hive介绍及架构设计
hive介绍及架构设计
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
我们知道MapReduce和Spark它们提供了高度抽象的编程接口便于用户编写分布式程序,它们具有极好的扩展性和容错性,能够处理超大规模的数据集。这些计算引擎提供了面向高级语言(比如Java,Python等)的编程接口,然而,考虑到分布式程序编写的复杂性,直接使用这些编程接口实现应用系统(比如报表系统)无疑会提高使用门槛,降低开发效率。考虑到SQL仍然是一种非常主流的数据分析语言,开源社区在分布式计算框架基础山构建了支持SQL的引擎,其中典型的代表是MapReduce之上的Hive以及Spark之上的Spark SQL,这些数据分析引擎通常不支持标准得到SQL,而是对SQL进行了选择性支持,并进行了适当扩展,其中最主流的数据分析语言为HQL(Hive Query Language)。
简而言之,Hive是对非Java,python等编程者对hdfs数据做MapReduce操作。
一.概述
1>.背景
大数据计算引擎为大规模数据处理提供了解决方案,它们提供了高级编程语言(比如Java,Python等)编程接口,可让程序员很容易表达计算逻辑。但在大数据领域,仅提供对编程语言的支持是不够的,这会降低一些数据分析场景(比如报表系统)下的开发效率,也提高了使用门槛。
为了让更多人使用这些大数据引擎分析数据,提高系统开发效率,大数据系统引入了对SQL的支持。SQL作为一种主流的数据分析语言,仍广受数据分析师欢迎,主要原因如下:
(1)SQL能够跟现有系统进行很好的集成,现有的有JDBC/ODBC BI系统兼容。
(2)很多工程师习惯使用SQL。
(3)相比于MapReduce和Spark等,SQL更容易表达。
需要注意的是,大数据SQL引擎通常不支持标准SQL。大数据SQL主要是面向数据分析(另外一类是面向事务)的,支持绝大部分标准SQL语法,并进行了适当扩展。
