Django之web框架原理
Web框架原理
我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端。 这样我们就可以自己实现Web框架了。
先写一个
原始的web框架
import socket
sk = socket.socket()
sk.bind(('127.0.0.1', 8080))
sk.listen(5)
while True:
conn, addr = sk.accept()
data = conn.recv(1024)
print(data) # 打印浏览器发过来的消息并分析
conn.send(b'ok')
conn.close()
可以说Web服务本质上都是在这几行代码基础上扩展出来的。这段代码就是它们的祖宗。
用户的浏览器一输入网址,会给服务端发送数据,那浏览器会发送什么数据?怎么发?这个谁来定? 你这个网站是这个规定,他那个网站按照他那个规定,这互联网还能玩么?
所以,必须有一个统一的规则,让大家发送消息、接收消息的时候有个格式依据,不能随便写。
这个规则就是HTTP协议,以后浏览器发送请求信息也好,服务器回复响应信息也罢,都要按照这个规则来。
HTTP协议主要规定了客户端和服务器之间的通信格式,那HTTP协议是怎么规定消息格式的呢?
运行上面的代码,在浏览器输入服务器的地址和端口
得到浏览器发过来的data的打印结果:
# data结果
'''
1.请求首行:
b'GET / HTTP/1.1\r\n
2.请求体:一大堆K:V键值对
Host: 127.0.0.1:8080\r\n
Connection: keep-alive\r\n
Cache-Control: max-age=0\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36 chrome-extension\r\n
Sec-Fetch-Mode: navigate\r\n
Sec-Fetch-User: ?1\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\r\n
Sec-Fetch-Site: cross-site\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9,en-GB;q=0.8,en;q=0.7\r\n
\r\n
3.请求体:
这里是请求数据,get请求没有,post请求才有
'''
我们发现收发的消息需要按照一定的格式来,
1.数据格式
get请求格式
请求首行(请求方式,协议版本。。。)
请求头(一大堆k:v键值对)
\r\n
请求体(真正的数据 发post请求的时候才有 如果是get请求不会有)
响应格式
响应首行
响应头
\r\n
响应体
HTTP GET请求的格式:

HTTP响应的格式:

这里就需要了解一下HTTP协议了。
HTTP协议对收发消息的格式要求
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。 HTTP响应的Header中有一个 Content-Type表明响应的内容格式。如 text/html表示HTML网页。
HTTP协议特点:
超文本传输协议
1.四大特性
1.基于TCP/IP之上作用于应用层
2.基于请求响应
3.无状态 cookie session token...
4.无连接
2.响应状态码
用特定的数字表示一些意思
1XX:服务端已经成功接收到了你的数据 正在处理 你可以继续提交其他数据
2XX:服务端成功响应(200请求成功)
3XX:重定向
4XX:请求错误(404 请求资源不存在 403 拒绝访问)
5XX:服务器内部错误(500 )
自定义web框架完整版
如果我们想要自己写的web server服务端真正运行起来,达到一种请求与响应的对应关系,我们必须要在sercer服务端给客户端回复消息的时候,按照HTTP协议的规则加上响应状态行 ,就是 协议版本+状态码+状态描述符:b'HTTP/1.1 200 OK\r\n\r\n'
如下例子:
import socket
sk = socket.socket()
sk.bind(('127.0.0.1', 8080))
sk.listen(5)
while True:
conn, addr = sk.accept()
data = conn.recv(1024)
print(data)
# 需要向客服端发送响应头,客户端才能正常显示信息
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')
conn.send(b'hello world')
conn.close()
根据不同的路径返回不同的内容的Web服务端
如果我们在浏览器客户端输入:http://127.0.0.1:8080/home,浏览器的页面显示就为home,那么可以这样做:
import socket
sk = socket.socket()
sk.bind(('127.0.0.1', 8080)) # 绑定IP和端口
sk.listen(5) # 监听
while True:
# 等待连接
conn, addr = sk.accept()
# 接收客户端返回的信息
data = conn.recv(1024)
# print(data)
# 从data中取到路径 并将收到的字节类型的数据转换成字符串
# data = str(data,encoding='utf8')
data = data.decode('utf8')
# 按\r\n分割
data1 = data.split('\r\n')[0]
# print(data1)
# 请求首行的进行切割拿到url url是我们从浏览器发来的消息分离出来的访问路径
url=data1.split(' ')[1]
# print(url)
# 必须遵循HTTP协议,需要向客服端发送状态行,客户端才能正常显示信息
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')
# 根据不同的路径返回不同内容
if url == '/index':
response = b'index'
elif url == '/home':
response = b'home'
else:
response = b'404 not found!!!'
