利用ShardingSphere-JDBC实现分库分表
利用ShardingSphere-JDBC实现分库分表
1. ShardingSphere概述
1.1 概述
业务发展到一定程度,分库分表是一种必然的要求,分库可以实现资源隔离,分表则可以降低单表数据量,提高访问效率。
分库分表的技术方案,很久以来都有两种理念:
- 集中式的Proxy,实现MySQL客户端协议,使用户无感知
- 分布式的Proxy,在代码层面进行增强,实现一个路由程序
这两种方式是各有利弊的,集中式Proxy的好处是业务没有感知,一切交给DBA把控,分布式的Proxy其支持的语言有限,比如本文要提及的ShardingShpere-JDBC就只支持Java。
我们需要了解一点,集中式的Proxy其实现非常复杂,这要从MySQL处理SQL语句的原理说起,因为不是本文要论述的重点,因此只是简单的提及几点:
- SQL语句要被Parser解析成抽象语法树
- SQL要被优化器解析出执行计划
- SQL语句完成解析后,发给存储引擎
因此大部分的中间件都选择了自己实现SQL的解析器和查询优化器,下面是著名的中间件dble的实现示意图:
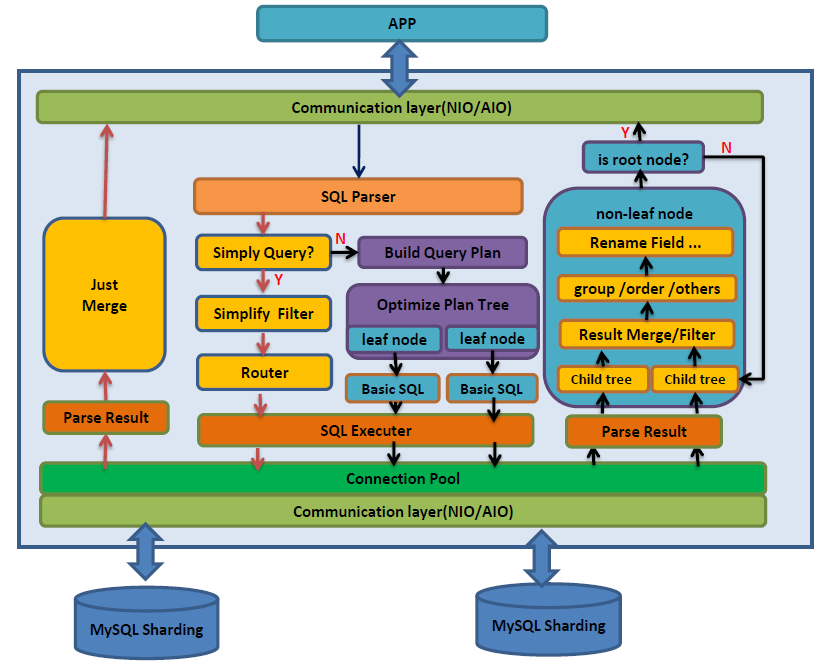
只要有解析的过程,其性能损耗就是比较可观的,我们也可以认为这是一种重量级的解决方案。
与之形成对比的是ShardingSphere-JDBC,其原理示意图如下:
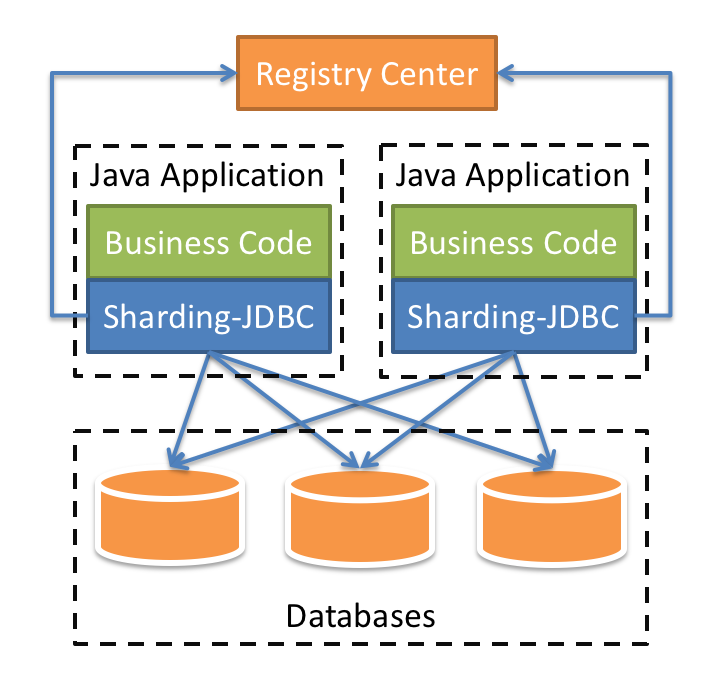
每一个服务都持有一个Sharing-JDBC,这个JDBC以Jar包的形式提供,基本上可以认为是一个增强版的jdbc驱动,需要一些分库分表的配置,业务开发人员不需要去对代码进行任何的修改。可以很轻松的移植到SpringBoot,ORM等框架上。
但是这个中结构也不是完美的,每一个服务持有一个proxy意味着会在MySQL服务端新建大量的连接,维持连接会增加MySQL服务器的负载,虽然这种负载提升一般无法察觉。
1.2 概念
逻辑表
**
即水平拆分的表的总称。比如订单业务会被拆分成t_order0,t_order1两张表,但是他们同属于一个逻辑表:t_order
绑定表
分片规则一直的主表和子表。比如还是上面的t_order表,其分片键是order_id,其子表t_order_item的分片键也是order_id。在规则配置时将两个表配置成绑定关系,就不会在查询时出现笛卡尔积。
在关联查询时,如果没有绑定关系,则t_order和t_order_item的关联会出现这样一种场景:
select * from t_order0 inner join t_order_item0 on order_id = order_id where order_id in (0, 1);select * from t_order0 inner join t_order_item1 on order_id = order_id where order_id in (0, 1;select * from t_order1 inner join t_order_item0 on order_id = order_id where order_id in (0, 1;select * from t_order1 inner join t_order_item1 on order_id = order_id where order_id in (0, 1;
如果配置了绑定关系,则会精确地定位到order_id所在的表,消除笛卡尔积。
广播表
有一些表是没有分片的必要的,比如省份信息表,全国也就30多条数据,这种表在每一个节点上都是一样的,这种表叫做广播表。
2. 利用SpringBoot实现分库分表
要分库分表首先需要有不同的数据源,我们启动两个mysqld进行,监听3306和3307两个端口,以多实例的形式模拟多数据源。
我们的分库是以用户ID为依据的,分表是以表本身的主键为依据的。下面是一张示意表:
-- 注意,这是逻辑表,实际不存在create table t_order(order_id bigint not null auto_increment primary key,user_id bigint not null,name varchar(100));CREATE TABLE `t_order_item` (`order_id` bigint(20) NOT NULL,`item` varchar(100) DEFAULT NULL,`user_id` bigint(20) NOT NULL,PRIMARY KEY (`order_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
我现在有两个数据源,每个数据源上根据order_id分成2两表,也就是说每个实例上都应该有这两张表:
create table t_order0(order_id bigint not null auto_increment primary key,user_id bigint not null,name varchar(100));create table t_order1(order_id bigint not null auto_increment primary key,user_id bigint not null,name varchar(100));-- 这是广播表,新建在其中一个节点上就可以CREATE TABLE `t_config` (`id` int(11) NOT NULL AUTO_INCREMENT,`user_id` bigint(20) DEFAULT NULL,`config` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB;CREATE TABLE `t_order_item0` (`order_id` bigint(20) NOT NULL,`item` varchar(100) DEFAULT NULL,`user_id` bigint(20) NOT NULL,PRIMARY KEY (`order_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE `t_order_item1` (`order_id` bigint(20) NOT NULL,`item` varchar(100) DEFAULT NULL,`user_id` bigint(20) NOT NULL,PRIMARY KEY (`order_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