为了让大家更高效地使用MapReuce和Spark等计算引擎,开源社区在计算引擎基础上构建了更高级的SQL引擎,其中典型的代表是Hive和Spark SQL。Hive提供的查询语言被成为“HQL”(Hive Query Language),该语言的跟标准的SQL语法极为相似,已经掌握SQL的工程师可以很容易学习HQL;Spark SQL提供的查询语言接近HQL,但在个别语法上稍有不同。
2>SQL On Hadoop
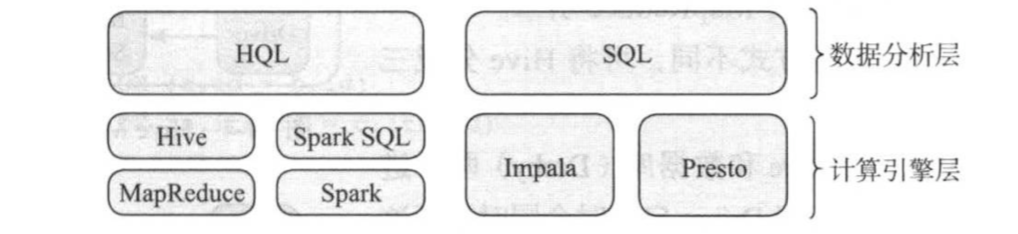
如下图所示,目前构建在Hadoop之上的SQL引擎主要分为两类,基于计算引擎和基于MPP架构:
(1)基于计算引擎
这些SQL引擎是在计算引擎基础上构建的,其基本原理是将SQL语聚翻译成分布式应用程序,之后运行在集群中。典型的代表有构建在MapReduce之上的Hive和构建在Spark之上的Spark SQL。这类SQL引擎的特点是具有良好的扩展性和容错性,能够应对海量数据。
(2)基于MPP架构
这些SQL引擎是基于MPP架构构建的,其基本原理是将SQL翻译成可分布式执行的任务,采用Volcano风格的计算引擎并处理这些任务,任务之间的数据流动和交换由专门的Exchange运算符完成。典型的代表有Presto和Impala等。这些SQL引擎具有良好的可扩展性,但容错性较差。
二.Hive架构
Hive是构建在分布式计算框架之上的SQL引擎,它重用了Hadoop中的分布式存储系统HDFS/HBase和分时计算框架MapReduce/Tez/Spark等。Hive是Hadoop生态系统中的重要部分,目前是应用最广泛的SQL On Hadoop解决方案。
1>.Hive基本架构
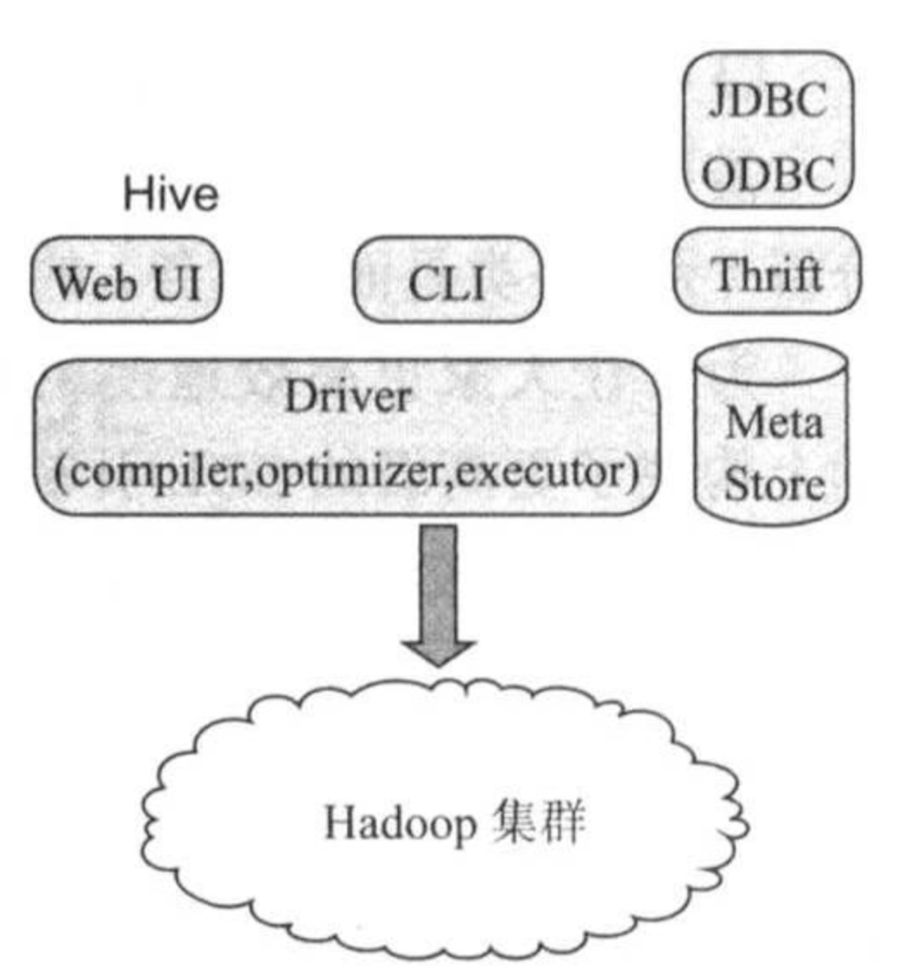
Hive对外提供了三种访问方式,包括Web UI,CLI(Client Line Interface)和Thrift协议(支持JDBC/ODBC),而在Hive后端,主要包括三个服务组件构成,如下图所示:
(1)Driver(驱动器)
与关系型数据库的查询引擎类似,Driver实现了SQL解析,生成逻辑计划,物理计划,查询优化与执行等,它的输入是SQL语句,输出为一系列分布式执行程序(可以为MapReduce,Tez或Spark等)。
