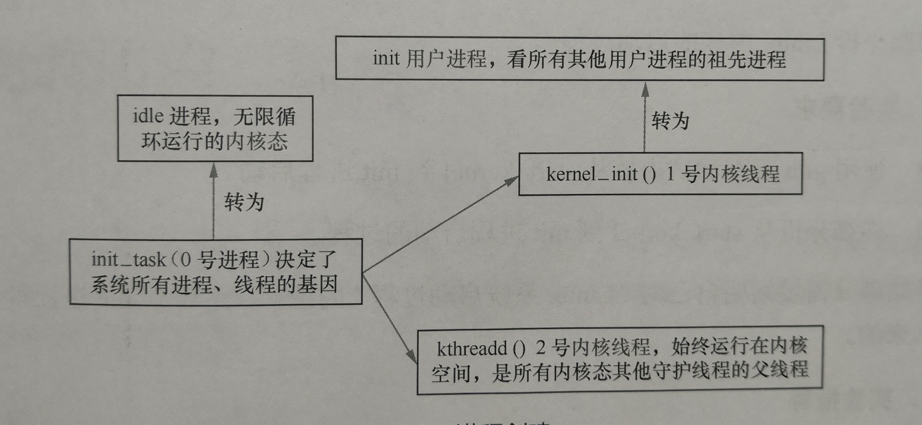
2019-2020-7 20199317《Linux内核原理与分析》第七周作业
第6章 进程的描述和进程的创建
1 进程的描述
操作系统内核实现操作系统的三大管理功能,即进程管理、内存管理和文件系统。其中,操作系统内核中最核心的功能是进程管理。为了管理进程,内核要描述进程的结构,我们称其为进程描述符,进程描述符提供了进程相关的所有信息。
1.1 进程描述符的内容
在Linux内核中用一个数据结构struct task_struct来描述进程,进程描述符的结构如下图所示:
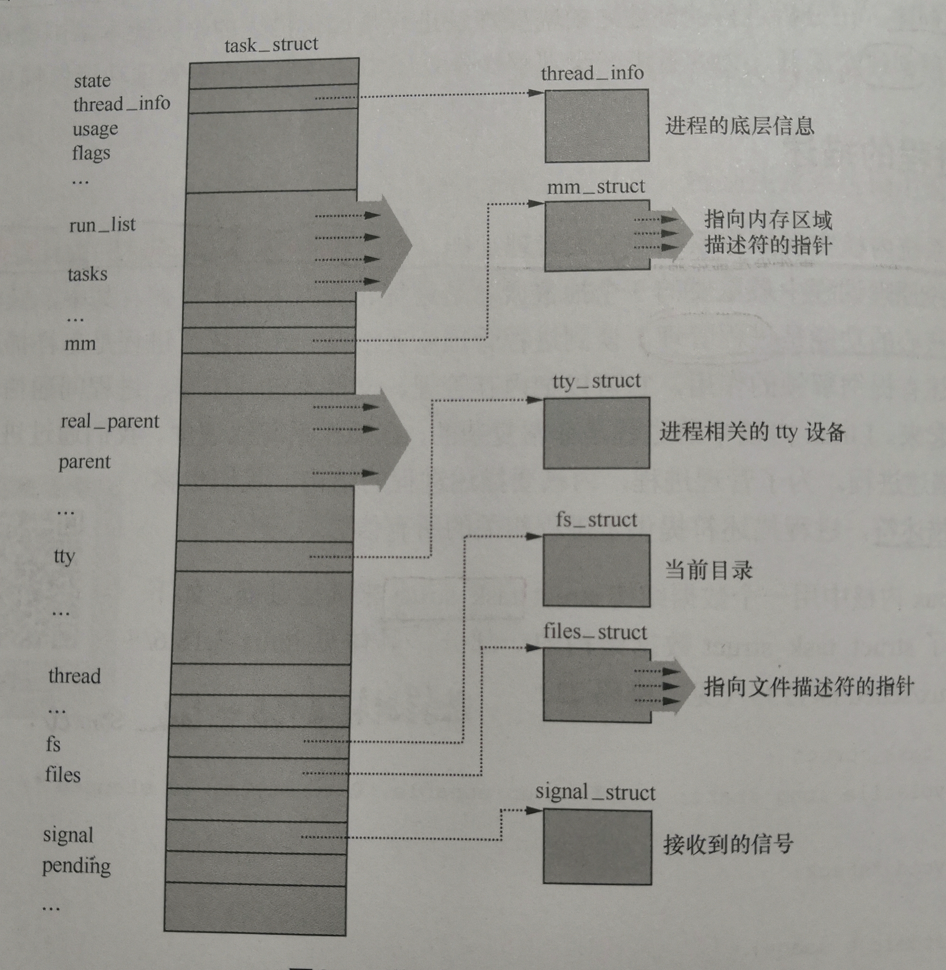
1.2 进程的状态转换
我们知道操作系统原理中的进程有就绪态、运行态、阻塞态这3种基本状态,实际的Linux内核管理的进程状态与这3个状态是很不一样的。如下图所示为Linux内核管理的进程状态转换图:
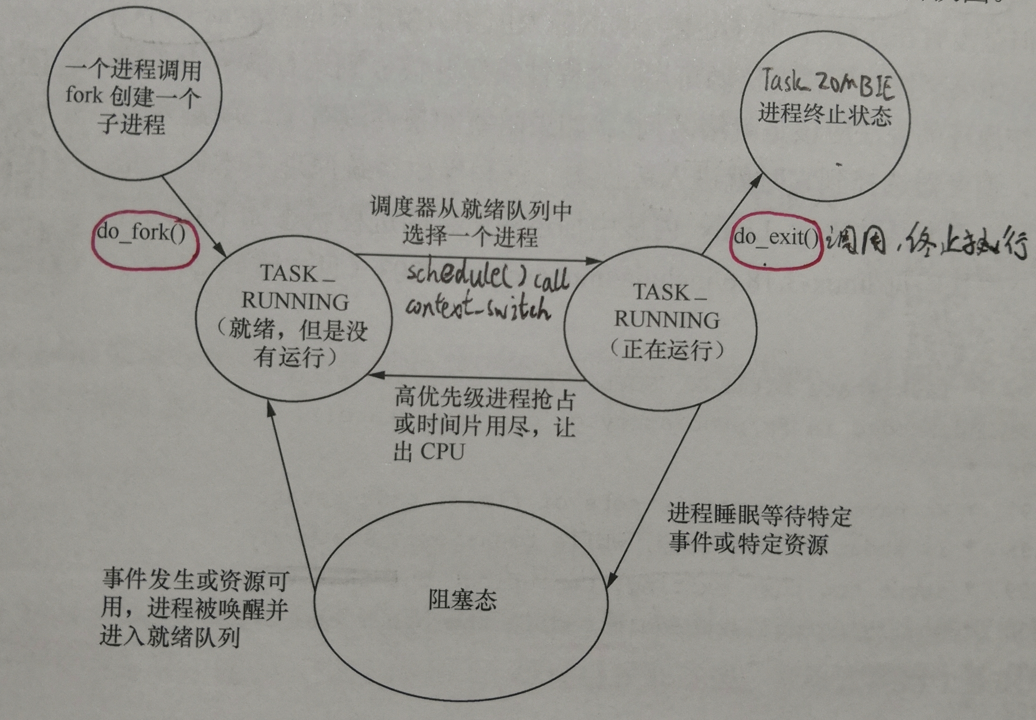
当使用fork()系统调用来创建一个新进程时,新进程的状态是TASK_RUNNING(就绪态,但是没有在运行)。当调度器选择这个新创建的进程运行时,新创建的进程就切换都运行态,它也是TASK_RUNNING。在这里我们可以看到在操作系统原理中的就绪态和运行态两个状态在Linux内核中都是相同的TASK_RUNNING状态,那我们该怎么去区分TASK_RUNNING状态是就绪态还是运行态呢?在Linux内核中,当进程处于TASK_RUNNING状态时,它是可运行的,也就是就绪态,是否在运行取决于它有没有获得CPU的控制权,也就是说这个进程有没有在CPU中实际执行。如果在CPU中实际执行了,进程状态就是运行态;如果被内核调度出去了,在等待队列里就是就绪态。
对于一个正在运行的进程,调用用户态函数exit()会陷入内核执行该内核函数do_exit(),也就是终止进程,那么就是进入TASK_ZOMBIE状态,即进程的终止状态。TASK_ZOMBIE状态的进程一般叫作僵尸进程,Linux内核会在适当的时候把僵尸进程给处理掉,处理掉之后进程描述符被释放了,该进程才从Linux系统里消失。
一个正在运行的进程在等待特定的事件或资源时会进入阻塞态。阻塞态也有两种:TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE。TASK_INTERRUPTIBL状态是可以被信号和wake_up()唤醒的,当信号到来时,进程会被设置为TASK_RUNNING(就绪态),而TASK_UNINTERRUPTIBLE只能被wake_up()唤醒。如果事件发生或者资源可用,进程被唤醒并被放到运行队列上(就绪态),调度器选择到它时就进入运行态。
进程除了状态比较重要之外,还有进程的标识符PID。在进程描述符中用pid和pid和tgid标识进程。