利用SpringBoot技术可以很快的构建一个RESTful的Web服务,下面是application.properties的内容:
# 这里要注册所有的数据源spring.shardingsphere.datasource.names=ds0,ds1# 这是数据源0的配置spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds0.username=rootspring.shardingsphere.datasource.ds0.password=# 这是数据源1的配置spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3307/test?serverTimezone=GMT%2B8spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds1.username=rootspring.shardingsphere.datasource.ds1.password=# 分库策略# 分库的列是user_idspring.shardingsphere.sharding.default-database-strategy.standard.sharding-column=user_idspring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=com.sinosun.demo.sharding.PreciseShardingAlgorithmImpl# 分表策略spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_idspring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_idspring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKEspring.shardingsphere.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}spring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_idspring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}spring.shardingsphere.sharding.binding-tables=t_order, t_order_item# 广播表, 其主节点是ds0spring.shardingsphere.sharding.broadcast-tables=t_configspring.shardingsphere.sharding.tables.t_config.actual-data-nodes=ds$->{0}.t_configspring.jpa.show-sql=trueserver.address=10.1.20.96server.port=8080
这是buid.gradle内容,只列举ShardingSphere相关的:
dependencies {compile group: 'org.apache.shardingsphere', name: 'sharding-jdbc-spring-boot-starter', version: '4.0.0-RC1'compile group: 'org.apache.shardingsphere', name: 'sharding-jdbc-spring-namespace', version: '4.0.0-RC1'}
下图是工程的代码结构,供参考:
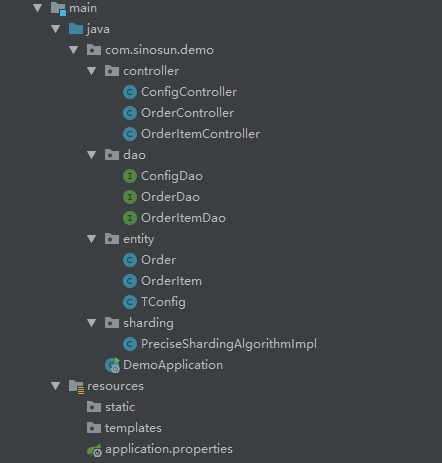
现在开始列举代码:
Order.java:
**
package com.example.demo.entity;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.GenerationType;import javax.persistence.Id;import javax.persistence.Table;import java.util.StringJoiner;@Entity@Table(name = "t_order")public class Order {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private long orderId;@Column(name = "user_id")private long userId;@Column(name = "name")private String name;public long getOrderId() {return orderId;}public void setOrderId(long orderId) {this.orderId = orderId;}public String getName() {return name;}public void setName(String name) {this.name = name;}public long getUserId() {return userId;}public void setUserId(long userId) {this.userId = userId;}@Overridepublic String toString() {return new StringJoiner(", ", Order.class.getSimpleName() + "[", "]").add("orderId=" + orderId).add("userId=" + userId).add("name='" + name + "'").toString();}}
