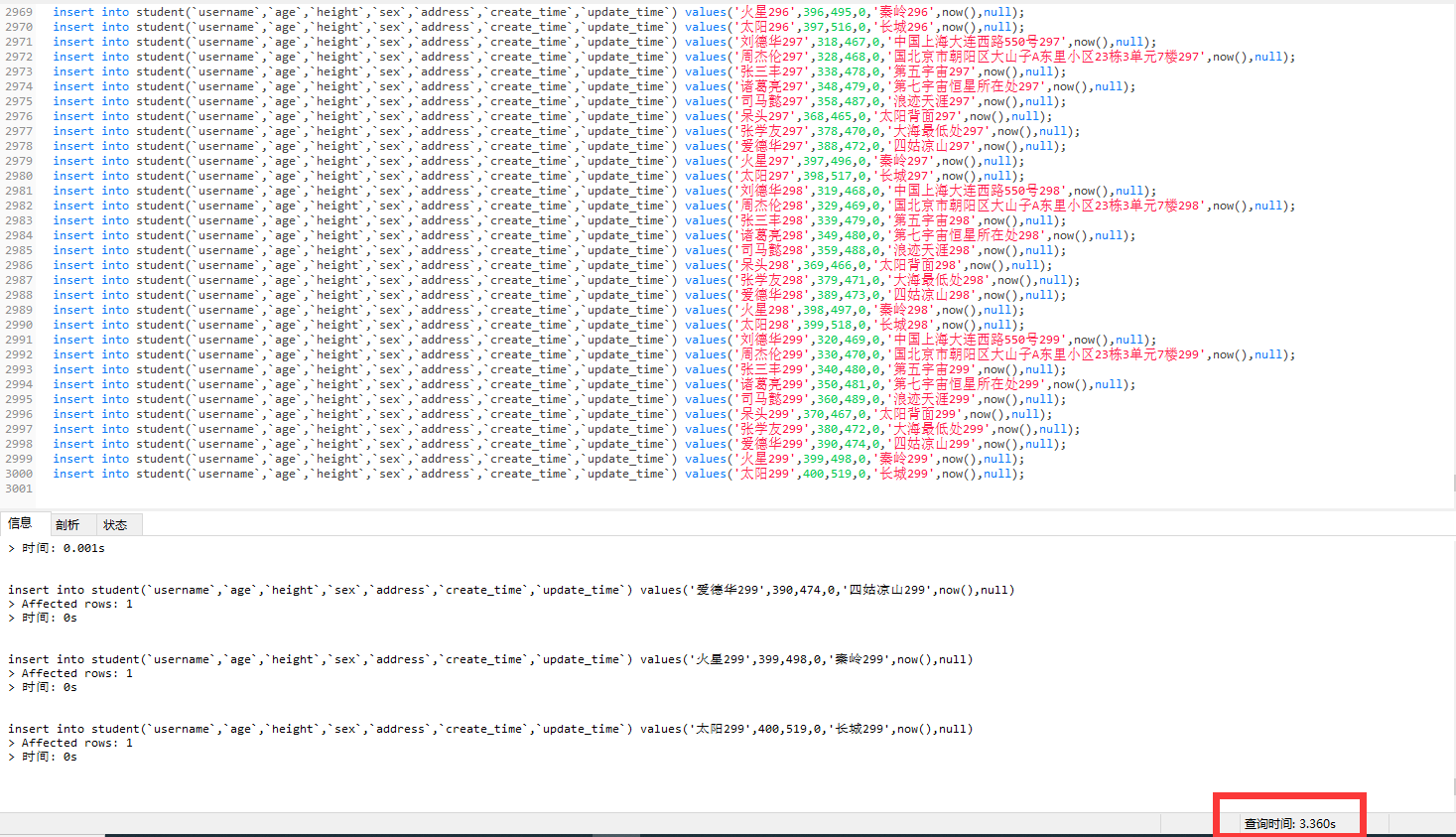
然后在服务端看日志,会发现mysql,是一条一条逐步insert的,总共服务端执行3000次insert

第二种:插入3000条数据,一个insert,在navicat执行,耗时0.241秒

然后看服务端日志,会发现mysql,是批量插入的,只有一个insert,多个values

这应该非常容易理解,按照计算机理论知识,批量插入效率铁定比单条插入效率高。
注意,如果批量插入中间出现错误,那么整个insert会失败,不会插入任何数据,及该条insert批量插入是一个事务操作,要么全部插入成功,要么全部都插入失败
3.2 JDBC的批量插入操作
由于SQL注入等问题,Statement已经用的很少了,JDBC我们主要讲preparedStatement的批量插入,核心代码如下所示:
private static final String[] names = {"刘德华", "周杰伦", "张三丰", "诸葛亮", "司马懿", "呆头", "张学友", "爱德华", "火星", "太阳"};
private static final Integer[] ages = {21, 31, 41, 51, 61, 71, 81, 91, 100, 101};
private static final Integer[] heights = {170, 171, 181, 182, 190, 168, 173, 175, 199, 220};
private static final Byte[] sexs = {0, 1};
private static final String[] address = {"中国上海大连西路550号",
"国北京市朝阳区大山子A东里小区23栋3单元7楼",
"第五宇宙", "第七宇宙恒星所在处", "浪迹天涯", "太阳背面", "大海最低处", "四姑凉山", "秦岭", "长城"};
private static final Integer NUMBER = 100000;
private static void prepareStatementBatch(Connection connection) throws SQLException {
String sql = "insert into student(`username`,`age`,`height`,`sex`,`address`,`create_time`,`update_time`) values(?,?,?,?,?,now(),null)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
long begin = System.currentTimeMillis();
for (int i = 0; i < NUMBER; i++) {
String name = names[j] + i;
int age = ages[j] + i;
int height = heights[j] + i;