(2)Metastore
Hive Metastore是管理和存储元信息的服务,它保存了数据库的基本信息以及数据表的定义等,为了能够可靠地保存这些元信息,Hive Metastore一般将它们持久化到关系型数据库中,默认采用了嵌入式数据库Derby(数据存放在内存中),用户可以根据需要启用其他数据库,比如MySQL。
(3)Hadoop
Hive依赖与Hadoop,包括分布式文件系统HDFS,分布式资源管理系统YARN以及分布式计算引擎MapReduce,Hive中的数据表对应的数据存放在HDFS上,计算资源由YARN分配,而计算任务则来自MapReduce引擎。
根据访问方式不同,可将Hvie分成三种部署模式,即嵌入式不模式,本地模式和远程模式。
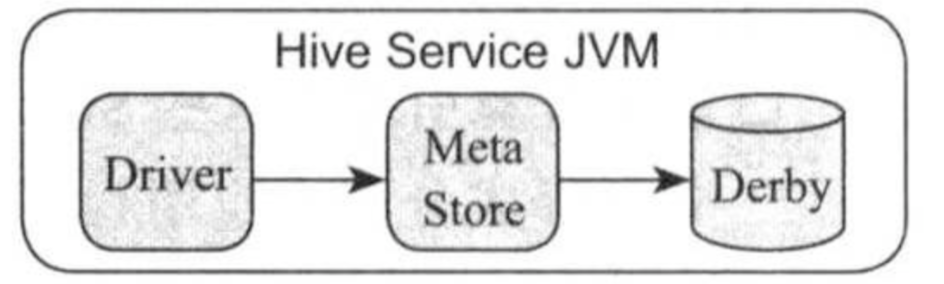
如上图所示,在嵌入式模式中,Metasotre和数据库(Derby)两个进程嵌入到Driver中,当Driver启动时会同时运行这两个进程,一般用于测试。
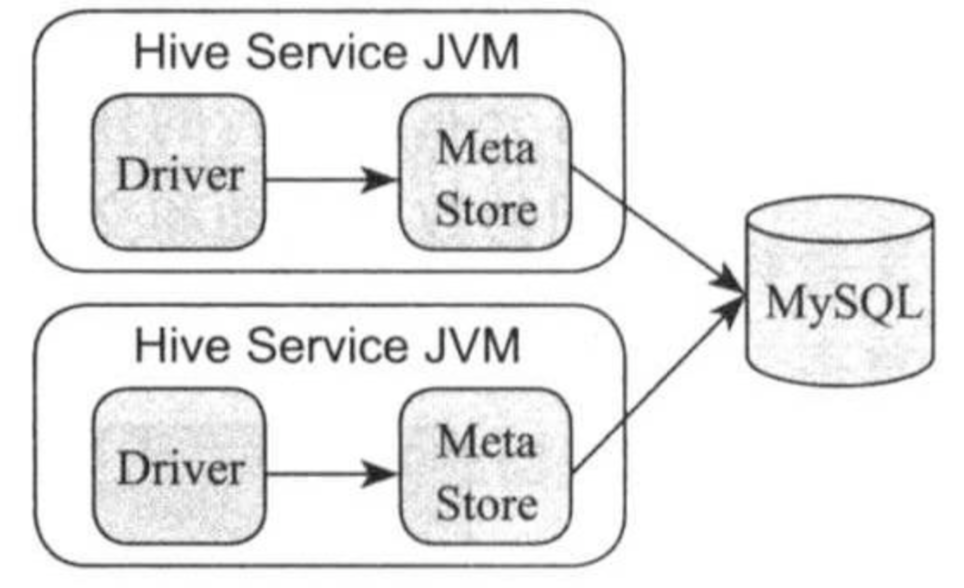
如上图所示,在本地模式中,Driver和Metastore运行在本地,而数据库(比如MySQL)启动在一个共享节点上。

如上图所示,在远程模式中,Metastore运行在单独一个节点上,被其他所有服务共享。使用Beeline,JDBC/ODBC,CLI个Thrift等方式访问Hive时,则采用该的是该模式,这是一种常用于生成环境下的部署模式。 Hive是Hadoop生态系统中最早的SQL引擎,它的Metastore服务已经被越来越多的SQL引擎所支持,已经成为大数据系统的元信息标准存储仓库。比如Spark SQL,Impala和Presto等引擎均可直接读取并处理Hive Metastore中的数据表,真正实现“一份数据多种引擎”的计算方式。
2>.Hive查询引擎
Hive最初是构建在MapReduce计算引擎之上的,但随着越来越多的新型计算引擎的出现,Hive也逐步支持其他更高效的DAG计算引擎,包括Tez和Spark等,如下图所示,用户可个性化指定每个HQL的执行执行引擎。

