Linux内核链表复用实现栈
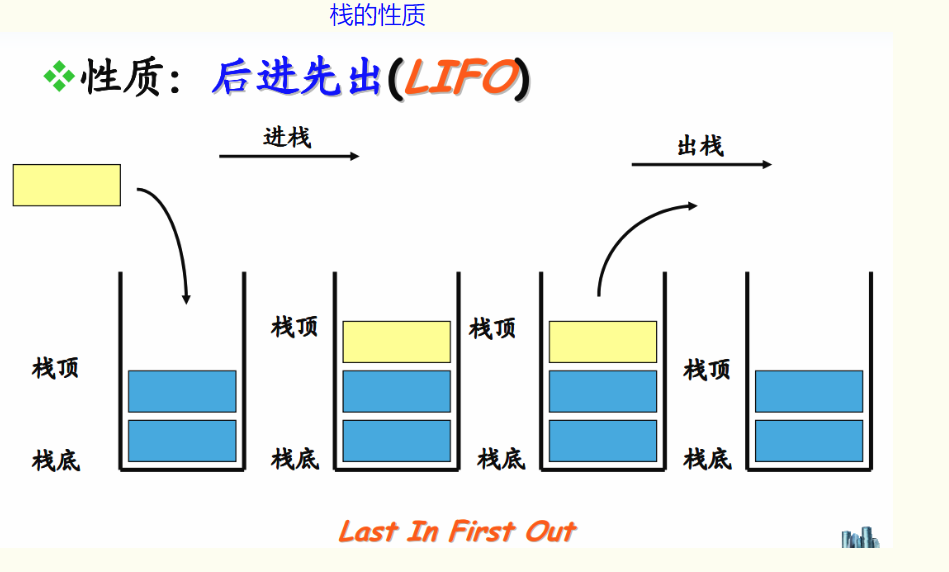
我们当然可以根据栈的特性,向实现链表一样实现栈。但是,如果能够复用已经经过实践证明的可靠数据结构来实现栈,不是可以更加高效吗?
so,今天我们就复用Linux内核链表,实现栈这样的数据结构。
要实现的功能很简单,如下(项目中如需更多功能,可自行添加):
/* stack.h */ #ifndef _STACK_H_
#define _STACK_H_ #include "list.h" #define get_stack_top(pos, head, member) \
list_entry((head)->prev, typeof(*pos), member) void stack_creat(struct list_head *list);
void stack_push(struct list_head *new, struct list_head *head);
void stack_pop(struct list_head *entry);
int get_satck_size(struct list_head *head); #endif /* _STACK_H_ */
/* stack.c */ #include "stack.h" void list_del_tail(struct list_head *head)
{
__list_del(head->prev->prev,head);
} void stack_creat(struct list_head *list)
{
INIT_LIST_HEAD(list);
} void stack_push(struct list_head *new, struct list_head *head)
{
list_add_tail(new,head);
} void stack_pop(struct list_head *head)
{
struct list_head *list = head->prev; /* 保存链表的最后节点 */ list_del_tail(head); /* 尾删法 */ INIT_LIST_HEAD(list); /* 重新初始化删除的最后节点,使其指向自身 */ } int get_satck_size(struct list_head *head)
{
struct list_head *pos;
int size = ; if (head == NULL) {
return -;
} list_for_each(pos,head) {
size++;
} return size;
}
我们先来说,栈的创建:

非常简单,和内核链表一样,仅仅是将链表指针指向自身。
栈的push(入栈)操作:

也非常得简单,根据栈的先进后出特性,我们采用尾插法,这样最后插入的节点也就位于最后,也就是栈顶。
栈的pop(出栈)操作:


出栈只能操作栈顶元素,所以我们使用尾删法,将内核链表的尾部节点删除,就实现了出栈操作,但是内核链表没有直接实现尾删法,不过,我们已经在前面的随笔中对内核链表进行了分析,显然可以利用内核已经实现了的__list_del函数,稍微改变一下参数,就可以实现尾删法了。
获取栈的大小:

原理也非常简单,循环遍历链表,计数增加即可。
得到栈顶元素:

为什么这里我没有使用函数,而是使用宏呢?这和内核链表的逻辑是一致的。因为如果要写成函数,我必须知道使用栈的人定义的数据类型,如果我定义成void *,又不能使用内核链表的list_entry获取容器结构地址的宏了,所以,我将获取栈顶元素设计为宏,这样我可以不定义数据类型,靠用户输入。
现在,我们通过非常简单的一点代码复用内核链表实现了栈,下面看看测试用例:
#include <stdio.h>
#include <stdlib.h> #include "stack.h"
#include "list.h" struct person
{
int age;
struct list_head list;
}; int main(int argc,char **argv)
{
int i;
int num =;
struct person *p;
struct person head;
struct person *pos,*n; stack_creat(&head.list); p = (struct person *)malloc(sizeof(struct person )*num); for (i = ;i < num;i++) {
p->age = i*;
stack_push(&p->list,&head.list);
p++;
} struct person test;
test.age = ; stack_pop(&head.list);
stack_pop(&head.list);
stack_push(&test.list,&head.list); printf("==========>\n");
list_for_each_entry_safe_reverse(pos,n,&head.list,list) {
printf("%p age = %d\n",pos,pos->age);
} printf("栈顶节点:%p age = %d\n",get_stack_top(pos,&head.list,list),
get_stack_top(pos,&head.list,list)->age);
printf("size = %d\n",get_satck_size(&head.list)); return ;
}
运行结果:

