浅谈HDFS(一)
产生背景及定义
HDFS:分布式文件系统,用于存储文件,主要特点在于其分布式,即有很多服务器联合起来实现其功能,集群中的服务器各有各的角色
- 随着数据量越来越大,一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是管理和维护极不方便,于是迫切需要一种系统来管理多台机器上的文件,这就是分布式管理系统,HDFS是其中一种。
- HDFS的使用适合一次写入,多次读出的场景,且不支持对文件的直接修改,仅支持在文件末尾追加
- HDFS采用流式的数据访问方式:特点就是像流水一样,数据不是一次过来,而是一点一点“流”过来,处理数据也是一点一点处理。如果是数据全部过来之后才处理,那么延迟就会很大,而且会消耗很大的内存。
优缺点
- 高容错性
- 数据自动保存多个副本,通过增加副本的方式,提高容错性
- 若某一个副本丢失后,它可以自动分配到其它节点作为新的副本
- 处理大数据
- 数据规模:能够处理的数据规模可以达到GB,TB,甚至PB级别的数据
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大
- 可构建在廉价的机器上,通过多副本机制,提高可靠性
组成架构
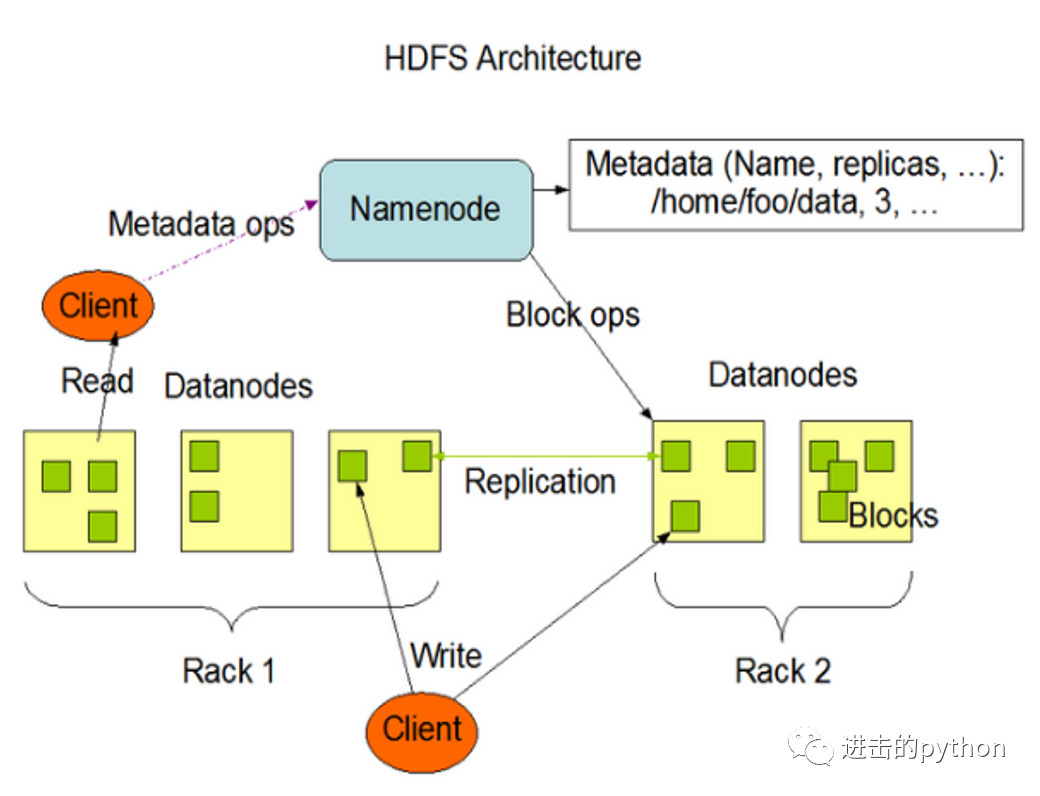
namenode(nn):就是Master,是一个管理者,存放元数据- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块的映射信息
- 处理客户端的读写请求
datanode(dn):就是slave,真正存储文件的地方- 存储实际的数据块
- 执行数据块的读写操作
secondarynamenode(2nn):并非namenode的热备,当namenode挂掉的时候,并不能马上替换namenode并提供服务- 作为namenode的辅助,分担其工作量,比如定期合并Fsimage和Edits(文章后边会讲到这两个东西),并推送给namenode
- 在紧急情况下,可辅助恢复namenode,但是只能恢复部分,而不能全部恢复
client:客户端- 文件的切分,在上传HDFS之前,client将文件切分为一个一个的Block,然后一个一个进行上传
- 与namenode交互,获取文件的datanode信息
- 与datanode交互,读取或写入数据
- client提供一些命令来管理HDFS,比如namenode的格式化
- client通过一些命令来访问HDFS,比如对HDFS的增删查改等
文件块大小
为什么要把文件抽象为Block块存储?
