利用tensorboard可视化checkpoint模型文件参数分布
写在前面:
上周微调一个文本检测模型seglink,将特征提取层进行冻结,只训练分类回归层,然而查看tensorboard发现里面有histogram显示模型各个参数分布,看了目前这个训练模型参数分布压根就看不懂,很想知道我的预训练模型的参数分布是怎么个情况,训练了一天了,模型的参数分布较预训练的模型参数有啥变化没有,怎么办呢?
利用tf.summary将模型参数分布在tensorboard可视化:
导入需要的库 设置模型文件夹路径
import TensorFlow as tf
from tensorflow.python import pywrap_tensorflow
model_dir="___"
定义可视化方法:
1、获取ckpt路径,这里的路径是checkpoint文件中的路径(ckpt文件夹中包括:checkpoint文件,index,meta,data四个文件)
code:
ckpt=tf.train.get_checkpoint_state(model_dir)
ckpt_path=ckpt.model_checkpoint_path
2、读取checkpoint 文件中模型的变量名和变量值
这里是使用get_variable_to_shape_map()获取了一个[key:name of variable value:the shape of variable]的list
code:
reader=pywrap_tensorflow.NewCheckpointReader(ckpt_path)
param_dict=reader.get_variable_to_shape_map()
3、开一个session,
code:
with tf.Session() as sess:
validate_writer=tf.summary.FileWriter('./run')
for key in param_dict:
if(key.startwith('vgg')):
vgg_summary=tf.summary.histogram(key,reader.get_tensor(key))
merge_summary=tf.summary.merge([vgg_summary])#这里可以添加其他需要merge的summary项,如果只有一个summary也可以不用merge,
test_summary=sess.run(merge_summary)
validate_writer.add_summary(test_summary)
tf.summary.FileWriter(event_dir_path)#event_dir_path为事件日志文件夹,运行程序之后会在该指定的文件夹中生产events文件。运行TensorFlow计算后,会将各类数据汇总记录进该日志文件,tensorboard会读取这些数据进行解析并生成数据可视化的web页面。
key.startwith('vgg')在param_dict字典中提取以vgg开头的key,并获取相关tensor以histogram的形式汇总
merge_summary=tf.summary.merge([.....])合并指定数据汇总
test_summary=sess.run(merge_summary)执行一步run,得到merge_summary,并将该summary
validate_writer.add_summary(test_summary)#将当前一步run得到的summary加入之前设置的validate_writer
附上summary示意图帮助理解,图片引用自CSDN网址:https://blog.csdn.net/hongxue8888/article/details/78610305
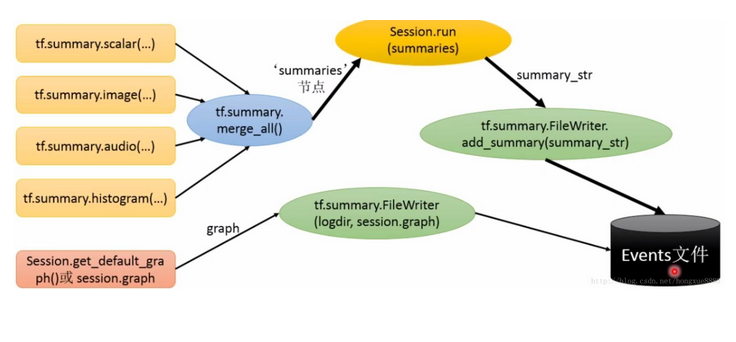
最后还要关闭writer
validate_writer.close()
运行代码之后,执行如下指令:
tensorboard --logdir="./run"#就是之前设置的events日志文件夹的路径
然后根据执行结果上的网址,打开浏览器即可观察模型参数分部情况:
附一张参数分布图,具体怎么研究比较这个直方图,接下去再研究吧~
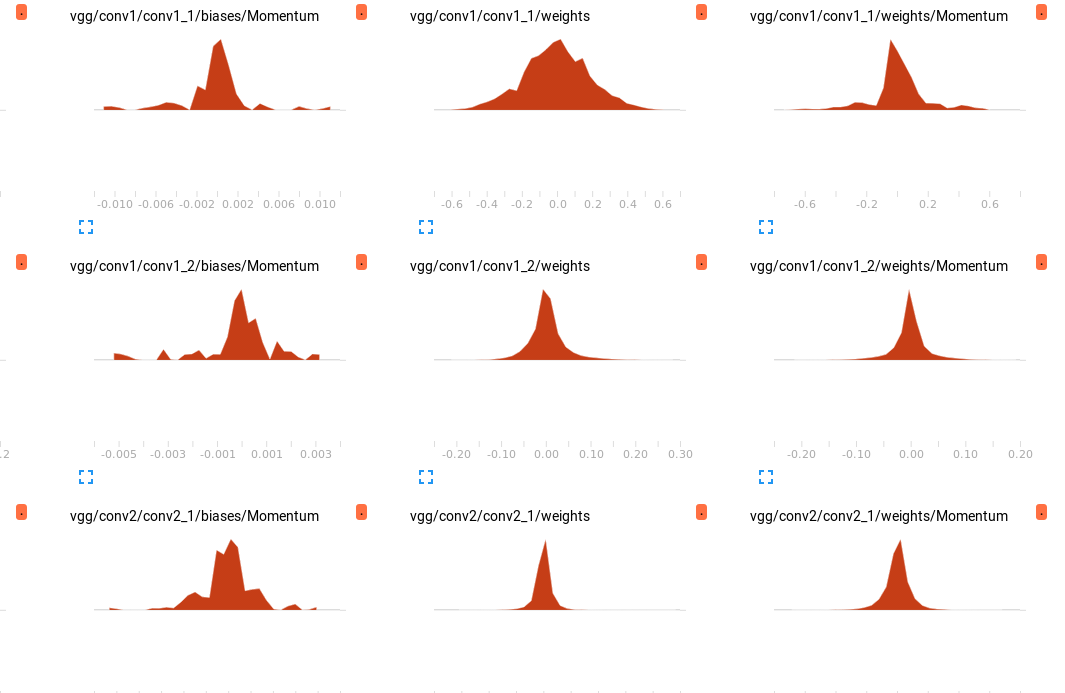
小白一枚,进步很慢,希望各路大神道友指教和批评~~~~
利用tensorboard可视化checkpoint模型文件参数分布的更多相关文章
- 【猫狗数据集】利用tensorboard可视化训练和测试过程
数据集下载地址: 链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw提取码:2xq4 创建数据集:https://www.cnblogs.com/xi ...