相比于每个MapReduce计算引擎,新型DAG计算引擎采用以下优化机制让HQL具有更高的执行性能:
(1)避免借助分布式文件系统交换数据而减少不必要的网络和磁盘IO。
(2)将重复使用的数据缓存队列到内存中以加速读取效率。
(3)复用资源直到HQL运行结束(比如在Spark,Executor一旦启用后不会释放,直到所有任务运行完成)。
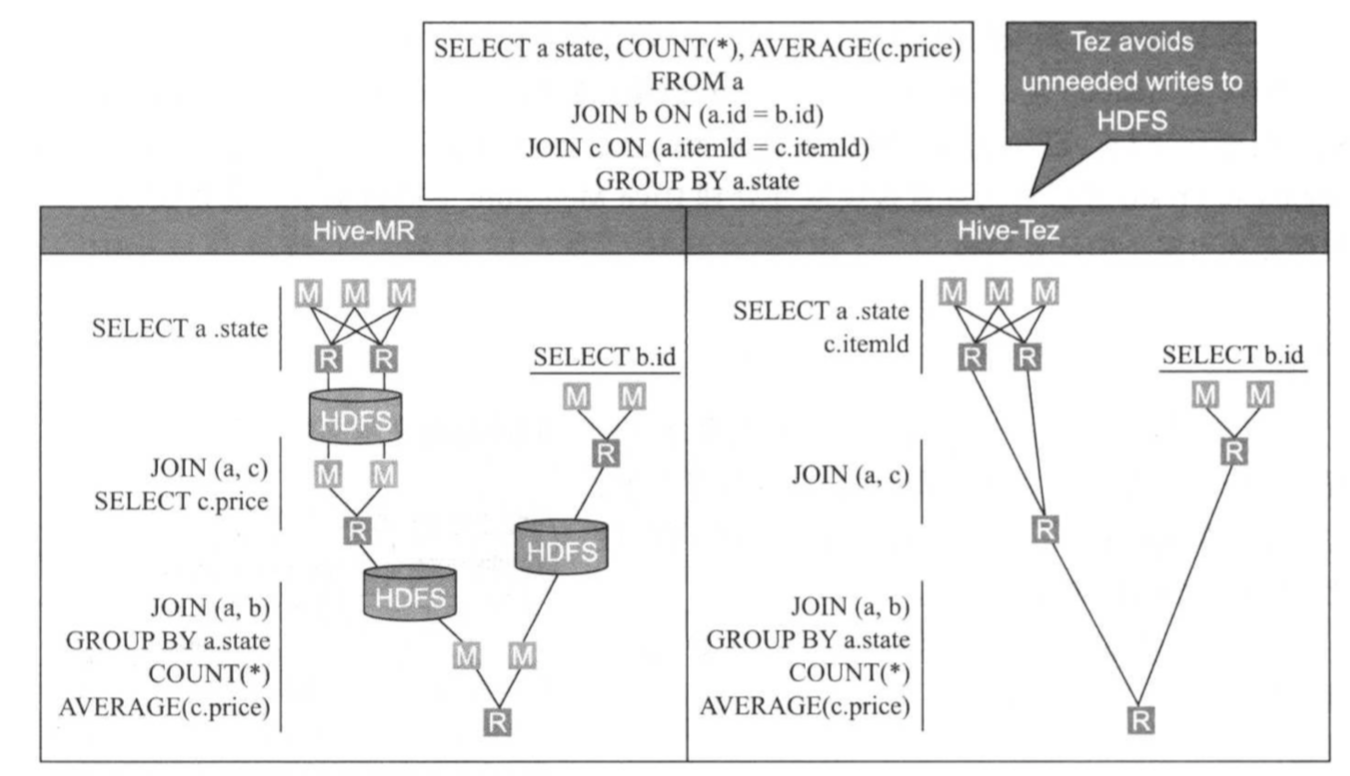
如上图所示,在Hive中运行以下HQL,在该HQL中,3个表进行链接操作,并按照state唯独进行交互操作:
SELECT a.state,COUNT(*),AVERAGE(c.price)
FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemid = c.itemid)
GROUP BY a.state
(1)如果采用MapReduce计算引擎
该HQL最终被转换成4个MapReduce作业,它们之间通过分布式文件系统HDFS交换数据,并最终由一个MapReduce作业将结果返回。在该计算过程中,中间结果要被前一个作业写入HDFS(需要写三个副本),并由下一个作业从HDFS读取数据,并进一步处理。 (2)如果采用类似Tez或Spark的DAG计算引擎
该HQL最终仅被转化成1个应用程序(得益于DAG引擎的通用性),该作业HQL中不同算子的数据交换可以直接通过本地磁盘或者网络进行,因而磁盘的网络IO开销较小,性能会更高。
三.Spark SQL基本架构
Spark SQL是构建在分布式计算框架Spark之上的结构化数据处理引擎,它不仅支持类HQL查询语言,也提供了一套结构化编程接口DataFreame/DataSet。它是一个异构化数据处理引擎,支持多种数据源,包括HDFS(各种文件格式),Hive,关系型数据库等,用户可以使用Spark SQL提供的类HQL语言和结构化编程结构处理这些数据源中的数据。
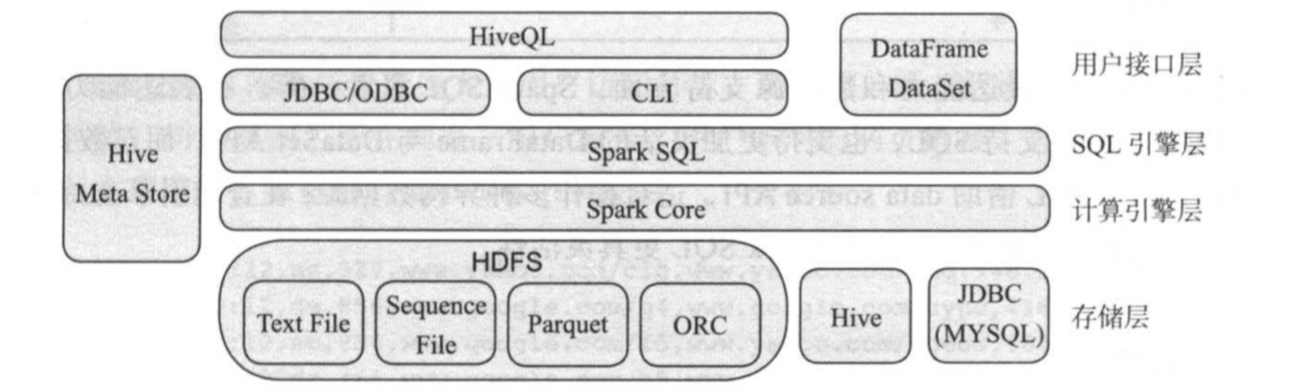