Byte sex = sexs[0];
String addre = address[j] + i;
preparedStatement.setString(1, name);
preparedStatement.setInt(2, age);
preparedStatement.setInt(3, height);
preparedStatement.setByte(4, sex);
preparedStatement.setString(5, addre);
preparedStatement.addBatch();
if ((i + 1) % 500 == 0) {
preparedStatement.executeBatch();
preparedStatement.clearBatch();
}
}
// 执行剩下的
preparedStatement.executeBatch();
long end = System.currentTimeMillis();
System.out.println("prepareStatementBatch 消耗时间:" + (end - begin));
}
打开mysql服务器日志:我们可以看到就两条 insert语句,后面跟了很多values...,从第一个例子可以看出,这样的执行效率非常高。

3.3 两个常被忽略的问题
上面的代码中出现了
if ((i + 1) % 500 == 0) {
preparedStatement.executeBatch();
preparedStatement.clearBatch();
}
我个人觉得有两个原因:
1. 防止内存溢出。
2. MYSQL有一个max_packet_allowed参数,会限制Server接受的数据包大小。有时候大的插入和更新会受 max_allowed_packet 参数限制,导致大数据写入或者更新失败。
但是经过我的代码实验,只会出现第一种内存溢出的情况,而不会出现第二种max_packet_allowed超出的情况。
因为MYSQL驱动在底层已经对max_packet_allowed进行了处理。 debug 源码 进行跟踪
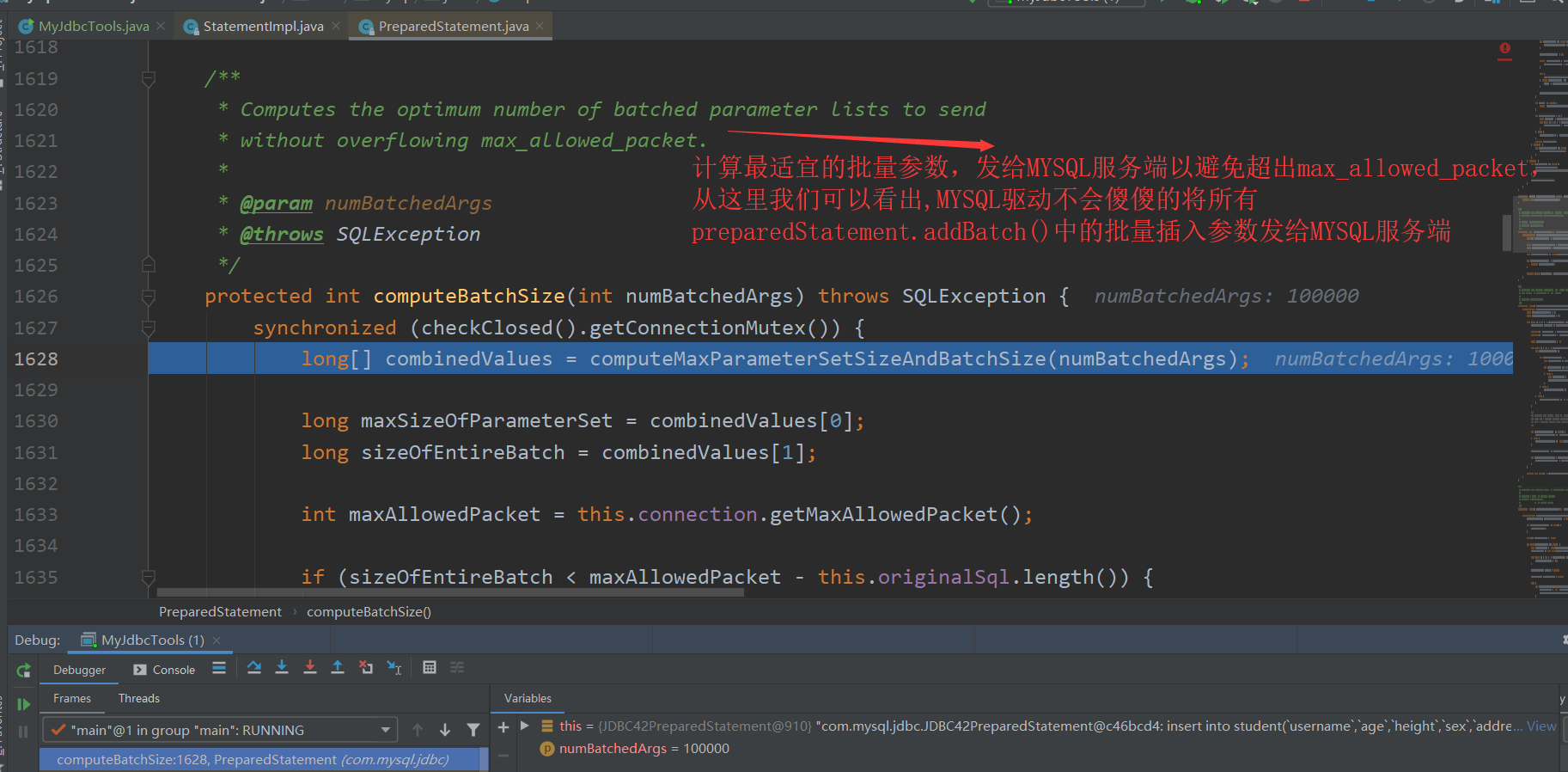

并且在调用preparedStatment.executeBatch()方法后,不需要手动调用preparedStatement.clearBatch(),因为MYSQL驱动自己会在调用executeBatch()方法后,执行clearBatch()
protected long[] executeBatchInternal() throws SQLException {
synchronized (checkClosed().getConnectionMutex()) {
... ... ...
} finally {
this.statementExecuting.set(false);
clearBatch(); // clearBatch()在 finally 语句块中
}