- 利用Tensorboard可视化模型、数据和训练过程
在60分钟闪电战中,我们像你展示了如何加载数据,通过为我们定义的nn.Module的子类的model提供数据,在训练集上训练模型,在测试集上测试模型.为了了解发生了什么,我们在模型训练时打印了一些统计 ...
- 利用libsvm-mat建立分类模型model参数解密[zz from faruto]
本帖子主要就是讲解利用libsvm-mat工具箱建立分类(回归模型)后,得到的模型model里面参数的意义都是神马?以及如果通过model得到相应模型的表达式,这里主要以分类问题为例子. 测试数据使用 ...
- 模型文件(checkpoint)对模型参数的储存与恢复
1. 模型参数的保存: import tensorflow as tfw=tf.Variable(0.0,name='graph_w')ww=tf.Variable(tf.random_normal ...
- 学习TensorFlow,TensorBoard可视化网络结构和参数
在学习深度网络框架的过程中,我们发现一个问题,就是如何输出各层网络参数,用于更好地理解,调试和优化网络?针对这个问题,TensorFlow开发了一个特别有用的可视化工具包:TensorBoard,既可 ...
- tensorflow打印pb、ckpt模型的参数以及在tensorboard里显示图结构
打印pb模型参数及可视化结构import tensorflow as tf from tensorflow.python.framework import graph_util tf.reset_de ...
- 使用 TensorBoard 可视化模型、数据和训练
使用 TensorBoard 可视化模型.数据和训练 在 60 Minutes Blitz 中,我们展示了如何加载数据,并把数据送到我们继承 nn.Module 类的模型,在训练数据上训练模型,并在测 ...
- TensorFlow2.0(9):TensorBoard可视化
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- Tensorflow学习笔记3:TensorBoard可视化学习
TensorBoard简介 Tensorflow发布包中提供了TensorBoard,用于展示Tensorflow任务在计算过程中的Graph.定量指标图以及附加数据.大致的效果如下所示, Tenso ...
随机推荐
- 9.秋招复习简单整理之Spring面试AOP和IOC的理解
1.Spring的AOP理解: OOP面向对象,允许开发者定义纵向的关系,但不适用于定义横向的关系,导致了大量代码的重复,而不利于各个模块的重用. AOP,一般称为面向切面,作为面向对象的一种补充,用 ...
- 第三章.定制专属的kali
1.更新升级 • apt-get update • apt-get upgrade • apt-get dis-upgrade 2.根据个人喜好需求安装软件包 • 库 • Apt-get命令 • ...
- 第二章 Session会话管理
采用网址重写的缺点: 在有些Web浏览器中,URL限制为2000个字符. 仅当有链接要插入值时,值才能转换成后面的资源.此外,要把值添加到静态页面的链接中,可不是一件容易的事情. 网址重写必须在服务器 ...
- Lake Counting-C++
Description Due to recent rains, water has pooled in various places in Farmer John's field, which is ...
- Jira 使用手册
Date Revision version Description author 2018-06-14 V1.0.0 Isaac Zhang 2018-06-22 V1.0.1 1,添加git提交操作 ...
- windbg 配置符号路径
(转)WINDBG的符号下载与符号路径问题 安装与配置 windbg 的 symbol (符号) 本篇是新手自己写的一点心得.建议新手看看.同时希望前辈多多指教. 写这篇的动机:在网上找了一上午的 w ...
- C语言入门1-计算机工作原理
一. 计算机与人工智能.计算机系统: 计算机工作原理:计算机的基本原理是存储程序和程序控制,预先要把指挥计算机如何进行操作的指令序列(称为程序)和原始数据通过输入设备输送到计算机内存贮器中.每一条指令 ...
- python中的字典,if_while使用
1.定义两个字典用于表述你的个人信息 第一个字典存放你的这些信息:姓名.性别.年龄.身高第二个字典存放你的其他信息:性格.爱好.座右铭将两个字典合并为第三个字典之后,打印出来 觉得自己很年轻的,可以去 ...
- 安科 OJ 1190 连接电脑 (并查集)
时间限制:1 s 空间限制:128 M 传送门:https://oj.ahstu.cc/JudgeOnline/problem.php?id=1190 题目描述 机房里有若干台电脑,其中有一些电脑已经 ...
- Ambassador,云原生应用的“门神”
目前,行业内基于云原生思想的开源项目,重点在于管理.控制微服务以及微服务架构下服务之间的通信问题.它们有效的解决了“服务异构化”.“动态化”.“多协议”场景所带来的east/west流量的管控问题,而 ...