Python + opencv 实现图片文字的分割
实现步骤:
1、通过水平投影对图形进行水平分割,获取每一行的图像;
2、通过垂直投影对分割的每一行图像进行垂直分割,最终确定每一个字符的坐标位置,分割出每一个字符;
先简单介绍一下投影法:分别在水平和垂直方向对预处理(二值化)的图像某一种像素进行统计,对于二值化图像非黑即白,我们通过对其中的白点或者黑点进行统计,根据统计结果就可以判断出每一行的上下边界以及每一列的左右边界,从而实现分割的目的。
下面通过Python+opencv来实现该功能
首先来实现水平投影:
import cv2
import numpy as np '''水平投影'''
def getHProjection(image):
hProjection = np.zeros(image.shape,np.uint8)
#图像高与宽
(h,w)=image.shape
#长度与图像高度一致的数组
h_ = [0]*h
#循环统计每一行白色像素的个数
for y in range(h):
for x in range(w):
if image[y,x] == 255:
h_[y]+=1
#绘制水平投影图像
for y in range(h):
for x in range(h_[y]):
hProjection[y,x] = 255
cv2.imshow('hProjection2',hProjection) return h_ if __name__ == "__main__":
#读入原始图像
origineImage = cv2.imread('test.jpg')
# 图像灰度化
#image = cv2.imread('test.jpg',0)
image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',image)
# 将图片二值化
retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)
cv2.imshow('binary',img)
#水平投影
H = getHProjection(img)

通过上面的水平投影,根据其白色小山峰的起始位置就可以界定出每一行的起始位置,从而把每一行分割出来。

获得每一行图像之后,可以对其进行垂直投影
def getVProjection(image):
vProjection = np.zeros(image.shape,np.uint8);
#图像高与宽
(h,w) = image.shape
#长度与图像宽度一致的数组
w_ = [0]*w
#循环统计每一列白色像素的个数
for x in range(w):
for y in range(h):
if image[y,x] == 255:
w_[x]+=1
#绘制垂直平投影图像
for x in range(w):
for y in range(h-w_[x],h):
vProjection[y,x] = 255
cv2.imshow('vProjection',vProjection)
return w_

通过垂直投影可以获得每一个字符左右的起始位置,这样也就可以获得到每一个字符的具体坐标位置,即一个矩形框的位置。
下面是实现的全部代码:
import cv2
import numpy as np '''水平投影'''
def getHProjection(image):
hProjection = np.zeros(image.shape,np.uint8)
#图像高与宽
(h,w)=image.shape
#长度与图像高度一致的数组
h_ = [0]*h
#循环统计每一行白色像素的个数
for y in range(h):
for x in range(w):
if image[y,x] == 255:
h_[y]+=1
#绘制水平投影图像
for y in range(h):
for x in range(h_[y]):
hProjection[y,x] = 255
cv2.imshow('hProjection2',hProjection) return h_ def getVProjection(image):
vProjection = np.zeros(image.shape,np.uint8);
#图像高与宽