1.3 双向链表
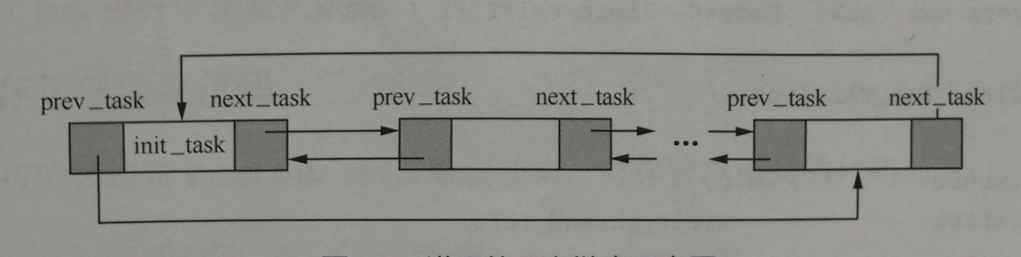
用于管理进程数据结构的双向链表struct list_head tasks是一个很关键的进程链表,它把所有的进程用双向链表链起来,如下图所示:
2 进程的创建
2.1 0号进程的初始化
在第3章的学习中,我们知道了init_task为Linux内核的第一个进程(0号进程),它的初始化是通过硬编码方式固定下来的,init_task进程描述符的初始化代码见/linux-3.18.6/init/init_task.c#18
/* Initial task structure */
struct task_struct init_task = INIT_TASK(init_task);
EXPORT_SYMBOL(init_task);
其中的INIT_TASK宏定义见/linux-3.18.6/include/linux/init_task.h#173。
除init_task之外的所有其他进程的初始化都是通过do_fork复制父进程的方式初始化的。
2.2 进程之间的父子、兄弟关系
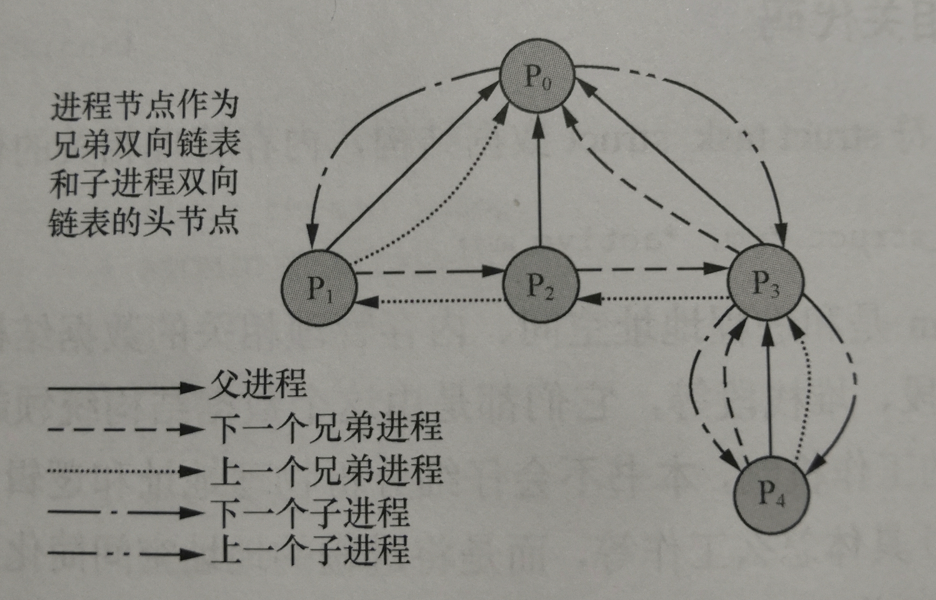
进程描述符通过struct list_head tasks双向链表来管理所有进程,但涉及将进程之间的父子、兄弟关系记录管理起来,情况就比较复杂了。为了方便在内核代码中快速获取当前进程的父子、兄弟进程的信息,我们在进程的描述符struct task_struct数据结构中记录当前进程的父进程real_parent、parent,记录当前进程的子进程的是双向链表struct list_head children;记录当前进程的兄弟进程的双向链表struct list_head sibling。这样一来就能得到进程之间的父子、兄弟关系,如下图所示:
2.3 保存进程上下文中CPU相关的一些状态信息的数据结构
在Linux内核中定义了一个struct thread_struct,用来保存进程上下文CPU相关的一些状态信息,struct thread_struct在进程描述符中定义的结构体变量thread如下:
/* CPU-specific state of this task */
struct thread_struct thread;
struct thread_struct数据结构的完整代码见/linux-3.18.6/arch/x86/include/asm/processor.h#468,其中最关键的是sp和ip,在x86-32位系统中,sp用来保存进程上下文中的ESP寄存器状态,ip用来保存进程上下文中的EIP寄存器状态,在这个数据结构中还有其他和CPU相关的状态。struct thread_struct数据结构主要保存进程上下文中CPU相关的状态,在进程切换时起着很重要的作用。