conn.send(response)
conn.close()
不同路径不同内容-函数版
import socket
sk = socket.socket()
sk.bind(('127.0.0.1', 8080)) # 绑定IP和端口
sk.listen(5) # 监听
# 将返回不同的内容部分封装成函数
def index(url):
res = f'这是{url}页面|'
return bytes(res,encoding='gbk')
# return res.encode('utf-8')
def home(url):
res = f'这是{url}页面|'
return bytes(res,encoding='gbk')
# return res.encode('utf-8')
while True:
# 等待连接
conn, addr = sk.accept()
# 接收客户端返回的信息
data = conn.recv(1024)
# print(data)
# 从data中取到路径 并将收到的字节类型的数据转换成字符串
# data = str(data,encoding='utf8')
data = data.decode('utf8')
# 按\r\n分割
data1 = data.split('\r\n')[0]
# print(data1)
# 请求首行的进行切割拿到url url是我们从浏览器发来的消息分离出来的访问路径
url=data1.split(' ')[1]
# print(url)
# 根据不同的路径返回不同内容
if url == '/index':
response = index(url)
elif url == '/home':
response = home(url)
else:
response = b'404 not found!!!'
# 必须遵循HTTP协议,需要向客服端发送状态行,客户端才能正常显示信息
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')
conn.send(response)
conn.close()
不同路径不同内容-函数进阶版
import socket
sk = socket.socket()
sk.bind(('127.0.0.1', 8080)) # 绑定IP和端口
sk.listen(5) # 监听
# 定义一个url和实际要执行的函数的对应关系
def home(url):
res = bytes(url, encoding='utf8')
return res
def index(url):
res = bytes(url, encoding='utf8')
return res
# 定义一个url和要执行函数对应关系的字典
dt = {
'/index':index,
'/home':home
}
while True:
# 等待连接
conn, addr = sk.accept()
# 接收客户端返回的信息
data = conn.recv(1024)
# print(data)
# 从data中取到路径 并将收到的字节类型的数据转换成字符串
# data = str(data,encoding='utf8')
data = data.decode('utf8')
# 按\r\n分割
data1 = data.split('\r\n')[0]
# print(data1)
# 请求首行的进行切割拿到url url是我们从浏览器发来的消息分离出来的访问路径
url=data1.split(' ')[1]
# print(url)
func = None
# 根据不同的路径返回不同内容
for k,v in dt.items():
print(k,v)
if url == k:
func = v
break
if func:
response = func(url)
else:
response = b'404 not found!!!'
# 必须遵循HTTP协议,需要向客服端发送状态行,客户端才能正常显示信息
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')
conn.send(response)
conn.close()
返回具体的HTML页面
首先创建我们需要的html页面,然后把在代码里面以rb模式读取出来,发送到浏览器
import socket
sk = socket.socket()
sk.bind(('127.0.0.1', 8080)) # 绑定IP和端口
sk.listen(5) # 监听
def home(url):
with open('home页面.html','rb') as fr:
res = fr.read()
return res
def index(url):
with open('index页面.html', 'rb') as fr:
res = fr.read()
return res
# 定义一个url和实际要执行的函数的对应关系
dt = {
'/index':'index',
'/home':'home'
}
while True:
# 等待连接
conn, addr = sk.accept()
# 接收客户端返回的信息
data = conn.recv(1024)
# print(data)
# 从data中取到路径 并将收到的字节类型的数据转换成字符串
# data = str(data,encoding='utf8')
data = data.decode('utf8')
# 按\r\n分割
data1 = data.split('\r\n')[0]
# print(data1)
# 请求首行的进行切割拿到url url是我们从浏览器发来的消息分离出来的访问路径
url=data1.split(' ')[1]
# print(url)
func = None
# 根据不同的路径返回不同内容
for k,v in dt.items():
print(k,v)
if url == k:
func = v
break
if func:
response = func(url)
else:
response = b'404 not found!!!'