}
总结一下,这里有两个常被忽略的问题:
MYSQL的
prepareStatement.executeBatch()方法底层会自动判断max_allowed_packet大小,然后对batch里面的集合数据分批传给MYSQL服务端,因此肯定不会报
com.mysql.jdbc.PacketTooBigException: Packet for query is too large (5372027 > 4194304)而
Mybatis的批量插入不会对max_allowed_packet进行判断,因此当数据量大的时候,会报这个错误preparedStatment.executeBatch()完后,会自动调用preparedStatement.clearBatch()方法,无需我们手动再进行调用。
3.4 Mybatis批量插入操作
两种方式,数组、List。效果都是一样的,这里我用List进行演示,主要用到Mybatis中的<foreach>
标签
<insert id="insert">
insert into student
(`username`,`age`,`height`,`sex`,`address`,`create_time`,`update_time`) values
<foreach collection="studentList" item="student" index="index" separator=",">
(#{student.username},#{student.age},#{student.height},#{student.sex},#{student.address},now(),null)
</foreach>
查看后台MYSQL服务器日志:
2019-10-31T14:35:50.817807Z 141 Query insert into student(`username`,`age`,`height`,`sex`,`address`,`create_time`,`update_time`) values
('刘德华0',21,170,0,'中国上海大连西路550号0',now(),null)
,
('周杰伦0',31,171,0,'国北京市朝阳区大山子A东里小区23栋3单元7楼0',now(),null)
,
('张三丰0',41,181,0,'第五宇宙0',now(),null)
,
('诸葛亮0',51,182,0,'第七宇宙恒星所在处0',now(),null)
,
('司马懿0',61,190,0,'浪迹天涯0',now(),null)
,
('呆头0',71,168,0,'太阳背面0',now(),null)
,
('张学友0',81,173,0,'大海最低处0',now(),null)
,
('爱德华0',91,175,0,'四姑凉山0',now(),null)
,
('火星0',100,199,0,'秦岭0',now(),null)
,
('太阳0',101,220,0,'长城0',now(),null)
... ... ... ... ... ...