另外,进程描述符中还有和文件系统相关的数据结构、打开的文件描述符,有和信号处理相关以及和pipe管道相关的等。
2.4 进程的创建过程分析
在第3章里分析过start_kernel,进程创建过程为:
这里的kernel_thread创建进程的过程和shell命令行下启动一个进程时创建进程的过程在本质上是一样的,都需要通过复制父进程来创建一个子进程。
2.4.1 用户态创建进程的方法
用如下一小段代码的程序来看怎样在用户态创建一个子进程。
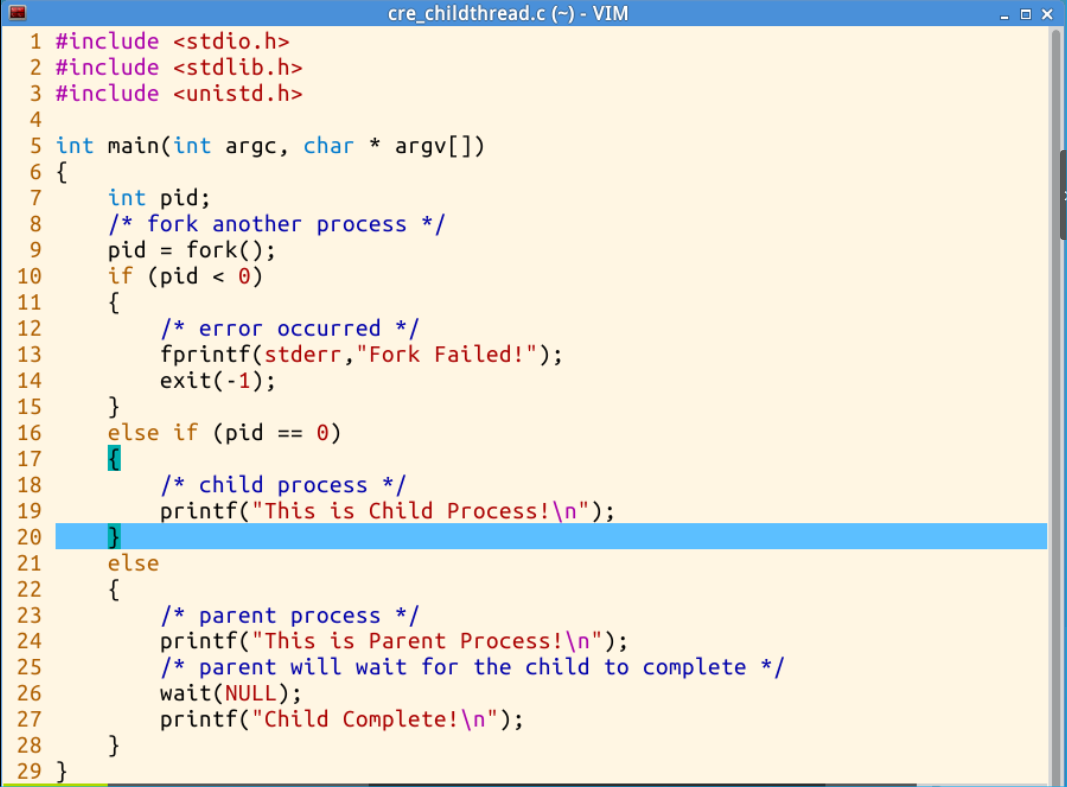
执行结果如下图所示:
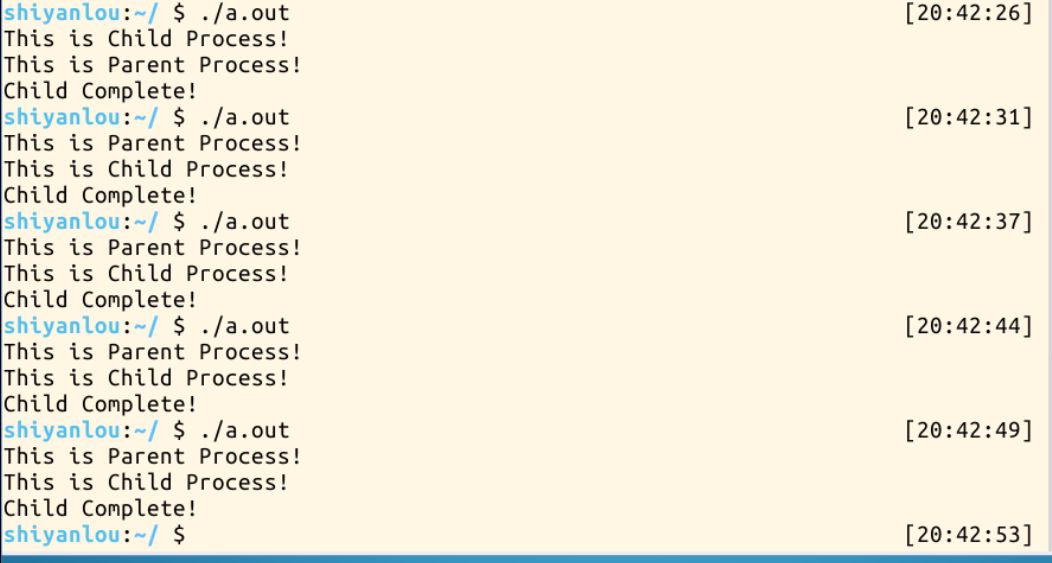
这个结果我们会很疑惑,fork在正常执行后,if条件判断中除了if(pid<0)异常处理没被执行,else if(pid == 0)和esle两段代码都被执行了。实际上fork系统调用把当前进程又复制了一个子进程,也就是一个进程变成了两个进程,两个进程执行相同的代码,只是fork系统调用在父进程和子进程的返回值不同。之所以会在Shell终端得到这样看似混乱的结果,其实是因为if语句在两个进程中各执行了一次,由于判断条件不同,输出的信息也就不同。然后我们还看到父子进程的执行顺序并不是确定的,这是因为父子进程的执行顺序和调度算法密切相关。
通过这一段fork代码程序,我们可以在用户态创建一个子进程,一个进程就是一条系统调用fork。
2.4.2 fork系统调用概述
fork是一个系统调用,但这里的问题是:fork系统调用创建了一个子进程,子进程复制了父进程中所有的进程信息,包括内核堆栈、进程描述符等,子进程作为一个独立的进程也会被调度,当子进程获得CPU开始运行时,它是从哪里开始运行的呢?
如下代码是创建进程相关的几个系统调用内核处理函数,具体代码如下图所示:


通过上面的代码可以看出fork、vfork和clone这三个系统调用和kernel_thread内核函数都可以创建一个新进程,而且都是通过do_fork函数来创建进程的,只不过传递的参数不同。
2.4.3 进程创建的主要过程
前面我们了解到创建一个进程是复制当前进程的信息,就是fork一个进程,这样就创建了一个新进程。但是父进程和子进程的有些信息是不能一样的,比如pid的值和内核堆栈等。建立一个进程的框架为:1)复制一个PCB---task_struct:err =arch_dup_task_struct(tsk,orig);2)要给新进程分配一个新的内核堆栈:ti = alloc_thread_info_node(tsk,node); tsk->stack = ti; setup_thread_stack(st); 3)要修改复制过来的进程数据,比如pid、进程链表等等,见copy_process内部。
