[数据结构 - 第3章] 线性表之双向链表(C语言实现)
一、什么是双向链表?
双向链表(double linked list)是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
既然单链表也可以有循环链表,那么双向链表当然也可以是循环表。
线性表的双向链表存储结构如下:
typedef int ElemType;
typedef struct DulNode
{
ElemType data; //数据域
DulNode *prior; //指向前驱结点的指针
DulNode *next; //指向后继结点的指针
}DulNode, DulList;
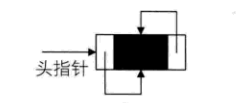
双向链表的循环、带头结点的空链表如下:
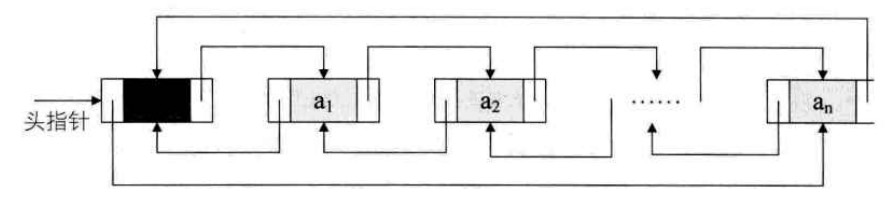
非空、循环、带头结点的双向链表如下:
二、双向链表的基本操作
2.1 插入操作
双向链表的插入操作:
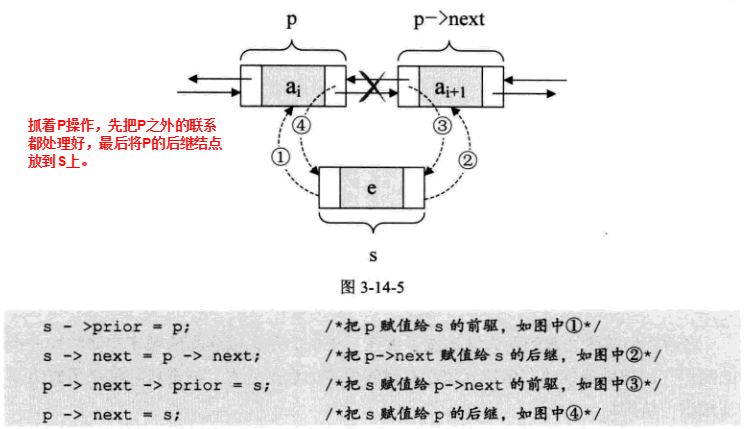
实现代码如下:
// 插入元素操作
Status insertList(DulList *pList, int i, const ElemType e)
{
// 判断链表是否存在
if (!pList)
{
printf("list not exist!\n");
return FALSE;
}
// 只能在位置1以及后面插入,所以i至少为1
if (i < 1)
{
printf("i is invalid!\n");
return FALSE;
}
// 找到i位置所在的前一个结点
Node *front = pList; // 这里是让front与i不同步,始终指向j对应的前一个结点
for (int j = 1; j < i; j++) // j为计数器,赋值为1,对应front指向的下一个结点,即插入位置结点
{
front = front->next;
if (front == NULL)
{
printf("dont find front!\n");
return FALSE;
}
}
// 创建一个空节点,存放要插入的新元素
Node *temp = (Node *)malloc(sizeof(Node));
if (!temp)
{
printf("malloc error!\n");
return FALSE;
}
temp->data = e;
// 插入结点
temp->prior = front;
temp->next = front->next;
// 当空链表第一次插入结点时,此时head->next = NULL,调用NULL->prior会出错
if (front->next != NULL)
front->next->prior = temp;
front->next = temp;
return TRUE;
}
注意当空链表第一次插入结点的特殊情况。
2.2 删除操作
双向链表的删除操作:
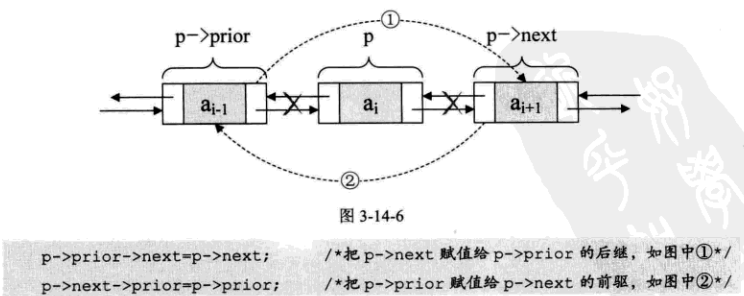
实现代码如下:
// 删除元素操作
Status deleteList(DulList *pList, int i, ElemType *e)
{
// 判断链表是否存在
if (!pList)
{
printf("list not exist!\n");
return FALSE;
}
// 只能删除位置1以及以后的结点
if (i < 1)
{
printf("i is invalid!\n");
return FALSE;
}
// 找到i位置所在的前一个结点
Node *front = pList; // 这里是让front与i不同步,始终指向j对应的前一个结点
for (int j = 1; j < i; j++) // j为计数器,赋值为1,对应front指向的下一个结点,即插入位置结点
{
front = front->next;
if (front->next == NULL)
{
printf("dont find front!\n");
return FALSE;
}
}
// 提前保存要删除的结点
Node *temp = front->next;
*e = temp->data; // 将要删除结点的数据赋给e
// 删除结点
if (front->next->next != NULL) // 删除的不是尾结点,才进入
{
front->next->prior = front;