- block的拆分使得单个文件大小可以大于整个磁盘的容量,构成文件的Block可以分布在整个集群, 理论上,单个文件可以占据集群中所有机器的磁盘。
- Block的抽象也简化了存储系统,对于Block,无需关注其权限,所有者等内容(这些内容都在文件级别上进行控制)。
- Block作为容错和高可用机制中的副本单元,即以Block为单位进行复制。
HDFS中的文件在物理内存中分块存储(Block),块的大小在Hadoop2.x版本中默认为128M,在老版本中为64M,那么为什么为128M呢?
其实,HDFS的块的大小的设置主要取决于磁盘传输速率,如下:
- 如果在HDFS中,寻址时间为10ms,即查找到目标Block的时间为10ms
- 专家说操作的最佳状态为:寻址时间为传输时间的1%,因此传输时间为1s
- 而目前磁盘的传输速率普遍为100M/s
为什么块大小不能设置太小,也不能设置太大?
- HDFS的块设置太小,会增加寻址时间,使得程序可能一直在寻找块的开始位置
- 如果设置的太大,从磁盘传输数据的时间会明显大于定位这个块所需的寻址时间,导致程序处理这块数据时会非常慢
HDFS的数据流
HDFS写数据流程
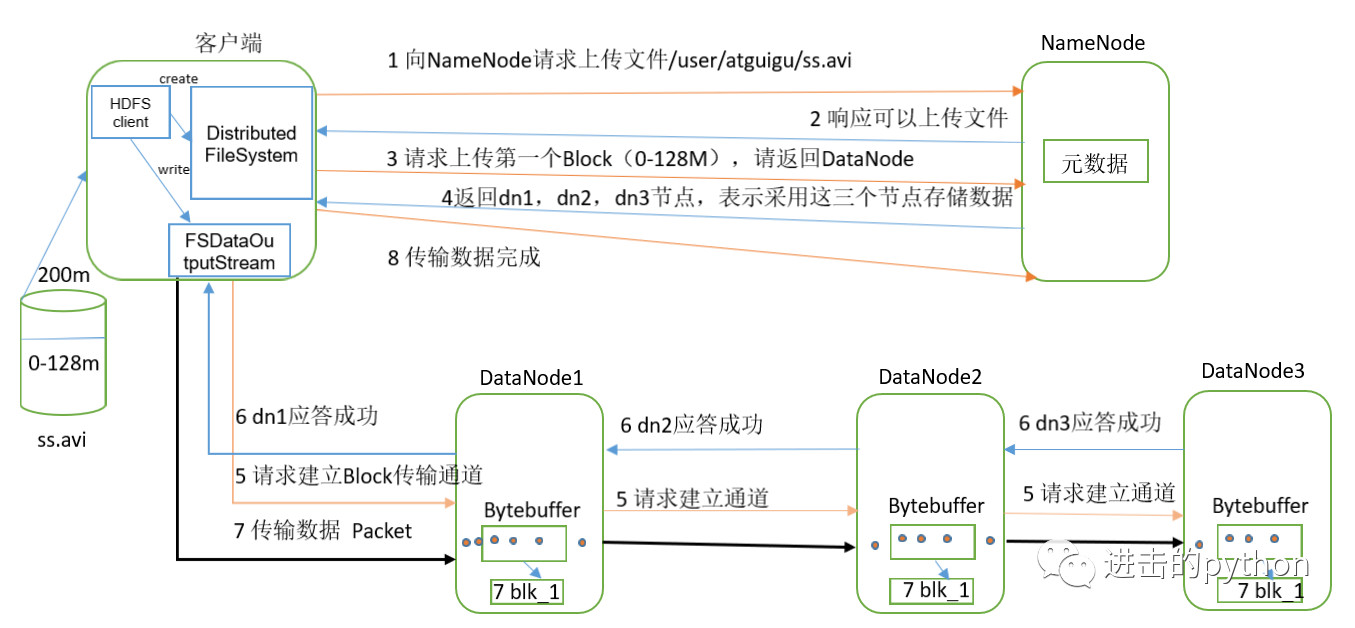
- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求第一个 Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3, 如果有多个节点,返回实际的副本数量,并根据距离及负载情况计算
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
网络拓扑---节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据,那么这个最近距离是怎么计算的呢?