# 必须遵循HTTP协议,需要向客服端发送状态行,客户端才能正常显示信息
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')
conn.send(response)
conn.close()
返回动态的网页
上面的网页是不会变化的,如何实现得到一个动态的网站呢?下面做个例子:每次刷新都在获取新的时间,模拟动态的数据
import socket
import datetime
sk = socket.socket()
sk.bind(('127.0.0.1', 8080)) # 绑定IP和端口
sk.listen(5) # 监听
def home(url):
with open('get_time.html', 'r',encoding='utf8') as fr:
res = fr.read()
now = datetime.datetime.now().strftime("%Y-%m-%d %X")
# 在网页中定义好特殊符号,用动态的数据替换特殊字符
res = res.replace('*time*',now).encode('utf8')
return res
def index(url):
with open('index页面.html', 'rb') as fr:
res = fr.read()
return res
# 定义一个url和实际要执行的函数的对应关系
dt = {
'/index': index,
'/home': home
}
while True:
# 等待连接
conn, addr = sk.accept()
# 接收客户端返回的信息
data = conn.recv(1024)
# print(data)
# 从data中取到路径 并将收到的字节类型的数据转换成字符串
# data = str(data,encoding='utf8')
data = data.decode('utf8')
# 按\r\n分割
data1 = data.split('\r\n')[0]
# print(data1)
# 请求首行的进行切割拿到url url是我们从浏览器发来的消息分离出来的访问路径
url=data1.split(' ')[1]
# print(url)
func = None
# 根据不同的路径返回不同内容
for k,v in dt.items():
print(k,v)
if url == k:
func = v
break
if func:
response = func(url)
else:
response = b'404 not found!!!'
# 必须遵循HTTP协议,需要向客服端发送状态行,客户端才能正常显示信息
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')
conn.send(response)
conn.close()
什么是服务器程序和应用程序?
对于真实开发中的python web程序来说,一般会分为两部分:服务器程序和应用程序。
服务器程序负责对socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理
应用程序则负责具体的逻辑处理。为了方便应用程序的开发,就出现了众多的Web框架,例如:Django、Flask、web.py 等。不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。
为了统一规范,设立了一个标准,服务器和框架都支持这个标准。这样不同的服务器就能适应不同的开发框架,不同的开发框架也就能适应不同的服务器。
WSGI(Web Server Gateway Interface)就是一种规范,它定义了使用Python编写的web应用程序与web服务器程序之间的接口格式,实现web应用程序与web服务器程序间的解耦。
常用的WSGI服务器有uwsgi、Gunicorn。而Python标准库提供的独立WSGI服务器叫wsgiref,Django开发环境用的就是这个模块来做服务器
利用wsgiref模块创建web服务器
from wsgiref.simple_server import make_server
def run(environ,response):
# 当客户发送请求过来时,会先调用wsgi内部接口,然后调用run函数,并且携带了两个参数给run函数
# environ:一个包含所有HTTP请求信息的dict对象;
# response:一个发送HTTP响应的函数。
# 向客户端发送的状态码和头信息
response('200 OK',[('content-type','text/html; charset=utf-8'),])
# 返回的是一个列表,内容是发送给客户端展示的内容
return ['hello world'.encode('utf-8')]
if __name__ == '__main__':
# 相当于socket绑定ip和端口
server = make_server('127.0.0.1',8080,run)
# 实时监听地址,等待客户端连接,有连接来了就调用run函数
server.serve_forever()
wsgiref模块实现上所有述功能的服务端
from wsgiref.simple_server import make_server
import datetime
def index(url):
with open('index页面.html', 'rb') as fr:
data = fr.read()
return data
def home(url):
with open('home页面.html', 'rb') as fr:
data = fr.read()
return data
def get_time(url):
now = datetime.datetime.now().strftime('%Y-%m-%d %X')
with open('get_time.html','r',encoding='utf-8') as fr:
data = fr.read()
data = data.replace('*time*',now)
return data.encode('utf-8')
dic={
'/index':index,
'/home':home,
'/get_time':get_time
}
def run(env,response):
# 发送状态码和头信息到客户端
response('200 ok',[('content-type','text/html;charset=utf-8'),])
# print(env)
# 因为env就是客户端发过来的请求信息(k:v键值对形式),
# 通过打印信息得出PATH_INFO就是请求的url,
url = env.get('PATH_INFO')
print(url)
func = None
if url in dic:
func = dic.get(url)
if func:
res = func(url)
else:
res = b'404 not found!!!'