}
front->next = front->next->next;
// 销毁结点
free(temp);
temp = NULL;
return TRUE;
}
注意:当双向链表的空链表第一次插入结点时,或者在尾结点后插入或删除的特殊情况,不需要设置插入位置后一个结点的直接前驱指针,因为此时插入位置的后一个结点为 NULL。
三、完整程序
#include <stdio.h>
#include <stdlib.h>
#define TRUE 1
#define FALSE 0
typedef int Status; // Status是函数结果状态,成功返回TRUE,失败返回FALSE
typedef int ElemType;
// 双向非循环链表的结构定义
typedef struct Node
{
ElemType data; //数据域
Node *prior; //指向前驱结点的指针
Node *next; //指向后继结点的指针
}Node, DulList;
void initList(DulList **pList); // 初始化链表操作
Status insertList(DulList *pList, int i, const ElemType e); // 插入元素操作
Status deleteList(DulList *pList, int i, ElemType *e); // 删除元素操作
Status getElem(DulList *pList, int i, ElemType *e); // 获取元素操作
Status insertListHead(DulList *pList, const ElemType e); // 头部后插入元素操作
Status insertListTail(DulList *pList, const ElemType e); // 尾部后插入元素操作
Status clearList(DulList *pList); // 清空链表操作
void traverseList(DulList *pList); // 遍历链表操作
int getLength(DulList *pList); // 获取链表长度操作
// 初始化链表操作
void initList(DulList **pList) // 必须使用双重指针,一重指针申请会出错
{
*pList = (DulList *)malloc(sizeof(Node));
if (!pList)
{
printf("malloc error!\n");
return;
}
(*pList)->data = 0;
(*pList)->prior = NULL;
(*pList)->next = NULL;
}
// 插入元素操作
Status insertList(DulList *pList, int i, const ElemType e)
{
// 判断链表是否存在
if (!pList)
{
printf("list not exist!\n");
return FALSE;
}
// 只能在位置1以及后面插入,所以i至少为1
if (i < 1)
{
printf("i is invalid!\n");
return FALSE;
}
// 找到i位置所在的前一个结点
Node *front = pList; // 这里是让front与i不同步,始终指向j对应的前一个结点
for (int j = 1; j < i; j++) // j为计数器,赋值为1,对应front指向的下一个结点,即插入位置结点
{
front = front->next;
if (front == NULL)
{
printf("dont find front!\n");
return FALSE;
}
}
// 创建一个空节点,存放要插入的新元素
Node *temp = (Node *)malloc(sizeof(Node));
if (!temp)
{
printf("malloc error!\n");
return FALSE;
}
temp->data = e;
// 插入结点
temp->prior = front;
temp->next = front->next;
// 当空链表第一次插入结点时,此时head->next = NULL,调用NULL->prior会出错
if (front->next != NULL)
front->next->prior = temp;
front->next = temp;
return TRUE;
}
// 删除元素操作
