如何利用python爬取网易新闻
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: LSGOGroup
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
学习了python基本语法后,对爬虫产生了很大的兴趣,废话不多说,今天来爬取网易新闻,实战出真知。
打开网易新闻 可以发现新闻分为这样的几个板块:
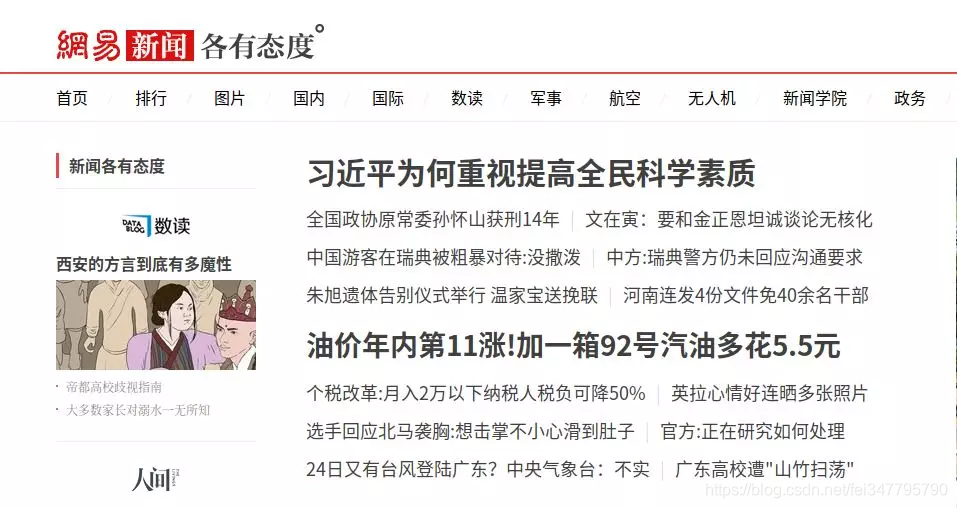
这次选择国内板块来爬取文章。
1. 准备
环境:python3
编译器:PyCharm
安装 selenium 针对三大浏览器驱动 driver
下载地址
chromedriver:
https://code.google.com/p/chromedriver/downloads/listFirefox 的驱动 geckodriver:
https://github.com/mozilla/geckodriver/releases/IE 的驱动 IEdrive:
http://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
了解网页
网页绚丽多彩,美轮美奂,如同一幅水彩画。爬取数据首先需要知道所需要抓取的数据是怎样的呈现的,就像学作一幅画,开始前你要知道这幅画是用什么画出来的,铅笔还是水彩笔…可能种类是多样的,但是放到网页信息来说这儿只有两种呈现方式:
HTML
JSON
HTML是用来描述网页的一种语言
JSON是一种轻量级的数据交换格式
爬取网页信息其实就是向网页提出请求,服务器就会将数据反馈给你
2. 获得动态加载源码
导入需要的用的模块和库:
from bs4 import BeautifulSoup
import time
import def_text_save as dts
import def_get_data as dgd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
获取网页信息需要发送请求,requests 能帮我们很好的完成这件事,但是仔细观察发现网易新闻是动态加载,requests 返回的是即时信息,网页部分稍后加载出来的数据没有返回,这种情况 selenium 能够帮助我们得到更多的数据,我们将 selenium 理解为一个自动化测试工具就好,Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
我使用的浏览器为Firefox
browser = webdriver.Firefox()#根据浏览器切换
browser.maximize_window()#最大化窗口
browser.get('http://news.163.com/domestic/')
这样我们就能驱动浏览器自动登陆网易新闻页面
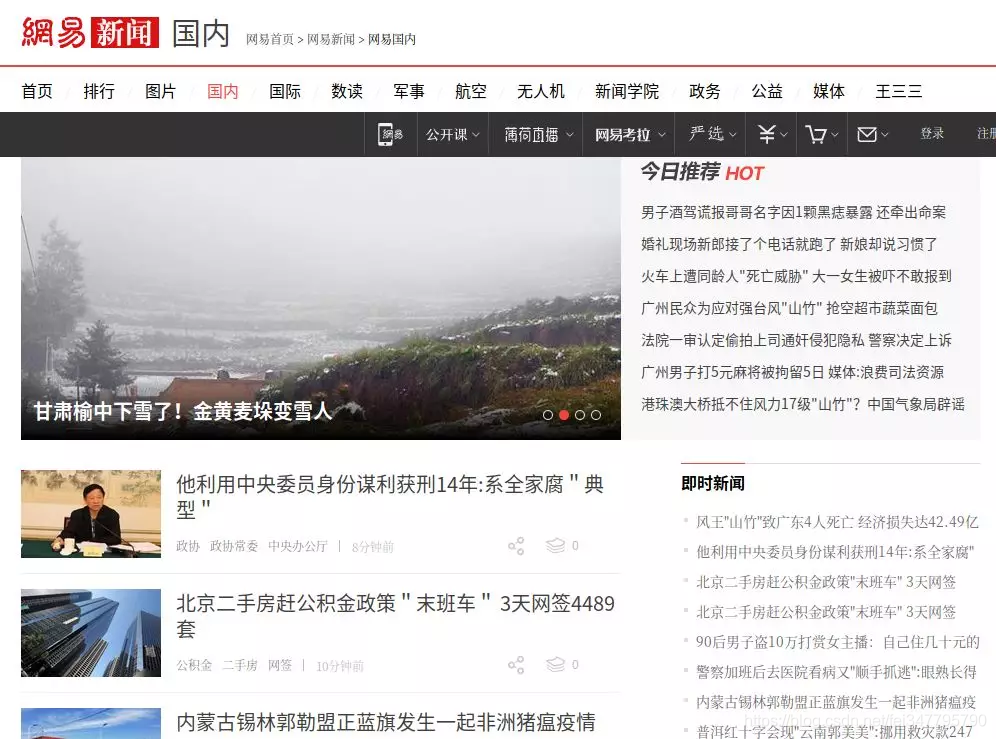