Spark SQL基本架构如上图所示,主要由四层构成:
(1)用户接口层
Spark SQL提供了两套访问接口:
1)类HQL语言
该语言兼容绝大部分HQL语法,支持CLi,JDBC/ODBC等访问方式。它可以于Hive无缝集成,直接存取Hive Metastore中的数据库和数据表。
2)结构化编程接口DataFrame/DataSet
众所周知,SQL表达能力是有限的,对于复杂的数据分析,比如机器学习算法实现,SQL很难胜任。
为了解决SQL的缺点,Spark SQL引入了一套结构化编程接口 DataFrame/DataSet,基于这套API,用户可以灵活控制自己的计算逻辑,目前是Spark生态系统中最重要的编程接口,而Spark Steaming,Mlib和graphX等系统均基于这套API实现自己的引擎和编程接口。
(2)SQL引擎层
Spark SQL引擎层主要职责是将HQL或DataFrame/DataSet程序编译成可分布式运行的程序,设计生成逻辑计划,物理计划,查询优化于执行等。其最重要的组件就是查询优化器catalyst,确保生成最优化的分布式程序。
(3)计算引擎层
SQL引擎层的输入是HQL或DataFrame/DataSet程序,而输出则是基于RDD模型的Spark分布式计算程序,这些程序会直接运行在Spark计算引擎层。
(4)存储层
Spark SQL另一个强大之处就是对数据源进行抽象,内置了对大量存储引擎的支持,包括HDFS(支持各种数据存储格式Text和Sequence File,列式存储格式Parquet和ORC等),Hive,各种关系行数据库等。用户也可以根据需要将特定数据存储引擎接入Spark SQL,进而利用其强大而灵活的引擎进行数据分析。
四.Spark SQL和Hive对比
Spark SQL于Hive均支持类SQL语言,能够很方便地处理海量数据,但它们也有明显的区别,如下图所示:
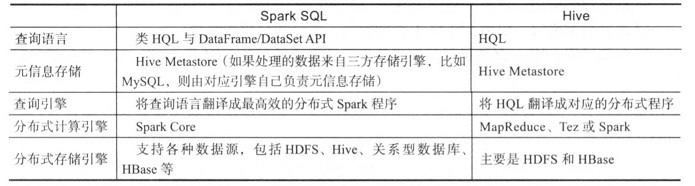