Status deleteList(DulList *pList, int i, ElemType *e)
{
// 判断链表是否存在
if (!pList)
{
printf("list not exist!\n");
return FALSE;
}
// 只能删除位置1以及以后的结点
if (i < 1)
{
printf("i is invalid!\n");
return FALSE;
}
// 找到i位置所在的前一个结点
Node *front = pList; // 这里是让front与i不同步,始终指向j对应的前一个结点
for (int j = 1; j < i; j++) // j为计数器,赋值为1,对应front指向的下一个结点,即插入位置结点
{
front = front->next;
if (front->next == NULL)
{
printf("dont find front!\n");
return FALSE;
}
}
// 提前保存要删除的结点
Node *temp = front->next;
*e = temp->data; // 将要删除结点的数据赋给e
// 删除结点
if (front->next->next != NULL) // 删除的不是尾结点,才进入
{
front->next->prior = front;
}
front->next = front->next->next;
// 销毁结点
free(temp);
temp = NULL;
return TRUE;
}
// 获取元素操作
Status getElem(DulList *pList, int i, ElemType *e)
{
// 判断链表是否存在
if (!pList)
{
printf("list not exist!\n");
return FALSE;
}
// 只能获取位置1以及以后的元素
if (i < 1)
{
printf("i is invalid!\n");
return FALSE;
}
// 找到i位置所在的结点
Node *cur = pList->next; // 这里是让cur指向链表的第1个结点,与j同步
for (int j = 1; j < i; j++) // j为计数器,赋值为1,对应cur指向结点
{
cur = cur->next;
if (cur == NULL)
{
printf("dont find front!\n");
return FALSE;
}
}
// 取第i个结点的数据
*e = cur->data;
return TRUE;
}
// 头部后插入元素操作
Status insertListHead(DulList *plist, const ElemType e)
{
Node *head;
Node *temp;
// 判断链表是否存在
if (!plist)
{
printf("list not exist!\n");
return false;
}
// 让head指向链表的头结点
head = plist;
// 创建存放插入元素的结点
temp = (Node *)malloc(sizeof(Node));
if (!temp)
{
printf("malloc error!\n");
return false;
}
temp->data = e;
// 头结点后插入结点
temp->prior = head;
temp->next = head->next;
// 当空链表第一次插入结点时,此时head->next = NULL,调用NULL->prior会出错
if (head->next != NULL)
head->next->prior = temp;
head->next = temp;
return true;
}
// 尾部后插入元素操作
Status insertListTail(DulList *pList, const ElemType e)
{
Node *cur;
Node *temp;
// 判断链表是否存在
if (!pList)
{
printf("list not exist!\n");
return FALSE;
}
// 找到链表尾节点
cur = pList;
while (cur->next)
{
cur = cur->next;
}
// 创建存放插入元素的结点
temp = (Node *)malloc(sizeof(Node));
if (!temp)
{
printf("malloc error!\n");
return -1;
}
temp->data = e;