return [res]
if __name__ == '__main__':
server = make_server('127.0.0.1',8080,run)
server.serve_forever()
jinja2模块
jinja2模块,跟上面的用特殊符号去替换需要展示的内容的原理是一样的,jinja2他将html页面封装成一个可以渲染数据的模板,然后得到我们真正想要返回给浏览器的html页面。
例子:从数据库中获取数据展示到浏览器。
1.创建一张user表:
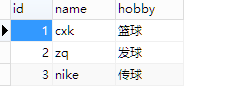
2.创建html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
<link href="https://cdn.bootcss.com/twitter-bootstrap/3.3.1/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.bootcss.com/twitter-bootstrap/3.3.1/js/bootstrap.min.js"></script>
</head>
<body>
<div class="container">
<div class="row">
<div class="col-md-8 col-md-offset-2">
<h1 class="text-center">用户列表</h1>
<table class="table table-bordered table-striped table-hover">
<thead>
<tr>
<th>id</th>
<th>name</th>
<th>pwd</th>
</tr>
</thead>
<tbody>
<!--user_list是渲染的数据 -->
{% for user_dict in user_list %}
<tr>
<td>{{ user_dict.id }}</td>
<td>{{ user_dict.name }}</td>
<td>{{ user_dict.hobby}}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
</div>
</body>
</html>
3.使用jinja2渲染html文件。
from wsgiref.simple_server import make_server
from jinja2 import Template
import pymysql
# 从数据库中获取,并使用jinja2将数据渲染到html
def get_db(url):
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='tomjoy',
password='123456',
database='user_info',
charset='utf8',
autocommit=True
)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = "select * from user"
cursor.execute(sql)
# 1.从数据库中获取数据
res = cursor.fetchall()
with open('get_db.html','r',encoding='utf8') as fr:
data = fr.read()
# 2.生成html渲染模板对象
temp = Template(data)
# 3.将数据库中获取回来的数据,传到html模板对象进行渲染,
# 返回一个我们真正想要展示的html页面
ret = temp.render(user_list=res)
return ret.encode('utf8')
dic = {
'/get_db' : get_db
}
def run(env,response):
response('200 ok',[('content-type','text/html;charset=utf-8'),])
func = None
url = env.get('PATH_INFO')
if url in dic:
func = dic.get(url)
if func:
res = func(url)
else:
res = b'404 not found!!!'
return [res]
if __name__ == '__main__':
server = make_server('127.0.0.1',8080,run)
server.serve_forever()
jinja2模板语法(极其贴近python后端语法)
<p>{{ user }}</p>
<p>{{ user.name }}</p>
<p>{{ user['pwd'] }}</p>
<p>{{ user.get('hobby') }}</p>
{% for user_dict in user_list %}
<tr>
<td>{{ user_dict.id }}</td>
<td>{{ user_dict.name }}</td>
<td>{{ user_dict.pwd }}</td>
</tr>
{% endfor %}
模板渲染:利用模板语法 实现后端传递数据给前端html页面
模板语法书写格式:
变量相关:{{}}
逻辑相关:{%%}
注意:Django的模板语法由于是自己封装好的,只支持 点.取值
注:模板渲染的原理就是字符串替换,我们只要在HTML页面中遵循jinja2的语法规则写上,其内部就会按照指定的语法进行相应的替换,从而达到动态的返回内容。
效果如下:
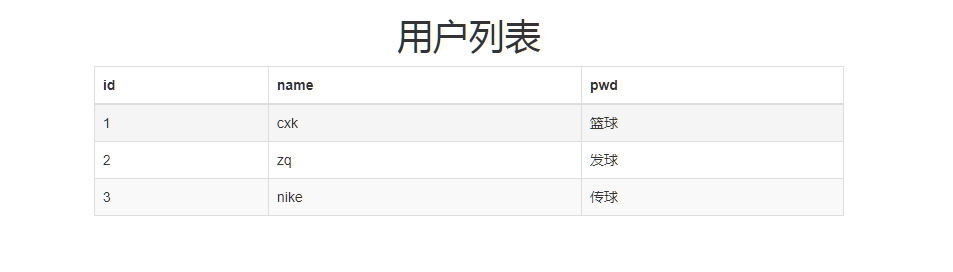
Django
1.安装django
pip3 install django==1.11.11
2.创建django项目
在cmd命令行下创建一个名为mysite的Django项目
django-admin startproject mysite
3.目录介绍
mysite
├── manage.py # Django入口管理文件
└── templates # 存放html文件
└── mysite # 项目目录
├── __init__.py
├── settings.py # 配置
├── urls.py # 路由 --> URL和函数的对应关系
└── wsgi.py # runserver命令就使用wsgiref模块做简单的web server
4.模板文件配置
使用命令行创建django项目 不会自动帮你创建templates文件夹, 只能自己创建
在.settings文件中 需要你手动在TEMPLATES的DIRS写配置
[os.path.join(BASE_DIR, 'templates')]
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates')], # templates 文件夹位置
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
5.启动django项目
python manage.py runserver
6.创建应用app01
python manage.py startapp app01
7.app应用目录:
└── app01 # 项目目录
├── migrations文件夹 # 存放数据库迁移记录
├── __init__.py
├── admin.py # django后台管理
└── apps.py # 注册相关
└── models.py # 模型类
└── tests.py # 测试文件
└── views.py # 存放视图函数
注意:如果是在命令行下创建app后,需要你去settings配置文件中注册添加app名字。这样django项目才能识别到你这个app

8.静态文件配置:
什么是静态文件?