我们的目标自然是一次将国内板块爬取下来,观察网页,在网页不断向下刷时,新的新闻才会加载出来,到最下面甚至还有需要点击按钮才能刷新:
这时使用 selenium 就能展现其优势:自动化,模拟鼠标键盘操作:
diver.execute_script("window.scrollBy(0,5000)")
#使网页向下拉,括号内为每次下拉数值
在网页中右键点击加载更多按钮,点击查看元素,可以看到

通过这个 class 就可以定位到按钮,碰到按钮时,click 事件就能帮助我们自动点击按钮完成网页刷新
# 爬取板块动态加载部分源代码
info1=[]
info_links=[] #存储文章内容链接
try:
while True :
if browser.page_source.find("load_more_btn") != -1 :
browser.find_element_by_class_name("load_more_btn").click()
browser.execute_script("window.scrollBy(0,5000)")
time.sleep(1)
except:
url = browser.page_source#返回加载完全的网页源码
browser.close()#关闭浏览器
获取有用信息
简单来说,BeautifulSoup 是 python 的一个库,最主要的功能是从网页抓取数据,能减轻菜鸟的负担。 通过 BeautifulSoup 解析网页源码,在加上附带的函数,我们能轻松取出想要的信息,例如:获取文章标题,标签以及文本内容超链接 
同样在文章标题区域右键点击查看元素:
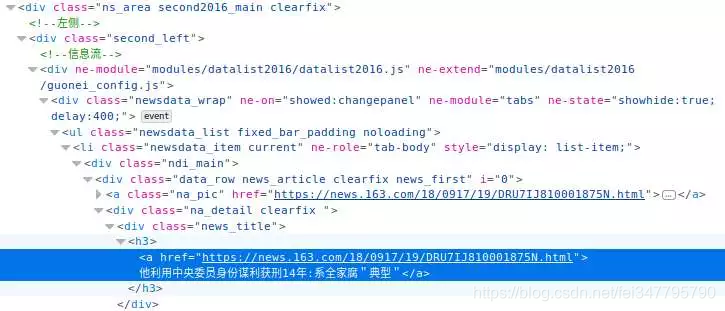
观察网页结构发现每一个div标签class=“news_title" 下都是文章的标题和超链接。soup.find_all()函数能帮我们找到我们想要的全部信息,这一级结构下的内容就能一次摘取出来。最后通过字典,把标签信息,挨个个取出来。
info_total=[]
def get_data(url):
soup=BeautifulSoup(url,"html.parser")
titles=soup.find_all('div','news_title')
labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
for title, label in zip(titles,labels ):
data = {
'文章标题': title.get_text().split(),
'文章标签':label.get_text().split() ,
'link':title.find("a").get('href')
}
info_total.append(data)
return info_total
4. 获取新闻内容
自此,新闻链接已经被我们取出来存到列表里了,现在需要做的就是利用链接得到新闻主题内容。新闻主题内容页面为静态加载方式,requests 能轻松处理:
def get_content(url):
info_text = []
info=[]
adata=requests.get(url)
soup=BeautifulSoup(adata.text,'html.parser')
try :
articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
except :
articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
'p')
for a in articles:
a=a.get_text()
a= ' '.join(a.split())
info_text.append(a)
return (info_text)
使用 try except的原因在于,网易新闻文章在某个时间段前后,文本信息所处位置标签不一样,对不同的情况应作出不同的处理。
最后遍历整个列表取出全部文本内容:
for i in info1 :
info_links.append(i.get('link'))
x=0 #控制访问文章目录
info_content={}# 存储文章内容
for i in info_links:
try :
info_content['文章内容']=dgd.get_content(i)
except:
continue
s=str(info1[x]["文章标题"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
s= ''.join(s.split())
file = '/home/lsgo18/PycharmProjects/网易新闻'+'/'+s
print(s)
dts.text_save(file,info_content['文章内容'],info1[x]['文章标签'])
x = x + 1
存储数据到本地txt文件
python 提供了处理文件的函数open(),第一个参数为文件路径,第二为文件处理模式,"w" 模式为只写(不存在文件则创建,存在则清空内容)
def text_save(filename, data,lable): #filename为写入CSV文件的路径
file = open(filename,'w')
file.write(str(lable).replace('[','').replace(']','')+'\n')
for i in range(len(data)):
s =str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
file.write(s)
file.close()
print("保存文件成功")
一个简单的爬虫至此就编写成功:
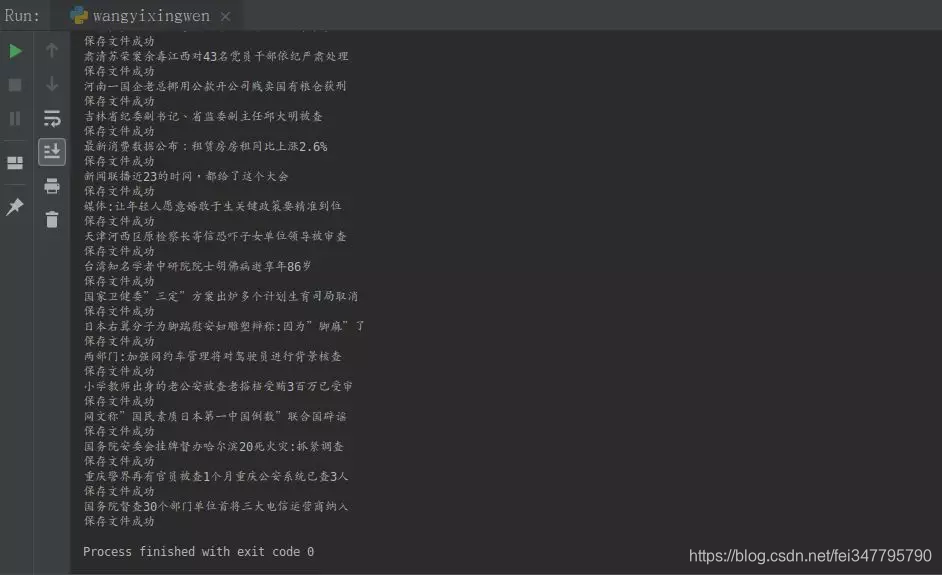
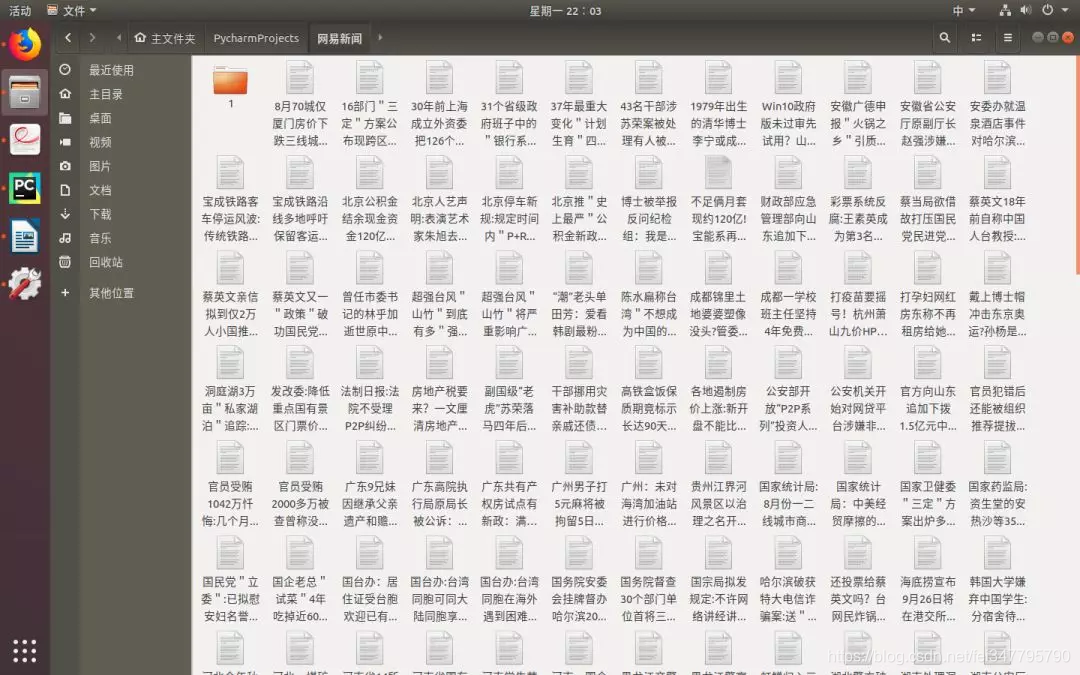
到此为止,爬取网易新闻的方法就介绍完了,希望对大家有用!See You!