... ... ... ... ... ...
... ... ... ... ... ...
可以看到,Mybatis底层就是使用一个insert,多个value的插入操作。
不过要特意留意,Mybatis的批量插入操作,不会像JDBC的preparedStatement.execute()一样,会自动判断MYSQL服务器的 max_allow_packet大小,然后进行分批传输。Mybatis会将所有的value拼接在一起,然后将这整个insert语句传给MYSQL服务器去执行。如果这整个sql语句超出了 max_allow_packet,那么错误将会产生。
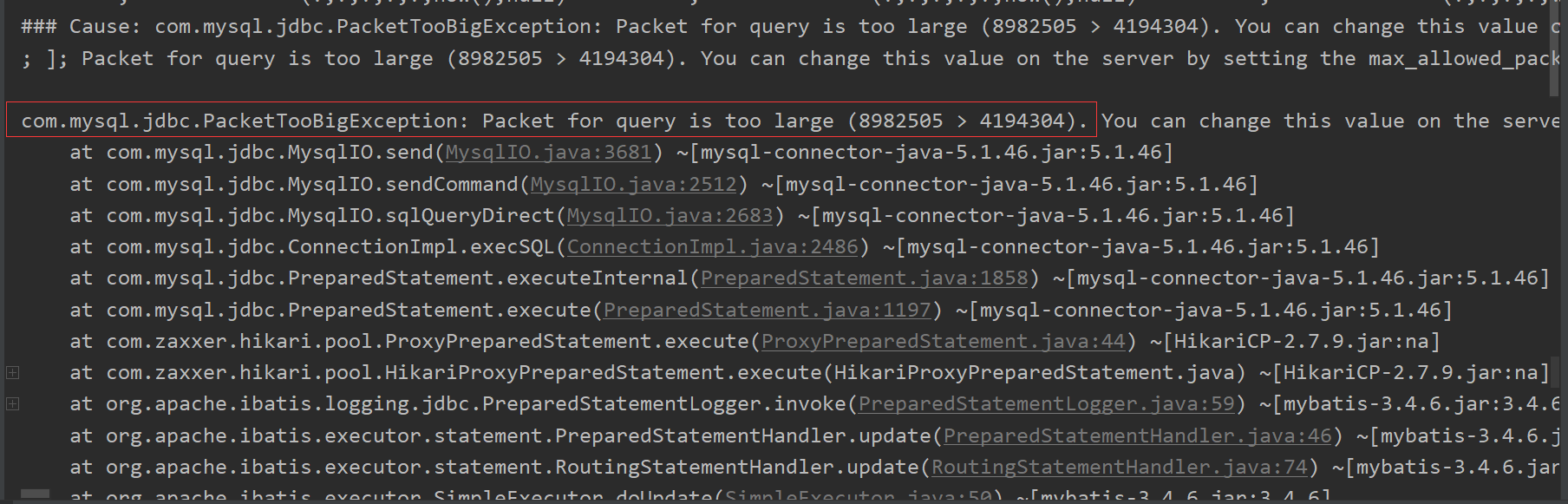
总结:
不管是MYSQL、JDBC、Mybatis批量插入,底层都是一个 insert、多个values组合。
3.5 误区
很多人将批量插入效率很高的原因,归结于客户端跟服务端交互变少了,因为客户端一次会“攒”很多value,然后再发给服务端,这是不准确的,批量插入效率很高的原因,主要是因为 insert ... value() ...value() ...value()这个SQL特性,这个sql特性省下的时间远远超过 客户端和MYSQL服务端的交互所省下的时间。
4 MYSQL/JDBC批量更新
4.1 MYSQL不支持批量更新
MYSQL是不支持批量更新的
注意:这里的批量更新指的是
update student set username = "adai" where id = 1;
update student set age = 22 where id = 3;
update student set address= '上海' where id = 6;
update student set username = ‘daitou’ and address= '上海' where id = 11;
... ... ... ... ... ...