静态文件就是在打开网页时所用到的 图片、 js、css以及第三方的框架bootstrap、fontawesome、sweetalert
通常情况下 网站所用到的静态文件资源 统一都放在static文件夹下,为了方便识别
STATIC_URL = '/static/' # 是访问静态资源的接口前缀,并不是存放静态文件的文件夹
"""只要你想访问静态资源 你就必须以static开头"""
# 手动在settings最底下添加配置静态文件访问资源
# 下面都是存放静态文件的文件夹的路径
# 从上往下找静态文件,找不到就报错
STATICFILES_DIRS = [
os.path.join(BASE_DIR,'static'),
os.path.join(BASE_DIR,'static1'),
os.path.join(BASE_DIR,'static2'),
]
图解:
9.禁用中间件:
前期为了方便表单提交测试。在settings配置文件中暂时禁用csrf中间件
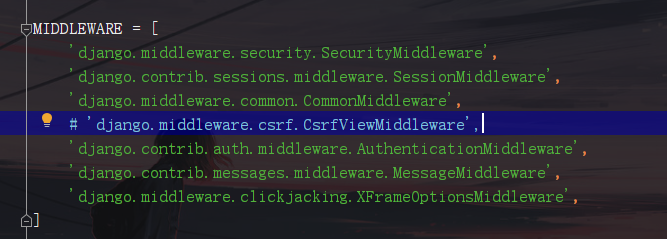
10.重定向:
重定向的意思就是,我访问的链接不是我刚刚输入的那个链接,而是我一输入他就跳转到了另外一个链接,这就是重定向

最后注意事项:
1.计算机的名称不能有中文
2.一个pycharm窗口就是一个项目
3.项目名里面尽量不要用中文
django版本问题
1.X 2.X 现在市面上用的比较多的还是1.X
推荐使用1.11.9~1.11.13
django安装
pip3 install django==1.11.11
如何验证django是否安装成功
命令行直接敲django-admin
一个django项目就类似于是一所大学,而app就类似于大学里面的学院
django其实就是用来一个个应用的
一个app就相当于一块独立的功能
用户功能
管理功能
.........
django支持任意多个app
Django之web框架原理的更多相关文章
- Django安装和web框架原理
Django安装和web框架原理 在PyCharm中安装 在cmd中输入 django-admin startproject 项目名 如果报错 不是内部或外部命令,也不是可运行的程序 需要添加环境变量 ...
- [Python] 利用Django进行Web开发系列(一)
1 写在前面 在没有接触互联网这个行业的时候,我就一直很好奇网站是怎么构建的.现在虽然从事互联网相关的工作,但是也一直没有接触过Web开发之类的东西,但是兴趣终归还是要有的,而且是需要自己动手去实践的 ...
- [Python] 利用Django进行Web开发系列(二)
1 编写第一个静态页面——Hello world页面 在上一篇博客<[Python] 利用Django进行Web开发系列(一)>中,我们创建了自己的目录mysite. Step1:创建视图 ...
- Nginx+Python+uwsgi+Django的web开发环境安装及配置
Nginx+Python+uwsgi+Django的web开发环境安装及配置 nginx安装 nginx的安装这里就略过了... python安装 通常系统已经自带了,这里也略过 uwsgi安装 官网 ...