我们已经知道fork、vfork和clone这3个系统调用和kernel_thread内核函数都是通过do_fork函数来创建进程,接下来直接从do_fork来跟踪分析代码,具体代码见/linux-3.18.6/kernel/fork.c#1617,如下所示:
/*
1618 * Ok, this is the main fork-routine.
1619 *
1620 * It copies the process, and if successful kick-starts
1621 * it and waits for it to finish using the VM if required.
1622 */
long do_ fork (unsigned long clone_ flags,
unsigned long stack_ start,
unsigned long stack_ size,
int _user *parent _tidptr,
int _user *child_tidptr)
{
struct task_ struct *p; //创建进程描述符指针
int trace = ;
long nr; //子进程pid /*
1634 * Determine whether and which event to report to ptracer. When
1635 * called from kernel thread or CLONE_UNTRACRD is expllcitly
1636 * requested, no event is reported; otherwise,report if the event
1637 * for the type of forking is enabled.
1638 */
if (!(clone_flags & CLONE _UNTRACED)) { //如果 clone_flags 包含 CLONE_VFORK 标志,就将完成量 vfork赋值给进程描述符中的vfork_clone字段,此处只是对完成量进行初始化
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_ EVENT_FORK; if (likely(!ptrace_event_enabled(current, trace)))
trace = ;
} p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace); //创建子进程的描述符和执行时所需的其他数据结构
/*
1654 * Do this prior waking up the new thread - the thread pointer
1655 * might get invalid after that point, if the thread exits quickly.