如何利用python爬取网易新闻的更多相关文章
- Python爬虫实战教程:爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Amauri PS:如有需要Python学习资料的小伙伴可以加点击 ...
- Python爬虫实战教程:爬取网易新闻;爬虫精选 高手技巧
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. stars声明很多小伙伴学习Python过程中会遇到各种烦恼问题解决不了.为 ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 利用python爬取城市公交站点
利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得 ...
- 利用scrapy抓取网易新闻并将其存储在mongoDB
好久没有写爬虫了,写一个scrapy的小爬爬来抓取网易新闻,代码原型是github上的一个爬虫,近期也看了一点mongoDB.顺便小用一下.体验一下NoSQL是什么感觉.言归正传啊.scrapy爬虫主 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- Python 爬虫实例(4)—— 爬取网易新闻
自己闲来无聊,就爬取了网易信息,重点是分析网页,使用抓包工具详细的分析网页的每个链接,数据存储在sqllite中,这里只是简单的解析了新闻页面的文字信息,并未对图片信息进行解析 仅供参考,不足之处请指 ...
随机推荐
- python强大的绘图模块matplotlib示例讲解
Matplotlib 是 Python 的绘图库.作为程序员,经常需要进行绘图,在我自己的工作中,如果需要绘图,一般都是将数据导入到excel中,然后通过excel生成图表,这样操作起来还是比较繁琐的 ...
- 【带着canvas去流浪(9)】粒子动画
目录 一. 粒子特效 二. 开发中遇到的问题 2.1 卡顿 2.2 轨迹 2.3 复位 2.4 防护层 2.5 二维向量类 三. 实现讲解 3.1 粒子类的update方法 3.2 粒子群的绘制 3. ...
- 文件批量生成IO流读写
/// <summary> /// 生成文件的 /// </summary> /// <param name="calssName"></ ...
- fluwx使用的问题
今天搞了下fluwx这个库,也是遇到了很多问题. 问题一:‘包名不对,请检查包名是否与开放平台上填写的一致’ 显示把文档这些看了遍,但是也不是很清楚,还加了下群问别人,主要我没有开发过Android, ...
- Jackson version is too old 2.xx
我使用的是IDEA,很简单. 切换到project,如果下面的module版本是2.65,上面的jackson.core.xx小于2.65就会报old,如果高于2.65就会报不兼容. 所以调整成相同的 ...
- linux学习(七)Shell编程中的变量
目录 shell编程的建立 shell的hello world! Shell的环境变量 使用和设置环境变量 Shell的系统变量 用户自定义变量 @(Shell编程) shell编程的建立 [root ...
- bayaim_mysql5.6下table_open_cache参数
bayaim_mysql5.6下table_open_cache参数_2017年12月26日10:51:58 原创 作者:bayaim 时间:2017-12-26 10:57:17 1 0删除编辑 ( ...
- Resolving RMAN-06023 or RMAN-06025 (Doc ID 2038119.1)
Resolving RMAN-06023 or RMAN-06025 (Doc ID 2038119.1) APPLIES TO: Oracle Database - Enterprise Editi ...
- elasticsearch安装与使用
一.windows10上安装elasticsearch Elasticsearch 需要 Java环境,在安装Elasticsearch之前先安装好JDK. 本文安装jdk1.8,es6.3.2为例. ...
- python3 邮件方式发送测试报告
以邮件方式发送测试报告 import smtplib from email.mime.text import MIMEText class SendEmail: """邮 ...