TensorFlow笔记-模型的保存,恢复,实现线性回归
模型的保存
tf.train.Saver(var_list=None,max_to_keep=5)
•var_list:指定将要保存和还原的变量。它可以作为一个
dict或一个列表传递.
•max_to_keep:指示要保留的最近检查点文件的最大数量。
创建新文件时,会删除较旧的文件。如果无或0,则保留所有
检查点文件。默认为5(即保留最新的5个检查点文件。)
saver = tf.train.Saver()
saver.save(sess, "")
模型的恢复
恢复模型的方法是restore(sess, save_path),save_path是以前保存参数的路径,我们可以使用tf.train.latest_checkpoint来获取最近的检查点文件(也恶意直接写文件目录)
if os.path.exists("tmp/ckpt/checkpoint"):
saver.restore(sess,"")
print("恢复模型")
自定义命令行参数
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('data_dir', '/tmp/tensorflow/mnist/input_data',
"""数据集目录""")
tf.app.flags.DEFINE_integer('max_steps', 2000,
"""训练次数""")
tf.app.flags.DEFINE_string('summary_dir', '/tmp/summary/mnist/convtrain',
"""事件文件目录""")
def main(argv):
print(FLAGS.data_dir)
print(FLAGS.max_steps)
print(FLAGS.summary_dir)
print(argv)
if __name__=="__main__":
tf.app.run()
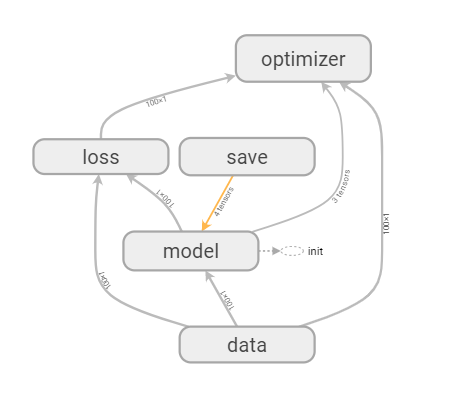
线性回归
准备数据
with tf.variable_scope("data"):
# 1、准备数据,x 特征值 [100, 1] y 目标值[100]
x = tf.random_normal([100, 1], mean=1.75, stddev=0.5, name="x_data")
# 矩阵相乘必须是二维的
y_true = tf.matmul(x, [[0.7]]) + 0.8
构建模型
with tf.variable_scope("model"):
# 2、建立线性回归模型 1个特征,1个权重, 一个偏置 y = x w + b
# 随机给一个权重和偏置的值,让他去计算损失,然后再当前状态下优化
# 用变量定义才能优化
weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name="w")
bias = tf.Variable(0.0, name="b")
y_predict = tf.matmul(x, weight) + bias
构造损失函数
with tf.variable_scope("loss"):
# 3、建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_true - y_predict))
利用梯度下降
with tf.variable_scope("optimizer"):
# 4、梯度下降优化损失 leaning_rate: 0 ~ 1, 2, 3,5, 7, 10
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
源码
import tensorflow as tf
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
# 在这里立flag
tf.app.flags.DEFINE_integer("max_step",100,"模型训练的步数")
tf.app.flags.DEFINE_string("model_dir","tmp/summary/test","模型文件的加载路径") FLAGS = tf.app.flags.FLAGS
def myregression():
with tf.variable_scope("data"):
x = tf.random_normal([100, 1], mean=1.75, stddev=0.5)
y_true = tf.matmul(x, [[0.7]]) + 0.8
with tf.variable_scope("model"):
# 权重 trainable 指定权重是否随着session改变
weight = tf.Variable(tf.random_normal([int(x.shape[1]), 1], mean=0, stddev=1), name="w")
# 偏置项
bias = tf.Variable(0.0, name='b')
# 构造y函数
y_predict = tf.matmul(x, weight) + bias
with tf.variable_scope("loss"):
# 定义损失函数
loss = tf.reduce_mean(tf.square(y_true - y_predict))
with tf.variable_scope("optimizer"):
# 使用梯度下降进行求解
train_op = tf.train.GradientDescentOptimizer(0.1).minimize((loss))
# 1.收集tensor
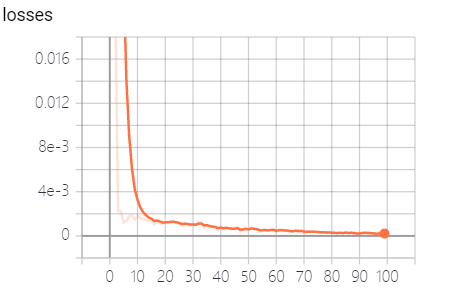
tf.summary.scalar("losses", loss)
tf.summary.histogram("weights", weight)
# 2.定义合并tensor的op
merged = tf.summary.merge_all()
# 定义一个保存模型的op
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
# import matplotlib.pyplot as plt
# plt.scatter(x.eval(), y_true.eval())
# plt.show()
print("初始化的权重:%f,偏置项:%f" % (weight.eval(), bias.eval()))
# 建立事件文件
filewriter = tf.summary.FileWriter('./tmp/summary/test/', graph=sess.graph)
# 加载模型
if os.path.exists("tmp/ckpt/checkpoint"):
saver.restore(sess,FLAGS.model_dir)
print("加载")
n = 0
while loss.eval() > 1e-6:
n += 1
if(n==FLAGS.max_step):
break
sess.run(train_op)
summary = sess.run(merged)
filewriter.add_summary(summary, n)
print("第%d次权重:%f,偏置项:%f" % (n, weight.eval(), bias.eval()))
saver.save(sess, FLAGS.model_dir)
return weight, bias myregression()
# x_min,x_max = np.min(x.eval()),np.max(x.eval())
# tx = np.arange(x_min,x_max,100)
TensorFlow笔记-模型的保存,恢复,实现线性回归的更多相关文章
- Tensorflow Learning1 模型的保存和恢复
CKPT->pb Demo 解析 tensor name 和 node name 的区别 Pb 的恢复 CKPT->pb tensorflow的模型保存有两种形式: 1. ckpt:可以恢 ...