通过复用内核链表,可以非常快速高效地实现很多其他数据结构,所以内核链表一定要充分掌握。
增加判断栈是否为空的函数:
bool is_empt_stack(struct list_head *head)
{
return list_empty(head);
}
c语言中bool可以包含#include <stdbool.h>,c99可以直接使用_Bool。
Linux内核链表复用实现栈的更多相关文章
- Linux内核链表复用实现队列
有了前面Linux内核复用实现栈的基础,使用相同的思想实现队列,也是非常简单的.普通单链表复用实现队列,总会在出队或入队的时候有一个O(n)复杂度的操作,大多数采用增加两个变量,一个head,一个ta ...
- 链表的艺术——Linux内核链表分析
引言: 链表是数据结构中的重要成员之中的一个.因为其结构简单且动态插入.删除节点用时少的长处,链表在开发中的应用场景许多.仅次于数组(越简单应用越广). 可是.正如其长处一样,链表的缺点也是显而易见的 ...
- Linux 内核 链表 的简单模拟(1)
第零章:扯扯淡 出一个有意思的题目:用一个宏定义FIND求一个结构体struct里某个变量相对struc的编移量,如 struct student { int a; //FIND(struct stu ...
- C语言 Linux内核链表(企业级链表)
//Linux内核链表(企业级链表) #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<stdlib.h> ...
- 深入分析 Linux 内核链表--转
引用地址:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/index.html 一. 链表数据结构简介 链表是一种常用的组织有序数据 ...
- Linux 内核链表
一 . Linux内核链表 1 . 内核链表函数 1.INIT_LIST_HEAD:创建链表 2.list_add:在链表头插入节点 3.list_add_tail:在链表尾插入节点 4.list_d ...
- linux内核链表分析
一.常用的链表和内核链表的区别 1.1 常规链表结构 通常链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,指针域用于建立与下一个节点的联系.按照指针域的组织以及各个节 ...
- 深入分析 Linux 内核链表
转载:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/ 一. 链表数据结构简介 链表是一种常用的组织有序数据的数据结构,它通过指 ...
- Linux 内核 链表 的简单模拟(2)
接上一篇Linux 内核 链表 的简单模拟(1) 第五章:Linux内核链表的遍历 /** * list_for_each - iterate over a list * @pos: the & ...
随机推荐
- linux设备驱动程序-设备树(3)-设备树多级子节点的转换
linux设备驱动程序--设备树多级子节点的转换 在上一章:设备树处理之--device_node转换成platform_device中,有提到在设备树的device_node到platform_de ...
- Pat 1003 甲级
#include <cstdlib> #include <cstring> #include <iostream> #include <cstdio> ...
- springboot集成ftp
目录 springboot集成ftp pom依赖包 ftp登录初始化 ftp上传文件 ftp读取文件,并转成base64 ftp下载文件 ftp客户端与服务端之间数据传输,主动模式和被动模式 spri ...
- Laravel5.4框架中视图共享数据的方法详解
本文实例讲述了Laravel5.4框架中视图共享数据的方法.分享给大家供大家参考,具体如下: 每个人都会遇到这种情况:某些数据还在每个页面进行使用,比如用户信息,或者菜单数据,最基本的做法是在每个视图 ...
- vue 实战总结
相对angular 和react ,本人比较喜欢vue,现在的工作项目也在用vue,前两个有朋友在问我在使用vue中有没有遇到一些很难解决的问题,一下我也只能说出一两个,所以索性就抽时间总结一下我在项 ...
- curl多线程下载类
<?php /** * curl多线程下载类 */class MultiHttpRequest{ public $urls = array (); private $res = array () ...
- mr-jobhistory-daemon.sh 查看mr的历史任务
这个脚本的服务是实现web查看作业的历史运行情况.有些情况下,作业运行完了,在web端就无法查看运行情况. 可以通过开启这个的守护进程来达到查看历史任务. 启动命令为 mr-jobhistory-da ...
- gettid和pthread_self区别
http://blog.csdn.net/rsyp2008/article/details/45150621 1 线程ID获取方法 Linux下获取线程有两种方法: 1)gettid或者类似getti ...
- [Android] Android studio gradle 插件的版本号和 gradle 的版本号 的对应关系
[Android] Android studio gradle 插件的版本号和 gradle 的版本号 的对应关系 本博客地址: wukong1688 本文原文地址:https://www.cnblo ...
- 几种npm install 的区别
一个node package有两种依赖,一种是dependencies,一种是devDependencies,其中前者依赖的项该是正常运行该包时所需要的依赖项,而后者则是开发的时候需要的依赖项,像一些 ...