OrderItem.java:
**
package com.example.demo.entity;import com.google.common.base.MoreObjects;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.Id;import javax.persistence.Table;@Entity@Table(name = "t_order_item")public class OrderItem {@Id@Column(name = "order_id")private long orderId;@Column(name = "user_id")private long userId;@Column(name = "item")private String item;public long getOrderId() {return orderId;}public void setOrderId(long orderId) {this.orderId = orderId;}public long getUserId() {return userId;}public void setUserId(long userId) {this.userId = userId;}public String getItem() {return item;}public void setItem(String item) {this.item = item;}@Overridepublic String toString() {return MoreObjects.toStringHelper(this).add("orderId", orderId).add("userId", userId).add("item", item).toString();}}
TConfig.java:
**
package com.example.demo.entity;import com.google.common.base.MoreObjects;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.GenerationType;import javax.persistence.Id;import javax.persistence.Table;@Entity@Table(name = "t_config")public class TConfig {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private int id;@Column(name = "user_id")private long userId;@Column(name = "config")private String config;public int getId() {return id;}public void setId(int id) {this.id = id;}public long getUserId() {return userId;}public void setUserId(long userId) {this.userId = userId;}public String getConfig() {return config;}public void setConfig(String config) {this.config = config;}@Overridepublic String toString() {return MoreObjects.toStringHelper(this).add("id", id).add("userId", userId).add("config", config).toString();}}
OrderDao.java:
**
package com.example.demo.dao;import com.example.demo.entity.Order;import org.springframework.data.jpa.repository.JpaRepository;public interface OrderDao extends JpaRepository<Order, Long> {}
OrderItemDao.java:
**
package com.example.demo.dao;import com.example.demo.entity.OrderItem;import org.springframework.data.jpa.repository.JpaRepository;import org.springframework.data.jpa.repository.Query;import org.springframework.data.repository.query.Param;import java.util.Optional;public interface OrderItemDao extends JpaRepository<OrderItem, Long> {//为了测试绑定表@Query(value = "select n from Order t inner join OrderItem n on t.orderId = n.orderId where n.orderId=:orderId")Optional<OrderItem> getOrderItemByOrderId(@Param("orderId") Long orderId);}