1656 */
if (!IS_ERR(p)) { //如果 copy_process 执行成功
struct completion vfork; //定义完成量(一个执行单元等待另一个执行单元完成某事)
struct pid *pid; trace_sched_process_fork(current, p) ; pid = get_task_pid(p, PIDTYPE_PID); //获得task结构体中的pid
nr = pid_vnr(pid) ; //根据pid结构体中获得进程pid if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr); if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_ task_struct(p);
} wake_up_new_task(p); //将子进程添加到调度器的队列,使之有机会获得CPU /* forking complete and child started to run, tell ptracer */
if (unlikely (trace) )
ptrace_event_pid(trace, pid) ; if (clone_flags & CLONE_VFORK) { //如果clone_flags 包含 CLONE_VFORK标志,就将父进程插入等待队列直到子进程调用exec函数或退出,此处是具体的阻塞
if (!wait_for_vfork_done(p, &vfork) )
ptrace_event_pid (PTRACE_EVENT_VFORK_DONE, pid) ;
} put_ pid(pid) ;
} else {
nr = PTR_ERR(p) ; //错误处理
}
return nr; //返回子进程pid(父进程的fork函数返回的值为子进程pid的原因)
}
首先来了解do_fork函数的参数。
clone_flags:子进程创建相关标志,通过此标志可以对父进程的资源进行有选择的复制。
stack_start:子进程用户态堆栈的指针。
regs:指向pt_regs结构体的指针。当系统发生系统调用时,int指令和SAVE_ALL保存现场等会将CPU寄存器中的值按顺序压入内核栈。为了便于访问操作,这部分数据被定义为pt_regs结构体。
stack_size:用户态栈的大小,通常是不必要的,总被设置为0。
parent_tidptr和child_tidptr:父进程、子进程用户态下的pid地址。
do_fork()主要完成了调用copy_process()复制父进程信息、获得pid、调用wake_up_new_task将子进程加入调度器队列等待获得分配CPU资源运行、通过clone_flags标志做一些辅助工作。
其中copy_process()是创建一个进程内容的主要代码,copy_process 函数主要完成了调用 dup_task_struct 复制当前进程(父进程)描述符task_struct、信息检查、初始化、把进程状态设置为TASK_RUNNING(此时子进程置为就绪态)、采用写时复制技术逐一复制其他进程资源、调用copy_thhread初始化子进程内核栈、设置子进程pid等。如下的copy_process()函数代码做了删减并添加了一些中文注释,完整代码见/linux3.18.6/kernel/fork.c#1174
static struct task_struct *copy_process (unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int _user *child_tidptr ,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
...
retval = security_task_create(clone_flags);//安全性检查
...
p = dup_task_struct(current); //复制PCB, 为子进程创建内核栈。进程描述符
ftrace_graph_init_task(p);
...
retval = -EAGAIN;
//检查该用户的进程数是否超过限制
if (atomic_read(&p->real_cred->user->processes) >= task_rlimit(p,RLIMIT_NPROC)) {
//检查该用户是否具有相关权限,不一定是root
if (p->real_cred->user != INIT_USER && !capable (CAP_SYS_RESOURCE) && !capable (CAP_SYS_ADMIN))
goto bad_fork_ free;
...
//检查进程数量是否超过max_threads, 后者取决于内存的大小
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
...
spin_lock_init(&p->a1loc-lock); //初始化自旋锁
init_ sigpending(&p->pending); //初始化挂起信号
posix_cpu_timers_init(p); //初始化CPU定时器
...
retval = sched_fork{clone_flags, p); //初始化新进程调度程序数据结构,把新进程的状态设置为TASK_RUNNING,并禁止内核抢占
...
//复制所有的进程信息
shm_init_task(p);
retval = copy_semundo(clone_flags, p);
...
retval = copy_files(clone_flags, p);
...
retval = copy_fs(clone_flage, p);
...
retval = copy_sighand(clone_flags, p);
...
retval = cooy_signal(clone_flags, p);
...
retval =copy_mm(clone_flags, P);
...
retval copy_namespaces(clone_flags, P);
...
retval = copy_io(clone_flags, p);
...
retval = copy_thread(clone_flags, stack_start, stack_size, p); // 初始化子进程内核栈
...
//若传进来的pid指针和全局结构体变量init_struct_pid的地址不相同,就要为子进程分配新的pid
if (pid != &init_struct_pid) (
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (!pid)
goto bad_fork_cleanup_io;
} ...
p->pid= pid_nr(pid); //根据pid结构体中获得进程pid
//若clone_flags 包含CLONE_TREAD标志,说明子进程和父进程在同一个线程组
if (clone_flags & CLONE_THREAD) (
p->exit_signal = -;
p->group_leader = current->group_leader; //将线程组的leader设为子进程的组leader
p->tgid = current->tgid; // 子进程继承父进程的tgid
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flage & CSIGNAL):
p->gcoup_leader = p; //子进程的组leader就是它言已 P->tgid= p->pid; //組号tgid是它白己的pid
} ... if (likely(p->pid)) {
ptrace_init_task(p,(clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid);
if (thread_group_leader(p)) {
...
//将子进程加入它所在组的散列链表中
attach_pid(p,PIDTYPE_PGID);
attach_pid(p, PIDTYPE_SID) ;
_this_cpu_inc(process_counts) ;
} else {
...
}
attach_pid(p, PIDTYPE_PID);
nr_threads++; //增加系统中的进程数目
}
...
return p; //返回被创建的子进程描述符指针P
...