整体上说,在表达能力和数据源支持方面,Spark SQL更胜一筹,在表达能力方面Spark SQL不仅仅支持SQL,也支持更加灵活的DataFrame与DataSet API,而对数据源支持方面,Spark SQL借助data source API,适合操作多种异构数据源,在查询引擎支持方面,Hive借助插拔是引擎设计,则此Spark SQL更具灵活性。
五.博主推荐阅读
链接一:Hive快速入门篇之Hive环境搭建(https://www.cnblogs.com/yinzhengjie/p/9154324.html) 。
链接二:Hive快速入门篇之HQL的基础语法(https://www.cnblogs.com/yinzhengjie/p/9154339.html)。
链接三:HQL基本语法及应用案例(https://www.cnblogs.com/yinzhengjie/p/10847527.html)。
hive介绍及架构设计的更多相关文章
- 高焕堂《android从程序员到架构师之路》 YY讲坛直面大师学习架构设计
<android从程序员到架构师之路>YY讲坛活动: sundy携手高焕堂老师全程YY答疑 与大师一起,分享android技术 时间:7月21日下午2:00 报名联系QQ:22243 ...
- 架构师必备技能指南:SaaS(软件即服务)架构设计
1.介绍 从计算机诞生开始,就伴随着计算机应用程序的演变.简短的回顾历史,我们可以清楚的看到应用程序发生的巨大变化.上世纪70年代中期,随着个人PC机的爆炸式增长以及程序员的崛起,让计算机的计算能力得 ...
- Unity3d 引擎原理详细介绍、Unity3D引擎架构设计
体系结构 为了更好地理解游戏的软件架构和对象模型,它获得更好的外观仅有一名Unity3D的游戏引擎和编辑器是非常有用的,它的主要原则. Unity3D 引擎 Unity3D的是一个屡获殊荣的工具,用于 ...
- MySQL性能调优与架构设计——第1章 MySQL 基本介绍
第1章 MySQL 基本介绍 前言:作为最为流行的开源数据库软件之一, MySQL 数据库软件已经是广为人知了. 但是为了照顾对MySQL还不熟悉的读者,这章我们将对 MySQL 做一个简单的介绍.主 ...