- Tensorflow学习笔记----模型的保存和读取(4)
一.模型的保存:tf.train.Saver类中的save TensorFlow提供了一个一个API来保存和还原一个模型,即tf.train.Saver类.以下代码为保存TensorFlow计算图的方 ...
- Python之TensorFlow的模型训练保存与加载-3
一.TensorFlow的模型保存和加载,使我们在训练和使用时的一种常用方式.我们把训练好的模型通过二次加载训练,或者独立加载模型训练.这基本上都是比较常用的方式. 二.模型的保存与加载类型有2种 1 ...
- tensorflow 之模型的保存与加载(三)
前面的两篇博文 第一篇:简单的模型保存和加载,会包含所有的信息:神经网络的op,node,args等; 第二篇:选择性的进行模型参数的保存与加载. 本篇介绍,只保存和加载神经网络的计算图,即前向传播的 ...
- tensorflow 之模型的保存与加载(二)
上一遍博文提到 有些场景下,可能只需要保存或加载部分变量,并不是所有隐藏层的参数都需要重新训练. 在实例化tf.train.Saver对象时,可以提供一个列表或字典来指定需要保存或加载的变量. #!/ ...
- tensorflow 之模型的保存与加载(一)
怎样让通过训练的神经网络模型得以复用? 本文先介绍简单的模型保存与加载的方法,后续文章再慢慢深入解读. #!/usr/bin/env python3 #-*- coding:utf-8 -*- ### ...
- tensorflow:模型的保存和训练过程可视化
在使用tf来训练模型的时候,难免会出现中断的情况.这时候自然就希望能够将辛辛苦苦得到的中间参数保留下来,不然下次又要重新开始. 保存模型的方法: #之前是各种构建模型graph的操作(矩阵相乘,sig ...
- 【TensorFlow】TensorFlow基础 —— 模型的保存读取与可视化方法总结
TensorFlow提供了一个用于保存模型的工具以及一个可视化方案 这里使用的TensorFlow为1.3.0版本 一.保存模型数据 模型数据以文件的形式保存到本地: 使用神经网络模型进行大数据量和复 ...
- tensorflow模型的保存与恢复
1.tensorflow中模型的保存 创建tf.train.saver,使用saver进行保存: saver = tf.train.Saver() saver.save(sess, './traine ...
随机推荐
- 文件文件夹混合多选对话框(修改GWL_WNDPROC)
/******************************************************************** created: 2008/07/22 created: 2 ...
- C语言实现常用查找算法——二分查找
#include<stdio.h> void insert_sort(int a[],int n); int binary_search(int a[],int x,int n); voi ...
- Python处理图片
# -*- coding: UTF-8 -*- from PIL import Image import os import sys reload(sys) sys.setdefaultencodin ...
- hgoi#20190517
T1-Mike and gcd problem Mike给定一个n个元素的整数序列,A=[a1,a2,...,an],每次操作可以选择一个i(1≤i<n),将a[i],a[i+1]变成a[i]- ...
- 系列教程 之 Android开发之旅
工作室持续推出Android开发系列教程与案例,供广大朋友分享交流技术经验,帮助喜欢Android的朋友们学习进步: 1. Android开发之旅(1) 之 Android 开发环境搭建 代码之间工作 ...
- java - Builder模式实例化对象
Builder 优雅的链式调用来实现实例化对象 1. 首先在实体类中,构造一个Builder内部类,由Builder来完成Person的属性赋值,并最终执行build来完成Person的实例化 pa ...
- 学习 GitHub 有什么好处?
layout: post title: "学习 GitHub 有什么好处?" date: 2018-04-15 19:20:20 +0800 --- 鸣谢:王顶 老师(河北经贸大学 ...
- 用python的matplotlib和numpy库绘制股票K线均线和成交量的整合效果(含量化验证交易策略代码)
在用python的matplotlib和numpy库绘制股票K线均线的整合效果(含从网络接口爬取数据和验证交易策略代码)一文里,我讲述了通过爬虫接口得到股票数据并绘制出K线均线图形的方式,在本文里,将 ...
- POJ 2778:DNA Sequence(AC自动机构造矩阵)
http://poj.org/problem?id=2778 题意:有m个病毒DNA,问构造一个长度为n的不带病毒DNA的字符串可以有多少种. 思路:看到这题有点懵,想了挺久题解的思路. 使用AC自动 ...
- RedisCrawlSpider
这个RedisCrawlSpider类爬虫继承了RedisCrawlSpider,能够支持分布式的抓取.因为采用的是crawlSpider,所以需要遵守Rule规则,以及callback不能写pars ...