- 利用Django进行Web开发
Web就是用来表示Internet主机上供外界访问的资源的.网页也统称为web资源.Internet上供外界访问的Web资源主要分为如下两类: 静态web资源:指web页面中供人们浏览的数据始终是不变 ...
- Python第十三天 django 1.6 导入模板 定义数据模型 访问数据库 GET和POST方法 SimpleCMDB项目 urllib模块 urllib2模块 httplib模块 django和web服务器整合 wsgi模块 gunicorn模块
Python第十三天 django 1.6 导入模板 定义数据模型 访问数据库 GET和POST方法 SimpleCMDB项目 urllib模块 urllib2模块 ...
- web理论知识--网页访问过程(附有Django的web项目访问流程)
当我们闲暇之余想上网看看新闻,或者看个电影,通常的操作是:打开电脑.打开浏览器.输入网址.浏览页面信息.点击自己感兴趣的连接......那么有没有想过,这些网页从哪里来的?过程中计算机又做了什么事情了 ...
- Web框架本质及第一个Django实例 Web框架
Web框架本质及第一个Django实例 Web框架本质 我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端. 这样我们就可以自己实现Web ...
- 利用Django构建web应用及其部署
注:很久之前就有了学习Django的想法,最近终于有机会做了一次尝试.由于Django的详细教程很多,我在这里就不再详述了,只是将整个开发流程以及自己在学习Django中的一些思考记录在此. Syst ...
随机推荐
- 【CV现状-1】磨染的初心——计算机视觉的现状:缘起
#磨染的初心--计算机视觉的现状 [这一系列文章是关于计算机视觉的反思,希望能引起一些人的共鸣.可以随意传播,随意喷.所涉及的内容过多,将按如下内容划分章节.已经完成的会逐渐加上链接.] 缘起 三维感 ...
- SpringCloud(三):服务消费以及负载均衡(RestTemplate+Ribbon)
一.什么是Ribbon: Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法. 将Netflix的中间层服务连接在一起.Ribbon客户端组件提供一系列完善的配置项如连 ...
- CSS 解决z-index上层元素遮挡下层元素点击事件问题
解决z-index上层元素遮挡下层元素点击事件问题 by:授客 QQ:1033553122 开发环境 Win 10 element-ui "2.8.2" Vue 2.9.6 需求 ...
- vue-element-admin在install的时候关于sass的错误信息
vue-element-admin在install的是报关于sass的错误信息 今天使用vue-element-admin给自己弄的一个微信小程序编写一个后台管理系统的时候,报关于sass的错误,下载 ...
- Linux下使用docker 拉取 vsftpd 镜像搭建 Ftp 服务器,连接 Ftp 时遇到的错误(425 Failed to establish connection)
Ftp踩坑系列: Linux上的ftp服务器 vsftpd 之配置满天飞--设置匿名用户访问(不弹出用户名密码框)以及其他用户可正常上传 ftp服务器Serv-U 设置允许自动创建不存在的目录 FTP ...
- win10下配置python环境变量(Python配置环境变量)
从官网下载Windows下的python版本,一路按照默认进行安装. 安装之后配置环境变量的步骤如下: 1,点“我的电脑”,右键选“属性”. 2,选择“高级系统设置”--->选“环境变量”--- ...
- CAD制图初学入门如何学好CAD?CAD大神总结5点诀窍,必须收藏
现在有很多的小伙伴们都加入到了CAD这个大家庭中,一开始都是都是一脸懵的状态,更不知要从何入手! 小编才开始也是,但是只要掌握好CAD的技巧和脊髓,一切都不是事.CAD大神总结5点诀窍,悄悄告诉你,必 ...
- laravel开发大型电商网站之异常设计思路分析
令人讨厌的异常 提起异常,大家都很反感,当信心满满的写完一段代码,刷新页面发现上面写着大大的 Exception 是最心烦的时候了.模块给领导演示的时候,如果报了异常,也是最让人崩溃的时候了. 在一般 ...
- Java EE 基本开发流程及数据库连接池 Druid
一. 公司开发基本流程 a. 了解需求信息(比较模糊) 需求,不是别人告诉你的,是你自己挖掘出来的. 售前工程师(对行业知识了解):编程学不好,但懂点代码,对人的综合 ...
- leaflet实现风场图(附源码下载)
前言 leaflet 入门开发系列环境知识点了解: leaflet api文档介绍,详细介绍 leaflet 每个类的函数以及属性等等 leaflet 在线例子 leaflet 插件,leaflet ...