// 尾结点后插入结点
temp->prior = cur;
temp->next = cur->next;
cur->next = temp; // 尾结点的直接后继指针是NULL,所以不用指定NULL的前驱指针
return TRUE;
}
// 清空链表操作
Status clearList(DulList *pList)
{
Node *cur; // 当前结点
Node *temp; // 事先保存下一结点,防止释放当前结点后导致“掉链”
// 判断链表是否存在
if (!pList)
{
printf("list not exist!\n");
return FALSE;
}
cur = pList->next; // 指向第一个结点
while (cur)
{
temp = cur->next; // 事先保存下一结点,防止释放当前结点后导致“掉链”
free(cur); // 释放当前结点
cur = temp; // 将下一结点赋给当前结点p
}
pList->next = NULL; // 头结点指针域指向空
return TRUE;
}
// 遍历链表操作
void traverseList(DulList *pList)
{
// 判断链表是否存在
if (!pList)
{
printf("list not exist!\n");
return;
}
Node *cur = pList->next;
while (cur != NULL)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
// 获取链表长度操作
int getLength(DulList *pList)
{
Node *cur = pList;
int length = 0;
while (cur->next)
{
cur = cur->next;
length++;
}
return length;
}
int main()
{
DulList *pList;
// 初始化链表
initList(&pList);
printf("初始化链表!\n\n");
// 尾部后插入结点
printf("尾部后插入元素1、2、3\n\n");
for (int i = 0; i < 3; i++)
{
insertListTail(pList, i+1);
}
// 头部后插入元素
insertListHead(pList, 5);
printf("头部后插入元素5\n\n");
// 插入结点
insertList(pList, 1, 9);
printf("在位置1插入元素9\n\n");
// 遍历链表并显示元素操作
printf("遍历链表:");
traverseList(pList);
printf("\n");
// 删除结点
int val;
deleteList(pList, 2, &val);
printf("删除位置2的结点,删除结点的数据为: %d\n", val);
printf("\n");
// 遍历链表并显示元素操作
printf("遍历链表:");
traverseList(pList);
printf("\n");
// 获得链表长度
printf("链表长度: %d\n\n", getLength(pList));
// 销毁链表
clearList(pList);
printf("销毁链表\n\n");
return 0;
}
输出结果如下图所示:
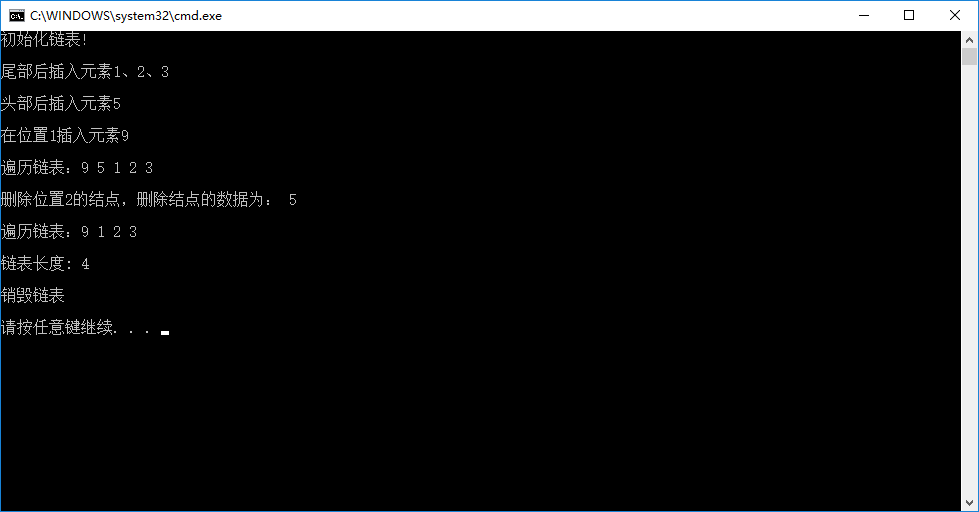
参考:
《大话数据结构 - 第3章》 线性表
[数据结构 - 第3章] 线性表之双向链表(C语言实现)的更多相关文章
- [数据结构 - 第3章] 线性表之单链表(C++实现)
一.类定义 单链表类的定义如下: #ifndef SIGNALLIST_H #define SIGNALLIST_H typedef int ElemType; /* "ElemType类型 ...
- [数据结构 - 第3章] 线性表之顺序表(C++实现)
一.类定义 顺序表类的定义如下: #ifndef SEQLIST_H #define SEQLIST_H typedef int ElemType; /* "ElemType类型根据实际情况 ...
- (续)线性表之双向链表(C语言实现)
在前文实现单向链表的基本操作下,本文实现双向链表的基本操作. 双向链表与单链表差异,是双向链表结点中有前向指针和后向指针.所以在插入和删除新结点元素时候不见要考虑后向指针还要考虑前向指针. 以下是双向 ...