- Android APP架构设计——MVC、MVP和MVVM介绍
)对于过大的项目,数据绑定需要花费更多的内存. 关于APP的架构设计就介绍到这吧,转载请注明出处:http://blog.csdn.net/seu_calvin/article/details/529 ...
- Unity3d 引擎原理详细介绍、Unity3D引擎架构设计 - zhibolife
时间 2014-03-24 11:18:00 博客园-所有随笔区原文 http://www.cnblogs.com/zhibolife/p/3620440.html 体系结构 为了更好地理解游戏的 ...
- 【MySQL高可用架构设计】(一)-- mysql复制功能介绍
一. 介绍 Mysql的复制功能是构建基于SQL数据库的大规模高性能应用的基础,主要用于分担主数据库的读负载,同时也为高可用.灾难恢复.备份等工作提供了更多的选择. 二.为什么要使用mysql复制功能 ...
- ClickHouse(02)ClickHouse架构设计介绍概述与ClickHouse数据分片设计
ClickHouse核心架构设计是怎么样的?ClickHouse核心架构模块分为两个部分:ClickHouse执行过程架构和ClickHouse数据存储架构,下面分别详细介绍. ClickHouse执 ...
- Slickflow.NET 开源工作流引擎基础介绍(六)--模块化架构设计和实践
前言:在集成Slickflow.NET 引擎组件过程中,引擎组件需要将用户,角色等资源数据读取进来,供引擎内部调用:而企业客户都是有自己的组织架构模型,在引入模块化架构设计后,引擎组件的集成性更加友好 ...
随机推荐
- PAT 甲级 1076 Forwards on Weibo (30分)(bfs较简单)
1076 Forwards on Weibo (30分) Weibo is known as the Chinese version of Twitter. One user on Weibo m ...
- k8s添加凭证
请参照:https://www.cnblogs.com/effortsing/p/10013441.html
- [LeetCode] 142. Linked List Cycle II 链表中的环 II
Given a linked list, return the node where the cycle begins. If there is no cycle, return null. Foll ...
- 【SSH进阶之路】Spring的IOC逐层深入——为什么要使用IOC[实例讲解](二)
上篇博客[SSH进阶之路]Spring简介,搭建Spring环境——轻量级容器框架(一),我们简单的介绍了Spring的基本概念,并且搭建了两个版本的Spring开发环境,但是我们剩下了Spring最 ...
- 【VS开发】MFC CListCtrl列表控件的消息响应
MFC里的CListCtrl选中一行,消息是哪个.实在想不起来了.找了一篇文章,比较有用: http://www.cnblogs.com/hongfei/archive/2012/12/25/2832 ...
- POJ 1014 Dividing(入门例题一)
Time Limit: 1000MS Memory Limit: 10000K Total Submissions: Accepted: Description Marsha and Bill own ...
- linux U盘 硬盘 unable to mount
转自aaa小菜鸡 出现原因: 上次文件没拷完就拔了U盘 参考: 解决Ubuntu挂载U盘失败的解决方法 Linux下无法挂载U盘 解决: 1.sudo fdisk -l列出当前系统下的文件设备 2.s ...
- 谈谈php里的IOC控制反转,DI依赖注入(转)
转自:http://www.cnblogs.com/qq120848369/p/6129483.html 发现问题 在深入细节之前,需要确保我们理解"IOC控制反转"和" ...
- Java开发笔记(一百二十八)Swing的图标
前面提过,AWT没提供能够直接显示图像的控件,这无疑是个令人诟病的短板,因为一上来就得由程序员自己去定义新控件,对于初学者来讲很不友好.这个问题在Swing中也解决掉了,不过Swing并未提供单独的图 ...
- Python开发之virtualenv和virtualenvwrapper详解
在使用 Python 开发的过程中,工程一多,难免会碰到不同的工程依赖不同版本的库的问题: 亦或者是在开发过程中不想让物理环境里充斥各种各样的库,引发未来的依赖灾难. 此时,我们需要对于不同的工程使用 ...