结论:两个节点到达最近的共同祖先的距离总和,即为节点距离。

如上图所示:
- 同一节点上的进程节点距离为0
- 同一机架上不同节点的距离为两个节点到共同机架r1的距离总和,为2
- 同一数据中心不同机架的节点距离为两个节点到共同祖先集群d1的距离之和,为4
- 不同数据中心的节点距离为两个节点到达共同祖先数据中心的距离之和,为6
机架感知(副本存储的节点选择)
副本的数量我们可以从配置文件中设置,那么HDFS是怎么选择副本存储的节点的呢?
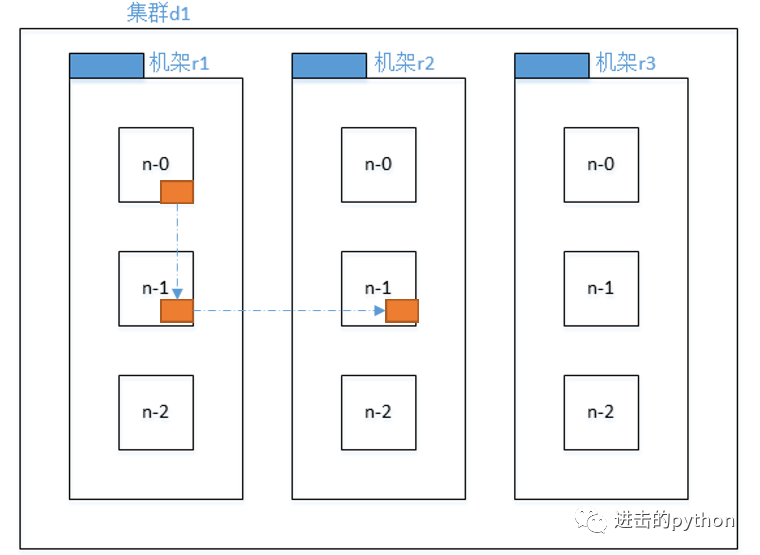
如上图所示,为了提高容错性,有如下设置,加入现在有3个副本:
- 第一个副本在Client所在的节点上,如果客户端在集群外,则随机选一个
- 第二个副本和第一个副本位于相同机架,随机节点
- 第三个副本位于不同机架,随机节点
这样做的目的就是为了提高容错性。
HDFS读数据流程

- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
浅谈HDFS(一)的更多相关文章
- 浅谈HDFS(二)之NameNode与SecondaryNameNode
NN与2NN工作机制 思考:NameNode中的元数据是存储在哪里的? 假设存储在NameNode节点的硬盘中,因为经常需要随机访问和响应客户请求,必然效率太低,所以是存储在内存中的 但是,如果存储在 ...
- 浅谈HDFS(三)之DataNote
DataNode工作机制 一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳. DataNode启动后向Nam ...
- 浅谈mapreduce程序部署
尽管我们在虚拟机client上能非常快通过shell命令,进行运行一些已经封装好实例程序,可是在应用中还是是自己敲代码,然后部署到server中去,以下,我通过程序进行浅谈一个程序的部署过程. 在启动 ...