- 【数据结构与算法】线性表操作(C语言)
#include <stdio.h> #include <stdlib.h> #define OK 1 #define NO 0 #define MAXSIZE 20 type ...
- 第2章 线性表《C#数据结构和算法》
( )除第一个位置的数据 元素外,其它数据元素位置的前面都只有一个数据元素:( )除最后一个位置的 数据元素外,其它数据元素位置的后面都只有一个元素.也就是说,数据元素是 一个接一个的排列.因此,可以 ...
- 数据结构(c语言版,严蔚敏)第2章线性表
弟2章线性表
- c/c++ 线性表之双向链表
c/c++ 线性表之双向链表 线性表之双向链表 不是存放在连续的内存空间,链表中的每个节点的next都指向下一个节点,每个节点的before都指向前一个节点,最后一个节点的下一个节点是NULL. 真实 ...
- 【Java】 大话数据结构(5) 线性表之双向链表
本文根据<大话数据结构>一书,实现了Java版的双向链表. 在每个数据结点中都有两个指针,分别指向直接后继和直接前驱,这样的链表称为双向链表. 双向链表的结构如图所示: 查找元素可以根据元 ...
- C语言数据结构——第二章 线性表
二.线性表 2.1-线性表简介 2.1.1-线性表的定义 线性表是由若干个相同特性的数据元素组成的有限序列.若该线性表不包含任何元素,则称为空表,此时长度为0,当线性表不为空时,表中的元素的个数就是线 ...
随机推荐
- 【Postgres】Windows2012 不能启动
PG启动错误-不知道什么错误 等待 postgresql-x64- 服务的连接超时( 毫秒). 由于下列错误,postgresql-x64- 服务启动失败: 服务没有及时响应启动或控制请求. 编写ba ...
- Codechef July Challenge 2019 Snake and Apple Tree
费用流.把每个方格拆成 $T$ 个点,$t$ 时刻一个方格向周围四个方格的 $t + 1$ 的点连一条容量为 $1$ 费用为 $0$ 的边,向自身的 $t + 1$ 连一条容量为 $1$ 费用为该方格 ...
- 异常STATUS_FATAL_APP_EXIT(0x40000015)
简介 STATUS_FATAL_APP_EXIT,值为0x40000015.代表的意思是"致命错误,应用退出".它定义在 ntstatus.h头文件里,如下: //// Messa ...
- 2.深入学习Servlet的ServletContext对象
一.建立项目servlet01 在入门Servlet项目中建立一个子项目模块(此处不再赘述如何建立),补全maven项目中的java和resources文件夹,添加类HelloServlet.java ...
- 牛客网 牛客练习赛4 A.Laptop-二维偏序+离散化+树状数组
A.Laptop 链接:https://ac.nowcoder.com/acm/contest/16/A来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 131072K,其 ...
- nginx之系统参数优化
系统参数优化 默认的Linux内核参数考虑的是最通用场景,不符合用于支持高并发访问的Web服务器的定义,根据业务特点来进行调整,当Nginx作为静态web内容服务器.反向代理或者提供压缩服务器的服务器 ...
- x64汇编第二讲,复习x86汇编指令格式,学习x64指令格式
目录 x64汇编第二讲,复习x86汇编指令格式,学习x64指令格式 一丶x86指令复习. 1.1什么是x86指令. 1.2 x86与x64下的通用寄存器 1.3 OpCode 1.4 7种寻址方式 二 ...
- Django 数据库与ORM
一.数据库的配置 1 django默认支持sqlite,mysql, oracle,postgresql数据库. <1> sqlite django默认使用sqlite的数据库,默认自带 ...
- SpringBoot上传文件到本服务器 目录与jar包同级问题
目录 前言 原因 实现 不要忘记 最后的封装 Follow up 前言 看标题好像很简单的样子,但是针对使用jar包发布SpringBoot项目就不一样了.当你使用tomcat发布项目的时候,上传 ...
- return、reutrn false、e.preventDefault、e.stopPropagation、e.stopImmediatePropagation的区别
return var i = function(){ return } console.log(i())//undefined return的主要作用是阻止函数继续执行,直接返回undefined r ...