}
在copy_process函数中最关键的就是dup_task_struct复制当前进程(父进程)描述符task_struct和copy_thread初始化子进程内核栈。
2.4.4 复制当前进程(父进程)——dup_task_struct函数
如下代码为经过删减并添加一些中文注释后的dup_task_struct函数,完整代码见/linux-3.18.6/kernel/fork.c#305
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
int node = tak_fork_get_node(orig);
int err;
tsk = alloc_task_struct_node(node);
...
ti = alloc_thread_info_node(tsk, node); //为子进程创建进程描述符分配存储空间,另一部分就是内核堆栈
...
err = arch_dup_task_struct(tsk, orig); //复制父进程的task_struct信息
tsk->stack = ti; //将栈底的值赋给新结点的struct //对子进程的thread_info结构进行初始化(复制父进程的thread_info 结构,然后将 task 指针指向子进程的进程描述符)
setup_thread_stack(tsk, orig);
...
return tsk;
...
} //返回新创建的进程描述符指针
这里解释一下thread_info结构,它被称为小型的进程描述符,内存区域大小是8KB,占据连续的两个页框。struct thread_info是记录部分进程信息的结构体,其中包括了进程上下文信息 ,这个结构体保存了进程描述符中中频繁访问和需要快速访问的字段,内核依赖于该数据结构来获得当前进程的描述符(为了获取当前CPU上运行进程的task_struct结构,内核提供了current宏。内核还需要存储每个进程的PCB信息,linux内核是支持不同体系的的,但是不同的体系结构可能进程需要存储的信息不尽相同,这就需要我们实现一种通用的方式,我们将体系结构相关的部分和无关的部门进行分离,用一种通用的方式来描述进程, 这就是struct task_struct,而thread_info就保存了特定体系结构的汇编代码段需要访问的那部分进程的数据,我们在thread_info中嵌入指向task_struct的指针, 则我们可以很方便的通过thread_info来查找task_struct。
内核栈、thread_info结构和进程描述符逻辑结构如下图所示:
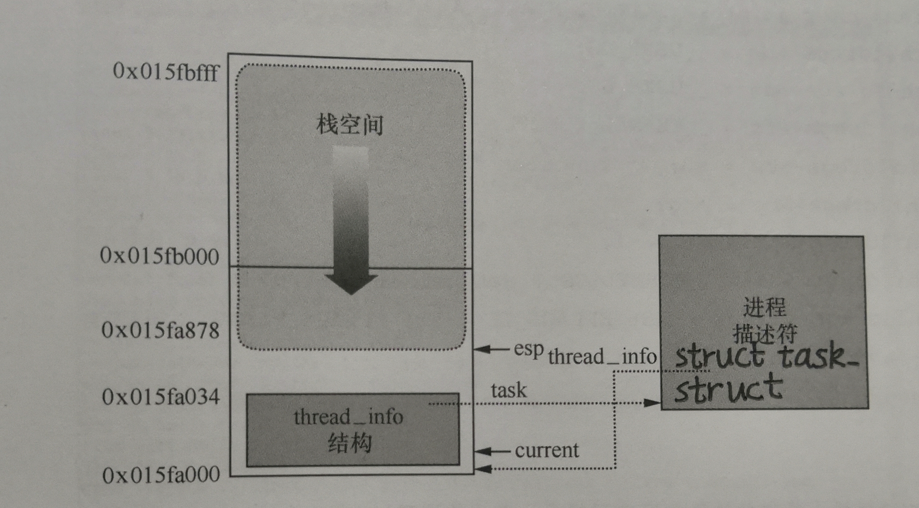
从上图中可以看出内核栈由高地址到低地址增长,thread_info 结构由低地址到高地址增长。
内核通过屏蔽ESP寄存器的低13位有效位获得thread_info 结构的基地址。在较新的内核代码中,task_struct 结构中没有直接指向thread_info 结构的指针,而是用一个void 指针类型的成员表示,然后通过类型转换来访问thread_info 结构。内核栈和thread_info 结构被定义在一个联合体当中,既分配了thread_info 结构,又分配了内核栈。
2.4.5 内核堆栈关键信息的初始化
前面的dup_task_struct 函数中为子进程分配好了内核栈,copy_thread 才能真正完成内核栈关键信息的初始化。如下为经过删减并添加一些中文注释后的copy_thread 函数代码:
int copy_thread(unsigned long clone_flags, unsigned long sp, unsigned long arg, struct task_struct *p)
{ struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err; p->thread.sp = (unsigned long) childregs;
p->thread.sp0 = (unsigned long) (childregs+);
memset(p->thread.pttrace_bps, , sizeof(p->thread.ptrace_bps)); if (unlikely(p->flag & PF_KTHREAD)) {
/* kernel thread */
memset (childregs, , sizeof(struct pt_regs));
//如果创建的是内核线程,则从ret_from_kernel_thread开始执行
p->thread.ip = (unsigned long) ret_from_kernel_thread;
task_user_gs(p) = _KERNEL_STACK_CANARY;
childregs->ds = _USER_DS;
childregs->es = _USER_DS;
childregs->fs = _KERNEL_PERCPU;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -;
childregs->cs = _KERNEL_CS | get_kernel_rpl ();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return ;
} //复制内核堆栈(复制父进程的寄存器信息,即系统调用int指令和SAVE_ALL压栈的那一部分内容)
*childregs = *current_pt_regs (); chilldregs->ax = ; //将子进程的eax置0,所以fork的子进程返回值为0
...