- 【转】浅谈分布式服务协调技术 Zookeeper
非常好介绍Zookeeper的文章, Google的三篇论文影响了很多很多人,也影响了很多很多系统.这三篇论文一直是分布式领域传阅的经典.根据MapReduce,于是我们有了Hadoop:根据GFS, ...
- [转]浅谈Hive vs. HBase 区别在哪里
浅谈Hive vs. HBase 区别在哪里 导读:Apache Hive是一个构建于Hadoop(分布式系统基础架构)顶层的数据仓库,Apache HBase是运行于HDFS顶层的NoSQL(=No ...
- 浅谈一下流式处理平台Flink
浅谈一下流式处理平台(Flink) 大数据框架听过很多,比如 Hadoop,HDFS...不过自己的项目都没有上过 为什么突然提到 Flink,因为最近一个项目需要用到,所以学习最好的方式就是项目驱动 ...
- 浅谈 Fragment 生命周期
版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Fragment 文中如有纰漏,欢迎大家留言指出. Fragment 是在 Android 3.0 中 ...
- 浅谈 LayoutInflater
浅谈 LayoutInflater 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/View 文中如有纰漏,欢迎大家留言指出. 在 Android 的 ...
- 浅谈Java的throw与throws
转载:http://blog.csdn.net/luoweifu/article/details/10721543 我进行了一些加工,不是本人原创但比原博主要更完善~ 浅谈Java异常 以前虽然知道一 ...
随机推荐
- Vue+ElementUI项目使用webpack输出MPA
目录 Vue+ElementUI项目使用webpack输出MPA 一. 需求分析 二. 原方案分析 三. 多页面改造3步走 四. 小结 Vue+ElementUI项目使用webpack输出MPA 示例 ...
- 学习 Object-C: 简史
对于一门语言的历史,我认为写一本书可能都不为过,关键是看你如何介绍和表达.当然每一个人的理解也大相径庭.本文阐述也仅仅只是冰山一角,如果需要深入了解,自己可能需要多花费一些心思. 这里也不会给大家说太 ...
- 计算机基础+python初阶
今日内容: 1.计算机基础知识 2.python简介 3.快速入门 今日内容: 一.计算机基础 1. 计算机什么组成的 输入输出设备 cpu 硬盘 内存 中央处理器 处理各种数据 相当于人的大脑 内存 ...
- zookeeper学习之原理
一.zookeeper 是什么 Zookeeper是一个分布式协调服务,可用于服务发现,分布式锁,分布式领导选举,配置管理等.这一切的基础,都是Zookeeper提供了一个类似于Linux文件系统的树 ...
- 深度解密Go语言之 scheduler
目录 前置知识 os scheduler 线程切换 函数调用过程分析 goroutine 是怎么工作的 什么是 goroutine goroutine 和 thread 的区别 M:N 模型 什么是 ...
- HTML连载34-背景关联和缩写以及插图图片和背景图片的区别
一.背景属性缩写的格式 1.backgound:背景颜色 背景图片 平铺方式 关联方式 定位方式 2.注意点: 这里的所有值都可以省略,但是至少需要一个 3.什么是背景关联方式 默认情况下,背 ...
- addTarget原理
addTarget原理: 当一个控件addTarget时,先到runLoop注册,然后runLoop才会监听该事件,事件处理按照响应者链条 以下以button为例图解:
- 2019DX#2
Solved Pro.ID Title Ratio(Accepted / Submitted) 1001 Another Chess Problem 8.33%(1/12) 1002 Beau ...
- bzoj 1051 [HAOI2006]受欢迎的牛(tarjan缩点)
题目链接:http://www.lydsy.com:808/JudgeOnline/problem.php?id=1051 题解:缩点之后判断出度为0的有几个,只有一个那么输出那个强连通块的点数,否者 ...
- Dungeon Master POJ - 2251 [kuangbin带你飞]专题一 简单搜索
You are trapped in a 3D dungeon and need to find the quickest way out! The dungeon is composed of un ...