... ... ... ... ... ...
类似于上面完全不同的update语句,MYSQL服务端只用执行一次,就能全部更新。
但是我们可以利用一些sql技巧,来完成批量更新。但是也有很大的局限性,例如要写很多 CASE ... WHEN。
UPDATE table SET title = (CASE
WHEN id = 1 THEN ‘Great Expectations’
WHEN id = 2 THEN ‘War and Peace’
...
END)
WHERE id IN (1,2,...)
在实际开发中如果遇到大批量更新,一般做法是 事务+单条更新
START TRANSACTION;
UPDATE ...;
UPDATE ...;
UPDATE ...;
UPDATE ...;
COMMIT;
4.2 JDBC的批量更新
既然在MYSQL中是不支持批量更新的,那么JDBC的 preparedStatement.addBatch() 和 preparedStatement.executeBatch() 又是如何执行的呢?
经过代码实验:
当sql是update的时候
for (...){
...
...
preparedStatement.addBatch()
}
preparedStatement.executeBatch()
for(...){
...
...
preparedStatement.executeUpdate()
}
更新15000行数据:
没有使用批量更新 12372
使用批量更新 12227
更新50000行数据:
没有使用批量更新 41295
使用批量更新 39754
更新100000行数据:
没有使用批量更新 80820
使用批量更新 78839
更新300000行数据:
没有使用批量更新 241400
使用批量更新 230104
更新500000行数据:
没有使用批量更新 410912
使用批量更新 398941
查看MYSQL服务器日志:发现批量更新和单独更新的日志都是一样的
update student set ..... where id = ..;
update student set ..... where id = ..;
update student set ..... where id = ..;
update student set ..... where id = ..;
可以看出,使用批量更新,会比单独更新快一些,这主要是因为客户端和服务端交互次数变少,所省下的时间开销。这也进一步证实了在 批量插入insert的时候,主要是insert ... value() ...value() ...value()这个sql特性大大的减少了时间花费。而不是像很多其他博客说的是因为客户端和服务端的交互次数减少。
4.3 注意一个小问题
在使用批量插入/更新的时候,如果已经将批量的sql传给了MYSQL服务器,那么即使停止了客户端程序,这些sql也会被执行。

5 MYSQL/JDBC批量删除
无论是MYSQL还是JDBC,批量删除和批量更新一样。
6 总结
可以看出 JDBC的 preparedStatment.addBatch()和preparedStatment.executeBatch()用在批量增加insert时,能够极高的提高效率,但是用在 update 和 delete时,能够提升部分效率。但是远远没有批量插入提升的多。
没有特殊情况限制,我们在insert、update、delete的时候,建议开启事务,然后执行完毕,手动commit。
SQL执行最快的方式如下:
connection.setAutoCommit(false);
for(int i = 0; i < NUMBER; i++){
...
...
preparedStatement.addBatch(); //NUMBER值不能太大,否则会内存溢出。
}
preparedStatement.executeBatch();
connection.commit();
出处:https://www.cnblogs.com/AdaiCoffee/
本文以学习、研究和分享为主,欢迎转载。如果文中有不妥或者错误的地方还望指出,以免误人子弟。如果你有更好的想法和意见,可以留言讨论,谢谢!
MYSQL-JDBC批量新增-更新-删除的更多相关文章
- MYSQL基础01(新增,修改,删除)
首先说明一下,本人之前一直都是用MSSQL,由于工作原因,每天写上百条sql语句,并持续了几年;由于换了工作目前主要接触的MYSQL;所以现在开始学习MYSQL. 我的学习计划很简单,我在MSSQL使 ...