ConfigDao.java:
**
package com.example.demo.dao;import com.sinosun.demo.entity.TConfig;import org.springframework.data.jpa.repository.JpaRepository;public interface ConfigDao extends JpaRepository<TConfig, Integer> {}
OrderController.java:
**
package com.example.demo.controller;import com.example.demo.dao.OrderDao;import com.example.demo.entity.Order;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import java.util.Optional;@RestControllerpublic class OrderController {@Autowiredprivate OrderDao orderDao;@RequestMapping(value = "/order", method = RequestMethod.GET)public Optional<Order> getOrderById(@RequestParam("id") Long id) {return this.orderDao.findById(id);}@RequestMapping(value = "/order/save", method = RequestMethod.POST)public Order saveOrder(@RequestParam("name") String name, @RequestParam("userid") Long userId) {Order order = new Order();order.setName(name);order.setUserId(userId);return this.orderDao.save(order);}}
OrderItemController.java:
**
package com.example.demo.controller;import com.example.demo.dao.OrderItemDao;import com.example.demo.entity.OrderItem;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import java.util.Optional;@RestControllerpublic class OrderItemController {@Autowiredprivate OrderItemDao orderItemDao;@RequestMapping(value = "/orderItem", method = RequestMethod.GET)public Optional<OrderItem> getOrderItemById(@RequestParam(name = "id") Long id) {return this.orderItemDao.findById(id);}@RequestMapping(value = "/orderItem/save", method = RequestMethod.POST)public OrderItem saveOrderItem(@RequestParam("item") String item, @RequestParam("userid") Long userId, @RequestParam("orderid") Long orderId) {OrderItem orderItem = new OrderItem();orderItem.setUserId(userId);orderItem.setItem(item);orderItem.setOrderId(orderId);return this.orderItemDao.save(orderItem);}@RequestMapping(value = "/orderItem/query", method = RequestMethod.GET)public Optional<OrderItem> getOrderItemByOrderId(@RequestParam(name = "orderid") Long orderId) {return this.orderItemDao.getOrderItemByOrderId(orderId);}}
ConfigController.java:
**
package com.example.demo.controller;import com.example.demo.dao.ConfigDao;import com.example.demo.entity.TConfig;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestControllerpublic class ConfigController {@Autowiredprivate ConfigDao configDao;@RequestMapping(value = "/listConfig", method = RequestMethod.GET)public List<TConfig> getConfig() {return this.configDao.findAll();}}