//ip指向 ret_from_fork,子进程从此处开始执行
p->thread.ip = (unsigned long) ret_from_fork;
task_user_gs(p) = get_user_gs(current_pt_regs());
...
return err;
2.5.5 通过实验跟踪分析进程创建的过程
删掉menu,然后克隆一份新的,并把test.c给覆盖掉。因为我们之前用过test.c,所以直接用可能会有影响。接着在menu下面执行 make rootfs,编译运行出来就可以看到列表中增加了一个fork。执行 fork 即可看到父进程和子进程都输出信息,如下图所示:
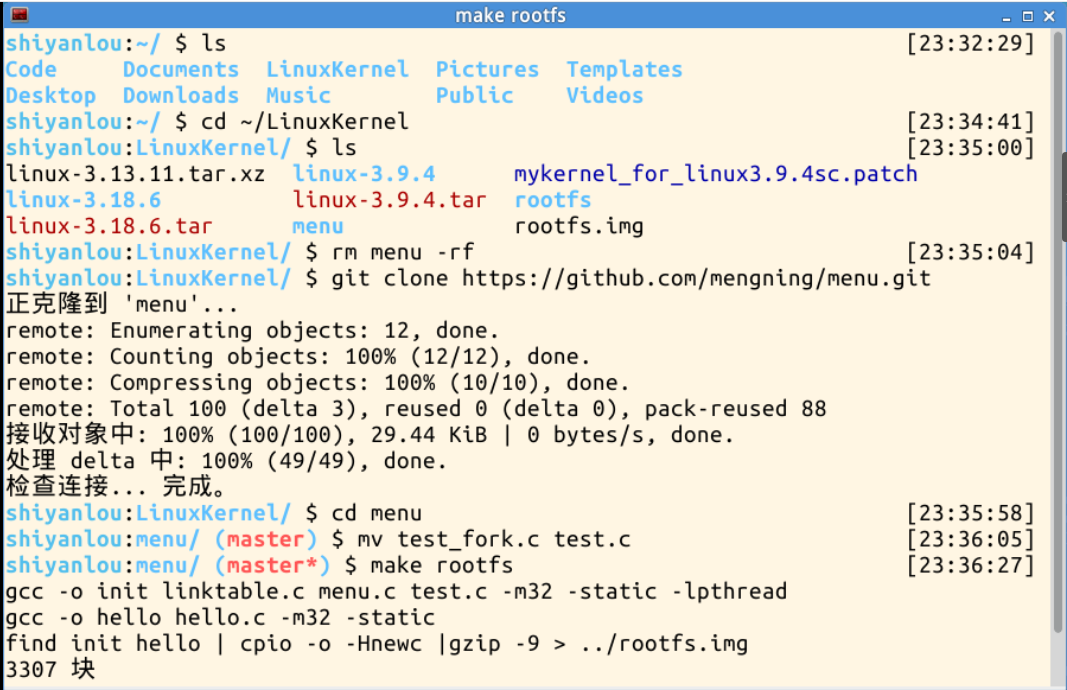
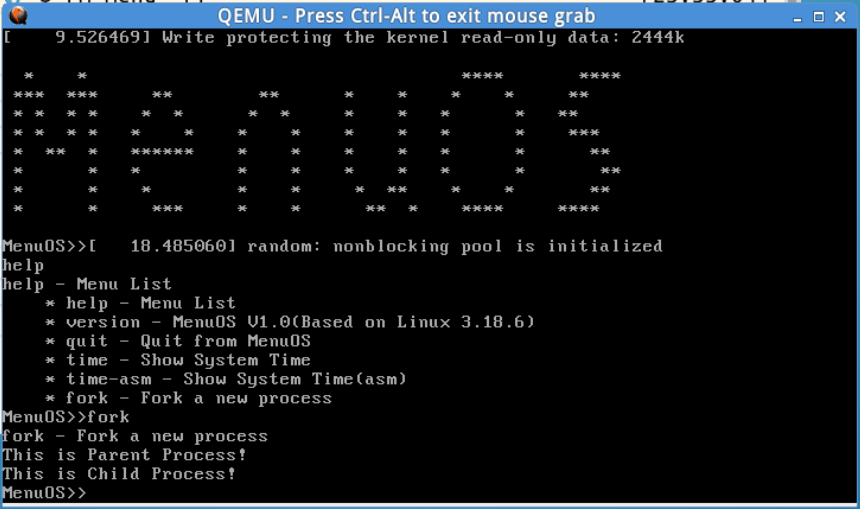
接着设置断点,在sys_clone、do_fork、dup_task_struct、copy_process、copy_thread、ret_from_fork等处设置断点。

设定完断点后执行 fork,发现只输出了一个命令描述,后面的并没有执行,而是停在了sys_clone这里。
继续执行,会停在do_fork的位置

从do_fork继续执行,停在了copy_process这里

继续执行,停在了dup_task_struct函数

接着就进入了dup_task_struct函数内部,如下图所示:
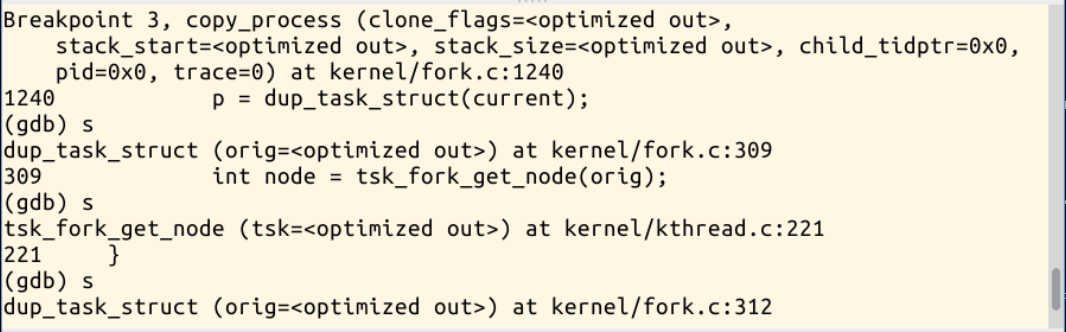
这个函数内部将当前内核堆栈压得那一部分寄存器复制到子进程中,以及赋值子进程的起点。
继续执行,我们发现跟踪不到断点ret_from_fork的位置。
3 总结
在本章内容中,我们通过学习进程的描述和进程的创建,重点在进程的创建中,层层递进,了解了进程创建的这一整个过程,并分析了这一过程中的相关关键性代码,然后自己动手实验验证了这一过程,理论配合动手实践,使我更更加深刻地了解了进程创建的过程。总的来说,进程的创建大致是复制进程描述符、一一复制其他进程资源(采用写时复制)、分配子进程的内核堆栈并对内核堆栈关键信息进行初始化。
2019-2020-7 20199317《Linux内核原理与分析》第七周作业的更多相关文章
- 2019-2020-1 20199329《Linux内核原理与分析》第九周作业
<Linux内核原理与分析>第九周作业 一.本周内容概述: 阐释linux操作系统的整体构架 理解linux系统的一般执行过程和进程调度的时机 理解linux系统的中断和进程上下文切换 二 ...