(h,w) = image.shape
#长度与图像宽度一致的数组
w_ = [0]*w
#循环统计每一列白色像素的个数
for x in range(w):
for y in range(h):
if image[y,x] == 255:
w_[x]+=1
#绘制垂直平投影图像
for x in range(w):
for y in range(h-w_[x],h):
vProjection[y,x] = 255
#cv2.imshow('vProjection',vProjection)
return w_ if __name__ == "__main__":
#读入原始图像
origineImage = cv2.imread('test.jpg')
# 图像灰度化
#image = cv2.imread('test.jpg',0)
image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',image)
# 将图片二值化
retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)
cv2.imshow('binary',img)
#图像高与宽
(h,w)=img.shape
Position = []
#水平投影
H = getHProjection(img) start = 0
H_Start = []
H_End = []
#根据水平投影获取垂直分割位置
for i in range(len(H)):
if H[i] > 0 and start ==0:
H_Start.append(i)
start = 1
if H[i] <= 0 and start == 1:
H_End.append(i)
start = 0
#分割行,分割之后再进行列分割并保存分割位置
for i in range(len(H_Start)):
#获取行图像
cropImg = img[H_Start[i]:H_End[i], 0:w]
#cv2.imshow('cropImg',cropImg)
#对行图像进行垂直投影
W = getVProjection(cropImg)
Wstart = 0
Wend = 0
W_Start = 0
W_End = 0
for j in range(len(W)):
if W[j] > 0 and Wstart ==0:
W_Start =j
Wstart = 1
Wend=0
if W[j] <= 0 and Wstart == 1:
W_End =j
Wstart = 0
Wend=1
if Wend == 1:
Position.append([W_Start,H_Start[i],W_End,H_End[i]])
Wend =0
#根据确定的位置分割字符
for m in range(len(Position)):
cv2.rectangle(origineImage, (Position[m][0],Position[m][1]), (Position[m][2],Position[m][3]), (0 ,229 ,238), 1)
cv2.imshow('image',origineImage)
cv2.waitKey(0)
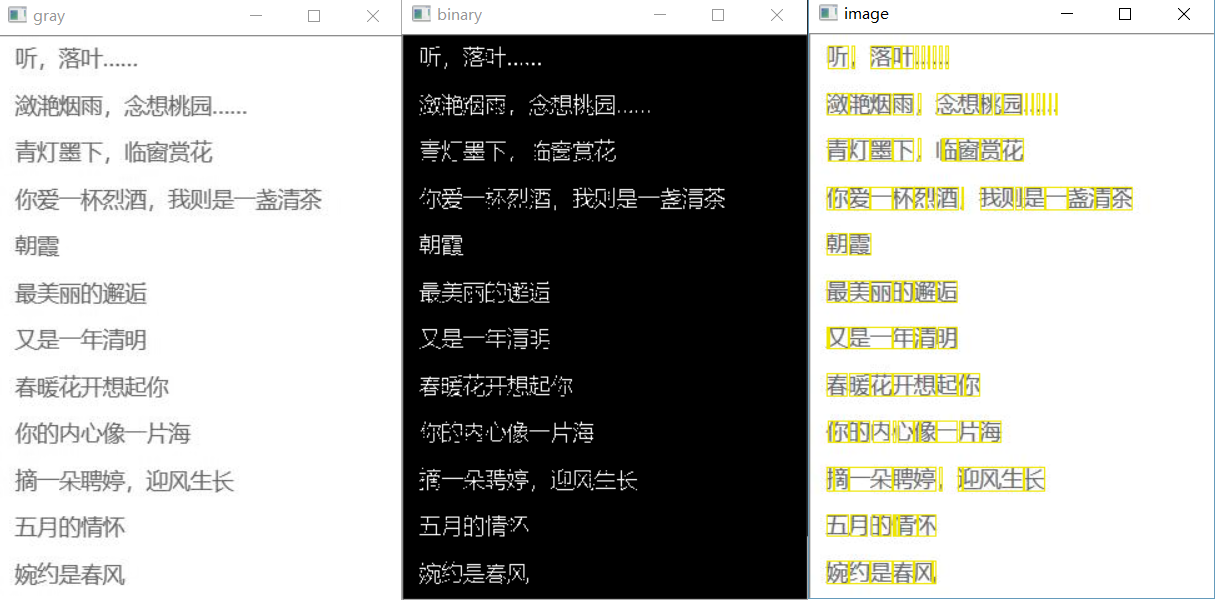
从分割的结果上看,基本上实现了图片中文字的分割。但由于中文结构复杂性,对于一些文字的分割并不理想,比如“叶”、“桃”等字会出现过度分割现象;对于有粘连的两个字会出现分割不够的现象,比如上图中的“念想”。不过可以从图像预处理(腐蚀),边界判断阈值的调整等方面进行优化。
Python + opencv 实现图片文字的分割的更多相关文章
- Python+OpenCV竖版古籍文字分割
在做图片文字分割的时候,常用的方法有两种.一种是投影法,适用于排版工整,字间距行间距比较宽裕的图像:还有一种是用OpenCV的轮廓检测,适用于文字不规则排列的图像. 1. 思路 一开始想偷个懒,直接用 ...
- python opencv show图片,debug技巧
debug的时候可以直接把图片画出来debug. imshow函数就是python opencv的展示图片的函数,第一个是你要起的图片名,第二个是图片本身.waitKey函数是用来展示图片多久的,默认 ...