这三段代码写完基本的功能就完备了,但是刚才配置的时候提过,我们的目的是按照user_id进行分库,比如user_id=0则分配这条数据到ds0去,如果为1则将数据分配到ds1去,这就要求我们自己实现分库的算法,ShardingSphere提供了接口,只需要去实现就可以了:
package com.example.demo.sharding;import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;import java.util.Collection;public class PreciseShardingAlgorithmImpl implements PreciseShardingAlgorithm<Long> {@Overridepublic String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {String dbName = "ds";Long val = shardingValue.getValue();dbName += val;for (String each : availableTargetNames) {if (each.equals(dbName)) {return each;}}throw new IllegalArgumentException();}}
这段代码很简单,其中有几个地方只需要讲明白了就可以。
- availableTargetNames:这是datasource的名字列表,在这里应该是ds0和ds1;
- shardingValue:这是分片列的值,我们只要其value部分就可以。
之后用一个循环遍历["ds0", "ds1"]集合,当我们的dbName和其中一个相等时,就能的到正确的数据源。这就简单的实现了根据user_id精确分配数据的目的。
这是实测例子中,shardingValue和availableTargetNames的实际值:
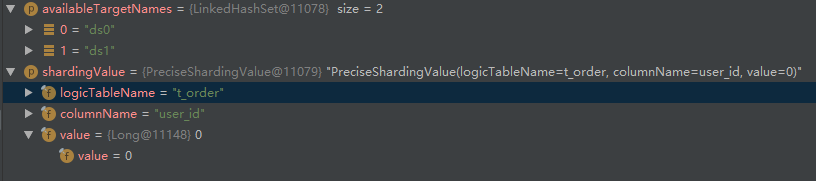
本次测试的请求是:
curl -X POST \'http://10.1.20.96:8080/order/save?name=LiLei&userid=0' \-H 'Postman-Token: d5e15e85-c760-4252-a7d4-ef57b5e95c2e' \-H 'cache-control: no-cache'
下面看看实际效果,这是ds0的数据:
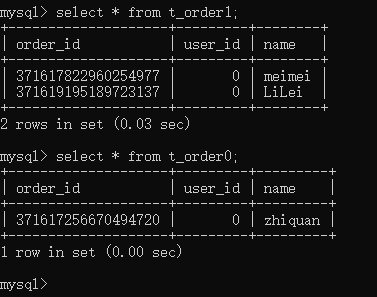
这是ds1的数据:
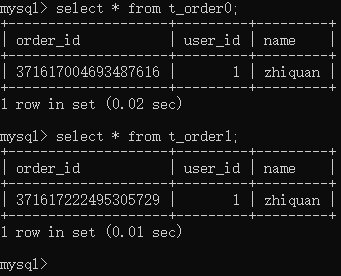
可以看到,所有的数据都根据user_id分布到了不同的库中,所有的数据都根据order_id的奇偶分布到了不同的表中。
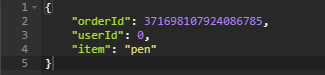
记录下保存t_order请求返回的order_id,组装一条POST请求写t_order_item表:
curl -X POST \'http://10.1.20.96:8080/orderItem/save?item=pen&userid=0&orderid=371698107924086785' \-H 'Accept: */*' \-H 'Cache-Control: no-cache' \-H 'Connection: keep-alive' \-H 'Host: 10.1.20.96:8080' \-H 'Postman-Token: 347b6c4d-0e2c-474f-b53e-6f0994db5871,24b362da-e77e-4b04-94e1-fa20dcb15845' \-H 'User-Agent: PostmanRuntime/7.15.0' \-H 'accept-encoding: gzip, deflate' \-H 'cache-control: no-cache' \-H 'content-length: '
得到结果如下:
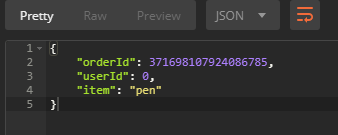
使用这个order_id去进行联合查询:
curl -X GET \'http://10.1.20.96:8080/orderItem/query?orderid=371698107924086785' \-H 'Accept: */*' \-H 'Cache-Control: no-cache' \-H 'Connection: keep-alive' \-H 'Host: 10.1.20.96:8080' \-H 'Postman-Token: d0da0523-d46e-429f-a8db-9f844cd77fe6,b61c6089-253d-4535-b473-158c037850be' \-H 'User-Agent: PostmanRuntime/7.15.0' \-H 'accept-encoding: gzip, deflate' \-H 'cache-control: no-cache'
得到返回如下:
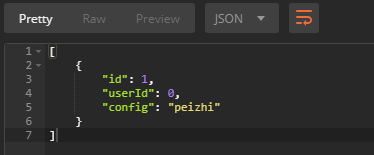
测试广播表,可以用下面的请求:
curl -X GET \http://10.1.20.96:8080/listConfig \-H 'Accept: */*' \-H 'Cache-Control: no-cache' \-H 'Connection: keep-alive' \-H 'Host: 10.1.20.96:8080' \-H 'Postman-Token: 1c9d0349-4b6d-4a2c-834f-4e2f94194649,3dff68f4-2e10-4e96-926a-344faa5f0a19' \-H 'User-Agent: PostmanRuntime/7.15.0' \-H 'accept-encoding: gzip, deflate' \-H 'cache-control: no-cache'
得到的结果:
3. 利用SpringBoot实现读写分离
上一小节中展示了如何利用SharingSphere+SpringBoot进行数据的分片,这一小节着重描述一下如何进行读写分离,下一小节计划展示如何将读写分离和分片结合起来。
首先还是会利用多实例来模拟,为了简单,我没有配置复制,而是预置了几条数据进去,判断能否将读写请求分发到不同的节点上。
首先我们新建一张表:
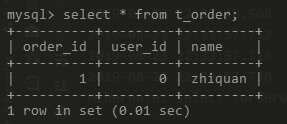
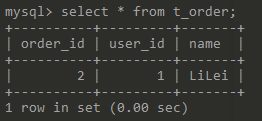
create table t_order(order_id bigint not null auto_increment primary key,user_id bigint not null,name varchar(100));-- masterinsert into t_order(user_id, name) values (0, 'zhiquan');-- slaveinsert into t_order(user_id, name) values (1, 'LiLei');
我会配置slave为读数据源,那么读出的数据一定是user_id=1这一条。
数据是这样的,首先是master:
然后是slave:
接下来开始粘贴代码,首先是配置:
application.properties:
**
spring.shardingsphere.datasource.names=ds0,ds1spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds0.username=rootspring.shardingsphere.datasource.ds0.password=spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3307/test?serverTimezone=GMT%2B8spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds1.username=rootspring.shardingsphere.datasource.ds1.password=spring.shardingsphere.masterslave.name=msspring.shardingsphere.masterslave.master-data-source-name=ds0spring.shardingsphere.masterslave.slave-data-source-names=ds1server.port=8080spring.jpa.show-sql=true
具体的实现代码就不粘贴了,和之前的小节没有什么区别。下面开始测试,首先是一个GET请求:
curl -X GET \'http://localhost:8080/getOrder?orderId=2' \-H 'Accept: */*' \-H 'Accept-Encoding: gzip, deflate' \-H 'Cache-Control: no-cache' \-H 'Connection: keep-alive' \-H 'Host: localhost:8080' \-H 'Postman-Token: 028a4539-a727-47f2-8862-2eed637883d0,ffbe396f-5c33-4266-a00e-d2a0246283f3' \-H 'User-Agent: PostmanRuntime/7.15.2' \-H 'cache-control: no-cache'
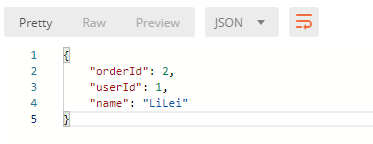
如上图,和预期是一样的,读取到了slave上的数据,那么现在看看写操作:
curl -X POST \'http://localhost:8080/saveOrder?userId=123&name=HanMeimei' \-H 'Accept: */*' \-H 'Accept-Encoding: gzip, deflate' \-H 'Cache-Control: no-cache' \-H 'Connection: keep-alive' \-H 'Content-Length: ' \-H 'Host: localhost:8080' \-H 'Postman-Token: f0497259-a82a-4dcf-9849-3dcdae431742,77fd1308-b5e8-4882-be07-fa128e6efc4d' \-H 'User-Agent: PostmanRuntime/7.15.2' \-H 'cache-control: no-cache'
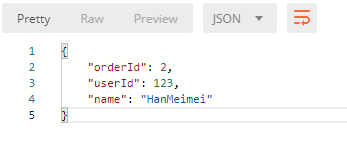
现在看看主节点的表:
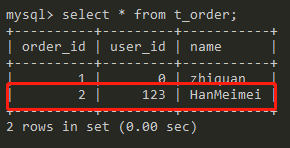
如上图,这条数据已经成功的写入了master。
利用ShardingSphere-JDBC实现分库分表的更多相关文章
- 分库分表之ShardingSphere
目录 分库分表诞生的前景 分库分表的方式(垂直拆分,水平复制) 1.垂直拆分 1.1 垂直分库 1.2 垂直分表 2.水平拆分 2.1 水平分库 2.2 水平分表 分库分库中间件 ShardingSp ...