- 2019-2020-1 20199329《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 一.上周问题总结: 未能及时整理笔记 Linux还需要多用 markdown格式不熟练 发布博客时间超过规定期限 二.本周学习内容: <庖丁解 ...
- 20169212《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 这一周学习了MOOCLinux内核分析的第一讲,计算机是如何工作的?由于本科对相关知识的不熟悉,所以感觉有的知识理解起来了有一定的难度,不过多查查资 ...
- 20169210《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 本周作业分为两部分:第一部分为观看学习视频并完成实验楼实验一:第二部分为看<Linux内核设计与实现>1.2.18章并安装配置内核. 第 ...
- 2018-2019-1 20189221 《Linux内核原理与分析》第九周作业
2018-2019-1 20189221 <Linux内核原理与分析>第九周作业 实验八 理理解进程调度时机跟踪分析进程调度与进程切换的过程 进程调度 进度调度时机: 1.中断处理过程(包 ...
- 2017-2018-1 20179215《Linux内核原理与分析》第二周作业
20179215<Linux内核原理与分析>第二周作业 这一周主要了解了计算机是如何工作的,包括现在存储程序计算机的工作模型.X86汇编指令包括几种内存地址的寻址方式和push.pop.c ...
- 2019-2020-1 20209313《Linux内核原理与分析》第二周作业
2019-2020-1 20209313<Linux内核原理与分析>第二周作业 零.总结 阐明自己对"计算机是如何工作的"理解. 一.myod 步骤 复习c文件处理内容 ...
- 2018-2019-1 20189221《Linux内核原理与分析》第一周作业
Linux内核原理与分析 - 第一周作业 实验1 Linux系统简介 Linux历史 1991 年 10 月,Linus Torvalds想在自己的电脑上运行UNIX,可是 UNIX 的商业版本非常昂 ...
- 《Linux内核原理与分析》第一周作业 20189210
实验一 Linux系统简介 这一节主要学习了Linux的历史,Linux有关的重要人物以及学习Linux的方法,Linux和Windows的区别.其中学到了LInux中的应用程序大都为开源自由的软件, ...
- 2018-2019-1 20189221《Linux内核原理与分析》第二周作业
读书报告 <庖丁解牛Linux内核分析> 第 1 章 计算工作原理 1.1 存储程序计算机工作模型 1.2 x86-32汇编基础 1.3汇编一个简单的C语言程序并分析其汇编指令执行过程 因 ...
随机推荐
- Mybatis:配置解析
配置解析 mybatis-config.xml(Mybatis核心配置文件)深深影响了Mybatis行为的设置和属性信息. 能配置的的内容 当然,并不是所有都是我们经常使用到的,下面选择经常使用的配 ...
- CSPS模拟 72
状态..找不回来了.. T2 简单的期望 考试的时候忘考虑一个事,就是连续多位进位的情况 考试的时候打出$n^2$复杂度dp还没引起怀疑真是不应该. T3 简单的操作 最后一刻才想到图不联通,已经想不 ...
- 【实用工具】这些你不得不知道的chrome插件,让你事半功倍
平时chrome插件用多了,发现在工作中有很多插件特别好用,让你事半功倍.于是我抽时间整理了一些非常好用的chrome插件分享给大家,其中有些插件是我已经离不开,每天都在用的.希望这篇文章能帮助你找到 ...
- DAY 4 基础算法
基础算法 本来今天是要讲枚举暴力还有什么的,没想到老师就说句那种题目就猪国杀,还说只是难打,不是难.... STL(一)set 感觉今天讲了好多,set,单调栈,单调队列,单调栈和单调队列保证了序列的 ...
- PyCharm安装及使用教程
1 PyCharm下载 PyCharm的下载安装非常简单,可以直接到Jetbrains公司官网下载,具体步骤如下: (1)打开Pycharm官网http://www.jetbrains.com,选择 ...
- php Yaf_Loader::import引入文件报错的解决方法
php Yaf_Loader::import引入文件报错的解决方法 改下配置文件就行<pre>yaf.use_spl_autoload=1</pre> 也可以PHP动态修改 毕 ...
- phpexcel导出数字带E的解决方法
phpexcel导出数字带E的解决方法 excel之所以带E 是因为按照数字格式来显示了(数字过长的时候) 数字左边或者右边加空格就变成字符串了 那么excel就会按照字符串格式来显示了 就不会带E了
- php递归删除文件夹
php递归删除文件夹 <pre> public function deldir($path) { //如果是目录则继续 if (is_dir($path)) { //扫描一个文件夹内的所有 ...
- go中的数据结构字典-map
1. map的使用 golang中的map是一种数据类型,将键与值绑定到一起,底层是用哈希表实现的,可以快速的通过键找到对应的值. 类型表示:map[keyType][valueType] key一定 ...
- PHPExcel数据导入(含图片)
PHPExcel是一个PHP类库,用来帮助我们简单.高效实现从Excel读取Excel的数据和导出数据到Excel. 首先下载压缩包: https://codeload.github.com/PHPO ...