- Python图像处理之图片文字识别(OCR)
OCR与Tesseract介绍 将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR).可以实现OCR 的底层库并不多,目前很多库都是使用共同 ...
- python实现中文图片文字识别--OCR about chinese text--tesseract
0.我的环境: win7 32bits python 3.5 pycharm 5.0 1.相关库 安装pillow: pip install pillow 安装tesseract: tesseract ...
- python opencv 读取图片 返回图片某像素点的b,g,r值
转载:https://blog.csdn.net/weixin_41799483/article/details/80884682 #coding=utf-8 #读取图片 返回图片某像素点的b,g ...
- Python opencv resize图片并保存原有的图像比例
参考链接:https://www.jianshu.com/p/3092835eab61 现有的图像是高瘦高瘦的,所以直接resize成矩形不合适.改变了整个结构. 所以采用的是先resize再padd ...
- Python OpenCV 显示图片,图片分类
def divide_image(path,g_path1,g_path0): img_lst = os.listdir(path) for i in img_lst: print('类别1,类别0' ...
- 用 Python 和 OpenCV 检测图片上的条形码
用 Python 和 OpenCV 检测图片上的的条形码 这篇博文的目的是应用计算机视觉和图像处理技术,展示一个条形码检测的基本实现.我所实现的算法本质上基于StackOverflow 上的这个问 ...
- Python人工智能之图片识别,Python3一行代码实现图片文字识别
1.Python人工智能之图片识别,Python3一行代码实现图片文字识别 2.tesseract-ocr安装包和中文语言包 注意:
随机推荐
- 水果机抽奖(CocosCreator)
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 一.前言 在前面给大家分享了大转盘的抽奖方式,这是现在游戏使用较多的一种抽奖方式,今天给大家介绍另一抽奖方式--水果 ...
- HDU 2147
题意略. 思路: 题中提到的3种操作,一个是将长方形的n减少1,一个是将m减少1,一个是将n和m同时减少1,都是将长方形规模减少的的操作. 现在我们可以知道,(1,1)先手必输:(1,2),(2,1) ...
- softRestTemplate 2
@SuppressWarnings("unchecked") public User getUser(String id,String name) { Soft ...
- CodeForces 1084 F Max Mex
Max Mex 题意:问在树上的所有路中mex值最大是多少. 题解: 用线段树维护值. 区间[L,R]意味着 区间[L,R]的数可不可以合并. 重点就是合并的问题了. 首先合法的区间只有3种: 1. ...
- hdu 6435 CSGO
题意:现在有n个主武器, m个副武器, 你要选择1个主武器,1个副武器, 使得 题目给定的那个式子最大. 题解:这个题目困难的地方就在于有绝对值,| a - b | 我们将绝对值去掉之后 他的值就为 ...
- 三个小白是如何在三个月内搭一个基于kaldi的嵌入式在线语音识别系统的
前面的博客里说过最近几个月我从传统语音(语音通信)切到了智能语音(语音识别).刚开始是学语音识别领域的基础知识,学了后把自己学到的写了PPT给组内同学做了presentation(语音识别传统方法(G ...
- Go操作etcd
etcd是近几年比较火热的一个开源的.分布式的键值对数据存储系统,提供共享配置.服务的注册和发现,本文主要介绍etcd的安装和使用. etcd etcd介绍 etcd是使用Go语言开发的一个开源的.高 ...
- 056 模块7-os库的基本使用
目录 一.os库基本介绍 二.os库之路径操作 2.1 路径操作 三.os库之进程管理 3.1 进程管理 四.os库之环境参数 4.1 环境参数 一.os库基本介绍 os库提供通用的.基本的操作系统交 ...
- QRowTable表格控件(五)-重写表头排序、支持第三次单击恢复默认排序
目录 一.原生表格 二.效果展示 三.实现方式 1.排序列定制 2.排序交互修改 四.相关文章 原文链接:QRowTable表格控件(五)-重写表头排序.支持第三次单击恢复默认排序 一.原生表格 开发 ...
- 人体行为识别(骨架提取),搭建openpose环境,VS2019(python3.7)+openpose
这几天开始接触人体行为识别,经过多方对比后,选择了现在最热的人体骨架提取开源库,openpose. 下面就不多说了,直接开始openpose在win10下的配置: 需求如下:1. VS2019 ...