- oracle批量新增更新数据
本博客介绍一下Oracle批量新增数据和更新数据的sql写法,业务场景是这样的,往一张关联表里批量新增更新数据,然后,下面介绍一下批量新增和更新的写法: 批量新增数据 对于批量新增数据,介绍两种方法 ...
- ado.net 批量添加 更新 删除
自曾列就别往下看 别折腾了 使用 SqlBulkCopy ,dataTable 必须跟sql里面的表字段完全一样 下面在sqlserver中演示 mysql 请google MySqlBulkLo ...
- mysql外键级联更新删除
MySQL支持外键的存储引擎只有InnoDB,在创建外键的时候,要求父表必须有对应的索引,子表在创建外键的时候也会自动创建对应的索引.在创建索引的时候,可以指定在删除.更新父表时,对子表进行的相应操作 ...
- .net core 对dapper 新增 更新 删除 查询 的扩展
早期的版本一直用的是EF,但是EF一直有个让人很不爽的东西需要mapping 实体对象:如果没有映射的情况下连查询都没办法: 所以后来开始使用dapper 但是dapper都是直接用的是sql,这个对 ...
- Oracle批量查询、删除、更新使用BULK COLLECT提高效率
BULK COLLECT(成批聚合类型)和数组集合type类型is table of 表%rowtype index by binary_integer用法笔记 例1: 批量查询项目资金账户号为 &q ...
- 【mybatis】mybatis进行批量更新,报错:com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right
使用mybatis进行批量更新操作: 报错如下: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: You have an erro ...
- mysql批量新增和批量删除
首先推荐使用PreparedStatement的批量处理操作. Connection conn = null; PreparedStatement stmt = null; try{ Class.fo ...
- Mybatis批量更新报错com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException
批量更新数据,非常简单的一段代码,硬是报错,插入的数据也能显示出来 List<User> userlist = new ArrayList<User>(); userlist. ...
随机推荐
- 力扣(LeetCode)整数形式的整数加法 个人题解
对于非负整数 X 而言,X 的数组形式是每位数字按从左到右的顺序形成的数组.例如,如果 X = 1231,那么其数组形式为 [1,2,3,1]. 给定非负整数 X 的数组形式 A,返回整数 X+K 的 ...
- 力扣(LeetCode)猜数字大小 个人题解
我们正在玩一个猜数字游戏. 游戏规则如下:我从 1 到 n 选择一个数字. 你需要猜我选择了哪个数字.每次你猜错了,我会告诉你这个数字是大了还是小了.你调用一个预先定义好的接口 guess(int n ...
- pwnable.kr 第一天
1.FD 直接通过ssh连接上去,然后,看下源代码. #include <stdio.h> #include <stdlib.h> #include <string.h& ...
- vue 学习 渲染、v-指令
vue渲染 在组件中data是一个方法里面的值要是一个对象return出去 export default { name: "HelloWorld", data() { return ...
- 读完此文让你了解各个queue的原理
队列是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作.通俗来讲,就是一个队列中,早来的排在前面,后来的就在队尾,而这个队列大多只有一个出口和入口的单项队列.Queue的重要 ...
- Python爬虫之Selenium的常用方法
1.单个元素的选取 find_element_by_id 通过标签属性Id查找元素 find_element_by_name 通过标签属性name查找元素 find_element ...
- Linux查看系统基本信息、版本信息等
Linux下如何查看版本信息, 包括位数.版本信息以及CPU内核信息.CPU具体型号 1.uname -a (Linux查看版本当前操作系统内核信息) 2.cat /proc/version (L ...
- 02-kubeadm初始化Kubernetes集群
目录 部署 组件分布 部署环境 kubeadm 步骤 基础环境 基础配置 安装基础组件 配置yum源 安装组件 初始化 master 导入镜像 执行命令: 查看组件状态 查看node状态 安装flan ...
- Vue实现mp3音乐播放及动态进度条
今天碰到一个Vue点击mp3播放及进度条动态走动的小功能,记录一下: 首先是通过HTML5 audio标签引入音频: <template> <div class="x-fo ...
- python中的局部变量和全局变量