- sharding-jdbc之——分库分表实例
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/79368021 一.概述 之前,我们介绍了利用Mycat进行分库分表操作,Mycat ...
- mycat+mysql集群:实现读写分离,分库分表
1.mycat文档:https://github.com/MyCATApache/Mycat-doc 官方网站:http://www.mycat.org.cn/ 2.mycat的优点: 配 ...
- mysql 分库分表 ~ ShardingSphere生态圈
一 简介 Apache ShardingSphere是一款开源的分布式数据库中间件组成的生态圈二 成员包含 Sharding-JDBC是一款轻量级的Java框架,在JDBC层提供上述核心功能 ...
- 分库分表利器——sharding-sphere
背景 得不到的东西让你彻夜难眠,没有尝试过的技术让我跃跃欲试. 本着杀鸡焉用牛刀的准则,我们倡导够用就行,不跟风,不盲从. 所以,结果就是我们一直没有真正使用分库分表.曾经好几次,感觉没有分库分表(起 ...
- 利用ShardingSphere-JDBC实现分库分表--配置中心的实现
在之前的文章中我详细描述了如何利用ShardingSphere-JDBC进行分库分表,同时也实现了简单的精确分库算法接口,详情见下面的链接: 利用ShardingSphere-JDBC实现分库分表 但 ...
- 分库分表(3) ---SpringBoot + ShardingSphere 实现读写分离
分库分表(3)---ShardingSphere实现读写分离 有关ShardingSphere概念前面写了两篇博客: 1.分库分表(1) --- 理论 2. 分库分表(2) --- ShardingS ...
- 分库分表(4) ---SpringBoot + ShardingSphere 实现分表
分库分表(4)--- ShardingSphere实现分表 有关分库分表前面写了三篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3.分库 ...
- 分库分表(5) ---SpringBoot + ShardingSphere 实现分库分表
分库分表(5)--- ShardingSphere实现分库分表 有关分库分表前面写了四篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3. ...
随机推荐
- iconfontのsymbol的使用
iconfontのsymbol的使用 iconfont三种方式的优缺点 unicode 优点: 1.兼容性最好,支持ie6+ 2.支持按字体的方式去动态调整图标大小,颜色等等 缺点: 1.不支持多色图 ...
- 判断list集合不为空
在java开发中新手容易将判断一个list集合是否为空,只以If(list!=null)去判断,且容易和isEmpty()混淆,但是,list集合为空还是为null,是有区别的. 先看一下下面的例子, ...
- Kafka集群部署以及使用
Kafka集群部署 部署步骤 hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka http://kafka.apache.org/down ...
- [小米OJ] 5. 找出旋转有序数列的中间值
排序,输出 #include <bits/stdc++.h> using namespace std; int main() { string input; while (cin > ...
- Java EE.JavaBean
JavaBean是一组可移植.可重用.并可以组装到应用程序中的Java类.一个Model类(属性+构造函数).
- 解读Android MediaPlayer 详细使用方法
MediaPlayer具有非常强大的功能,对音视频的播放均提供了支持,为了保证播放期间系统的正常工作,需要设置"android.permission.WAKE_LOCK"权 ...
- [NLP] 相对位置编码(二) Relative Positional Encodings - Transformer-XL
参考: 1. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context https://arxiv.org/pdf ...
- GStreamer基础教程06 - 获取媒体信息
摘要 在常见的媒体文件中,通常包含一些数据(例如:歌手,专辑,编码类型等),用于描述媒体文件.通常称这些数据为元数据(Metadata:data that provides information a ...
- poj2909 欧拉素数筛选
刚刚学了一种新的素数筛选法,效率比原先的要高一些,据说当n趋近于无穷大时这个的时间复杂度趋近O(n).本人水平有限,无法证明. 这是道水题,贴代码出来重点是欧拉筛选法.我把原来普通的筛选法贴出来. / ...
- OI/ACM最全卡常大招
NO.10: 循环展开: 在缓存和寄存器允许的情况下一条语句内大量的展开运算会刺激 CPU 并发(蛤?这是个什么原理,算了,反正写了没坏处就这么写吧) NO.9: 特殊运算优化:(或许这真的没用) 取 ...